自动驾驶数据集 nuScenes


nuScenes 是一个大型公开自动驾驶数据集,它使研究人员能够研究具有挑战性的城市驾驶情况,使用真实自动驾驶汽车的全套传感器。

简介
NuScenes 数据集 (发音为/nuːsiːnz/) 是一个公开的大规模自动驾驶数据集,由 Motional (以前的 nuTonomy)团队开发。动感正在使无人驾驶汽车成为一种安全、可靠和易于使用的现实。通过向公众发布我们的数据子集,Motion 的目标是支持公众对计算机视觉和自动驾驶的研究。
为此,我们在波士顿和新加坡收集了1000个驾驶场景,这两个城市以拥挤的交通和极具挑战性的驾驶环境而闻名。20秒长的场景是手动选择,以显示不同的和有趣的驾驶机动,交通情况和意想不到的行为。NuScenes 的丰富复杂性将鼓励开发方法,使安全驾驶在城市地区与每个场景几十个对象。通过收集不同大陆的数据,我们可以进一步研究计算机视觉算法在不同地点、天气条件、车辆类型、植被、道路标记和左右交通中的泛化。
为了方便常见的计算机视觉任务,例如目标检测和跟踪,我们在整个数据集上用 2Hz 的精确三维边界框对23个对象类进行注释。此外,我们还注释对象级属性,如可见性、活动和姿态。
对于 nuScenes 数据集,我们在波士顿和新加坡收集了大约15小时的驾驶数据。对于完整的 nuScenes 数据集,我们发布来自 Boston Seaport 和新加坡的 One North、昆斯敦和 Holland Village 地区的数据。驾驶路线是精心选择,以捕捉具有挑战性的情况。我们的目标是不同的地点,时间和天气条件。为了平衡班级频率分布,我们包含了更多稀有班级的场景(如自行车)。使用这些标准,我们手动选择1000个场景,每个场景持续时间为20秒。这些场景是由人类专家精心注释的。注释器指令可以在 devkit 存储库中找到。
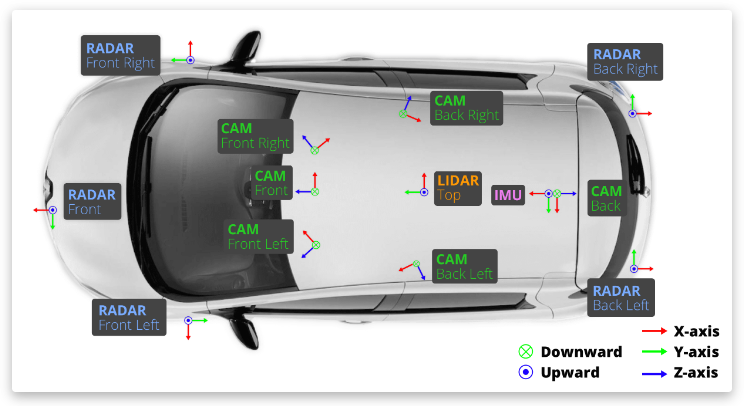
我们在波士顿和新加坡使用两辆雷诺佐伊汽车,它们的传感器布局完全相同。这些数据是从一个研究平台收集的,并不能说明在 Motion 产品中使用的设置。有关感应器的位置,请参阅上图。
数据集特点:
- 全套传感器(一个激光雷达,五个雷达,六个摄像头, IMU, GPS)
- 1000 个场景数据,每组数据 20s
- 1400000 摄像头图像
- 390000 激光雷达扫描数据
- 两个城市数据:波士顿和新加坡
- 详细的地图信息
- 为23个对象类手动注释的1.4 M 3D 边界框
- 可见性,活动和姿势等属性
- 1.1 B 激光雷达点32类手动注释
- 非商业用途免费使用
下载链接:https://nuscenes.org/nuscenes
传感器校准
为了获得高质量的多传感器数据集,必须对每个传感器的外部特性和内部特性进行标定。我们表示相对于自我框架的外部坐标,即后车轴的中点。最相关的步骤如下:
激光雷达
我们使用激光线来准确测量激光雷达的相对位置的自我框架。
相机
我们在摄像机和激光雷达传感器前面放置一个立方体形状的校准目标。标定目标由三个具有已知模式的正交平面组成。在检测到图案之后,我们通过校准目标的平面来计算从相机到激光雷达的变换矩阵。给定上述计算的激光雷达到自我帧变换,我们就可以计算摄像机到自我帧变换和由此产生的外部参数。
雷达
我们把雷达安装在水平位置。然后我们通过在城市环境中驾驶来收集雷达测量数据。在滤波雷达返回的运动目标,我们校准偏航角使用蛮力的方法,以最小化补偿距离率的静态目标。
