SimD:自适应相似度距离策略提升微小目标检测性能 !


免责声明
凡本公众号注明“来源:XXX(非集智书童)”的作品,均转载自其它媒体,版权归原作者所有,如有侵权请联系我们删除,谢谢。

微小目标检测成为计算机视觉中最具挑战性的任务之一,这是由于物体尺寸有限和信息不足所致。标签分配策略是影响目标检测准确性的关键因素。 尽管有一些针对微小物体的有效标签分配策略,但它们大多数关注降低对边界框的敏感性以增加正样本数量,并且需要设置一些固定的超参数。 然而,更多的正样本并不一定会导致更好的检测结果,实际上,过多的正样本可能导致更多的假阳性。 在本文中,作者介绍了一种简单但有效的策略,名为相似度距离(SimD),用于评估边界框之间的相似度。这个提出的策略不仅考虑了位置和形状的相似性,还自适应地学习超参数,确保它能够适应不同数据集和同一数据集中的各种物体大小。 作者的方法可以简单地应用于常见的基于 Anchor 点的检测器中,替代标签分配和Non Maximum Suppression(NMS)中的IoU。 在四个主流微小目标检测数据集上的大量实验证明了作者方法的高性能,特别是在AI-TOD上,对于非常微小的物体,比现有技术水平高出1.8 AP点和4.1 AP点。 代码可在以下链接获取:https://github.com/cszzshi/SimD。
I Introduction
随着无人机技术和自动驾驶的普及,目标检测在日常生活中的应用变得越来越广泛。通用目标检测器在准确性和检测速度方面取得了显著进展。例如,YOLO系列的最新版本YOLOv8,在COCO检测数据集上的平均平均精度(mAP)达到了53.9%,当在NVIDIA A100 GPU上使用TensorRT实现时,仅需要3.53毫秒就能检测图像中的目标。然而,尽管通用目标检测器取得了显著的进展,当它们直接应用于小目标检测任务时,其准确性会急剧下降。
在最近的小目标检测调查中,程等人[1]提出根据它们平均面积将小目标分为三类(极端小、相对小和普通小)。小目标检测面临的两个主要挑战是信息丢失和正样本缺乏。有许多方法可以提高小目标检测的准确性,如特征融合、数据增强和超分辨率。
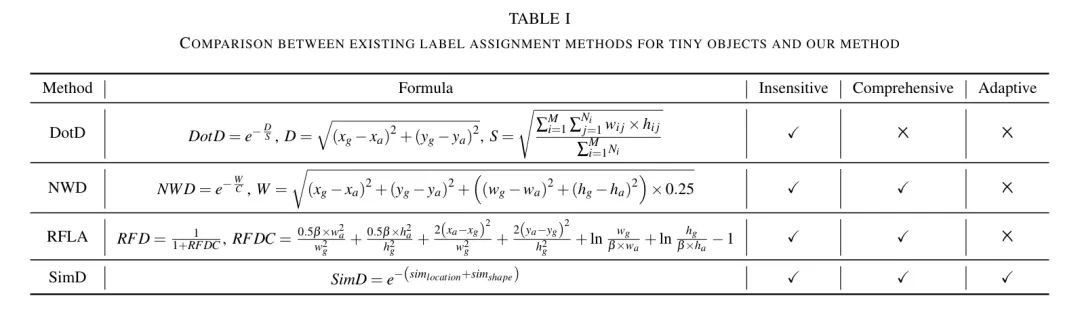
由于足够数量且高质量的阳性样本对目标检测至关重要,标签分配策略是影响最终结果的核心因素。边界框越小,IoU指标[2]的敏感性越高,这是为什么无法为小目标标记出与一般目标一样多的阳性样本的主要原因。图1展示了传统基于 Anchor 点和 Anchor-Free 点指标与作者的SimD指标的简单比较。

当前关于小目标标签分配策略的研究主要集中在降低对边界框尺寸的敏感性上。从这个角度来看,徐等人[2]提出使用点距(DotD)作为替代IoU的分配指标。后来,NWD[3]和RFLA[4]被提出,尝试将 GT 值和 Anchor 点建模为高斯分布,然后使用这两个高斯分布之间的距离来评估两个边界框。实际上,这些方法在标签分配方面取得了重大进步,但它们可能没有考虑到一些问题。
