CPU面试题Q7:如何处理内存中的数据依赖?

CPU面试题Q7:如何处理内存中的数据依赖?

tech life
发布于 2024-07-12 19:22:44
发布于 2024-07-12 19:22:44
要处理CPU乱序调度中的内存数据依赖,通常涉及两个步骤:
1.计算内存访问的有效地址
2.检查所有未处理完的load/store的地址,并确保冲突的load/store不能乱序执行
A Load / Store Processing Model
load/store处理模型,如下图所示。
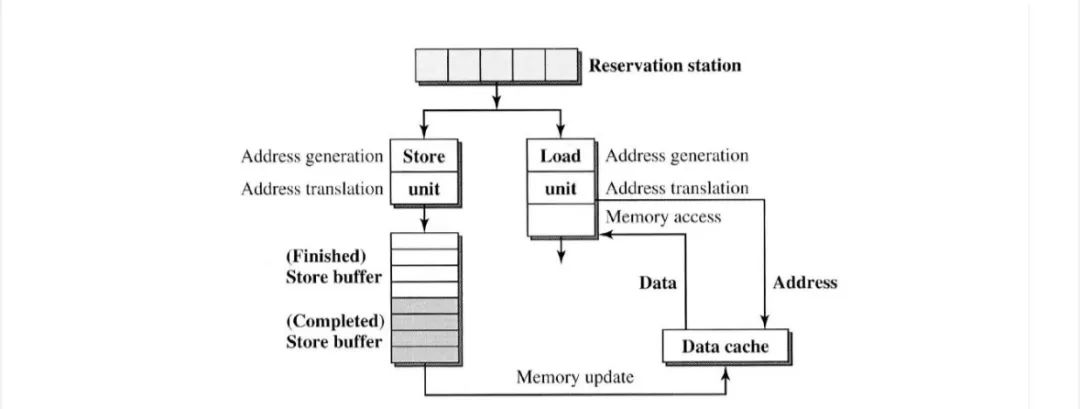
load和store指令首先发给reservation station ,然后发送到load单元或store 单元。
在store单元中,store 指令首先经过有效的地址计算和地址转换,然后驻留在“Finished ”store 缓冲区中。 “completed ”store 缓冲区中的store 指令最终会提交到内存中。
同样,load指令首先通过地址生成和翻译,并最终读取数据cache 以从内存中获取数据。
我们可以做出的一个假设是,store 指令需要按程序顺序完成,因此WAW数据依赖性是默认强制执行的。从本质上讲,处理数据依赖项可以简化为处理load/store 依赖项(RAW和WAR)。
Handling Data Dependencies with In-order Load / Store Dispatch
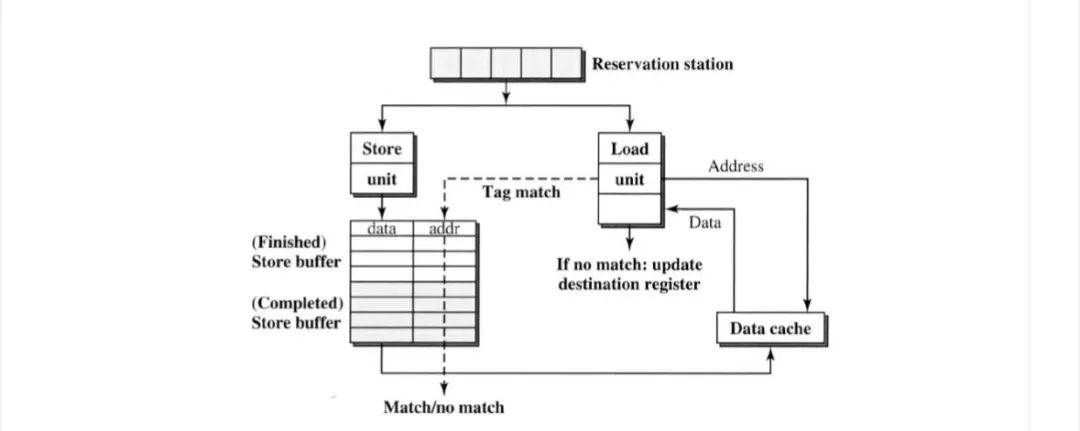
最直接的解决方案是按程序顺序向公共reservation station 发出load/store 指令,并从reservation station 按FIFO顺序发送。只有当store 缓冲区为空时,才能发送load。然而,load指令的延迟很长,不可预测。尽早执行load至关重要。
