Transformers 4.37 中文文档(六十七)

Transformers 4.37 中文文档(六十七)

ApacheCN_飞龙
发布于 2024-06-26 17:09:06
发布于 2024-06-26 17:09:06
扩张邻域注意力变换器
原文:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/dinat
概述
DiNAT 是由 Ali Hassani 和 Humphrey Shi 在扩张邻域注意力变换器中提出的。
它通过添加扩张邻域注意力模式来扩展 NAT,以捕获全局上下文,并显示出明显的性能改进。
论文摘要如下:
变换器正在迅速成为跨模态、领域和任务中最广泛应用的深度学习架构之一。在视觉领域,除了对普通变换器的持续努力外,分层变换器也引起了极大关注,这要归功于它们的性能和易于集成到现有框架中。这些模型通常采用局部化注意机制,例如滑动窗口邻域注意力(NA)或 Swin Transformer 的移位窗口自注意力。虽然有效地减少了自注意力的二次复杂度,但局部注意力削弱了自注意力的两个最理想的特性:长距离相互依赖建模和全局感受野。在本文中,我们介绍了扩张邻域注意力(DiNA),这是对 NA 的一种自然、灵活和高效的扩展,可以在不增加额外成本的情况下捕获更多的全局上下文并指数级扩展感受野。NA 的局部注意力和 DiNA 的稀疏全局注意力互补,因此我们引入了扩张邻域注意力变换器(DiNAT),这是一个基于两者构建的新的分层视觉变换器。DiNAT 的变体在强基线模型(如 NAT、Swin 和 ConvNeXt)上取得了显著的改进。我们的大型模型在 COCO 目标检测中比其 Swin 对应物快 1.5%的 box AP,在 COCO 实例分割中比其快 1.3%的 mask AP,在 ADE20K 语义分割中比其快 1.1%的 mIoU。与新框架配对,我们的大型变体是 COCO(58.2 PQ)和 ADE20K(48.5 PQ)的新一代全景分割模型,以及 Cityscapes(44.5 AP)和 ADE20K(35.4 AP)的实例分割模型(无额外数据)。它还与 ADE20K(58.2 mIoU)上的最先进专门的语义分割模型相匹配,并在 Cityscapes(84.5 mIoU)上排名第二(无额外数据)。
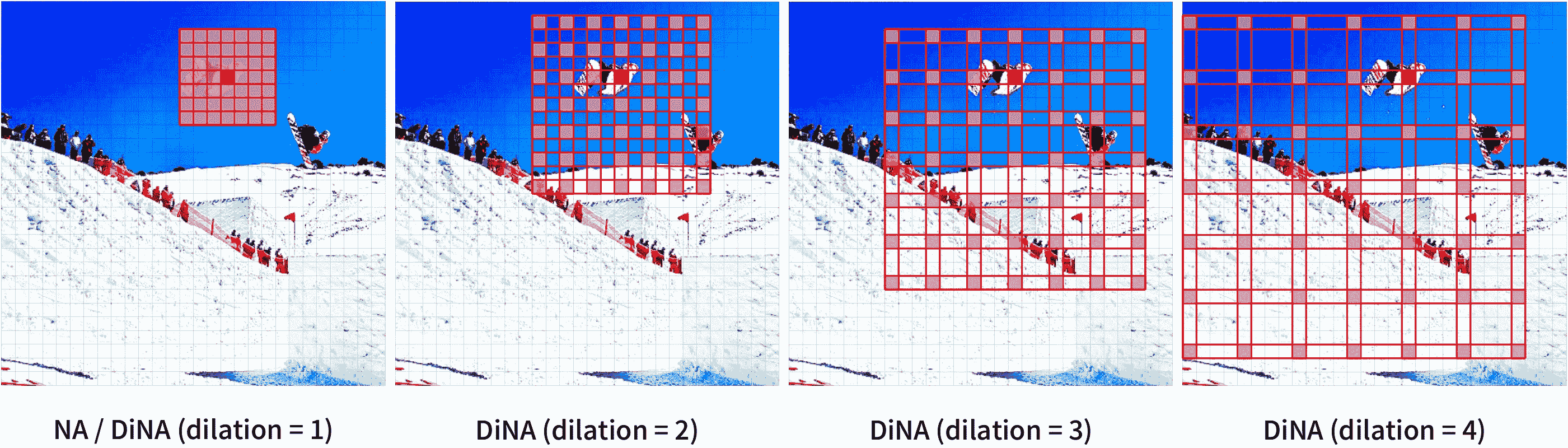
drawing
具有不同扩张值的邻域注意力。摘自原始论文。
此模型由Ali Hassani贡献。原始代码可以在这里找到。
使用提示
DiNAT 可以用作骨干。当output_hidden_states = True时,它将输出hidden_states和reshaped_hidden_states。reshaped_hidden_states的形状为(batch, num_channels, height, width),而不是(batch_size, height, width, num_channels)。
注意:
- DiNAT 依赖于NATTEN对邻域注意力和扩张邻域注意力的实现。您可以通过参考shi-labs.com/natten来安装 Linux 的预构建轮子,或者通过运行
pip install natten在您的系统上构建。请注意,后者可能需要一些时间来编译。NATTEN 目前不支持 Windows 设备。 - 目前仅支持 4 的补丁大小。
资源
一些官方 Hugging Face 和社区(由🌎表示)资源的列表,可帮助您开始使用 DiNAT。
图像分类
如果您有兴趣提交资源以包含在此处,请随时打开一个 Pull Request,我们将对其进行审查!资源应该展示一些新内容,而不是重复现有资源。
DinatConfig
class transformers.DinatConfig
( patch_size = 4 num_channels = 3 embed_dim = 64 depths = [3, 4, 6, 5] num_heads = [2, 4, 8, 16] kernel_size = 7 dilations = [[1, 8, 1], [1, 4, 1, 4], [1, 2, 1, 2, 1, 2], [1, 1, 1, 1, 1]] mlp_ratio = 3.0 qkv_bias = True hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 drop_path_rate = 0.1 hidden_act = 'gelu' initializer_range = 0.02 layer_norm_eps = 1e-05 layer_scale_init_value = 0.0 out_features = None out_indices = None **kwargs )参数
-
patch_size(int, 可选, 默认为 4) — 每个补丁的大小(分辨率)。注意:目前仅支持补丁大小为 4。 -
num_channels(int, 可选, 默认为 3) — 输入通道数。 -
embed_dim(int, 可选, 默认为 64) — 补丁嵌入的维度。 -
depths(List[int], 可选, 默认为[3, 4, 6, 5]) — 编码器每个级别的层数。 -
num_heads(List[int], 可选, 默认为[2, 4, 8, 16]) — Transformer 编码器每层中的注意力头数。 -
kernel_size(int, 可选, 默认为 7) — 邻域注意力核大小。 -
dilations(List[List[int]], 可选, 默认为[[1, 8, 1], [1, 4, 1, 4], [1, 2, 1, 2, 1, 2], [1, 1, 1, 1, 1]]) — Transformer 编码器中每个 NA 层的扩张值。 -
mlp_ratio(float, 可选, 默认为 3.0) — MLP 隐藏维度与嵌入维度的比率。 -
