【AI 大模型】RAG 检索增强生成 ③ ( 文本向量 | Word2Vec 词汇映射向量空间模型 - 算法原理、训练步骤、应用场景、实现细节 | Python 代码示例 )

【AI 大模型】RAG 检索增强生成 ③ ( 文本向量 | Word2Vec 词汇映射向量空间模型 - 算法原理、训练步骤、应用场景、实现细节 | Python 代码示例 )

韩曙亮
发布于 2024-08-20 13:59:08
发布于 2024-08-20 13:59:08
一、Word2Vec 词汇映射向量空间模型
1、Word2Vec 模型简介
Word2Vec 是一个 将 词汇 映射 到 高维向量空间 的模型 , 其 核心思想 是 通过大量的文本数据来学习每个词的向量表示 , 使得 语义相似 的 单词 或 汉字 在向量空间中彼此接近 ;
Word2Vec 的 训练模型 :
- 连续词袋模型 CBOW
- 跳字模型 Skip-gram
下面介绍上述两种模型的 算法原理 ;
2、连续词袋模型 CBOW - 算法原理
连续词袋模型 CBOW 算法的目的 : 预测 给定上下文词汇 的 中心词 ;
在 CBOW 模型中 , 先给定 某个词汇 ( 中心词 ) 的上下文 , 模型的目标是 预测 这段文字 中心的词汇 , 也就是 预测 中心词 ;
连续词袋模型 CBOW 通过 上下文词汇 的 平均 或 加权和 操作 , 预测中心词的 向量 , 然后从 文本向量表 中 查找 距离该向量 最近的词汇是哪个 , 这个词 就是 预测的结果 , 中心词 ;
将 上下文词汇 对应的 文本向量 进行 平均 或 加权 操作 后 , 传递给一个输出层 , 输出层 使用 softmax 激活函数 来预测中心词 ;
下图中 , X1 X2 X3 等词汇 , 每个词汇 都由 向量表示 , 每个向量都由 若干 浮点数组成 ;
输出层是多个 上下文词汇 , 隐藏层 进行 平均或加权和 计算操作 , 得到 输出层 的 中心词 对应的 向量 ;
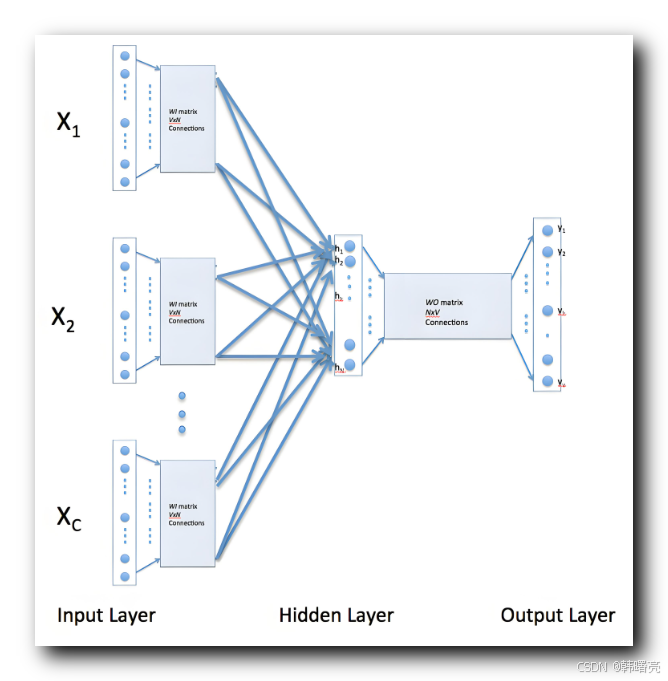
举例说明 :
假设 给定一句话 " The cat sits on the mat " , 并选择 " sits " 单词 作为 中心词 , 那么我们将 “The”, “cat”, “on”, “the”, “mat” 作为上下文词汇 ;
根据 这些 上下文词汇 , 预测出中心词 , 看是否能把 " sit " 单词作为中心词 预测出来 ;
3、连续词袋模型 CBOW - 模型训练步骤
连续词袋模型 CBOW 训练步骤 :
- 输入层 : 输入层的每个节点对应一个上下文词汇 , 每个上下文词汇用一个 编码向量表示 ;
- 隐藏层: 上下文词汇的 编码向量 通过一个权重矩阵映射到隐藏层 , 这些权重是模型要学习的 ;
- 输出层: 隐藏层的输出通过另一个权重矩阵映射到词汇表的大小 , 并通过 softmax 函数计算每个词的概率分布 ;
该模型的 训练目标 是 最大化 预测 中心词的 准确率 ;
4、跳字模型 Skip-gram - 算法原理
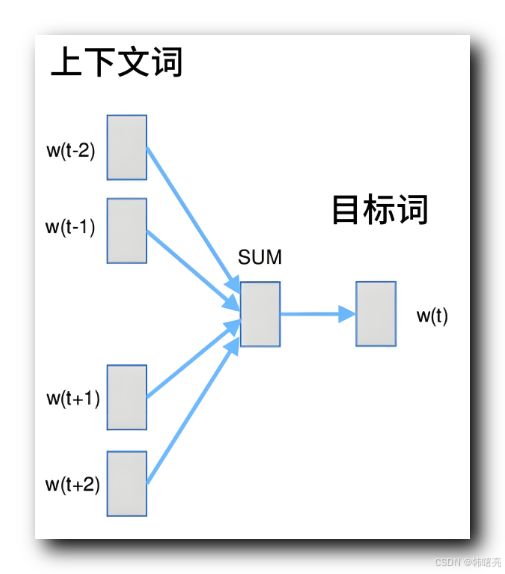
跳字模型 Skip-gram 算法原理 : 给定一个 中心词 , 预测 中心词 的 上下文词汇 ;
在 Skip-gram 模型中 , 给定一个中心词,模型的目标是预测这个中心词周围的上下文词汇 ;
Skip-gram 模型通过中心词的向量来预测每个上下文词汇的向量,即中心词的向量经过一个权重矩阵映射到输出层,通过 softmax 函数来预测上下文词汇的概率分布。
举例说明 : 假设我们有一个句子 " The cat sits on the mat " , 选择 " sits " 作为中心词 , 那么 “The”, “cat”, “on”, “the”, “mat” 就是上下文词汇 ;
给定 中心词 " sits " , 进行 上下文预测 , 看是否能预测出 “The”, “cat”, “on”, “the”, “mat” 等上下文词汇 ;
5、跳字模型 Skip-gram - 模型训练步骤
跳字模型 Skip-gram - 模型训练步骤 :
- 输入层 : 输入层的每个节点对应一个中心词 , 中心词用一个 编码向量表示 ;
- 隐藏层 : 中心词的独热编码向量通过一个权重矩阵映射到隐藏层 , 这些权重是模型要学习的 ;
- 输出层 : 隐藏层的输出通过另一个权重矩阵映射到词汇表的大小 , 并通过 softmax 函数计算每个上下文词的概率分布 ;
该模型 的 目标是 最大化 预测 上下文 的 准确率 ;
6、文本向量表示
Word2Vec 模型 训练完成后 , 每个 词汇 将被映射到一个高维向量空间中 , 相似的 词汇 在向量空间中的距离较近 ;
这些 词向量 / 文本向量 可以用来进行各种 自然语言处理任务 , 如词义相似度计算、文本分类等 ;
将下面的一段文本进行训练 ,
# 示例文本数据
sentences = [
"I love machine learning",
"Deep learning is amazing",
