腾讯云大数据TBDS 助力国有大行一表通业务性能翻三倍!

腾讯云大数据TBDS 助力国有大行一表通业务性能翻三倍!

腾讯QQ大数据
发布于 2024-07-08 11:21:51
发布于 2024-07-08 11:21:51
1.腾讯云 TBDS 大数据平台介绍
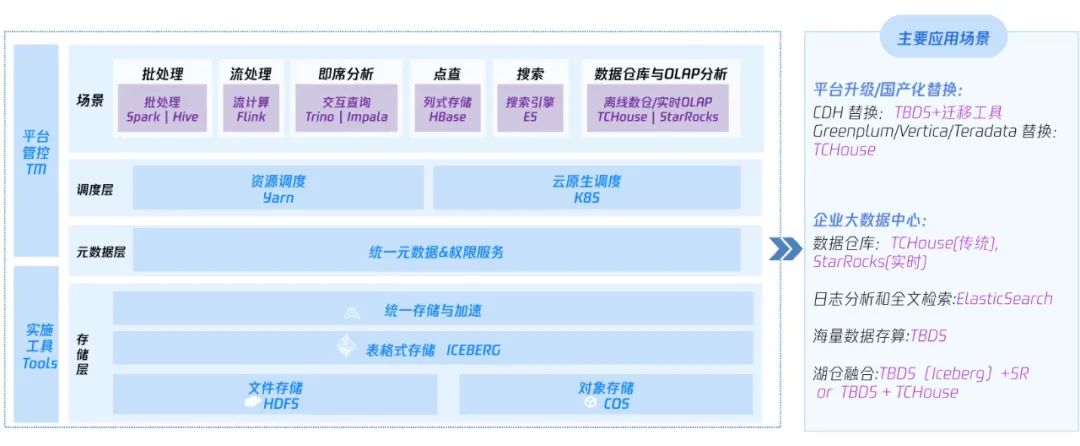
腾讯云 TBDS 是腾讯经过多年的大数据实践,面向数据全生命周期,对外提供安全、可靠、易用的一站式、高性能、企业级大数据存储计算分析平台,腾讯云TBDS 已落地金融、政务、能源、工业等多个行业,交付了 1000+ 的私有云大数据项目,腾讯云 TBDS 从 2017 年开始支持某国有大行的大数据平台建设,在大规模集群支持、核心业务性能优化、金融级数据安全、国产化创新、架构升级等方面一直在不断的升级和突破。
2.银行业一表通业务介绍
一表通业务是监管机构为了推进统一的监管数据体系,规范监管数据指标的定义和口径,确定统一的业务监测取数的规则,试行建立统一的监管数据采集规范和平台。
一表通业务是对原有金融 1104 报表、客户风险、EAST 等监管要求的升级,后续可能会作为最主要的平台在金融监管领域更广泛的应用;目前一表通主要分为两部分数据。
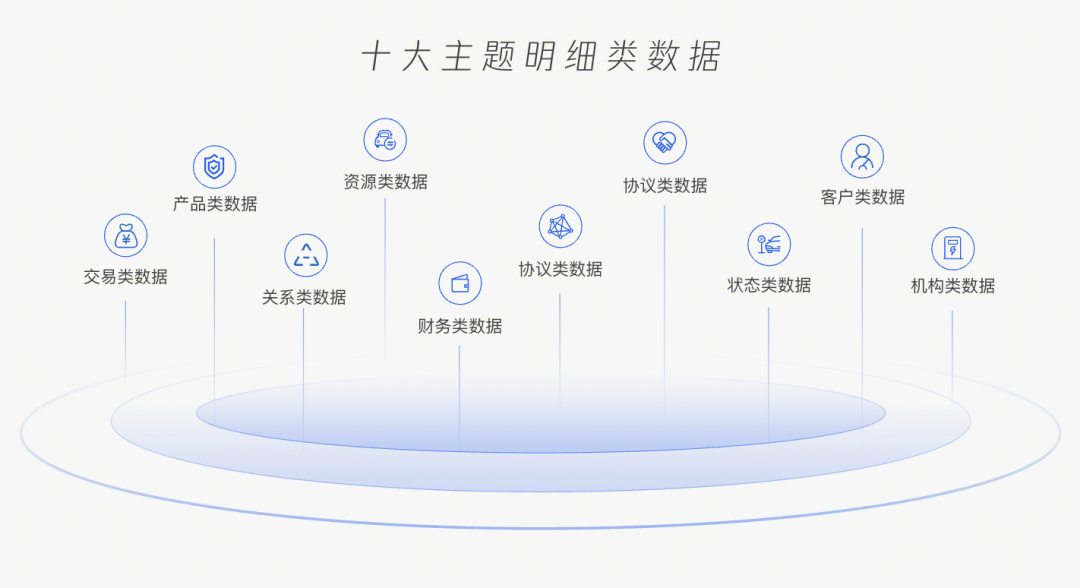
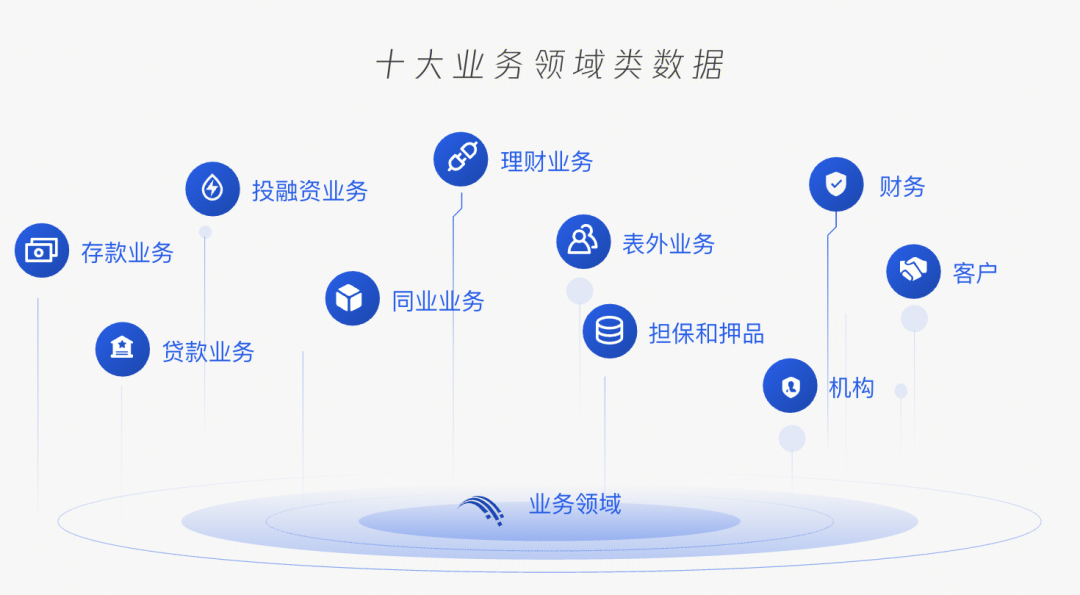
明细类数据(主题明细)和监管指标(业务领域)类数据,具体如下:
●明细类数据:分为 10 个主题类别,90 张表,2157 个数据项。
●监管指标类数据:分为 10 个领域、66 张数据表、1977 个数据项,确定从主题明细类数据进行取数计算
主题明细类数据和监管指标数据的关系说明:
●银行只需要填报主题明细类数据,监管指标数据按照标准逻辑自动生成
●一张监管指标(业务领域)报表与多张主题明细表对应;一张主题明细表会被多张监管指标(业务领域)表引用

TBDS 在一表通业务的核心挑战
●一表通业务监管的数据范围、指标逐渐增多,同时对数据采集、汇聚、计算、上报的性能、时效要求也越来越高。
●目前腾讯云 TBDS 在此项目的一表通业务涉及的数据量级单表百亿级,整体任务量在数百个左右,并且任务中有多层依赖关系,所以一表通涉及到监管报送的月批业务需要腾讯云 TBDS 跑 2 ~ 3 天左右。但由于银保监会的统一要求,需要把跑批时效约束在一天之内,同时改成日批后,所有工作流需要压缩到 12 小时内跑完,因此涉及到以下几部分的核心挑战:
●当前部分客户生产环境的核心计算组件仍然是 Tez,主要原因还是监管报送等对稳定性要求高,而 Hive on Tez 方案也较为成熟,风险相对可控,此方案在金融领域应用也是最广泛的,但随着客户和金融行业对风控监管等实时性要求的提升,客户对于 Hive on Tez 的性能也提出了更高的要求;