qkv_bias(bool, 可选, 默认为True) — 是否应向查询、键和值添加可学习偏置。 -
hidden_dropout_prob(float, 可选, 默认为 0.0) — 嵌入和编码器中所有全连接层的丢失概率。 -
attention_probs_dropout_prob(float, 可选, 默认为 0.0) — 注意力概率的丢失比率。 -
drop_path_rate(float, 可选, 默认为 0.1) — 随机深度率。 -
hidden_act(str或function, 可选, 默认为"gelu") — 编码器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 -
initializer_range(float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, 可选, 默认为 1e-05) — 层归一化层使用的 epsilon。 -
layer_scale_init_value(float, 可选, 默认为 0.0) — 层缩放的初始值。如果<=0,则禁用。 -
out_features(List[str], 可选) — 如果用作骨干,要输出的特征列表。可以是"stem"、"stage1"、"stage2"等(取决于模型有多少阶段)。如果未设置且设置了out_indices,将默认为相应的阶段。如果未设置且out_indices未设置,将默认为最后一个阶段。必须按照stage_names属性中定义的顺序。 -
out_indices(List[int], 可选) — 如果用作骨干,要输出的特征的索引列表。可以是 0、1、2 等(取决于模型有多少阶段)。如果未设置且设置了out_features,将默认为相应的阶段。如果未设置且out_features未设置,将默认为最后一个阶段。必须按照stage_names属性中定义的顺序。
这是用于存储 DinatModel 配置的配置类。用于根据指定参数实例化 Dinat 模型,定义模型架构。使用默认值实例化配置将产生类似于 Dinat shi-labs/dinat-mini-in1k-224 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import DinatConfig, DinatModel
>>> # Initializing a Dinat shi-labs/dinat-mini-in1k-224 style configuration
>>> configuration = DinatConfig()
>>> # Initializing a model (with random weights) from the shi-labs/dinat-mini-in1k-224 style configuration
>>> model = DinatModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configDinatModel
class transformers.DinatModel
( config add_pooling_layer = True )参数
config(DinatConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸 Dinat 模型变压器输出原始隐藏状态,没有特定的头部。这个模型是 PyTorch torch.nn.Module 子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有信息。
forward
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.dinat.modeling_dinat.DinatModelOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。可以使用 AutoImageProcessor 获取像素值。详细信息请参阅 ViTImageProcessor.call()。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请查看返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.dinat.modeling_dinat.DinatModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.dinat.modeling_dinat.DinatModelOutput 或一个 torch.FloatTensor 元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包括根据配置(DinatConfig)和输入的不同元素。
-
last_hidden_state(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态输出序列。 -
pooler_output(torch.FloatTensorof shape(batch_size, hidden_size), optional, returned whenadd_pooling_layer=Trueis passed) — 最后一层隐藏状态的平均池化。 -
hidden_states(tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each stage) of shape(batch_size, sequence_length, hidden_size). 模型在每一层输出的隐藏状态以及初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个阶段一个)。 自注意力头中用于计算加权平均值的注意力 softmax 后的注意力权重。 -
