Llama3.1 部署本地知识库应用
原创
Llama3.1 部署本地知识库应用
原创
geru
修改于 2024-07-26 18:05:23
修改于 2024-07-26 18:05:23
一. 环境介绍
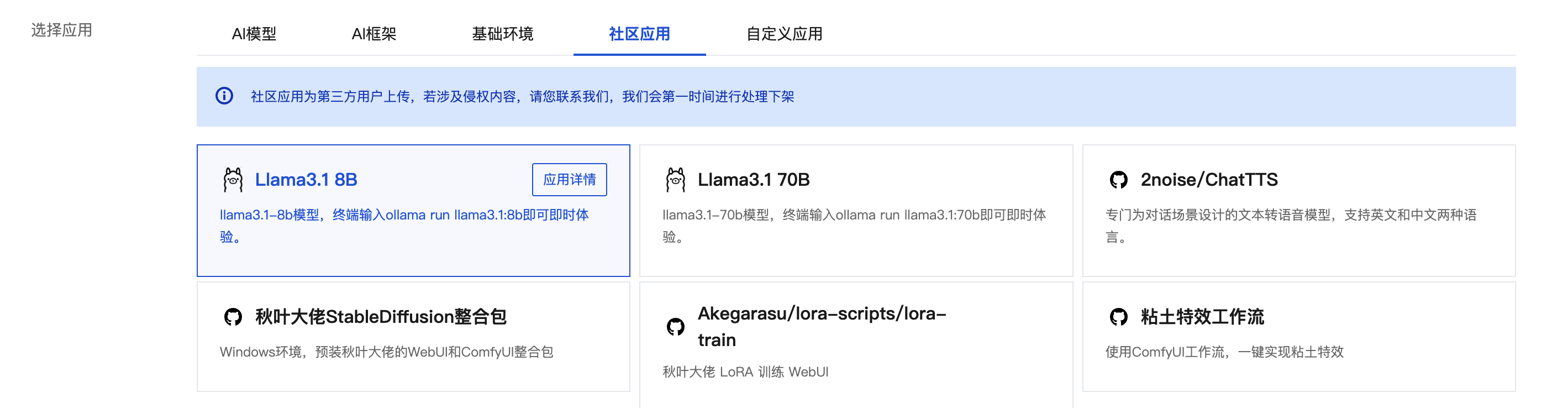
高性能应用服务 HAI 拥有丰富的预装应用,可以将开源社区的前沿模型快速转化为您专有的部署实践,一键拉起,即开即用。现已支持在HAI购买页的社区应用中,找到Llama 3.1等应用的入口,简单选型后,即可一键启动推理服务。
Chatchat项目介绍
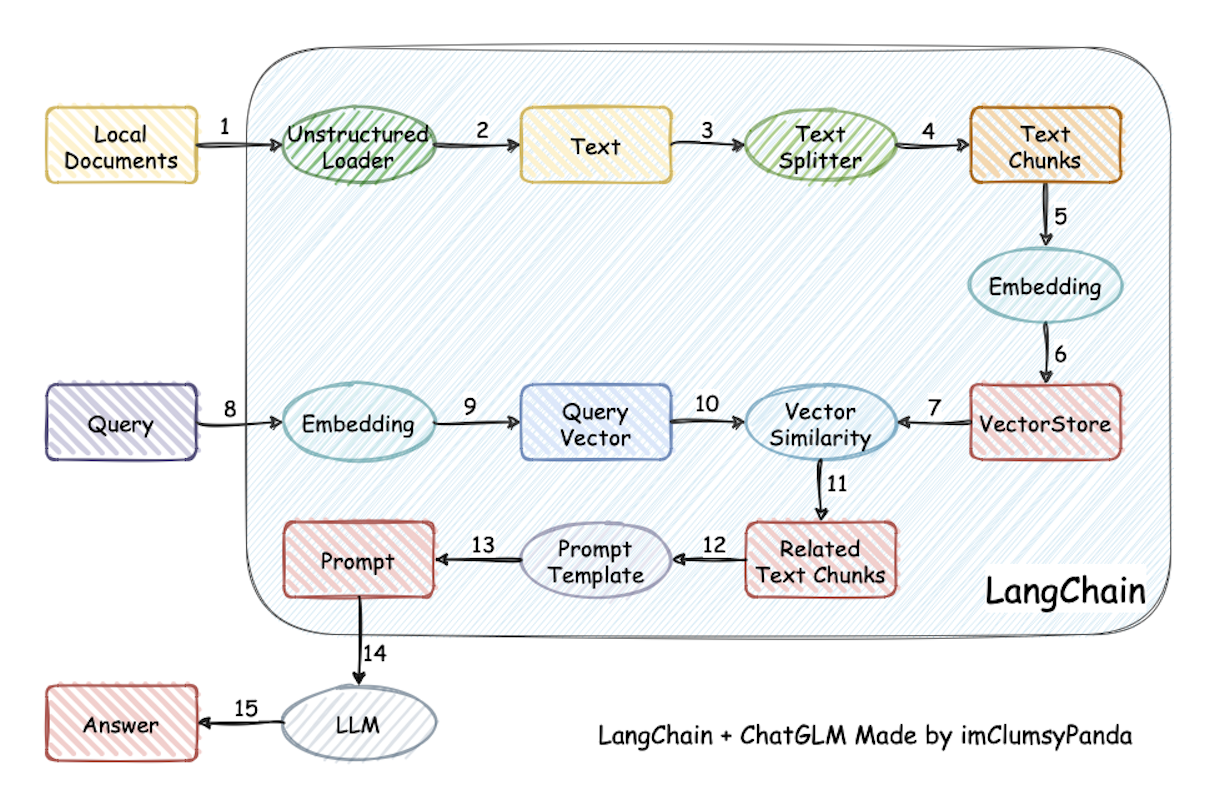