●腾讯云 TBDS 对当前作业分析后,发现大量 SQL 运行完成需要十几个小时,直接影响整个跑批的时效,所以对核心 SQL 进行优化也是本次要重点关注的内容;
●初步分析,当前环境在数据倾斜、向量化、查询优化器等方面仍然有提升空间,借此一表通业务,可以逐渐把以上能力融合和应用到一表通业务中;
TBDS 性能调优实践
1.SQL 引擎性能优化剖析
从初代 SQL 引擎 System R 开始,对性能的追求就一直没有停止。
●1972 年,E.F. Codd 发表论文阐述关系代数的优化方法,成为现代数据库“查询重写”的坚实理论基础,参考 Relational Completeness Of DataBase Sublanguages 第 4 节 REDUCTION。
●1974 年,System R 实现了启发式的优化器,参见:System R: Relational Approach to Database Management。
●20 世纪 90 年代,CPU 多核开始成为趋势,数据库开始尝试进行多线程执行加快效率。
●2000 年附近,X86 架构 SSE 指令集获得成功,MonetDB/X100 开始尝试向量化执行提升性能。
●2003 年,互联网数据大爆炸,Google MapReduce 拉开大数据的序幕,分布式计算成为主流。
这里,我们给出了两种 SQL 引擎实现高性能的思路:Top-Bottom 以数据为中心的思路、Bottom-Top 最大化利用硬件思路。
Top-Bottom 以数据为中心的思路如下:
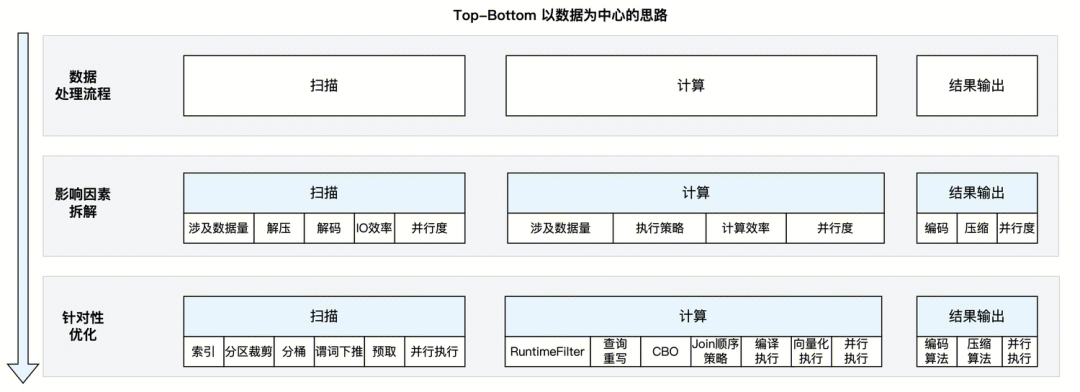
思考出发点是从 SQL 引擎处理的对象:“数据” 出发,目标是动用一切手段让数据可以尽快计算完,从 SQL 计算的几个阶段:扫描、计算、结果输出,分阶段自顶向下细化优化措施。
●减少参与计算数据量:索引、数据排序、分区、分桶、谓词下推、RuntimeFilter 都属于这一范围。
●减少数据传输时间:编码、压缩、预取 都属于这一范围。
●执行策略优化:优化器的查询重写、CBO 优化、Join 策略优化属于这一范围。
●执行方式优化:并行执行、编译执行、向量化执行属于这一范围。
而 Bottom-Top 最大化利用硬件 贯穿于现代多个性能良好的 SQL 引擎。
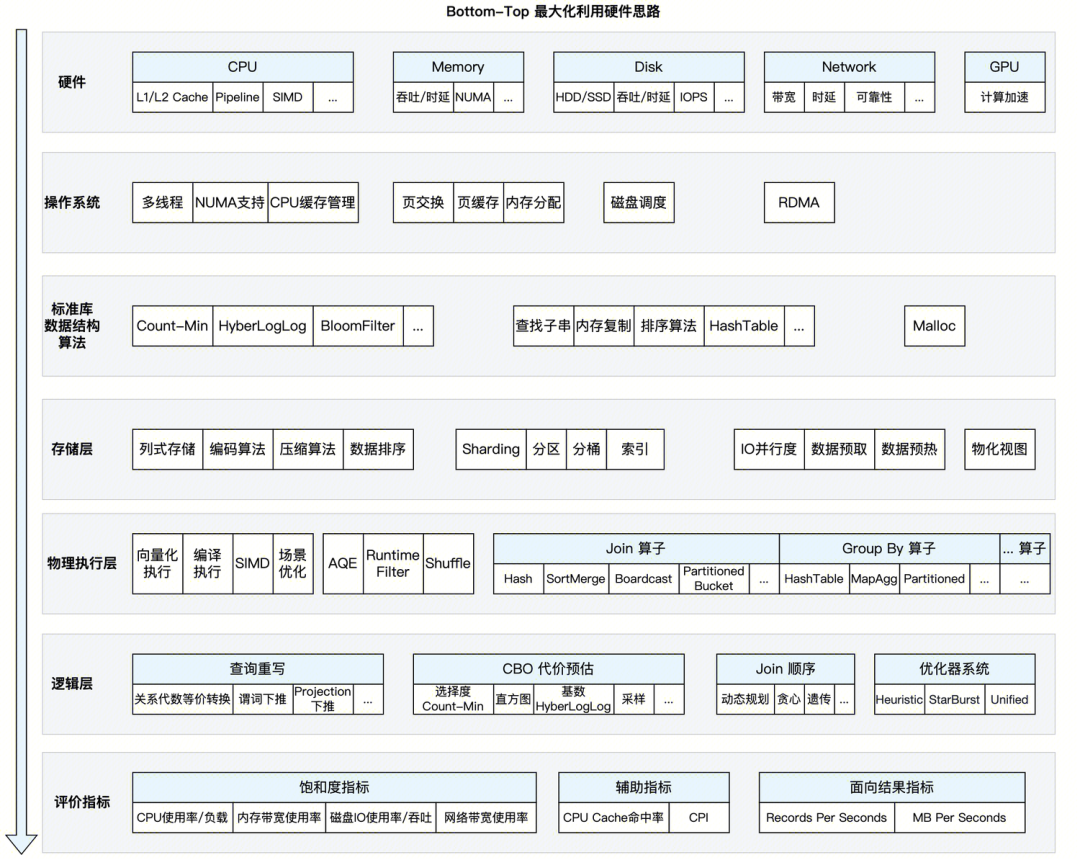
性能优化脱离现实硬件,无异于空中建楼阁,考虑当代计算机典型特征如下(当然逻辑上有其他的可能性,但是硬件发展现状是这样):
●分级存储:CPU (及 CPU Cache ) 吞吐显著优于内存吞吐、内存显著优于磁盘、网络吞吐性能略高于本地硬盘但稳定性低于本地硬盘,HDD 磁盘的 IOPS 指标比 SSD 低至少一个数量级。
●隐式缓存机制:CPU L1/L2、内存、磁盘与操作系统之间,协同实现了分级存储体系的同时,还实现隐式的缓存机制,以降低各层次间的性能 Gap。