reshaped_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, hidden_size, height, width)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个阶段的输出)。 模型在每个层的输出处的隐藏状态以及包括空间维度的初始嵌入输出的重塑。
DinatModel 的前向方法,覆盖__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行前处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, DinatModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("shi-labs/dinat-mini-in1k-224")
>>> model = DinatModel.from_pretrained("shi-labs/dinat-mini-in1k-224")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 7, 7, 512]DinatForImageClassification
class transformers.DinatForImageClassification
( config )参数
config(DinatConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
Dinat 模型变压器,顶部带有图像分类头(在[CLS]标记的最终隐藏状态顶部的线性层),例如用于 ImageNet。
此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( pixel_values: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.dinat.modeling_dinat.DinatImageClassifierOutput or tuple(torch.FloatTensor)参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)— 像素值。像素值可以使用 AutoImageProcessor 获取。有关详细信息,请参阅 ViTImageProcessor.call()。 -
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。 -
labels(形状为(batch_size,)的torch.LongTensor,可选)— 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.models.dinat.modeling_dinat.DinatImageClassifierOutput或tuple(torch.FloatTensor)
一个transformers.models.dinat.modeling_dinat.DinatImageClassifierOutput或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(DinatConfig)和输入的各种元素。
-
loss(形状为(1,)的torch.FloatTensor,可选,在提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(形状为(batch_size, config.num_labels)的torch.FloatTensor) — 分类(如果config.num_labels==1则为回归)分数(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个阶段的输出)。 模型在每一层输出的隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每个阶段一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
reshaped_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, hidden_size, height, width)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个阶段的输出)。 模型在每一层输出的隐藏状态加上初始嵌入输出,重塑以包括空间维度。
DinatForImageClassification 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, DinatForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("shi-labs/dinat-mini-in1k-224")
>>> model = DinatForImageClassification.from_pretrained("shi-labs/dinat-mini-in1k-224")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby catDINOv2
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/dinov2
概述