首先,这些方法中的大多数侧重于降低对边界框尺寸的敏感性,从而增加阳性样本的数量。然而,正如作者所知,过多的阳性样本可能会对目标检测器产生不利影响,导致许多假阳性。
其次,这些评估指标的本质是测量边界框之间的相似性。对于基于 Anchor 点的方法,考虑的是 GT 值与 Anchor 点之间的相似性。这种相似性包括两个方面:形状和位置。然而,有些方法只考虑边界框的位置,其他方法考虑形状和位置,但它们也有一个需要选择的超参数。最后,尽管小目标检测数据集中的目标大小趋于相似,但不同目标之间的尺度仍然存在差异。例如,AI-TOD数据集中的目标大小从2到64像素不等。VisDrone2019数据集的差异更为明显,其中包含小目标和一般大小的目标。实际上,目标越小,获取阳性样本越困难。不幸的是,大多数现有方法可能没有足够关注这个问题。
在本文中,为了解决这些问题,作者引入了一种新的评估指标来代替传统的IoU,作者的方法的处理流程如图2所示。本文的主要贡献包括以下内容:
- 作者提出了一种简单但有效的策略,名为相似性距离(SimD),用于评估两个边界框之间的关系。它不仅考虑了位置和形状的相似性,而且能够有效地适应不同数据集和同一数据集中的不同目标大小,无需设置任何超参数。
- 大量实验证明了作者方法的有效性。作者使用几种通用目标检测器,并简单地将基于IoU的分配模块替换为基于作者提出的SimD指标的模块,在这样做的过程中,作者在四个主流的小目标检测数据集上取得了最先进的表现。
II Related Work
近年来,目标检测技术在各个行业中的应用变得越来越广泛。这项技术提供了极大的便利。例如,通过识别遥感图像中的地面物体,可以快速进行救援行动。随着深度学习技术的发展,特别是ResNet[5]的引入,检测的准确性和速度显著提高。
通用目标检测器可以分为两类:单阶段和双阶段检测器。双阶段检测器首先生成一系列 Proposal 区域,然后确定物体的位置和类别。这类算法包括R-CNN[6]、Fast R-CNN[7]和Faster R-CNN[8]。单阶段检测器的结构更简单,它们可以直接从输入图像输出物体的坐标和类别。一些经典的单阶段检测器包括YOLO[9]和SSD[10]。
Tiny Object Detection
尽管深度学习技术在目标检测方面取得了重大进展,但当要检测的目标非常小的时候,检测精度会急剧下降。小物体通常被定义为尺寸小于某个阈值值的物体。例如,在Microsoft COCO [11]中,如果一个物体的面积小于或等于1024,它就被视为小物体。然而,在许多情况下,作者关注的物体实际上比上述定义要小得多。例如,在AI-TOD数据集中,一个物体的平均边长仅为12.8像素,远小于其他数据集。
如前文[1]所述,由于关注的小物体尺寸极小,微小型目标检测面临三大挑战。首先,大多数目标检测器在特征提取时使用降采样,这对于小物体来说将导致大量信息丢失。其次,由于它们包含的有效信息量有限,小物体很容易受到噪声的干扰。最后,物体越小,对边界框[2]变化的敏感性就越高。因此,如果作者使用传统的标签分配度量方法,如IoU、GIoU [12]、DIoU [13]和CIoU [13],进行目标检测,对于小物体获得的正向样本数量将非常少。