●基于网络的分布式架构:一个服务器节点多核、一个集群包含多节点且通过网络连接是最常见的物理形式。
●加速指令集:服务器 CPU 通常支持 SIMD 加速指令,但是不同 ISA 架构有不同的指令集扩展。
●CPU Pipeline 机制:当前 CPU 底层实现普遍有 Pipeline 机制,分支预测失败、数据依赖的成本依然高,但已经相比过去有了很大进步。
基于以上背景,可以得出下面基础的优化方向:
●局部性原理:各级存储有极大吞吐上的差距,且内存、磁盘在随机读场景都有性能 downgrade ,应尽量将随机读取转变为顺序读取,以满足缓存机制。
●提升并行度:计算应当分布式执行多线程执行,以充分利用集群资源。
●减少网络交互:因网络吞吐/延迟性能和内存相比较差,分布式执行需要尽量降低节点间网络交互。
●使用 CPU 加速指令集:SIMD 可以加速数据处理,但需要开发底层代码。
●规避CPU架构短板:CPU Pipeline 机制、CALL 函数调用的上下文开销等,让向量化执行/编译执行相比于单行处理的火山模型更具性能优势。
●取长补短:磁盘性能较差,一般会成为瓶颈,CPU 性能好,数据编码/压缩作为一种拿 CPU 性能换数据吞吐的方法,有助于取长补短,充分利用硬件资源。
通过针对硬件特性优化,平衡各底层硬件之间的负载,让底层硬件的资源可以得到充分应用,从而提升整体吞吐,是以硬件出发自底向上设计的核心思想。
另外,从近期性能优秀的 SQL 引擎来看,下面因素对性能也至关重要:
●标准库函数优化:优化标准库的热点函数(如 memcpy、malloc ),这些函数的实现具备普适性,但不具备最佳性能。
●面向场景优化:面向具体场景的优化,例如 HashTable 面向 Key 的基数、承载的数据类型、Value 的大小等场景,可以做多种针对性实现,来提升性能。
●概率性算法应用:概率性算法/数据结构,比较适合大数据处理场景,例如 BloomFilter 广泛应用于大规模数据处理的各种流程中。
●充分利用硬件:对硬件的充分使用,例如非易失内存、GPU 加速、RDMA、FPGA 软硬融合计算,是演进中的发展方向。
2.Hive SQL 执行流程
上一节我们对 SQL 引擎性能优化的整体方向和思路进行了说明,其中 Hive 系统实现了其中一部分优化项,包括分布式执行、向量化执行、列式存储、编码压缩、基于 CBO 的优化器、分区、分桶、谓词下推、分区级的 max-min 统计、多种 Join 策略等。
这里,我们通过进一步拆解 Hive 自身的 SQL 执行流程,来对执行环节在结合实际一表通业务的场景进行定向优化。
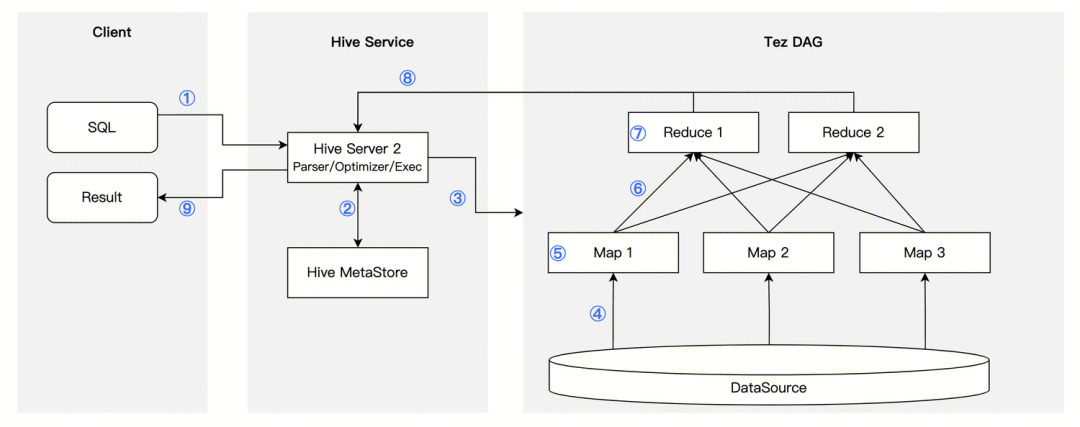
备注:对 SQL 执行的步骤进行了 ① ~ ⑨ 编号,方便理解下述优化对应的具体环节
●流程从客户端提交 SQL,到 Hive Server2 词法/语法解析生成逻辑执行计划,优化器优化生成物理查询计划,物理执行计划通过 Tez 等执行框架提交到 Yarn 分布式执行,期间每个环节都有可能出现性能问题。