DINOv2 模型是由 Maxime Oquab、Timothée Darcet、Théo Moutakanni、Huy Vo、Marc Szafraniec、Vasil Khalidov、Pierre Fernandez、Daniel Haziza、Francisco Massa、Alaaeldin El-Nouby、Mahmoud Assran、Nicolas Ballas、Wojciech Galuba、Russell Howes、Po-Yao Huang、Shang-Wen Li、Ishan Misra、Michael Rabbat、Vasu Sharma、Gabriel Synnaeve、Hu Xu、Hervé Jegou、Julien Mairal、Patrick Labatut、Armand Joulin、Piotr Bojanowski 提出的DINOv2: Learning Robust Visual Features without Supervision。DINOv2 是DINO的升级版本,是一种应用于视觉 Transformer 的自监督方法。该方法使得可以生成通用视觉特征,即在不进行微调的情况下适用于图像分布和任务的特征。
该论文的摘要如下:
最近在自然语言处理中的模型预训练方面取得的突破为计算机视觉中类似的基础模型打开了道路。这些模型可以通过生成通用视觉特征(即在不进行微调的情况下适用于图像分布和任务的特征)大大简化任何系统中图像的使用。这项工作表明,现有的预训练方法,特别是自监督方法,如果在来自不同来源的充分筛选数据上进行训练,可以产生这样的特征。我们重新审视现有方法,并结合不同技术来扩展我们的预训练数据和模型规模。大部分技术贡献旨在加速和稳定大规模训练。在数据方面,我们提出了一个自动流水线来构建一个专门的、多样化的、筛选过的图像数据集,而不是像自监督文献中通常所做的那样使用未筛选的数据。在模型方面,我们训练了一个具有 10 亿参数的 ViT 模型(Dosovitskiy 等人,2020 年),并将其蒸馏成一系列更小的模型,这些模型在图像和像素级别的大多数基准测试中超越了最佳的通用特征 OpenCLIP(Ilharco 等人,2021 年)
使用提示
该模型可以使用torch.jit.trace进行跟踪,利用 JIT 编译来优化模型,使其运行更快。请注意,这仍然会产生一些不匹配的元素,原始模型和跟踪模型之间的差异约为 1e-4 的数量级。
import torch
from transformers import AutoImageProcessor, AutoModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained('facebook/dinov2-base')
model = AutoModel.from_pretrained('facebook/dinov2-base')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs[0]
# We have to force return_dict=False for tracing
model.config.return_dict = False
with torch.no_grad():
traced_model = torch.jit.trace(model, [inputs.pixel_values])
traced_outputs = traced_model(inputs.pixel_values)
print((last_hidden_states - traced_outputs[0]).abs().max())资源
官方 Hugging Face 和社区(由🌎表示)资源列表,可帮助您开始使用 DPT。
- DINOv2 的演示笔记本可以在这里找到。🌎
图像分类
如果您有兴趣提交资源以包含在这里,请随时打开一个 Pull Request,我们将进行审核!资源应该理想地展示一些新东西,而不是重复现有资源。
Dinov2Config
class transformers.Dinov2Config
( hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 mlp_ratio = 4 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-06 image_size = 224 patch_size = 16 num_channels = 3 qkv_bias = True layerscale_value = 1.0 drop_path_rate = 0.0 use_swiglu_ffn = False out_features = None out_indices = None apply_layernorm = True reshape_hidden_states = True **kwargs )参数
-
hidden_size(int,可选,默认为 768)—编码器层和池化层的维度。 -
num_hidden_layers(int,可选,默认为 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int,可选,默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 -
mlp_ratio(int,可选,默认为 4) — MLP 的隐藏大小相对于hidden_size的比率。 -
hidden_act(str或function,可选,默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 -
hidden_dropout_prob(float,可选,默认为 0.0) — 嵌入、编码器和池化器中所有全连接层的丢弃概率。 -
attention_probs_dropout_prob(float,可选,默认为 0.0) — 注意力概率的丢弃比率。 -
initializer_range(float,可选,默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float,可选,默认为 1e-06) — 层归一化层使用的 epsilon。 -
image_size(int,可选,默认为 224) — 每个图像的大小(分辨率)。 -
