HBase与HDFS集成的最佳实践
原创

大数据时代的到来,分布式存储和计算系统成为了数据处理的主流解决方案。HBase和HDFS分别是分布式NoSQL数据库和分布式文件系统的代表,它们都源于Hadoop生态系统,并且常常结合使用。HBase利用HDFS作为底层存储系统,借助HDFS的分布式存储特性来提供高效的随机读写和海量数据管理的能力。
HBase与HDFS的集成原理
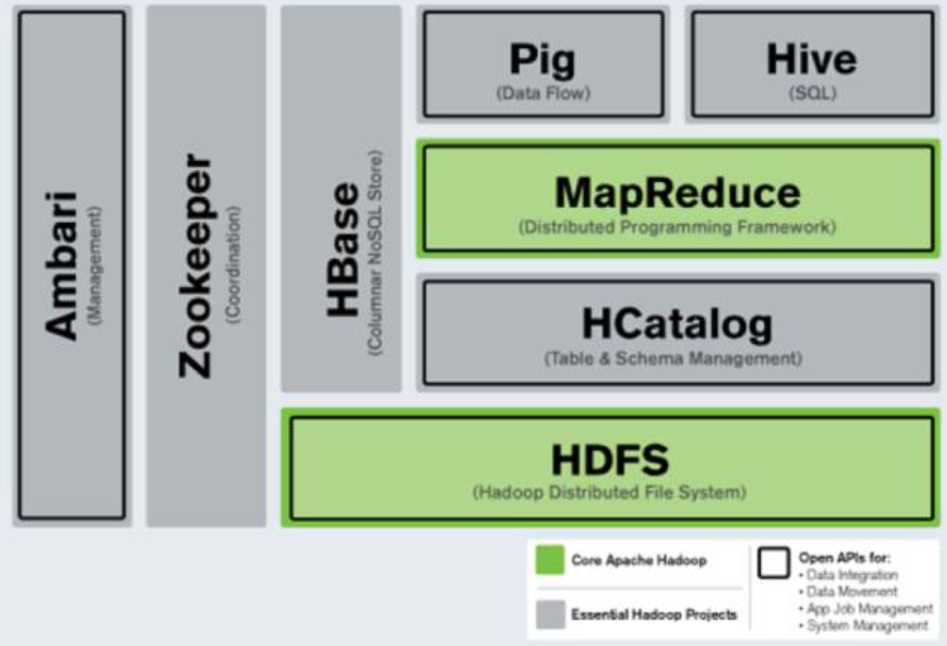
HBase依赖于HDFS作为底层的存储引擎。HBase将数据分片为多个Region,并将这些Region存储在HDFS中。HDFS负责将这些Region文件分布在多个节点上,并提供容错和高可用性保障。HBase通过以下机制与HDFS紧密集成:
数据存储 | 描述 |
|---|---|
数据存储在HFile中 | HBase中的数据以HFile格式存储在HDFS中。每个HFile包含有序的数据块,由Region Server管理。 |
WAL文件存储在HDFS上 | HBase的写操作首先记录在WAL日志中,这些日志存储在HDFS上,提供数据恢复能力。 |
HDFS特性 | 描述 |
|---|---|
提供高可靠性与数据冗余 | HDFS通过数据冗余(副本机制)确保在节点故障时数据不丢失,HBase借助此特性实现高可用性。 |
HBase与HDFS的集成部署
HDFS集群的安装与配置
在开始配置HBase之前,我们需要先配置一个HDFS集群。HDFS是Hadoop的核心组件之一,我们可以通过Hadoop来搭建HDFS。
安装Hadoop并配置HDFS:
# 下载Hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
tar -xzf hadoop-3.3.0.tar.gz
cd hadoop-3.3.0
# 编辑core-site.xml文件,配置HDFS的默认文件系统
nano etc/hadoop/core-site.xml
# 添加以下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
# 编辑hdfs-site.xml文件,配置数据副本数量和存储路径
nano etc/hadoop/hdfs-site.xml
# 添加以下配置
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
# 格式化HDFS Namenode
bin/hdfs namenode -format
# 启动HDFS
sbin/start-dfs.sh至此,我们已经成功部署了一个HDFS集群。
HBase集群的安装与配置
配置HBase并与HDFS进行集成。
# 下载HBase
wget https://downloads.apache.org/hbase/2.4.8/hbase-2.4.8-bin.tar.gz
tar -xzf hbase-2.4.8-bin.tar.gz
cd hbase-2.4.8
# 配置HBase与HDFS的集成
nano conf/hbase-site.xml
# 添加以下配置,确保HBase使用HDFS作为底层存储
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
</configuration>
# 启动HBase
bin/start-hbase.sh到这里,HBase集群已经与HDFS集成并启动成功。HBase将利用HDFS来存储它的数据。
HBase与HDFS的最佳实践
在大规模分布式系统中,HBase与HDFS的集成能够为数据的高效存储与读取提供强有力的保障。然而,如何通过配置和优化使得两者的结合充分发挥其优势,成为HBase性能和可扩展性优化的关键。本部分将深入探讨HBase与HDFS集成中的几项关键优化策略,并通过实例代码详细展示如何应用这些策略。
数据存储优化
HBase中每条记录以键值对的形式存储,数据在列族(Column Family)下进一步划分为多个列,最终以文件(HFile)的形式写入到HDFS上。在大规模数据处理场景中,数据的组织和压缩方式将直接影响HBase的存储效率与读取性能。因此,数据存储优化主要涉及以下几个方面:
数据压缩
数据压缩是减少存储空间占用和提高I/O效率的有效手段。在HBase中,列族可以启用压缩来减少HFile的大小,从而减少HDFS上的数据量。HBase支持多种压缩算法,如Snappy、LZO、Gzip等,不同的压缩算法在压缩率与解压速度上各有特点。
- Snappy:快速的压缩和解压速度,适合实时性较高的场景,但压缩率相对较低。
- Gzip:较高的压缩率,但解压速度相对较慢,适合历史数据存储等对实时性要求不高的场景。
通过启用合适的压缩算法,不仅可以减少HDFS的存储开销,还可以减少网络传输的数据量,从而提高数据的读取效率。
代码示例:启用Snappy压缩
以下是如何为HBase表启用Snappy压缩的代码示例:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.compress.Compression.Algorithm;
public class HBaseCompressionExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// 定义表名
TableName tableName = TableName.valueOf("user_data");
// 定义表描述符
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