"Natural language processing is a fascinating field"
]向量维度设置为 50 , 那么就是在 50 维的向量空间中表示每个单词 , 每个单词都使用 50 个 浮点数进行表示 ;
下面是 单词 " learning " 的 文本向量 , 由 50 个浮点数 ;
Word: learning,
Vector: [-0.00321157 0.03927787 0.00616916 0.02789649 0.02203173 0.03612738
0.00637109 0.04316046 -0.049891 0.02915843 -0.00426264 0.02841807
0.01823073 0.0149862 -0.02141328 -0.00687046 0.0535442 0.01235065
-0.046329 0.00192757 -0.00424403 0.00364727 0.05790862 0.04215468
0.04061833 0.03017248 -0.03808379 0.05979197 0.03251123 -0.01618787
-0.05283526 -0.01509981 0.05030754 -0.03224825 0.05769876 -0.01519872
0.02141866 0.01543435 -0.01191425 -0.00674526 0.00728445 0.04265702
0.01254657 0.04424815 -0.05862596 -0.00738266 0.01891772 0.02471734
0.01362135 0.02899224]7、Word2Vec 文本向量的应用场景
Word2Vec 文本向量 的 应用场景如下 :
- 计算同义词 : 通过计算 词向量 之间的 距离 或 余弦相似度 , 可以衡量词义的相似性 ;
- 文本分类 : 使用 文本向量 表示 文本的特征 , 可以提高 文本分类器 在 垃圾邮件检测、情感分析 等方面的性能 ;
- 语言翻译 : 词向量 帮助将源语言词汇映射到目标语言词汇 , 增强翻译系统的准确性和流畅性 ;
- 向量检索 : 替代传统的 " 关键词检索 " , 通过词向量改进搜索引擎的相关性排名 , 使得搜索结果与用户意图更加匹配 , 即使没有一模一样的词汇 , 也可以通过近义词进行检索 ;
- 命名实体识别(NER): 在文本中 识别 和 分类实体名称 , 词向量有助于提升识别准确率 ;
- 实体名称 指的是 人名 , 地名 , 公司名 等 ;
- GPT 生成文本模型 : 在 大语言模型 的 文本生成任务中 , 如 : 对话生成 , 自动写作,词向量可以帮助生成更自然和相关的内容 ;
二、Word2Vec 完整代码示例
1、Python 中实现 Word2Vec 模型的库
Python 中 实现了 Word2Vec 模型 的函数库 :
- TensorFlow : 开源的机器学习库 , 可以用来构建 Word2Vec 模型 , TensorFlow 提供了深度学习的基础工具 , 可以实现 Word2Vec 模型 ;
- 使用前先执行
pip install tensorflow命令 , 安装软件包 ;
- 使用前先执行
- Gensim : 用于自然语言处理的库 , 提供了高效的 Word2Vec 实现 ;
- 使用前先执行
pip install gensim命令 , 安装软件包 ;
- 使用前先执行
- Keras : 高级神经网络 API , 可以在 TensorFlow、Theano 和 CNTK 后端上运行 ; Keras 内置了很多功能来构建和训练模型 , 包括 Word2Vec ;
- 使用前先执行
pip install keras命令 , 安装软件包 ;
- 使用前先执行
- FastText : Facebook 开发的一个库 , 扩展了 Word2Vec 的功能 , 并且通常更快且准确度更高 ;
- 使用前先执行
pip install fasttext命令 , 安装软件包 ;
- 使用前先执行
2、安装 tensorflow 软件包
在 Windows 系统的 cmd 命令行中执行
pip install tensorflow命令 , 安装 PyCharm 中使用的 Python 函数库 tensorflow 软件包 ;
Python 中使用 pip install 命令 , 安装的 软件包 都在 Python SDK 的 Lib\site-packages 目录下 ;
本次的安装目录是 D:\001_Develop\022_Python\Python37_64\Lib\site-packages , 其中D:\001_Develop\022_Python\Python37_64 目录是 Python 的 SDK 安装位置 ;
tensorflow 库安装后有 1 GB , 因此 千万不要把 Python 的 SDK 装在 C 盘 , 系统盘不够用 ;
3、代码示例
示例代码解析 : 在下面的代码中 , 展示了 tensorflow 中提供的 Word2Vec 模型用法示例 ;
- 首先 , 进行 数据准备 操作 ;