patch_size(int,可选,默认为 16) — 每个补丁的大小(分辨率)。 -
num_channels(int,可选,默认为 3) — 输入通道数。 -
qkv_bias(bool,可选,默认为True) — 是否为查询、键和值添加偏置。 -
layerscale_value(float,可选,默认为 1.0) — 用于层缩放的初始值。 -
drop_path_rate(float,可选,默认为 0.0) — 每个样本的随机深度率(应用于残差层的主路径时)。 -
use_swiglu_ffn(bool,可选,默认为False) — 是否使用 SwiGLU 前馈神经网络。 -
out_features(List[str],可选) — 如果用作骨干,要输出的特征列表。可以是任何"stem"、"stage1"、"stage2"等(取决于模型有多少阶段)。如果未设置且设置了out_indices,将默认为相应的阶段。如果未设置且未设置out_indices,将默认为最后一个阶段。必须按照stage_names属性中定义的顺序。 -
out_indices(List[int],可选) — 如果用作骨干,要输出的特征的索引列表。可以是任何 0、1、2 等(取决于模型有多少阶段)。如果未设置且设置了out_features,将默认为相应的阶段。如果未设置且未设置out_features,将默认为最后一个阶段。必须按照stage_names属性中定义的顺序。 -
apply_layernorm(bool,可选,默认为True) — 是否在模型用作骨干时对特征图应用层归一化。 -
reshape_hidden_states(bool,可选,默认为True) — 是否将特征图重塑为形状为(batch_size, hidden_size, height, width)的 4D 张量,以便在模型用作骨干时使用。如果为False,特征图将是形状为(batch_size, seq_len, hidden_size)的 3D 张量。
这是一个配置类,用于存储 Dinov2Model 的配置。它用于根据指定的参数实例化 Dinov2 模型,定义模型架构。使用默认值实例化配置将产生类似于 Dinov2 google/dinov2-base-patch16-224 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import Dinov2Config, Dinov2Model
>>> # Initializing a Dinov2 dinov2-base-patch16-224 style configuration
>>> configuration = Dinov2Config()
>>> # Initializing a model (with random weights) from the dinov2-base-patch16-224 style configuration
>>> model = Dinov2Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configDinov2Model
class transformers.Dinov2Model
( config: Dinov2Config )参数
config(Dinov2Config) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的 DINOv2 模型变压器输出原始隐藏状态,没有特定的头部。此模型是 PyTorch torch.nn.Module 的子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: Optional = None bool_masked_pos: Optional = None head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 BitImageProcessor.preprocess()。 -
bool_masked_pos(torch.BoolTensor,形状为(batch_size, sequence_length)) — 布尔掩盖位置。指示哪些补丁被掩盖(1)哪些没有(0)。仅适用于预训练。 -
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),optional) — 用于使自注意力模块中选择的头部失效的掩码。掩码值选在[0, 1]:- 1 表示头部未被掩盖,
- 0 表示头部被掩盖。
-
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回的张量中的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回的张量中的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个 torch.FloatTensor 元组(如果传递了return_dict=False或当config.return_dict=False时)包含根据配置(Dinov2Config)和输入的各种元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
pooler_output(torch.FloatTensor,形状为(batch_size, hidden_size)) — 经过辅助预训练任务中使用的层进一步处理后的序列第一个标记(分类标记)的最后一层隐藏状态。例如,对于 BERT 系列模型,这将返回经过线性层和 tanh 激活函数处理后的分类标记。线性层的权重是从预训练期间的下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),optional,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型具有嵌入层,则为嵌入输出的输出+每层的输出)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