// 定义列族描述符并启用Snappy压缩
HColumnDescriptor columnDescriptor = new HColumnDescriptor("info");
columnDescriptor.setCompressionType(Algorithm.SNAPPY);
tableDescriptor.addFamily(columnDescriptor);
// 如果表不存在,创建表
if (!admin.tableExists(tableName)) {
admin.createTable(tableDescriptor);
System.out.println("Table created with Snappy compression.");
} else {
System.out.println("Table already exists.");
}
}
}
}setCompressionType(Algorithm.SNAPPY)方法用于启用Snappy压缩。- 通过这种方式,HBase将利用HDFS上的Snappy压缩算法来压缩存储在HFile中的数据,从而减少存储开销。
合理分区与预分裂
在HBase中,表的数据存储在多个Region中,Region是HBase水平分割的基本单位。随着数据的不断增长,Region会自动分裂成更小的Region,以平衡各Region Server的负载。然而,自动分裂的过程可能会带来一定的性能开销,尤其是当数据大量涌入时,系统需要频繁进行Region分裂。
为了解决这一问题,我们可以在创建表时手动进行预分裂。预分裂能够根据数据的RowKey范围提前划分Region,从而避免在数据写入的高峰期频繁发生自动分裂,提升整体系统的写入性能。
代码示例:手动预分裂
以下代码展示了如何在HBase中创建带有预分裂的表:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBasePreSplitExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// 定义表名
TableName tableName = TableName.valueOf("user_data");
// 定义表描述符
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
// 定义列族描述符
HColumnDescriptor columnDescriptor = new HColumnDescriptor("info");
tableDescriptor.addFamily(columnDescriptor);
// 定义预分裂的键值范围
byte[][] splitKeys = new byte[][] {
Bytes.toBytes("1000"),
Bytes.toBytes("2000"),
Bytes.toBytes("3000")
};
// 如果表不存在,创建表并进行预分裂
if (!admin.tableExists(tableName)) {
admin.createTable(tableDescriptor, splitKeys);
System.out.println("Table created with pre-split regions.");
} else {
System.out.println("Table already exists.");
}
}
}
}createTable(tableDescriptor, splitKeys)方法用于创建带有预分裂的表。splitKeys定义了预分裂的RowKey范围。- 通过预分裂,数据将会根据RowKey的范围分布在不同的Region中,从而避免写入压力集中在单一Region上。
写性能优化
HBase写操作的性能与HDFS的交互频率和数据管理机制密切相关。在HBase中,每次写操作(Put、Delete等)都会首先记录在WAL(Write-Ahead Log)中,WAL记录了每次写入的操作日志以便在系统发生故障时进行恢复。因此,如何优化WAL的管理和写入策略将显著影响HBase的写入性能。
WAL日志的管理
HBase的WAL记录每次写入操作的日志,确保了在发生系统崩溃时,数据可以通过WAL进行恢复。然而,对于某些对数据一致性要求不高的应用场景,可以选择临时禁用WAL日志,以提升写入性能。
禁用WAL适用于一些临时性的数据加载场景,或者一些能够容忍数据丢失的非核心业务场景。需要注意的是,禁用WAL将牺牲数据的持久性,系统在发生崩溃时,未记录到磁盘的数据可能会丢失。
代码示例:禁用WAL进行写入
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseDisableWALExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("user_data"))) {
// 创建Put对象
Put put = new Put(Bytes.toBytes("user1234"));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("John Doe"));
// 禁用WAL日志
put.setDurability(Durability.SKIP_WAL);
// 执行写入操作
table.put(put);
System.out.println("Data written without WAL.");
}
}