相机内部标定
我们使用一个具有已知模式集的校准目标板来推断摄像机的内在参数和畸变参数。
传感器同步
为了在激光雷达和相机之间实现良好的跨模态数据对齐,当顶部激光雷达扫过相机的视野中心时,相机的曝光被触发。图像的时间戳是曝光触发时间; 激光雷达扫描的时间戳是当前激光雷达帧完全旋转的时间。考虑到相机的曝光时间几乎是瞬间的,这种方法通常产生良好的数据对齐。请注意,相机运行在 12Hz,而激光雷达运行在 20Hz。12个相机的曝光在20个激光雷达扫描中尽可能均匀地分布,因此并非所有的激光雷达扫描都有相应的相机框架。将摄像机的帧频降低到12Hz 有助于减少感知系统的计算量、带宽和存储需求。
评价指标
nuScenes 检测任务的度量。我们的最终得分是平均精度(mAP)和几个真正正值(TP)指标的加权和。
Average Precision metric
- mean Average Precision (mAP)
我们使用众所周知的平均精度度量,但是通过考虑地平面上的二维中心距离来定义匹配。具体来说,我们将预测与具有最小中心距离达到一定阈值的地面真相对象进行匹配。对于给定的匹配阈值,我们通过积分召回与精度曲线来计算平均精度(AP) ,并且精度 > 0.1。最后,我们平均超过{0.5,1,2,4}米的匹配阈值,并计算类间的平均值。
米。在计算AP时,去除了低于0.1的recall和precision并用0来代替这些区域。不同类以及不同难度D用来计算mAP:
True Positive metrics
我们为一组真正的正面(TP)定义了度量转换/尺度/方向/速度和属性错误的指标。在匹配过程中,所有 TP 指标都使用2m 中心距离的阈值计算,并且它们都被设计为正标量。
匹配和评分分别发生在每个类别,每个指标是每个达到的召回水平超过10% 的累积平均值的平均值。如果某个类没有达到10% 的召回率,则该类的所有 TP 错误都设置为1。我们定义以下 TP 错误:
指标 | 含义 |
|---|---|
Average Translation Error (ATE) | 以米为单位的二维欧几里得中心距离。 |
Average Scale Error (ASE) | 1 - IoU, 其中 IoU 是角度对齐后的三维交并比 |
Average Orientation Error (AOE) | 弧度预报与地面真实度的最小偏航角差。方向误差评定在360度,除了障碍,所有类别只评定在180度。忽略锥体的方向错误。 |
Average Velocity Error (AVE) | 忽略了障碍物和锥体在 m/s 速度误差中的绝对速度误差, 二维速度差的L2 范数(m/s)。 |
Average Attribute Error (AAE) | 计算为1-acc,其中 acc 是属性分类精度。忽略障碍和锥的属性误差。 |
TP 指标是按类定义的,然后我们采用类的平均值来计算 mATE、 mASE、 mAOE、 mAVE 和 mAAE。
nuScenes detection score
- nuScenes detection score (NDS)
。然后,我们分配一个权重为 5 的 mAP 和 1 的 5 TP 分数,并计算归一化的总和。
原始论文
参考资料
文章链接:
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-9-5,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号