ShardingSphere整合Mybatis执行流程学习一

ShardingSphere整合Mybatis执行流程学习一

路行的亚洲
发布于 2024-06-27 19:52:16
发布于 2024-06-27 19:52:16
由于业务需求中,需要写一些逻辑,同时为了优化业务响应,这里对分库分表的中间件在业务中的使用,进行了自己的学习和记录。下面是对ShardingSphere学习的记录。
ShardingSphere整合Mybatis的时候,执行的相关流程,这里我们从整体的执行流程来学习。以下代码结合ShardingSphere的4.X系列学习。
一、 ShardingSphere增强数据源
SpringBootConfiguration#dataSource中会创建数据源
@Bean
public DataSource dataSource() throws SQLException {
return null == this.masterSlaveProperties.getMasterDataSourceName() ? ShardingDataSourceFactory.createDataSource(this.dataSourceMap, this.shardingProperties.getShardingRuleConfiguration(), this.configMapProperties.getConfigMap(), this.propMapProperties.getProps()) : MasterSlaveDataSourceFactory.createDataSource(this.dataSourceMap, this.masterSlaveProperties.getMasterSlaveRuleConfiguration(), this.configMapProperties.getConfigMap(), this.propMapProperties.getProps());
}
可以看到创建的数据源中分片上下文的相关信息:
public ShardingContext(Map<String, DataSource> dataSourceMap, ShardingRule shardingRule, DatabaseType databaseType, Properties props) throws SQLException {
this.databaseMetaData = this.getDatabaseMetaData(dataSourceMap);
this.shardingRule = shardingRule;
this.databaseType = databaseType;
this.shardingProperties = new ShardingProperties(null == props ? new Properties() : props);
int executorSize = (Integer)this.shardingProperties.getValue(ShardingPropertiesConstant.EXECUTOR_SIZE);
this.executeEngine = new ShardingExecuteEngine(executorSize);
this.metaData = new ShardingMetaData(this.getDataSourceURLs(dataSourceMap), shardingRule, databaseType, this.executeEngine, new JDBCTableMetaDataConnectionManager(dataSourceMap), (Integer)this.shardingProperties.getValue(ShardingPropertiesConstant.MAX_CONNECTIONS_SIZE_PER_QUERY), (Boolean)this.shardingProperties.getValue(ShardingPropertiesConstant.CHECK_TABLE_METADATA_ENABLED));
}
首先ShardingJdbc的相关配置信息是从ShardingDataSource的分片数据源开始去做一个数据源的填充和增强操作的。解析配置信息,然后创建sharding上下文。
数据源运行期上下文=> 分片规则、sql路由引擎、执行引擎等相关的信息
二、分片算法的复写
同时如果我们自定义对应的分片算法,此时需要复写PreciseShardingAlgorithm这个接口。比如我们项目里面就使用了
image-20240621142737656
根据经销商代码进行分片。我们在getOwnerShard中,完成了业务需求的分片逻辑。目前是按照分表的逻辑来进行的。
为了能够获取对应的经销商信息,我们在拦截器中添加了对登录信息中分片经销商信息进行拦截。方便sql的拼接。
三、ShardingSphere执行分库分表的流程
以insert为例来看整个执行过程:
首先sql的执行经过mybatis,然后走到mybatis的MybatisMapperProxy代理,通过动态代理拿到对应的方法,执行对应的实现。
而进入到ShardingSphere的逻辑是在Mybatis的PreparedStatementHandler#update时来到ShardingPreparedStatement的execute方法。
这里是进入ShardingSpehere的入口,我理解。
@Override
public boolean execute() throws SQLException {
try {
clearPrevious();
prepare();
initPreparedStatementExecutor();
return preparedStatementExecutor.execute();
} finally {
clearBatch();
}
}
这段代码包含了ShardingJDBC的四个过程:
解析+路由+改写 => prepare()
执行 => preparedStatementExecutor.execute()
这四个过程从这里开始。除此之外,查询还有一个归并的过程。
可以看到prepare的执行过程其实是一个解析+路由的过程
public ExecutionContext prepare(final String sql, final List<Object> parameters) {
List<Object> clonedParameters = cloneParameters(parameters);
// 先进行解析再执行路由
RouteContext routeContext = executeRoute(sql, clonedParameters);
ExecutionContext result = new ExecutionContext(routeContext.getSqlStatementContext());
// 执行rewrite操作
result.getExecutionUnits().addAll(executeRewrite(sql, clonedParameters, routeContext));
if (properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SHOW)) {
SQLLogger.logSQL(sql, properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SIMPLE), result.getSqlStatementContext(), result.getExecutionUnits());
}
return result;
}
完成这个操作之后,就可以执行初始化PreparedStatementExecutor。
private void initPreparedStatementExecutor() throws SQLException {
preparedStatementExecutor.init(executionContext);
setParametersForStatements();
replayMethodForStatements();
}
可以看到初始化预编译语句执行器。
执行sql的过程:
/**
* Execute SQL.