●结合腾讯云 TBDS 在客户实际场景下的调优实践,整理出 Top 5 的性能优化场景
3.CBO 优化
对应于步骤 ②③,SQL 语义分析优化
问题现象
开启 CBO 后,存在多个功能问题,如多表 join 导致的 RuntimeException问题,窗口函数中包含 count(distinct)计数操作时导致的异常,不支持事务表 update/delete/merge 语句等等;
问题原因
Hive 对 CBO 的支持不够完善,需修复常见的 bug 及功能增强;
解决方案
(1)CBO (Cost-Based Optimizer,基于代价的优化器)
CBO 是 Hive 中的一项重要优化技术,通过评估查询执行计划的成本来选择最优的执行策略。
(2)原理
Hive CBO 的核心在于:在 QB 转 Operator 的逻辑计划处理中进行了扩展,基于表,分区,列的统计信息,根据火山模型计算出代价最小的 join 顺序和算法;
(3)增强
解决了 CBO 中的多个常见 Bug,如:
●修复了两张 JDBC 表 join 操作导致的 RuntimeException 问题;
●修复了union all 操作导致 CBO 规则递归调用的 OOM 问题;
●修复了 count(distinct) 过多导致的查询结果错误;
●修复了窗口函数中包含 count(distinct) 计数操作时,CBO 抛出异常问题;
功能增强,如:
●支持 JDBC 表常量 UDF 的谓词下推;
●支持事务表 update/delete/merge 语句 CBO 优化;
●支持将 Sort 条件下推到过滤条件中;
以支持事务表 update/delete/merge 语句CBO优化为例;
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
explain cbo
update over10k_orc_bucketed_t set i = 0 where b = 4294967363 and t < 100;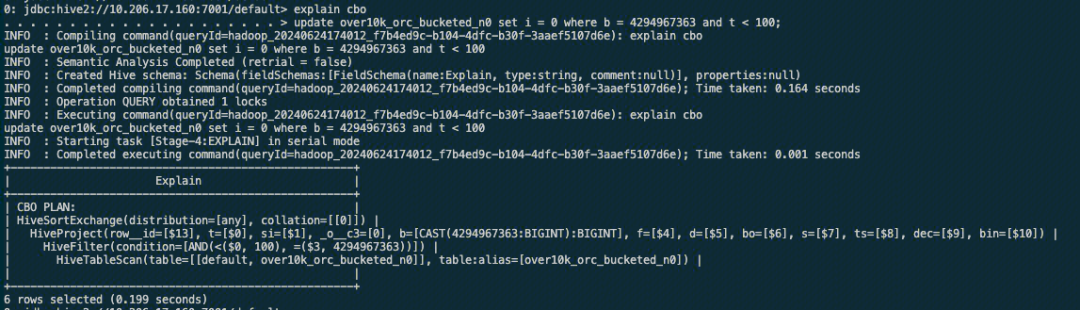
优化效果
实际优化后,一表通中主题明细类数据、以及存款、贷款、投融资中的跑批汇总作业任务,腾讯云 TBDS 版 Hive CBO 优化后的性能综合提升 15%;
4.Vectorization 优化
对应于步骤 ②③④⑤⑥⑦,SQL 语义分析,Map,Reduce 执行;
问题现象
开启 Vectorization 后,存在多个功能问题,如 Decimal64 数据类型的支持,COALESCE, BETWEEN/IN,Filter,GroupBy 等向量化操作的异常等
问题原因
Hive 对 Vectorization 的支持不够完善,需修复常见的 bug,支持客户用到的数据类型,函数,表达式,算子等;
解决方案
(1)Vectorization