该项目利用langchain思想,实现了基于本地知识库的问答应用。支持市面上主流的开源 LLM、 Embedding 模型与向量数据库,可实现全部使用开源模型离线私有部署。与此同时,该项目也支持 OpenAI GPT API 的调用。
项目的实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
部署完成的效果展示
二. 使用说明
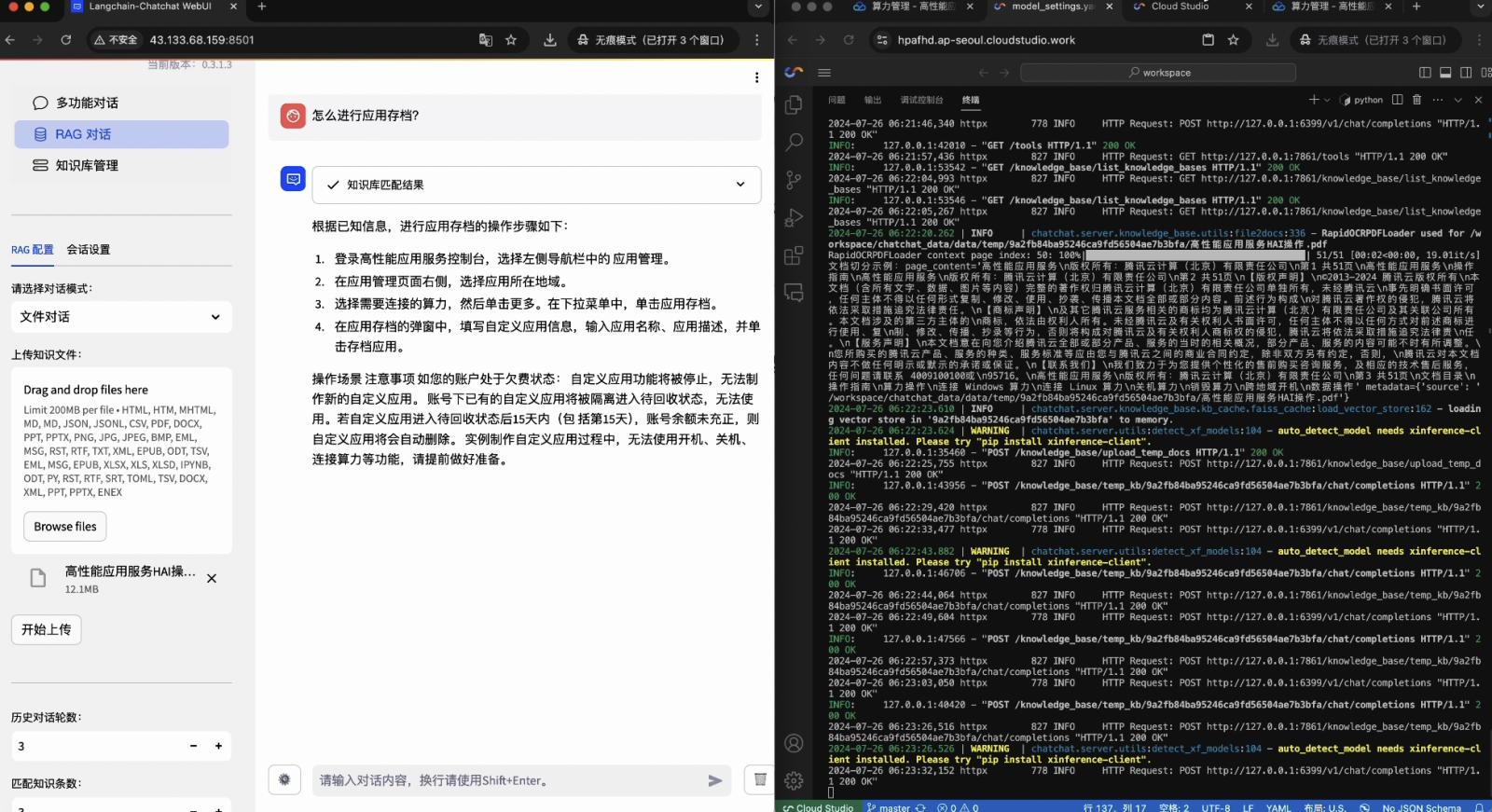
1. 进入HAI购买页,选择“Langchain-Chatchat-llama3.1”社区应用并创建实例。实例创建完成后,点击算力连接方式,选择jupyterlab并进入terminal,将下方的代码复制粘贴到terminal中,按回车执行。当看到下图所示内容后,代表应用启动完成。