}setDurability(Durability.SKIP_WAL)方法用于禁用WAL日志,从而减少写入的IO开销,提高写入速度。- 禁用WAL适用于那些对数据持久性要求不高的场景,能够显著提升批量写入时的性能。
批量写入优化
在大规模数据写入场景中,单条记录逐条写入将会引入巨大的网络延迟和频繁的磁盘I/O,影响写入效率。因此,HBase提供了批量写入的机制,允许将多个Put操作合并为一个请求批量提交到Region Server。这不仅减少了网络请求的频次,也减少了WAL的写入操作次数。
代码示例:批量写入
以下代码展示了如何使用批量写入来提升写入性能:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.util.ArrayList;
import java.util.List;
public class HBaseBatchWriteExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("user_data"))) {
// 创建批量Put对象
List<Put> putList =
new ArrayList<>();
for (int i = 1; i <= 1000; i++) {
Put put = new Put(Bytes.toBytes("user" + i));
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("User " + i));
putList.add(put);
}
// 执行批量写入
table.put(putList);
System.out.println("Batch write completed.");
}
}
}- 通过将多个Put对象放入列表中,批量提交到Region Server,减少了网络请求次数和WAL日志写入次数,从而大幅提升写入性能。
读性能优化
在大数据存储系统中,读操作的性能优化同样至关重要。HBase与HDFS的深度集成使得数据可以分布存储在多个Region Server中,充分利用HDFS的分布式文件系统特性。然而,读取性能不仅依赖于HDFS,还涉及数据在HBase中的组织方式和缓存机制。
启用缓存
HBase提供了多种缓存机制,用于加速数据的读取。例如,HBase的BlockCache可以将最近读取的HFile块缓存到内存中,从而加速后续相同数据的读取。同时,可以在列族级别启用缓存,以便在读取时自动将数据加载到缓存中。
代码示例:启用BlockCache
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
public class HBaseCacheExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// 定义表名
TableName tableName = TableName.valueOf("user_data");
// 定义表描述符
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
// 定义列族描述符并启用BlockCache
HColumnDescriptor columnDescriptor = new HColumnDescriptor("info");
columnDescriptor.setBlockCacheEnabled(true); // 启用BlockCache
tableDescriptor.addFamily(columnDescriptor);
// 如果表不存在,创建表
if (!admin.tableExists(tableName)) {
admin.createTable(tableDescriptor);
System.out.println("Table created with BlockCache enabled.");
} else {
System.out.println("Table already exists.");
}
}
}
}setBlockCacheEnabled(true)方法用于启用列族级别的缓存,提升读性能。- 当启用BlockCache后,最近访问的HFile块会被缓存到内存中,后续的读取请求可以直接从缓存中读取,避免不必要的磁盘I/O,从而提升读取速度。
合并小文件
在HBase与HDFS集成的过程中,大量的小文件(小HFile)会导致HDFS的性能问题,尤其是在读取时,过多的小文件会引发大量的随机I/O操作,降低系统整体的读性能。为了解决这个问题,可以通过HBase的合并操作(Compaction)来合并小文件,减少文件碎片,提高数据读取的连续性。
HBase支持两种类型的合并:
- Minor Compaction:合并小文件,将相邻的小HFile合并为较大的文件,但不会删除旧版本的数据。
- Major Compaction:将小文件合并为一个更大的文件,并且会删除多余的旧版本数据。
代码示例:手动触发合并
以下是如何手动触发合并操作的示例代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
public class HBaseCompactionExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// 定义表名
TableName tableName = TableName.valueOf("user_data");
// 手动触发Major Compaction
admin.majorCompact(tableName);