Vectorization 是 Hive 中的一项重要优化技术,通过批量处理数据来提高查询性能。向量化执行的主要思想是将数据分批处理,减少函数调用次数,较少内存分配和垃圾回收频率,更好的利用 CPU 缓存提升查询性能;
(2)原理
默认情况下,Hive 执行引擎基于行处理模式(row-at-a-time)处理数据时,每次处理一行数据。这种方式在处理大规模数据时,CPU使用率低,内存的开销大,性能较低。
Vectorization 通过批量处理数据(batch processing),数据被表示为一组列向量,一次处理多行数据,从而提高了处理效率。
●Vectorization 将数据分成固定大小的批次(1024 行),一次处理一个批次的数据,减少了函数调用和循环的开销;
●Vectorization 利用了列式存储格式(ORC 和 Parquet)优点,将同一列的数据存储在一起,使的Vectorization可直接访问列数据,并在内存中以列为单位存储。减少了内存方位开销;
●Hive 提供了专门为 Vectorization 设计的数据类型,表达式,操作符,可在批量数据执行操作;
●Vectorization 利用现代 CPU 的 SIMD(Single Instruction, Multiple Data)指令集,在一次指令中处理多个数据;
(3)增强
解决了 Hive 3.1 Vectorization 中的多个常见 Bug,如:
●修复了向量化中的类型转换错误;
●修复了 COALESCE, BETWEEN/IN,Filter,GroupBy 等向量化操作导致的 NULL 值或结果错误的问题;
●修复了包含 Map 结果的复杂嵌套类型的 SQL 解析错误问题;
●修复 map 类型的 value 中包含 null 值导致的 ArrayIndexOutOfBoundsException 异常;
功能增强,如:
●支持了 Decimal64 数据类型;
●支持了 grouping/lead/lag 函数向量化;
●支持常量表达式的向量化;
以支持 Decimal64 类型的向量化为例
set hive.vectorized.execution.enabled=true;
set hive.vectorized.execution.reduce.enabled=true;
set hive.vectorized.execution.reduce.groupby.enabled=true;
explain vectorization detail
select sum(ss_ext_list_price*ss_ext_discount_amt) from vector_decimal64_mul_intcolumn_tmp; 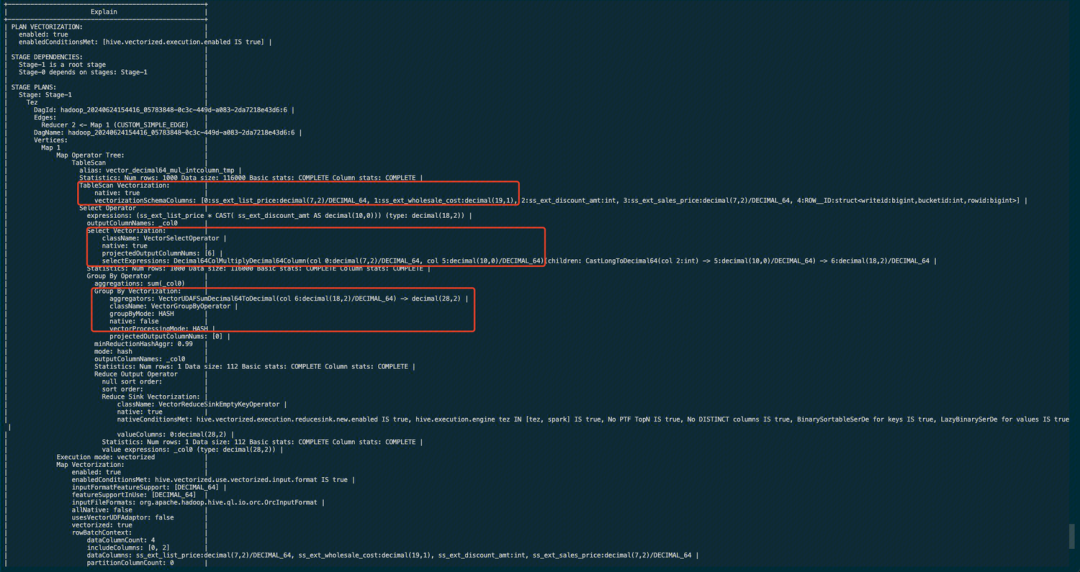
优化效果