export CHATCHAT_ROOT=/root/chatchat_data
chatchat init
chatchat kb -r
chatchat start -a
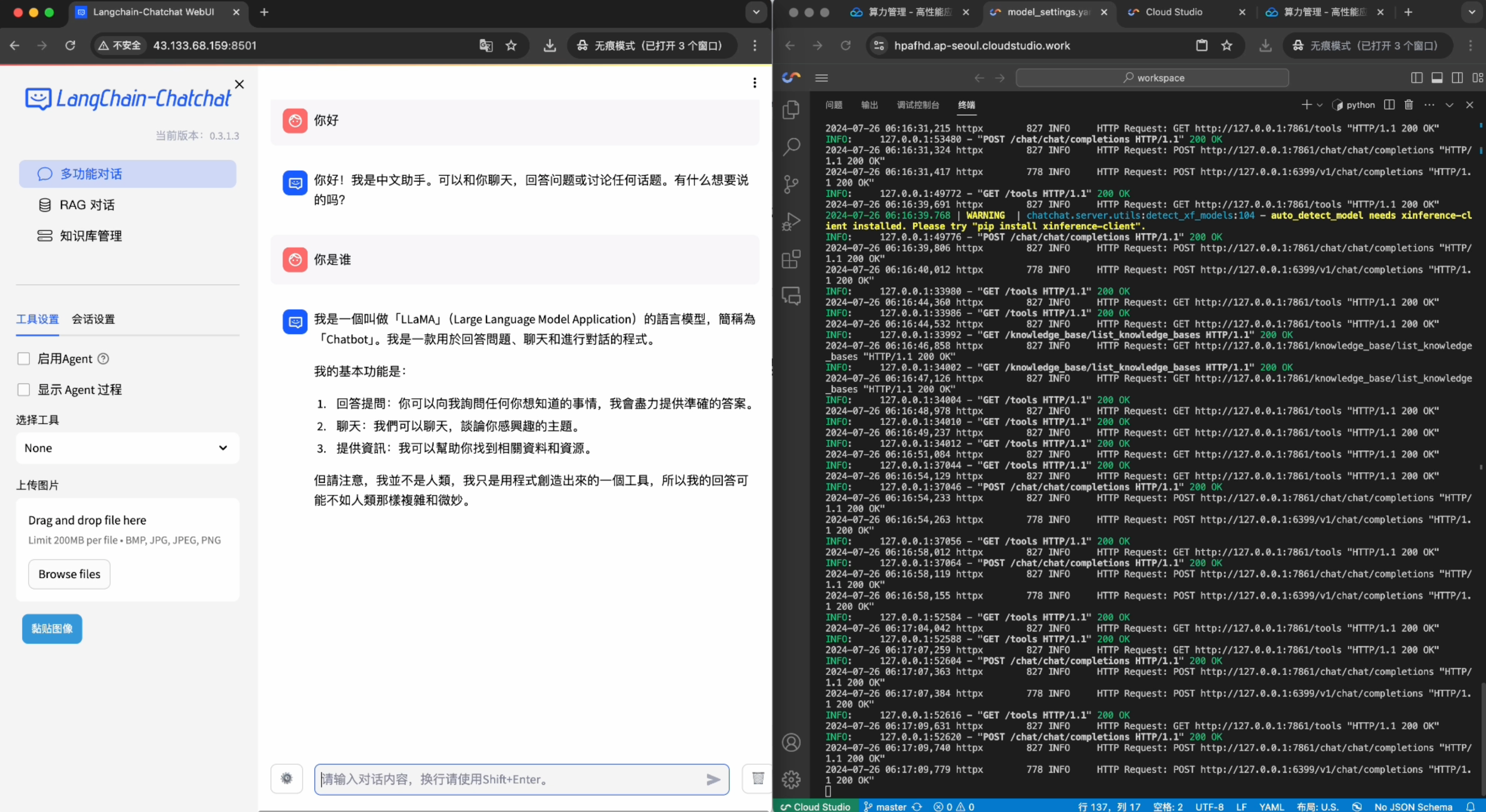
2. 使用实例公网ip,代替URL中的0.0.0.0,粘贴到导航栏即可访问。可按需上传本地的文件进行问答交互。
附录:在HAI上用llama3.1的几种姿势
模型测试
可以基于HAI中基础的llama3.1环境,快速测试模型问答性能。
微调(Fine-tuning)
通过在特定任务或领域的数据上进一步训练llama3.1模型,使其更适合特定应用。例如,可以使用特定领域的文本数据来微调模型,使其在该领域的表现更好。
挂载RAG(Retrieval-Augmented Generation)
结合信息检索技术和生成技术,使模型在回答问题时可以检索到相关的信息并生成更准确的回答。这种方法通常用于需要实时或准确信息的任务。
集成外部知识库
将模型与外部知识库(如知识图谱)结合,使其能够利用结构化数据提供更准确和全面的回答。
更多
基于llama3.1开发agent,以api的形式在HAI中部署,并接入您的app,助力应用开发。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号