改进的方案是支持不同地址的load bypass ,如果store 缓冲区中有地址匹配,则stall load指令。因此,不同地址的load可以继续进行。
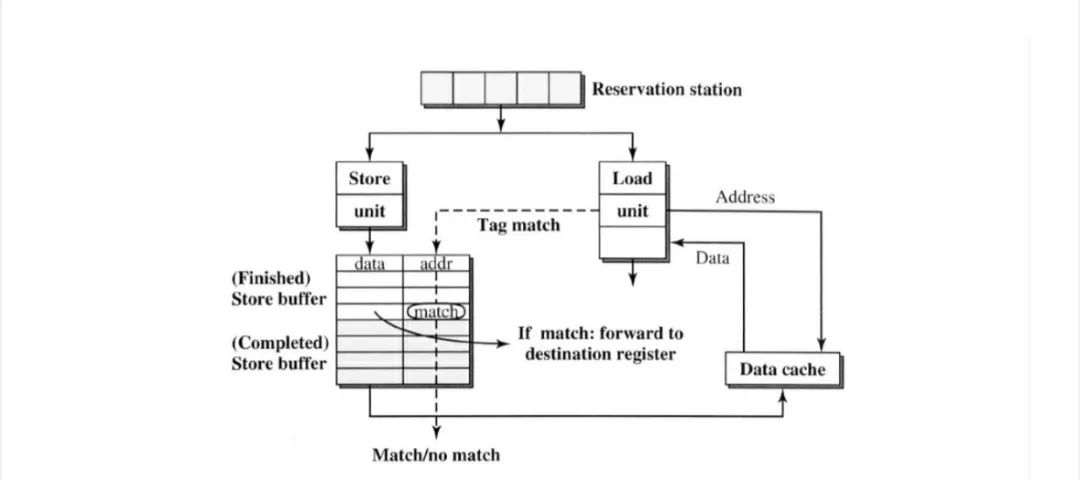
为了进一步加快load。如果存在地址匹配,但store buffer数据不可用,则load stall;如果存在地址匹配和store 数据可用,则将数据直接forward 到load。由于load直接从store buffer接收数据,因此可以尽早执行load指令,并避免数据cache 访问。
Handling Data Dependencies with Out-of-order Load / Store Dispatch
如果我们乱序调度load/store,可以在store之前发放load。由于无法检查地址匹配,因此存在潜在的RAW依赖关系。
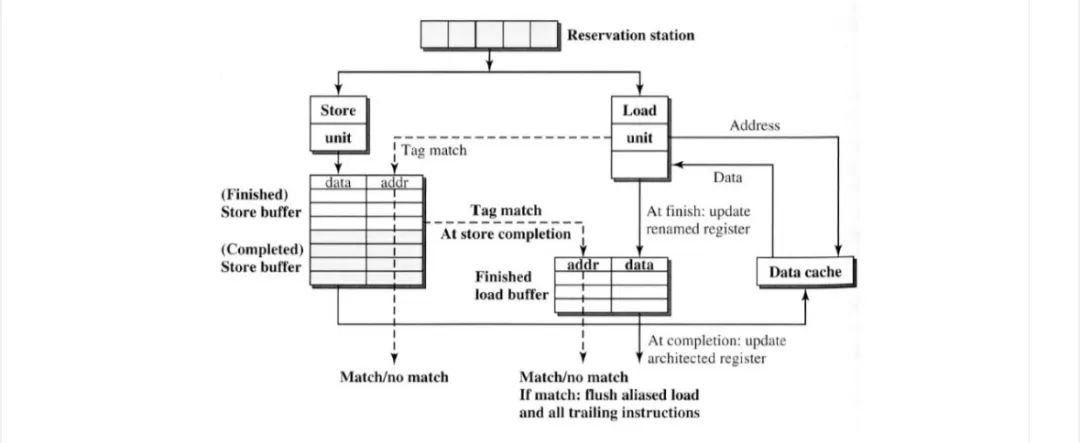
与store指令类似,如果从reservation station 发送的store在“finished ”load buffer中发现匹配的load,则应刷新所有指令。
这种放松也引入了可能的WAR数据依赖性。load地址可能与后续store的地址匹配,因此会触发不正确的数据forward 。一个简单的解决方案是stall 匹配地址的“finished ” store的load,仅具有匹配地址的“completed ”store上数据forward 给load。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-12,如有侵权请联系 cloudcommunity@tencent.com 删除
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号