已经提出了许多方法和改进措施来提高微小型目标检测的准确性和效率。例如,从数据增强的角度,Kisantal等人[14]提出通过复制小物体、随机变换复制品,然后将结果粘贴到图像中的新位置来增加训练样本的数量。
Label Assignment Strategies
标签分配策略在目标检测中起着重要的作用。根据每个标签是严格负样本还是严格正样本,这些策略可以分为硬标签分配策略和软标签分配策略。在软标签分配策略中,根据计算结果为不同的样本设置不同的权重,例如GFL [15],VFL [16],TOOD [17]和DW [18]。硬标签分配策略可以根据指定正负样本的阈值是否固定进一步分为静态和动态策略。静态标签分配策略包括基于IoU和DotD [2]指标以及RFLA [4]的策略。动态标签分配策略的例子包括ATSS [19],PAA [20],OTA [21]和DSLA [22]。从另一个角度来看,标签分配策略可以分为基于预测和无预测的策略。基于预测的方法根据 GT 框和预测框之间的关系为样本分配正/负标签,而无预测的方法仅根据 Anchor 框或其他现有信息分配标签。
Label Assignment Strategies for Tiny Objects
尽管在目标检测的标签分配策略上已有许多研究,但这些策略大多数是针对传统数据集设计的,专门针对小尺寸物体的则很少。当这些传统的标签分配策略直接用于小目标检测时,其准确度会显著下降。截至目前,专门为小物体设计的标签分配策略和指标主要包括 FD [23]、DotD [2]、NWD-RKA [24] 和 RFLA [4]。
在 FD 中,首先降低阈值值(从0.5降至0.35)以获得更多对于 GT 值的正样本,然后进一步降低至0.1以获得那些在第一次阈值降低时未被处理的 GT 值的正样本。然而,FD 同样使用传统的IoU指标来计算 GT 值与 Anchor 框之间的相似性。为了克服IoU指标的弱点,引入了新颖的DotD公式以降低对边界框尺寸的敏感性。基于这个指标,可以为 GT 值获得更多的正样本。在 NWD-RKA 中,引入了归一化的Wasserstein距离来替代IoU,并使用基于排名的策略将前k个样本分配为正样本。RFLA 从感受野的角度探索 GT 值与 Anchor 框之间的关系,在此基础上,将 GT 值和 Anchor 框建模为高斯分布。然后,基于Kullback-Leibler散度(KLD)计算这两个高斯分布之间的距离,用它来替代IoU指标。
III Method
Similarity Distance Between Bounding Boxes
在标签分配中,最重要的步骤之一是计算反映不同边界框之间相似性的值。特别是对于基于 Anchor 点的标签分配策略,在分配标签之前,必须量化 Anchor 点与真实值之间的相似性。