*
* @return return true if is DQL, false if is DML
* @throws SQLException SQL exception
*/
public boolean execute() throws SQLException {
boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
SQLExecuteCallback<Boolean> executeCallback = SQLExecuteCallbackFactory.getPreparedSQLExecuteCallback(getDatabaseType(), isExceptionThrown);
List<Boolean> result = executeCallback(executeCallback);
if (null == result || result.isEmpty() || null == result.get(0)) {
return false;
}
return result.get(0);
}
这里是sql执行的关键。
从上面的代码看:
prepare();
initPreparedStatementExecutor();
preparedStatementExecutor.execute();
这三行代码是完成执行的关键。
同时从上面,我们还可以看到除了execute()这个方法之外,还存在:
executeQuery()、executeQuery()、addBatch()
这几个方法。
而在查询executeQuery()中,可以看到有一个归并结果集的操作mergeQuery:
@Override
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
clearPrevious();
prepare();
initPreparedStatementExecutor();
// 执行查询,并对查询进行归并
MergedResult mergedResult = mergeQuery(preparedStatementExecutor.executeQuery());
result = new ShardingResultSet(preparedStatementExecutor.getResultSets(), mergedResult, this, executionContext);
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
说完了上面的流程和执行过程,下面我们来看看为什么能够扩展?
四、ShardingPreparedStatement以execute打头方法执行原因
那为什么说ShardingPreparedStatement的execute方法是执行的入口呢?下面是ShardingPreparedStatement的类图:
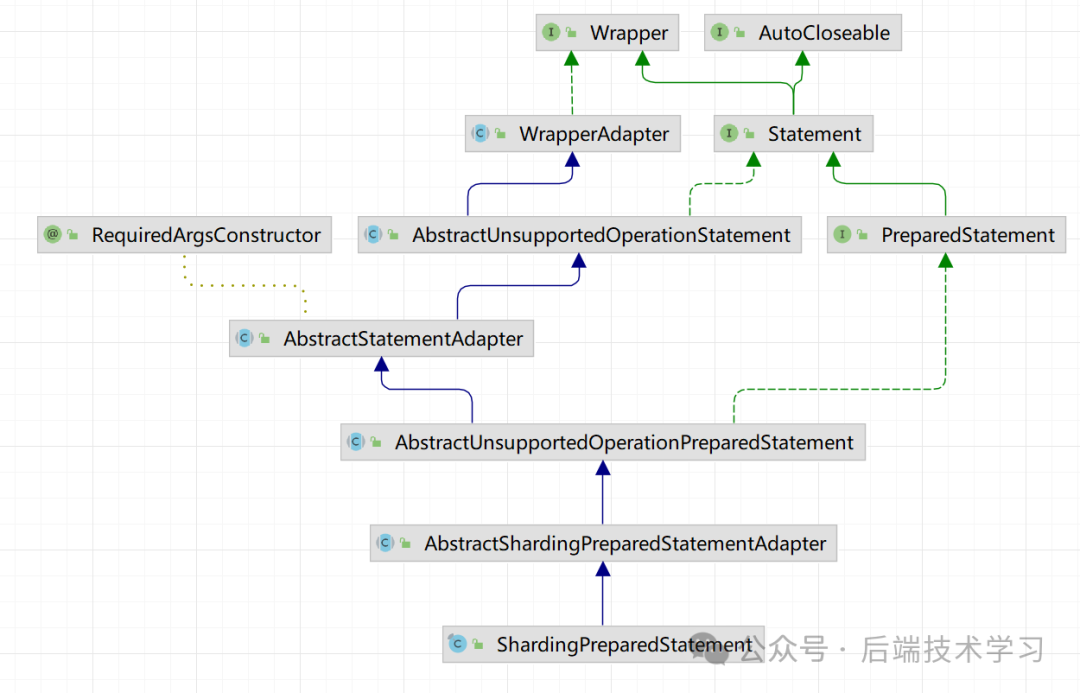
从上面,我们可以看到因为其实现了PreparedStament接口,进行了自己的扩展。这也是为什么ShardingPreparedStatement能够执行以execute打头方法执行原因。
上面我们只是简单的整理了一下ShardingSphere结合Mybatis的执行流程。
其中prepare()这个过程和preparedStatementExecutor.execute这个过程里面包含了很多代码。需要细细的研究。
参考:
https://github.com/apache/shardingsphere
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号