- 使用 Tokenizer 将文本数据转换为整数序列 , 并生成词汇表 ;
- 使用 skipgrams 函数生成训练对 , 这里我们使用了 Skip-gram 方法来生成上下文和目标词对 ;
- 然后 , 构建简单的 Word2Vec Skip-gram 模型 , 包括 两个 嵌入层 和 一个 点积层 ;
- 两个 嵌入层 分别对应 目标词 和 上下文词 ;
- 模型的输入是 目标词 和 上下文词 , 输出的是 两个词 之间的相似度 ;
- 再后 , 使用 binary_crossentropy 函数作为 损失函数 , 进行模型训练 ;
- 最后 , 从 训练好 的 模型中 , 提取 文本向量 , 并 输出 到命令行中 ;
代码示例 :
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import skipgrams
from tensorflow.keras.layers import Embedding, Dot, Reshape
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
# 示例文本数据
sentences = [
"I love machine learning",
"Deep learning is amazing",
"Natural language processing is a fascinating field"
]
# 使用 Tokenizer 进行词汇表创建
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences) # 构建词汇表
word_index = tokenizer.word_index # 获取词汇表中的词及其对应的索引
index_word = {i: w for w, i in word_index.items()} # 创建索引到词的映射
vocab_size = len(word_index) + 1 # 词汇表大小
# 将文本数据转为整数序列
sequences = tokenizer.texts_to_sequences(sentences) # 将文本转换为整数序列
# 生成 Skip-gram 数据对
pairs, labels = [], [] # 初始化数据对和标签列表
for sequence in sequences:
skipgram_pairs, skipgram_labels = skipgrams(sequence, vocabulary_size=vocab_size, window_size=2) # 生成 Skip-gram 对
pairs.extend(skipgram_pairs) # 添加数据对
labels.extend(skipgram_labels) # 添加标签
pairs = np.array(pairs) # 转换为 NumPy 数组
labels = np.array(labels) # 转换为 NumPy 数组
# 模型参数
embedding_dim = 50 # 嵌入向量维度
# 构建模型
input_target = tf.keras.Input(shape=(1,)) # 目标词输入层
input_context = tf.keras.Input(shape=(1,)) # 上下文词输入层
embedding = Embedding(vocab_size, embedding_dim, input_length=1, name='embedding') # 嵌入层
target = embedding(input_target) # 目标词嵌入
context = embedding(input_context) # 上下文词嵌入
dot_product = Dot(axes=-1)([target, context]) # 计算目标词和上下文词的点积
output = Reshape((1,))(dot_product) # 调整输出形状
model = Model(inputs=[input_target, input_context], outputs=output) # 创建模型
model.compile(optimizer=Adam(), loss='binary_crossentropy') # 编译模型,使用 Adam 优化器和二元交叉熵损失函数
# 训练模型
model.fit([pairs[:, 0], pairs[:, 1]], labels, epochs=10, batch_size=256) # 训练模型
# 提取词向量
word_embeddings = model.get_layer('embedding').get_weights()[0] # 获取词嵌入矩阵
# 打印词向量
for word, index in word_index.items(): # 遍历词汇表中的每个词
print(f'Word: {word}, Vector: {word_embeddings[index]}') # 打印词和对应的词向量4、执行结果