实际优化后,一表通中交易、财务等主题明细数据,以及理财、同业业务中的跑批作业任务,开启向量化查询,总耗时缩短 35.6% 左右;
5.Join 性能优化
对应于步骤 ②③,执行计划优化部分
问题现象
百亿量级主表 LEFT JOIN 多个小表,执行时消耗大量集群资源,并且计算长达十几小时+。
问题原因
主表 Left Join 多个小表时, Hive 自主生成的执行计划并非最优选择,需要结合具体业务对执行计划进行调整和细节优化
解决方案
(1)部分作业执行计划优化为 MapJoin,Map Join(Boardcast Join) 相比于 Hash Join 的区别,示意如下:
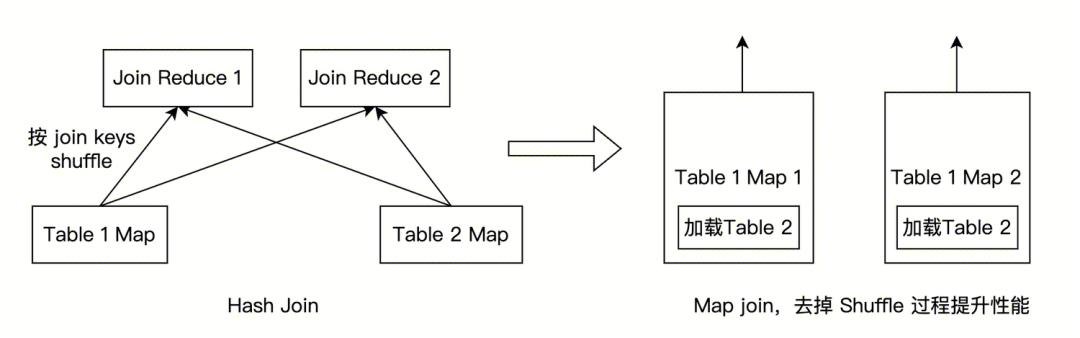
经典的 Hash Join / Sort Merge Join 的实现,均需要底层执行 Shuffle 过程,而如果其中一个表较小的话,执行 Shuffle 过程并不划算,可以将这个表广播到所有参与计算的节点,直接在 Map 流程中把 Join 一起做了,这样就移除了 Shuffle 过程,从而提升计算性能。
(2)同时在执行计划优化后,针对具体执行参数,比如对小表进行广播并调大广播阈值等参数进行优化,部分参数优化如下:
set hive.auto.convert.join=true; -- 开启 Map Join
set hive.mapjoin.smalltable.filesize=1000000000; -- 设置小于 1GB 的表都可以参与 MapJoin
set hive.auto.convert.join.noconditionaltask=true; -- 允许多个 JOIN 级连情况下,转换为 Map Join
set hive.auto.convert.join.noconditionaltask.size=3000000000; -- 设置多个 JOIN 级连情况下,所有参与JOIN小表大小合不超过 3 GB
set tez.am.resource.memory.mb=8192 -- 调大内存
set hive.tez.container.size=8192 -- 调大内存优化效果
通过对执行计划进行调整和优化,部分存贷款、财务、担保等领域的汇总数据相关的作业执行时长由十几小时优化为 15 分钟左右。
6.数据倾斜优化
对应于步骤 ⑤,数据源导致的数据倾斜
问题现象
十亿量级表 LEFT JOIN 多个小表时,执行时长数个小时,且最终执行 OOM。
原因分析
●现实情况下,大部分情况数据分布是不均匀的;
●不均匀的数据会造成 GROUP BY/JOIN 时候大部分数据在Reduce时被分发到同一个节点执行,造成执行缓慢甚至 OOM ;
解决方案
Hive 本身提供了多种方案,来解决各种 GROUP BY / JOIN 场景的数据倾斜问题,我们也针对多种方案以及结合一表通业务对数据倾斜问题进行综合性优化,以 hive.map.aggr 对 GROUP BY 的优化为例进行优化的技术说明。