常见的标签分配指标,如IoU、GIoU [12]、DIoU [13] 和 CIoU [13],通常基于 Anchor 点与真实值之间的重叠。这些指标存在一个严重问题,即如果重叠为零,这对于小物体来说通常是情况,这些指标可能变得无效。一些更合适的方法使用基于距离的评估指标,甚至使用高斯分布来模拟真实值和 Anchor 点,例如DotD [2],NWD [3]和RFLA [4]。作者在表1中从三个角度简单比较了现有指标与作者的SimD指标。例如,DotD只考虑位置相似性,可能无法适应数据集中不同物体大小,因此它不够全面和适应性强。NWD和RFLA不是自适应的,因为它们分别需要设置超参数和。遵循现有方法,作者考虑提出一个无需任何超参数的自适应方法。
在本文中,作者引入了一种名为相似性距离(SimD)的新指标,以更好地反映不同边界框之间的相似性。相似性距离定义如下:
其中 和 如下所示:
SimD 包含两部分,位置相似性 和形状相似性 。如 (2) 式所示,(, ) 和 (, ) 分别代表真实值和 Anchor 框的中心坐标,, , , 代表真实值和 Anchor 框的宽度和高度,公式的主要部分是真实值和 Anchor 框中心点之间的距离,类似于 DotD 公式 [2]。不同之处在于,作者使用两个边界框的宽度和高度乘以相应的参数来消除不同大小边界框之间的差异。这个过程类似于归一化的思想。这也是作者的度量可以轻松适应数据集中不同目标大小的原因。 (3) 式中的形状相似性类似于 (2)。
两个归一化参数的定义如(4)和(5)所示。由于它们非常相似,作者以(4)中的参数 为例进行进一步讨论。 是整个训练集中每张图像上所有 GT 值和 Anchor 框在 方向上的距离与两个宽度之和的平均比率。 表示训练集中的图像数量, 和 分别表示第 张图像中的 GT 值和 Anchor 框的数量。 和 分别代表第 张图像中第 个 GT 值和第 个 Anchor 框中心点的 坐标。 和 分别代表第 张图像中第 个 GT 值和第 个 Anchor 框的宽度。由于这两个归一化参数是基于训练集计算的,作者的度量标准也可以自动适应不同的数据集。
为了便于标签分配,作者使用指数函数将SimD的值缩放到零到一之间。如果两个边界框相同,根号下的值将为零,因此SimD将等于一。如果两个边界框差异很大,这个值将会非常大,所以SimD将趋近于零。
Similarity Distance-based Detectors
SimD这一在(1)中定义的新指标能够很好地反映两个边界框之间的关系,并且易于计算。因此,在需要计算两个边界框之间相似性的场景中,它可以替代IoU。
基于SimD的标签分配。 在传统的目标检测器中,例如Faster R-CNN [8],Cascade R-CNN [25]和DetectoRS [26],RPN和R-CNN模型的标签分配策略是MaxIoUAssigner。MaxIoUAssigner考虑三个阈值:一个正样本阈值,一个负样本阈值和一个最小正样本阈值。与 GT 值的IoU高于正样本阈值的 Anchor 为正样本,低于负样本阈值的为负样本,而介于正负样本阈值之间的则被忽略。对于小目标检测,Xu等人引入了RKA [24]和HLA [4]标签分配策略,它们不使用固定阈值来划分正负样本。在RKA中,简单地将与 GT 值相关的top-k Anchor 选为正样本,这种策略可以增加正样本的数量,因为正标签的分配不受正样本阈值的限制。然而,引入太多低质量的正样本可能会导致检测准确度下降。