上述 代码 执行结果如下 : 每个单词都转为了 50 个浮点数组成的向量值 ;
D:\001_Develop\022_Python\Python37_64\python.exe D:/002_Project/011_Python/OpenAI/word2vec2.py
2024-08-16 09:28:11.076184: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Epoch 1/10
1/1 [==============================] - 0s 338ms/step - loss: 4.6802
Epoch 2/10
1/1 [==============================] - 0s 2ms/step - loss: 4.5502
Epoch 3/10
1/1 [==============================] - 0s 2ms/step - loss: 4.4719
Epoch 4/10
1/1 [==============================] - 0s 949us/step - loss: 4.4127
Epoch 5/10
1/1 [==============================] - 0s 981us/step - loss: 4.3644
Epoch 6/10
1/1 [==============================] - 0s 969us/step - loss: 4.3234
Epoch 7/10
1/1 [==============================] - 0s 2ms/step - loss: 4.2877
Epoch 8/10
1/1 [==============================] - 0s 2ms/step - loss: 4.2559
Epoch 9/10
1/1 [==============================] - 0s 2ms/step - loss: 4.2272
Epoch 10/10
1/1 [==============================] - 0s 2ms/step - loss: 4.2011
Word: learning, Vector: [-0.00321157 0.03927787 0.00616916 0.02789649 0.02203173 0.03612738
0.00637109 0.04316046 -0.049891 0.02915843 -0.00426264 0.02841807
0.01823073 0.0149862 -0.02141328 -0.00687046 0.0535442 0.01235065
-0.046329 0.00192757 -0.00424403 0.00364727 0.05790862 0.04215468
0.04061833 0.03017248 -0.03808379 0.05979197 0.03251123 -0.01618787
-0.05283526 -0.01509981 0.05030754 -0.03224825 0.05769876 -0.01519872
0.02141866 0.01543435 -0.01191425 -0.00674526 0.00728445 0.04265702
0.01254657 0.04424815 -0.05862596 -0.00738266 0.01891772 0.02471734
0.01362135 0.02899224]
Word: is, Vector: [-0.04850127 -0.01817817 -0.01943211 -0.01507875 -0.03522446 0.03017616
0.00195579 -0.03032363 0.0471383 0.01740152 -0.02025871 0.03517399
-0.04072831 -0.01689353 -0.03618398 0.00728186 0.00643327 -0.04072586
0.02850184 0.02287598 0.02504763 0.04877659 -0.0156221 -0.02940094
-0.01005022 0.00579242 -0.03306862 -0.00362998 0.02999207 -0.02017872
0.04102116 0.04162875 -0.0057752 0.03878671 -0.01668419 0.01415582
-0.01787119 0.00202267 -0.0329514 0.00652844 -0.02275511 -0.01437672
0.02438227 -0.0381818 0.01253717 -0.0312217 -0.00204155 0.04164918
0.01921753 0.00964438]