Dinov2Model 的前向方法,覆盖__call__特殊方法。
尽管前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默忽略它们。
示例:
>>> from transformers import AutoImageProcessor, Dinov2Model
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/dinov2-base")
>>> model = Dinov2Model.from_pretrained("facebook/dinov2-base")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 257, 768]Dinov2ForImageClassification
class transformers.Dinov2ForImageClassification
( config: Dinov2Config )参数
config(Dinov2Config) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
在顶部带有图像分类头的 Dinov2 模型变换器(在[CLS]标记的最终隐藏状态之上的线性层),例如用于 ImageNet。
此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( pixel_values: Optional = None head_mask: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.ImageClassifierOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 BitImageProcessor.preprocess()。 -
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),optional) — 用于使自注意力模块中选择的头部失效的掩码。掩码值选在[0, 1]之间:- 1 表示头部未被
掩码, - 0 表示头部被
掩码。
- 1 表示头部未被
-
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensor,形状为(batch_size,),optional) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.ImageClassifierOutput 或 tuple(torch.FloatTensor)
transformers.modeling_outputs.ImageClassifierOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(Dinov2Config)和输入的不同元素。
-
loss(torch.FloatTensorof shape(1,), 可选的, 当提供labels时返回) — 分类(如果 config.num_labels==1 则为回归)损失。 -
logits(torch.FloatTensorof shape(batch_size, config.num_labels)) — 分类(如果 config.num_labels==1 则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor), 可选的, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入输出的一个 + 每个阶段输出的一个)。模型在每个阶段输出的隐藏状态(也称为特征图)。 -
attentions(tuple(torch.FloatTensor), 可选的, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, patch_size, sequence_length)的torch.FloatTensor元组(每个层一个)。 注意力权重在注意力 Softmax 之后,用于计算自注意力头中的加权平均值。
Dinov2ForImageClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, Dinov2ForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/dinov2-small-imagenet1k-1-layer")
>>> model = Dinov2ForImageClassification.from_pretrained("facebook/dinov2-small-imagenet1k-1-layer")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby catDiT
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/dit
概述
DiT 是由 Junlong Li、Yiheng Xu、Tengchao Lv、Lei Cui、Cha Zhang、Furu Wei 在DiT: Self-supervised Pre-training for Document Image Transformer中提出的。DiT 将 BEiT(图像变换器的 BERT 预训练)的自监督目标应用于 4200 万个文档图像,从而在包括以下任务在内的任务上取得了最先进的结果:
- 文档图像分类:RVL-CDIP数据集(包含 40 万张属于 16 个类别之一的图像)。