其中 GROUP BY 的聚合操作通常在 Reduce 端进行,示例如下左图,如果有数据倾斜情况,就会有大量数据聚集到部分 Reduce 上(如下图标红的 Reduce 2),造成这些 Task 执行缓慢。
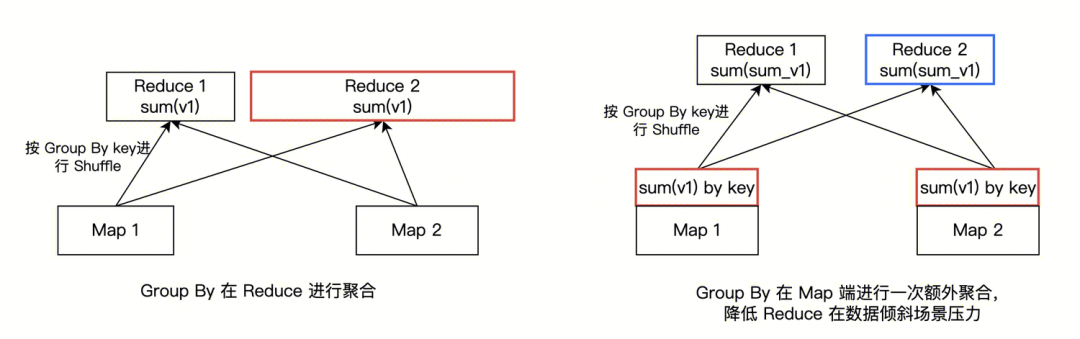
而 hive.map.aggr 设置为 true 时,Hive 会进行物理执行计划优化,如上右图,在 Map 端额外做一次预聚合后,再把聚合后的结果发给 Reduce,而不是原始数据发给 Reduce,聚合后数据规模大大降低,数据倾斜造成的负面影响从而得到显著改善,部分调整示例如下:
-- Group by 数据倾斜优化
set hive.map.aggr=true;
-- 这个 skewindata 数据倾斜优化在任务失败重试时可能造成数据丢失,这里不进行重试
set hive.groupby.skewindata=true;
set tez.am.task.max.failed.attempts=0;
-- Join 数据倾斜优化
set hive.optimize.skewjoin=true;优化效果
通过多种类似上述的细节优化,同时也结合业务减少主表 Left Join 小表中的个数等方式,原有多个执行时长由数小时的作业优化后变为 3 分钟左右,性能提升非常明显
7.加载分区性能优化
对应于步骤 ⑧,例如加载分区过程,涉及大量HDFS 文件 rename 造成性能差
问题现象
类似于这样的 SQL 语句(Insert+ 多个 Union all 模式),总执行时长需要 5+ 小时:
INSERT xxx
SELECT xxx FROM xxx
UNION ALL
SELECT xxx FROM xxx
UNION ALL
SELECT xxx FROM xxx
UNION ALL
SELECT xxx FROM xxx
UNION ALL问题原因
●Hive 为了数据一致性考虑,插入表的数据不会直接写入目标目录,而是写入一个名为 .hive-staging 的目录,而分布式执行框架在写入完成后,由 Hive Server2 进行后续将文件移入目标目录的动作,如果涉及大量小文件,将会导致性能较差。
●在动态分区插入场景,需要最终由 Hive Server2 调用 Metastore API 完成动态分区加载,如果涉及分区非常多,这个过程在极端场景要执行几十分钟以上,造成性能较差。
解决方案
(1)在 INSERT 前,加上一个 DISTRIBUTE BY rand(1024),引入额外的 Map/Reduce 过程,强制进行小文件合并(这里的 rand 函数的 seed 是为了避免 HIVE-19671 重跑造成数据丢失的问题)。
INSERT xxx
SELECT * FROM (
SELECT xxx FROM xxx
UNION ALL
SELECT xxx FROM xxx
...