Word: i, Vector: [ 0.04335381 0.00592583 0.0551033 -0.04590617 0.01631795 -0.04812752
0.04417964 -0.00318619 -0.01099156 0.00030646 0.05510231 0.03580425
0.00289193 0.03353943 -0.02868991 0.04636407 -0.00301994 0.02667969
0.00518026 0.03257323 -0.02532974 0.0029622 0.0350619 -0.00119264
0.02978915 -0.0100148 0.03251199 0.00673161 0.03937319 -0.04120999
0.01482028 0.04927919 0.03851033 -0.04100788 -0.00907034 0.02863063
0.02633214 0.04849904 -0.03800495 0.00345759 0.00713671 -0.01573475
0.0277383 0.00490151 0.02959421 0.01058907 0.05890618 0.05071354
0.00069239 0.0139456 ]
Word: love, Vector: [ 0.02124948 0.03345285 -0.03899518 0.04016155 0.01410933 0.00758267
-0.00921821 -0.03663526 -0.03631829 -0.03561198 -0.01100456 0.03640453
-0.01154441 -0.01214306 -0.00158718 -0.0030126 -0.00050348 -0.03853129
-0.03771586 0.006332 0.03172655 0.02283206 0.0449295 -0.03155522
0.03132889 0.03243085 -0.01863536 -0.01228887 0.00677787 0.01169837
-0.02064442 -0.01630308 0.00475659 -0.03805356 0.04366293 -0.00203237
0.03167215 -0.00051814 -0.01819641 0.02029561 -0.0150766 0.03840049
-0.0011336 0.01110033 -0.05739464 -0.03759264 0.00992759 0.03664881
-0.03737824 0.04481837]
Word: machine, Vector: [ 0.01256744 0.05493961 0.05156352 -0.05254603 0.05222714 -0.02787161
0.00884341 0.05859774 -0.01706602 0.05661383 0.02399637 -0.02899282
-0.01091578 0.02853572 -0.05435005 0.02165839 -0.02526646 -0.02812575
-0.05316673 0.00179729 -0.05648367 0.0175765 0.05152157 0.0199957
0.03839891 -0.0121992 -0.00552106 0.05587437 -0.00706059 -0.02177661
-0.00821144 0.0303122 0.05555865 0.00988145 0.01431244 0.03425541
-0.03562244 0.03591005 -0.02323821 -0.0334999 -0.03741898 0.0082142
0.04124561 0.01959193 0.01364672 -0.01761863 0.02024727 0.01130799
0.0123606 0.03641927]
Word: deep, Vector: [-0.05665746 -0.04792808 -0.05014217 0.03106089 -0.04355281 -0.03822718
-0.02590954 0.02262733 0.01333261 0.03697808 -0.00640199 0.02848412
-0.04587119 -0.04111011 -0.02802585 0.0494941 0.00170043 -0.0509933
-0.01448047 -0.03505946 -0.01690938 -0.03925737 -0.036212 -0.05171141
0.02333118 -0.04062278 -0.05268471 -0.00650161 0.0005835 0.02760867
0.01664205 0.03617666 -0.01858392 0.03185634 -0.00503922 -0.04093894
-0.05554398 0.01787306 0.03889327 -0.0032624 -0.01550952 -0.02787351
