大模型结合知识库问答应用第一次实践(上)
原创
大模型结合知识库问答应用第一次实践(上)
原创
用户9295575
发布于 2024-09-10 14:44:11
发布于 2024-09-10 14:44:11
记录一次用大模型LLM和向量数据库,搭建垂直领域的知识库问答实践。采用的LangChain框架,Qdrant向量数据库、Qwen大语言模型。本文介绍如何把文本转换成向量,存储到向量数据库中,为后续的大模型+知识库问答应用做知识库数据准备。
1、向量数据库的介绍
向量数据库的核心思想是将文本、图像、视频转换成向量,然后把转换后的向量数据存储在数据库中,向量维度大小代表文本、图像或视频的特征维度。当用户输入问题时,将问题转换成相应维度的向量,然后在数据库中搜索最相似的向量。
对于不同的数据,我们需要采用不同的向量化模型。这里我采用的是nlp_corom_sentence-embedding_chinese-base-ecom模型,在魔塔社区下载
向量相似度的计算算法有如下几种:
- 欧几里得距离(Euclidean Distance):两个向量之间的距离,适用于需要考虑向量长度的相似性计算。
- 余弦相似度(Cosine Similarity):两个向量之间的夹角余弦值,余弦相似度对向量的长度不敏感,只关注向量的方向,因此适用于高维向量的相似性计算。
- 点积相似度 (Dot product Similarity) :两个向量之间的点积值。优点在于它简单易懂,计算速度快,并且兼顾了向量的长度和方向。
我选择了Qdrant,使用的默认的余弦相似度计算向量相似性。Qdrant其占用资源开销小,基础功能都不错,部署简单Docker,部署后,有API接口和WebUI。客户端支持Java SDK和python SDK。
Docker部署,执行下面命令
docker run -d --network=host --restart=always -p 6333:6333 -p 6334:6334 \
-v /work/qdrant/qdrant_storage:/qdrant/storage:z \
-e QDRANT__SERVICE__API_KEY=XXXX \
--name qdrant qdrant/qdrant启动后直接访问http://ip:6333/dashboard#/
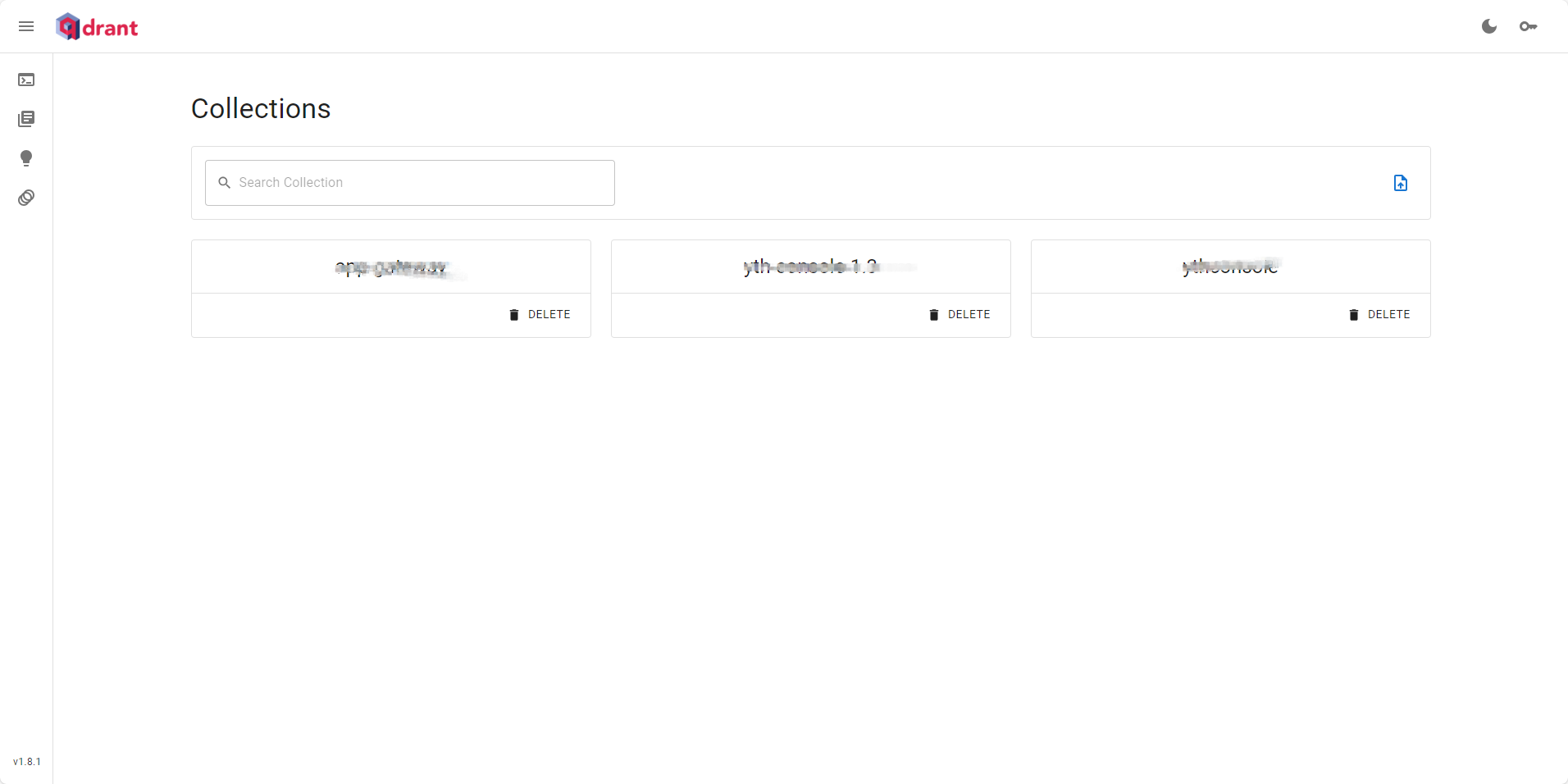
2、python代码实现把文本存储到向量数据库中
python环境:3.9
pip install 安装依赖
langchain==0.1.11
unstructured==0.12.6
markdown==3.5.2
qdrant-client==1.8.0
lark==1.1.9
modelscope==1.13.1
torch==2.2.1
transformers==4.38.2分隔markdown文档
def split_markdown(docs_path, splitters, chunk_size, chunk_overlap):
path = docs_path
loader = NotionDirectoryLoader(path)
docs = loader.load()
docs_splits = []
for doc in docs:
# Let's create groups based on the section headers in our page
# 设置markdown文档的一级标题分隔
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=splitters)