在本文中,作者遵循传统的MaxIoUAssigner策略,直接使用SimD替代IoU。正样本阈值、负样本阈值和最小正样本阈值分别设置为0.7、0.3和0.3。作者的标签分配策略称为MaxSimDAssigner。
基于SimD的NMS。 非极大值抑制(NMS)是后处理中最重要的组成部分之一。其目的是通过仅保留最佳检测结果来消除被重复检测到的预测边界框。在传统的NMS过程中,首先计算具有最高分数的边界框与其他所有边界框之间的IoU。然后,将IoU高于某个阈值的边界框消除。考虑到SimD的优点,作者可以直接用它作为NMS的度量标准,替代传统的IoU度量。
IV Experiments
为了验证作者提出方法的可靠性,作者设计了一系列实验,包括将传统目标检测器应用于几个开源的小目标检测数据集。
Datasets
微小目标检测数据集主要有两种类型:一种仅包含小目标,例如AI-TOD [27],AI-TODv2 [24]和SODA-D [1],另一种同时包含小目标和中等大小目标,例如VisDrone2019 [28]和TinyPerson [29]。
AI-TOD. AI-TOD(空中图像中的微小目标检测)是一个航空遥感小目标检测数据集,旨在解决空中图像目标检测任务可用的数据集不足的问题。它包含28,036张图像和700,621个目标实例,分为八个类别,并带有精确的标注。由于其目标实例极其微小(平均大小仅为12.8像素),因此可以有效地用于测试微小目标检测器的性能。
SODA-D. SODA(小目标检测数据集)系列包括两个数据集:SODA-A和SODA-D。SODA-D是从MVD [30]收集的,包含从街道、高速公路和其他类似场景捕获的图像。SODA-D [1]中有25,834个极其微小的目标(面积从0到144不等),使其成为微小目标检测任务的一个出色的基准。
VisDrone2019. VisDrone2019是VisDrone图像中目标检测挑战的数据集。为了这次竞赛,一架无人驾驶飞机在不同地点、不同高度和角度捕获了10,209张静态图像。VisDrone2019也是一个评估微小目标检测器优秀的数据集,因为它不仅包含极其微小的目标,还包含正常大小的目标。
Experimental settings
在以下的一系列实验中,作者使用了一台配备有一块NVIDIA RTX A6000 GPU的计算机,并基于目标检测框架MMDetection [31] 和 PyTorch [32] 实现了各种模型。作者使用了如Faster R-CNN、Cascade R-CNN和DetectoRS等通用目标检测器作为基础模型,并简单地将MaxIoUAssigner模块替换为作者的SimD分配模块。作者的方法可以有效地适应任何 Backbone 网络和基于 Anchor 点的检测器。遵循主流设置,对于所有模型,作者都使用在ImageNet上预训练的ResNet-50-FPN作为 Backbone 网络,并使用随机梯度下降(SGD)作为优化器,动量为0.9,权重衰减为0.0001。