0.01413828 -0.03148517 -0.00636994 0.0135811 0.04020449 -0.01036272
0.04809713 0.0139291 ]
Word: amazing, Vector: [-0.03804016 0.02857452 0.00322663 -0.03340072 -0.0381109 0.03038805
0.02846212 0.02931504 -0.01197881 0.01147577 -0.03653805 0.02703354
-0.04092281 -0.02101623 -0.00295804 -0.01291655 0.03330976 -0.03112418
-0.01069261 0.0437712 -0.02810412 0.02468324 -0.01412242 0.01921122
-0.00858794 0.04074717 -0.01255008 0.00473223 0.00847079 -0.04750414
0.00631876 0.02589377 0.04084728 0.00478772 0.04552785 -0.02180728
0.02622463 -0.02766575 -0.04723873 -0.00096275 -0.01052775 0.0362574
0.00161303 -0.01221719 -0.05281541 -0.03373772 -0.02718632 -0.00968645
0.00077633 -0.02636372]
Word: natural, Vector: [ 0.00922634 -0.00767834 -0.04555733 -0.03261197 -0.04359912 0.00299391
0.02118976 -0.02598096 -0.04075725 0.00434979 0.03954858 0.01491208
0.03670142 -0.01688498 0.00044547 -0.00746624 -0.00594356 0.00970965
-0.02324747 0.01481842 0.04039751 0.03627228 0.04142744 -0.03160152
0.02938914 0.02712004 -0.03241567 0.04020814 -0.01078338 0.03352029
0.04328843 0.00454491 0.02176973 0.01938275 -0.00989198 0.02724446
-0.05303999 -0.02890654 -0.00905713 -0.03527548 0.01366975 -0.01083682
0.05119205 0.03923048 -0.02052928 -0.02876336 0.006407 -0.0167786
-0.03914975 -0.02305199]
Word: language, Vector: [ 0.00847483 -0.05559875 -0.05925155 -0.0355204 -0.05359524 -0.00608283
0.00320329 0.00066788 0.03430515 0.00894064 0.00096238 -0.02127819
0.00662573 -0.00953977 0.03618817 0.02098873 -0.03547039 0.02478442
0.03772367 0.05674538 -0.01768715 0.05667575 -0.01954747 -0.05168736
0.01183402 0.03491602 -0.01471148 0.02342941 0.01461189 0.03154018
0.02979536 0.04334725 0.04547536 0.03179631 0.02813049 0.05590999
-0.01982505 -0.04677211 0.00529861 0.03856302 -0.01671158 0.02163729
0.03889727 -0.0004473 -0.05948495 -0.03651699 -0.01727288 0.04068163
0.01857873 -0.029497 ]
Word: processing, Vector: [ 0.01042999 -0.03210147 -0.00543597 -0.05209697 -0.03351552 0.04402945
0.04770755 -0.05743022 -0.00061579 -0.02664622 -0.04397092 0.01692001
0.01631451 -0.04232658 -0.01666508 -0.01825891 0.02082774 -0.00202723
-0.03656881 0.0267873 0.01689488 -0.00137658 -0.00539987 -0.04710834