# 按照分隔符分隔文档,返回List<Document>类型,Document中包含page_content和metadata(元数据自动包含分隔符)
md_header_splits = markdown_splitter.split_text(doc.page_content)
# Define our text splitter
# 设置分块的大小 chunkSize和chunkOverlap
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
# 把文档进一步按照chunkSize大小分块
docs_splits.extend(text_splitter.split_documents(md_header_splits))
for doc in docs_splits:
# 把文档的标题插入到文档内容中
if doc.metadata.get("h1") is not None:
doc.page_content = '#' + doc.metadata.get("h1") + ">>" + doc.page_content
return docs_splits把分隔后的markdown文档插入到向量数据库
def get_embedding(model_path):
# 加载模型 不需要外网
embedding = ModelScopeEmbeddings(
model_id=os.path.join(model_path, "model/nlp_corom_sentence-embedding_chinese-base-ecom")
)
return embedding
def save_doc_vector(model_path, docs, collection_name, url, api_key, port=6333):
Qdrant.from_documents(
docs,
embedding=get_embedding(model_path),
url=url,
port=port,
api_key=api_key,
collection_name=collection_name,
force_recreate=True
)主函数
if __name__ == '__main__':
chunk_size = 300
chunk_overlap = 20
database_url = 'http://IP'
database_port = 6333
database_api_key = 'XXXX'
collection_name = '自己定义的集合名称'
splitters = [
("#", "h1")
]
path = r"D:\docs" # 文档文件夹
model_path = r"D:\model" # 向量化模型的文件夹
docs = split_markdown(path, splitters, chunk_size, chunk_overlap)
print("共分隔了{0}个文本块".format(docs.__len__()))
print("===========覆盖式插入文档到向量数据库==============")
if docs.__len__() > 0:
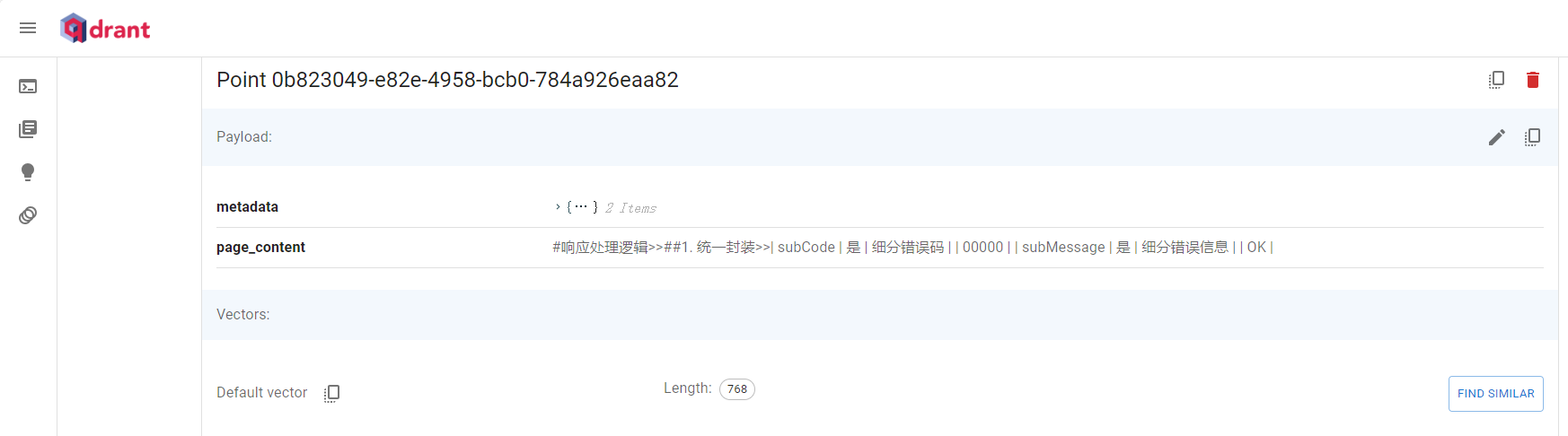
save_doc_vector(model_path, docs, collection_name, database_url, database_api_key, database_port)3、查看qdrant客户端,可以看到已经生成了集合,点击集合进入就是具体的文本分片后的向量
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号