批量大小设置为2,初始学习率为0.005。在训练和测试阶段,RPN Proposal 的数量均为3000。对于VisDrone2019数据集,训练的周期数设置为12,并在第8和第11个周期进行学习率衰减。对于AI-TOD、AI-TODv2和SODA-D,训练周期数设置为24,并在第20和第23个周期进行学习率衰减。对于NMS,作者使用IoU指标,RPN的IoU阈值设置为0.7,而R-CNN的IoU阈值设置为0.5。其他配置方面,如数据预处理和流程,遵循MMDetection中的默认设置。
为了便于与之前的研究结果进行比较,在测试阶段,作者使用了AI-TOD基准评估指标,包括平均精度(AP)、AP、AP、AP、AP、AP 和 AP,用于AI-TOD、AI-TODv2和VisDrone2019。对于SODA-D数据集,作者使用COCO评估指标。
Results
作者针对AI-TOD、AI-TODv2、VisDrone2019和SODA-D数据集设计了四组实验。在每组实验中,作者将RPN模块中的IoU指标替换为作者的SimD指标,并将这个模块与传统目标检测模型结合使用,包括Faster R-CNN、Cascade R-CNN和DetectoRS。
在AI-TOD上的结果展示在表2中,作者比较了作者的方法与几种典型的目标检测方法。前七行的检测器是基于两阶段的 Anchor 框检测器,接下来三行和四行分别是基于 Anchor 框的一阶段检测器和 Anchor-Free 框检测器,最后三行展示了作者方法的结果。与Faster R-CNN、Cascade R-CNN和DetectoRS相比,通过在RPN中用SimD替代IoU,作者分别实现了12.8、11.2和11.8点的AP提升。作者还与一些专门针对小目标的检测器进行了比较,即DotD、NWD和RFLA,相对于这些方法,作者的方法分别提升了10.5、5.8和1.8点的AP。
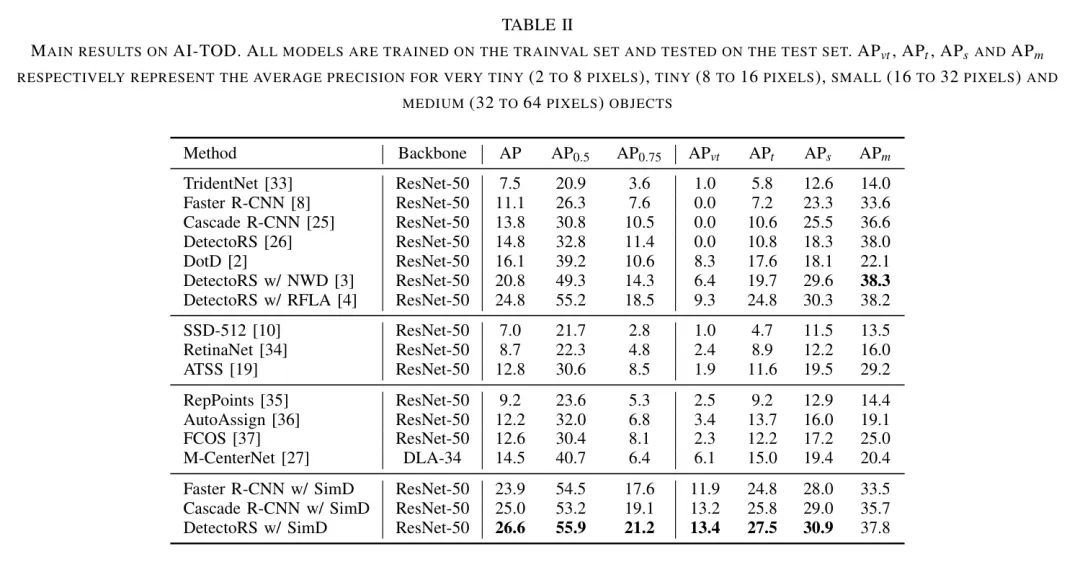
作者方法在小目标上的表现尤其值得关注。由于这些目标的大小极小(非常小指的是2到8像素的尺寸范围),一般目标检测器的AP为0,而使用SimD后,Faster R-CNN、Cascade R-CNN和DetectoRS的AP值分别从0提升到11.9、13.2和13.4点。
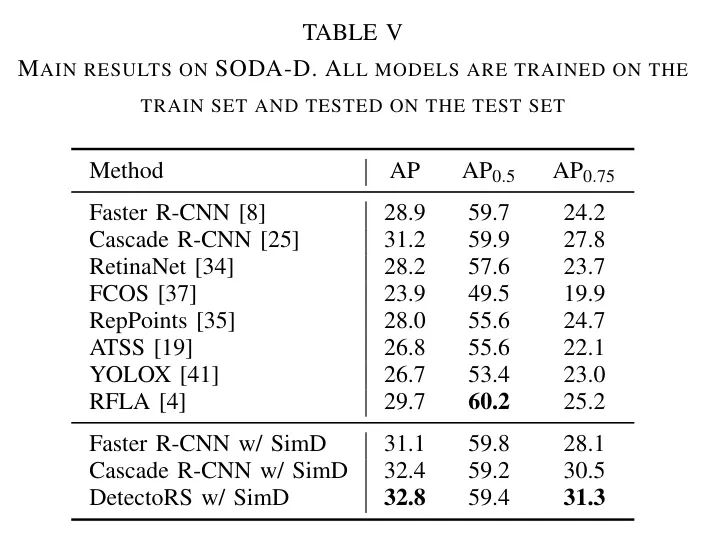
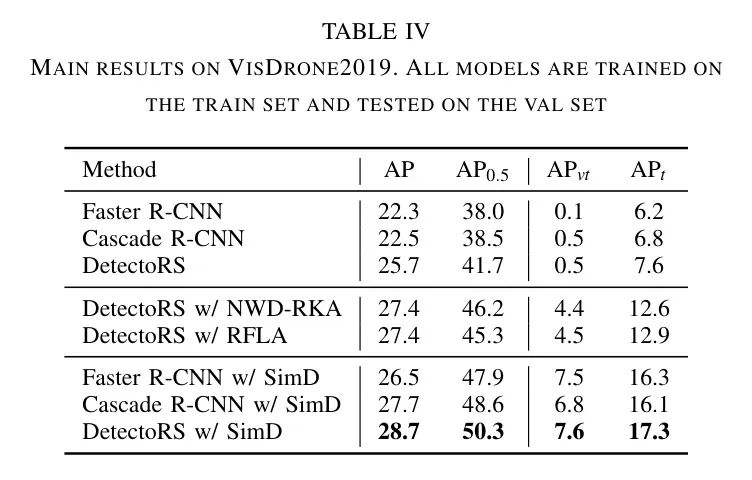
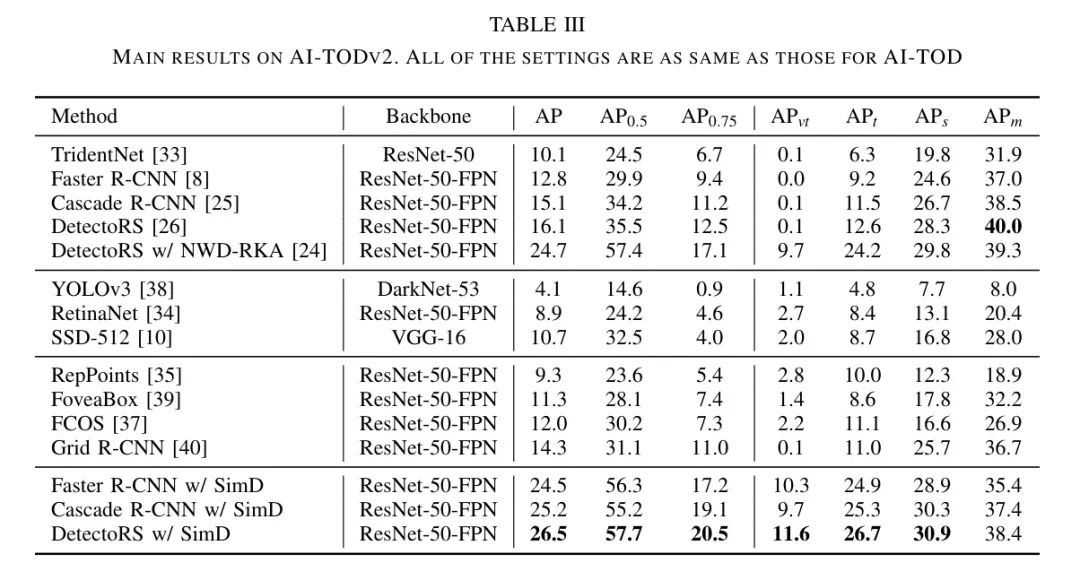
除了AI-TOD,作者的方法在AI-TODv2、VisDrone2019和SODA-D上的表现也最佳,分别如表3、表4和表5所示。在AI-TODv2和SODA-D上,作者方法的AP分别比最佳竞争方法高出1.8和1.6点。在包含小目标和一般大小目标的VisDrone2019上,作者的方法也表现出色,特别是比RFLA提高了1.3点。在表5中,AP与RFLA几乎在同一水平,但AP要高得多,这可能表明作者的方法在检测小目标方面更有能力。图3展示了一些IoU指标与SimD之间的典型视觉比较。作者可以发现,使用作者的方法后,检测性能有了明显的提升。