-0.03627909 0.0566317 -0.01942493 -0.02341237 0.02579835 -0.0117269
0.03720793 0.03990724 0.05278151 0.02369007 0.01840199 0.04370767
-0.05255595 -0.03147706 0.03517626 0.03002381 -0.03626465 0.02583629
0.02560278 0.04363503 -0.02960237 -0.02247534 0.02859247 -0.00505896
0.04147723 0.0269079 ]
Word: a, Vector: [ 0.00220123 -0.05223196 0.02945516 0.01754405 -0.050515 0.02510117
-0.02950761 -0.03056652 0.00088651 0.0317716 0.03254192 -0.00572918
-0.02531261 0.02860654 0.04450737 0.05419686 0.02541122 0.02225946
-0.05497834 -0.04607365 0.03371739 -0.00586361 0.01924774 0.03487618
-0.02686865 0.04013187 -0.01317471 -0.04139041 -0.00958664 0.02934398
-0.05417831 0.02288332 0.01579129 -0.01211508 0.02824134 -0.03828157
-0.00427263 0.03503546 0.03345916 -0.03407149 0.01519595 0.04121489
0.04955248 0.00572149 -0.01740555 -0.0336564 -0.05183009 -0.02940635
-0.02089442 -0.03992337]
Word: fascinating, Vector: [-0.03372697 -0.00548039 0.01430078 -0.02538841 0.01516997 -0.0042397
-0.01453294 -0.05913377 0.05197076 0.01240273 0.01846839 0.02746565
0.02233218 -0.05126255 -0.0090773 0.0167577 -0.03819533 0.00548373
0.02731238 0.05524713 0.04552881 0.01024329 0.00757937 -0.02946985
-0.02368664 0.03069277 -0.02440017 0.00595432 0.04770452 0.02805043
-0.02024739 0.00269523 -0.04128293 -0.02501465 -0.04641492 0.01521988
0.02474929 0.00230619 -0.04900512 -0.01796082 -0.0155594 -0.03421747
0.02724069 -0.0107807 -0.00976059 0.01740771 -0.02639746 0.016172
0.05962607 0.05553653]
Word: field, Vector: [ 0.00322471 -0.03018627 0.01437822 0.03609617 -0.03801164 -0.01510745
0.03879017 -0.01652177 0.01412087 -0.02735655 -0.02743557 -0.03221446
-0.05086558 0.03224384 0.02504818 0.03592138 -0.02861246 0.01564104
-0.02967609 -0.0399616 -0.01911848 -0.03690275 0.02965165 0.0108167
-0.04724862 -0.00419907 0.02764304 -0.02756451 -0.05550781 0.01215103
-0.01837657 0.04681823 0.01622975 0.04263613 0.00836677 0.01799515
-0.00060863 -0.00125658 0.01633861 0.02095414 -0.00010253 -0.00389527
0.015011 -0.03505156 -0.00920992 -0.01243817 -0.04472306 -0.04413529
-0.03762042 -0.03157695]
Process finished with exit code 0
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-08-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号