System.out.println("Major compaction triggered.");
}
}
}admin.majorCompact(tableName)方法用于触发Major Compaction,将小文件合并为较大的文件,并清理旧版本数据,从而提升读取性能。- 合并操作会占用一定的系统资源,建议在系统负载较低时执行,以免影响正常的读写操作。
扫描操作优化
HBase中的Scan操作用于批量读取一系列记录,在读取大范围的数据时,扫描操作的效率至关重要。默认的扫描操作会逐条读取数据,而通过合理配置扫描的缓存和批量大小,可以显著提高读取的吞吐量。
- Cache Size:指定每次读取的行数,增加缓存行数可以减少与Region Server的交互次数。
- Batch Size:指定每次从每个列族中读取的列数。
代码示例:优化扫描操作
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseScanOptimizationExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("user_data"))) {
// 创建扫描对象
Scan scan = new Scan();
scan.setCaching(500); // 设置缓存大小为500行
scan.setBatch(100); // 设置批处理大小为100列
// 执行扫描
try (ResultScanner scanner = table.getScanner(scan)) {
for (Result result : scanner) {
// 处理扫描结果
String rowKey = Bytes.toString(result.getRow());
String name = Bytes.toString(result.getValue(Bytes.toBytes("info"), Bytes.toBytes("name")));
System.out.println("Row: " + rowKey + ", Name: " + name);
}
}
}
}
}setCaching(500)方法用于设置每次读取的缓存行数为500,减少与服务器的交互频次。setBatch(100)方法用于设置批处理的列数为100,避免逐列读取数据,提升读取性能。
HDFS与HBase的一致性保障
HBase与HDFS的集成必须考虑数据一致性问题。HBase默认通过WAL(Write-Ahead Log)机制保障数据的持久性与一致性。写入的数据首先会被记录到WAL中,然后再写入到HBase内存中。即便发生系统故障,也可以通过WAL恢复未持久化的数据。
除了WAL机制,HDFS本身也具备多副本机制,通过配置HDFS的副本数可以进一步提升数据存储的可靠性。通常情况下,HDFS的副本数设置为3,以保证数据在多个节点上都有存储副本,即使某个节点发生故障,也不会丢失数据。
最佳实践:
- WAL的合理配置:在核心数据场景中,应始终启用WAL以确保数据的强一致性。对于临时性数据或对一致性要求不高的场景,可以根据业务需求选择跳过WAL记录,以提升性能。
- HDFS副本数配置:根据业务的可靠性要求,合理配置HDFS的副本数。通常设置为3是一个较为平衡的选择,既保证了数据的可靠性,又不会过度消耗存储资源。
HDFS副本数配置示例:
可以通过HDFS的配置文件 hdfs-site.xml 中的以下参数进行设置:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>dfs.replication设置为3,表示每份数据将会在HDFS上保存3个副本,确保数据可靠性。
负载均衡与容灾
为了提升HBase集群的可扩展性和容灾能力,HDFS与HBase的深度集成提供了数据的负载均衡与容灾策略。HBase通过将Region Server的数据分布到多个HDFS数据节点上来实现负载均衡,当某个节点出现故障时,HBase会自动将数据恢复到其他可用节点上,确保数据的可用性。
负载均衡策略
HBase支持自动负载均衡功能,通过动态分配Region到不同的Region Server上,确保各个服务器的负载均衡。可以通过手动或自动的方式启用负载均衡。
代码示例:手动触发负载均衡
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
public class HBaseLoadBalanceExample {
public static void main(String[] args) throws Exception {
Configuration config = HBaseConfiguration.create();
try (Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
// 手动触发负载均衡
admin.balance();
System.out.println("Load balancing triggered.");
}
}
}admin.balance()方法用于手动触发负载均衡操作,HBase将会尝试重新分配Region,确保集群的负载均匀分布。
HBase与HDFS的紧密集成使得它们在大数据存储与处理方面具备了强大的优势。通过合理的表设计、压缩、批量写入和读写性能优化策略,HBase可以充分发挥HDFS的分布式存储优势,在海量数据场景下提供高效的读写性能。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号