- 文档布局分析:PubLayNet数据集(由自动解析 PubMed XML 文件构建的超过 36 万个文档图像的集合)。
- 表格检测:ICDAR 2019 cTDaR数据集(包含 600 个训练图像和 240 个测试图像)。
论文摘要如下:
最近,图像变换器在自然图像理解方面取得了显著进展,无论是使用监督(ViT,DeiT 等)还是自监督(BEiT,MAE 等)的预训练技术。在本文中,我们提出了 DiT,这是一个自监督预训练的文档图像变换器模型,使用大规模未标记的文本图像进行文档 AI 任务,这是必不可少的,因为由于缺乏人工标记的文档图像,不存在任何监督对应物。我们将 DiT 作为各种基于视觉的文档 AI 任务的骨干网络,包括文档图像分类、文档布局分析以及表格检测。实验结果表明,自监督预训练的 DiT 模型在这些下游任务上取得了新的最先进结果,例如文档图像分类(91.11 → 92.69)、文档布局分析(91.0 → 94.9)和表格检测(94.23 → 96.55)。
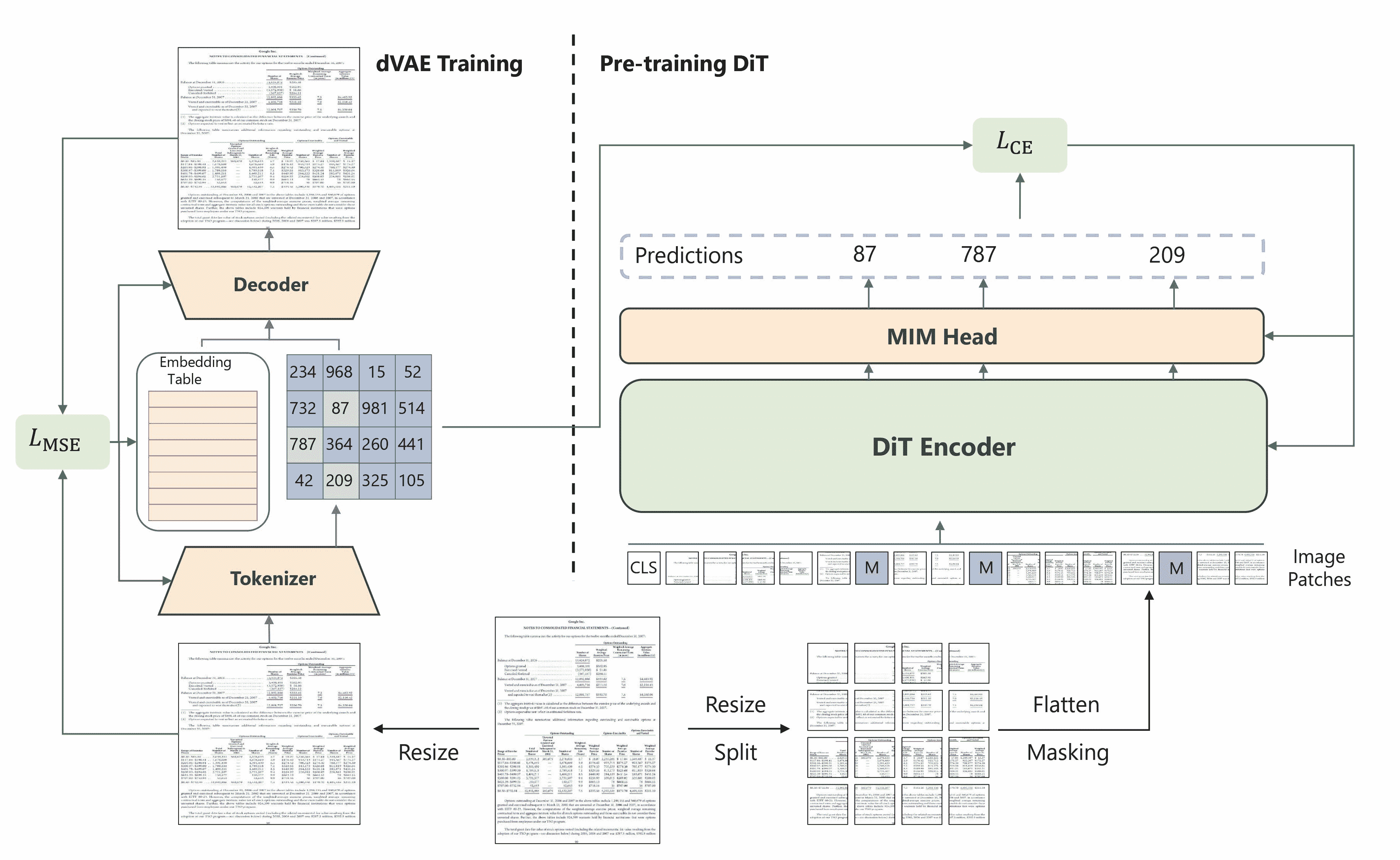
drawing
方法概述。摘自原始论文。
使用提示
可以直接使用 AutoModel API 中的 DiT 权重:
from transformers import AutoModel
model = AutoModel.from_pretrained("microsoft/dit-base")这将加载在遮蔽图像建模上预训练的模型。请注意,这不会包括顶部的语言建模头,用于预测视觉标记。
要包含头部,可以将权重加载到BeitForMaskedImageModeling模型中,如下所示:
from transformers import BeitForMaskedImageModeling
model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")您还可以从hub加载一个经过微调的模型,如下所示:
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")这个特定的检查点在RVL-CDIP上进行了微调,这是文档图像分类的重要基准。一个展示文档图像分类推理的笔记本可以在这里找到。
资源
Hugging Face 官方和社区(🌎表示)资源列表,帮助您开始使用 DiT。
图像分类
如果您有兴趣提交一个资源以包含在这里,请随时打开一个 Pull Request,我们将对其进行审查!资源应该理想地展示一些新东西,而不是重复现有资源。
由于 DiT 的架构与 BEiT 相当,因此可以参考 BEiT 的文档页面 获取所有提示、代码示例和笔记本。
DPT
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/dpt
概述
DPT 模型由 René Ranftl、Alexey Bochkovskiy、Vladlen Koltun 在 Vision Transformers for Dense Prediction 中提出。DPT 是一个利用 Vision Transformer (ViT) 作为密集预测任务(如语义分割和深度估计)的骨干的模型。
论文摘要如下:
我们介绍了密集视觉变换器,这是一种利用视觉变换器代替卷积网络作为密集预测任务骨干的架构。我们从视觉变换器的各个阶段汇集令牌,将它们组合成各种分辨率的图像表示,并逐渐将它们结合成使用卷积解码器进行全分辨率预测。变换器骨干以恒定且相对较高的分辨率处理表示,并在每个阶段具有全局感受野。这些特性使得密集视觉变换器在与完全卷积网络相比提供更精细和更全局一致的预测。我们的实验表明,这种架构在密集预测任务上取得了显著的改进,特别是当有大量训练数据可用时。对于单目深度估计,我们观察到与最先进的完全卷积网络相比,性能相对提高了高达 28%。当应用于语义分割时,密集视觉变换器在 ADE20K 上取得了 49.02% mIoU 的新的最先进水平。我们进一步展示,该架构可以在较小的数据集(如 NYUv2、KITTI 和 Pascal Context)上进行微调,也在这些数据集上取得了新的最先进水平。
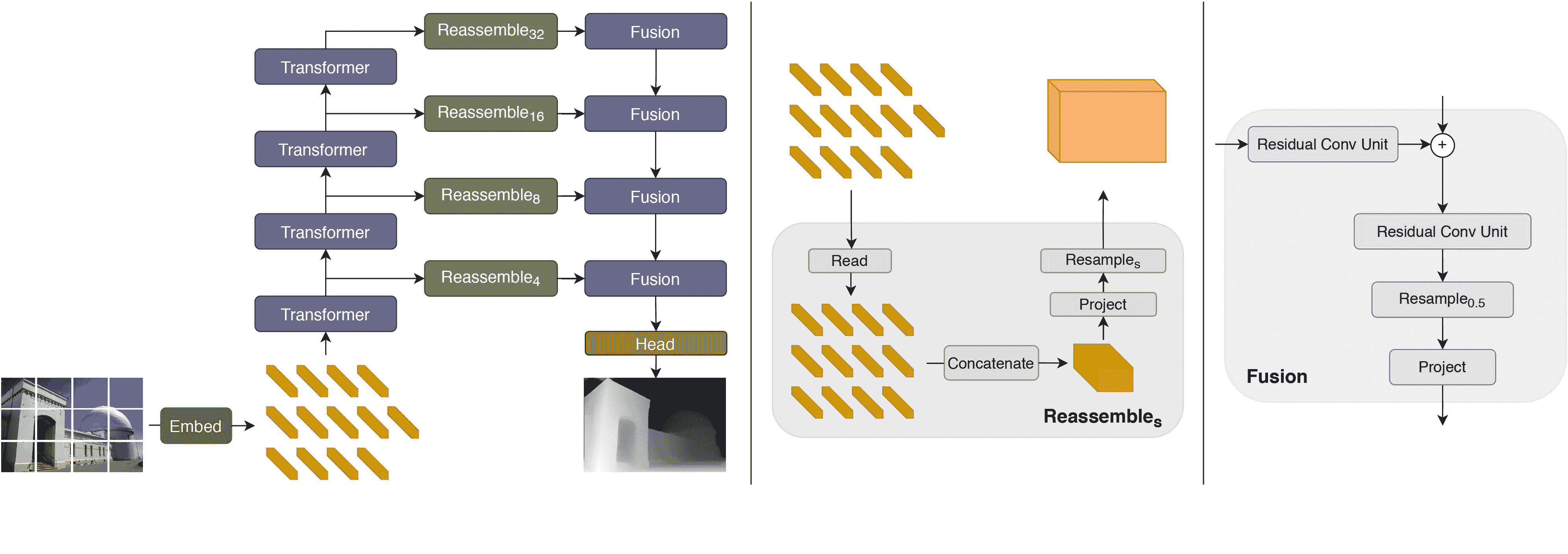
drawing
DPT 架构。摘自原始论文。
使用提示
DPT 兼容 AutoBackbone 类。这允许使用库中提供的各种计算机视觉骨干(如 VitDetBackbone 或 Dinov2Backbone)与 DPT 框架一起使用。可以按照以下方式创建它:
from transformers import Dinov2Config, DPTConfig, DPTForDepthEstimation
# initialize with a Transformer-based backbone such as DINOv2
# in that case, we also specify `reshape_hidden_states=False` to get feature maps of shape (batch_size, num_channels, height, width)
backbone_config = Dinov2Config.from_pretrained("facebook/dinov2-base", out_features=["stage1", "stage2", "stage3", "stage4"], reshape_hidden_states=False)
config = DPTConfig(backbone_config=backbone_config)
model = DPTForDepthEstimation(config=config)资源
以下是官方 Hugging Face 和社区(🌎 标志)资源列表,可帮助您开始使用 DPT。
- DPTForDepthEstimation 的演示笔记本可以在这里找到。
- 语义分割任务指南
- 单目深度估计任务指南