UNION ALL
SELECT xxx FROM xxx
)
DISTRIBUTE BY rand(1024)(2)通过对部分参数的新增和优化提升此类作业的性能,比如 Hive 通过提升动态加载分区的线程数,来提升性能
hive.load.dynamic.partitions.thread=50;优化效果
通过对此类作业的 SQL 和执行参数进行优化,多个主表执行时长从 5+ 小时优化为 6 分钟左右。
落地效果
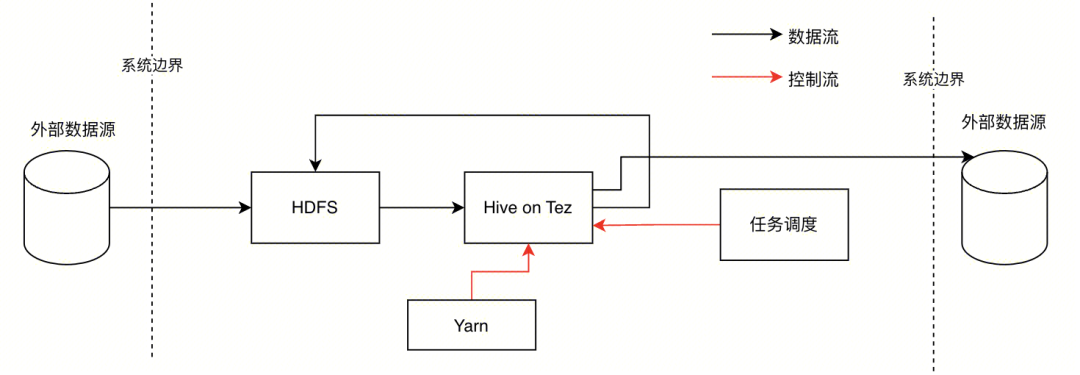
一表通业务在腾讯云 TBDS 落地的架构如下:
●CBO 实际优化后,一表通中存款、贷款、投融资中的跑批作业任务,腾讯云TBDS 版 Hive CBO优化后的性能综合提升 15%;
●向量化优化后,一表通中存款、贷款、理财、客户表中的跑批作业任务,开启向量化查询,总耗时缩短 35.6% 左右;
●百亿主表 Lest Join 性能优化后,部分存贷款、财务、担保等领域数据相关的作业执行时长由十几小时优化为 15 分钟左右。
●数据倾斜优化后,同时也结合业务减少主表 Left Join 小表中的个数等方式,原有多个执行时长由数小时的作业优化后变为 3 分钟左右
●通过对加载分区功能优化后,对此类作业的sql 和执行参数进行优化,多个主表执行时长从 5+ 小时优化为 6 分钟左右
综上,一表通业务整体经过上述优化措施,20+ 执行 5 小时+的 SQL 任务,均被优化至 5 分钟- 30 分钟。
展望
经过上面的优化后,客户一表通业务在当前腾讯云 TBDS Hive on Tez 架构下已经满足要求,并且保留了一年内数据发展的余量。
再次回顾客户的业务场景,结合新一代TBDS的湖仓一体架构,此类业务可以借助腾讯云 TBDS Iceberg 湖格式与 Spark/Trino/StarRocks 分析引擎,提供更好的解决方案。未来随着客户业务的升级与腾讯云 TBDS 版本升级演化,通过架构改造,从而进一步整体降低计算资源成本,提升运行效率。
具体结合新版本的业务架构方式可以如下进行:
● Spark+ Iceberg,缩短批处理写入的时长,提升 ETL 效率。
● Trino + Iceberg,Iceberg 实现了数据软实时写入,而 Trino 提供了更高的查询性能。
● StarRocks + Iceberg,湖仓一体,更高一层级的性能
另外,在新一代腾讯云 TBDS 产品中,通过采集分析作业执行计划数据,提供了作业智能洞察分析能力,让作业优化门槛更低,在业务投产初期就能识别作业运行效率问题,并给出合适的优化建议。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号