Ablation Study
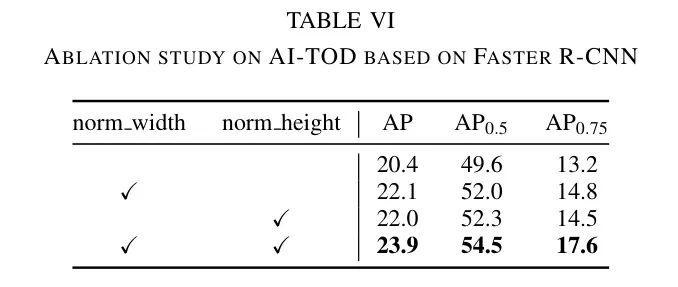
在作者的提出的方法中,一个重要的操作是基于 GT 值和 Anchor 点的宽度和高度进行归一化。为了验证归一化操作的有效性,作者进行了一系列的消融研究。正如表6所示,作者分别比较了不进行归一化、仅归一化宽度、仅归一化高度以及同时归一化宽度和高度的情况。实验结果表明,归一化操作实现了3.5个点的改进,这主要得益于其能够适应数据集中不同大小的目标,并且归一化参数、可以根据不同的数据集自适应调整。
Analysis
从表2到表5的实验结果可以看出,作者的方法在所有四个数据集上均取得了最佳的AP。此外,在AI-TOD、AI-TODv和VisDrone2019数据集上,作者的方法在非常小、小和中小型物体上取得了最佳结果。作者方法的主要成就可以概括为以下三个方面。
首先,作者的方法有效地解决了微小物体准确度低的问题。最根本的原因是,作者的方法充分考虑了两个边界框之间的相似性,包括位置和形状的相似性,因此在使用SimD度量时,只有质量最高的 Anchor 点会被选为正样本。与VisDrone2019相比,AI-TOD和AI-TODv2上的性能提升更为明显,因为这两个数据集中的物体要小得多,这种现象也可能反映了作者方法在微小目标检测上的有效性。
其次,作者的方法能够很好地适应数据集中不同大小的物体。在表4中,作者方法的AP和AP值都是最佳的,并且比其他方法高得多。主要原因是SimD度量在计算边界框之间的相似性时应用了归一化,因此可以消除由不同大小的边界框引起的差异。一些典型的检测结果示于图4中。
最后,作者的方法在四个不同的数据集上取得了最先进的结果。尽管不同数据集中物体的特征各不相同,作者在计算归一化参数时使用了训练集中 GT 值和 Anchor 点之间的关系,使得作者的度量能够自动适应不同的数据集。此外,作者的公式中没有需要设置的超级参数。
V Conclusion
在本文中,作者指出大多数现有方法可能无法自动适应不同大小的目标,并且需要选择一些超参数。
为此,作者提出了一种新颖的评价指标,名为相似距离(SimD),它不仅考虑了位置和形状的相似性,而且可以自动适应不同数据集以及数据集中的不同目标大小。此外,作者的公式中没有超参数。
最后,作者在四个经典的微小目标检测数据集上进行了大量实验,其中作者的方法取得了最先进的结果。
尽管作者提出的SimD指标是自适应的,但它也基于具有固定阈值的现有标签分配策略。
在未来,作者旨在进一步提高微小目标检测的标签分配的有效性。
参考
[1].Similarity Distance-Based Label Assignment for Tiny Object Detection.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号