如果您有兴趣提交资源以包含在此处,请随时提交拉取请求,我们将进行审查!资源应该展示一些新内容,而不是重复现有资源。
DPTConfig
transformers.DPTConfig 类
( hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-12 image_size = 384 patch_size = 16 num_channels = 3 is_hybrid = False qkv_bias = True backbone_out_indices = [2, 5, 8, 11] readout_type = 'project' reassemble_factors = [4, 2, 1, 0.5] neck_hidden_sizes = [96, 192, 384, 768] fusion_hidden_size = 256 head_in_index = -1 use_batch_norm_in_fusion_residual = False use_bias_in_fusion_residual = None add_projection = False use_auxiliary_head = True auxiliary_loss_weight = 0.4 semantic_loss_ignore_index = 255 semantic_classifier_dropout = 0.1 backbone_featmap_shape = [1, 1024, 24, 24] neck_ignore_stages = [0, 1] backbone_config = None **kwargs )参数
-
hidden_size(int, 可选, 默认为 768) — 编码器层和池化层的维度。 -
num_hidden_layers(int, 可选, 默认为 12) — Transformer 编码器中的隐藏层数。 -
num_attention_heads(int, 可选, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 -
intermediate_size(int, 可选, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 -
hidden_act(str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","selu"和"gelu_new"。 -
hidden_dropout_prob(float, optional, defaults to 0.0) — 嵌入、编码器和池化器中所有全连接层的 dropout 概率。 -
attention_probs_dropout_prob(float, optional, defaults to 0.0) — 注意力概率的 dropout 比率。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float, optional, defaults to 1e-12) — 层归一化层使用的 epsilon。 -
image_size(int, optional, defaults to 384) — 每个图像的大小(分辨率)。 -
patch_size(int, optional, defaults to 16) — 每个补丁的大小(分辨率)。 -
num_channels(int, optional, defaults to 3) — 输入通道数。 -
is_hybrid(bool, optional, defaults toFalse) — 是否使用混合主干。在加载 DPT-Hybrid 模型的情况下很有用。 -
qkv_bias(bool, optional, defaults toTrue) — 是否为查询、键和值添加偏置。 -
backbone_out_indices(List[int], optional, defaults to[2, 5, 8, 11]) — 要从主干使用的中间隐藏状态的索引。 -
readout_type(str, optional, defaults to"project") — 处理 ViT 主干中间隐藏状态的读出标记(CLS 标记)时要使用的读出类型。可以是["ignore","add","project"]之一。- “ignore” 简单地忽略 CLS 标记。
- “add” 通过将 CLS 标记的信息添加到所有其他标记中传递表示。
- “project” 通过将读出连接到所有其他标记,然后使用线性层将表示投影到原始特征维度 D,接着使用 GELU 非线性传递信息给其他标记。
-
reassemble_factors(List[int], optional, defaults to[4, 2, 1, 0.5]) — 重组层的上/下采样因子。 -
neck_hidden_sizes(List[str], optional, defaults to[96, 192, 384, 768]) — 要投影到主干特征图的隐藏大小。 -
fusion_hidden_size(int, optional, defaults to 256) — 融合前的通道数。 -
head_in_index(int, optional, defaults to -1) — 在头部中要使用的特征的索引。 -
use_batch_norm_in_fusion_residual(bool, optional, defaults toFalse) — 是否在融合块的预激活残差单元中使用批归一化。 -
use_bias_in_fusion_residual(bool, optional, defaults toTrue) — 是否在融合块的预激活残差单元中使用偏置。 -
add_projection(bool, optional, defaults toFalse) — 是否在深度估计头之前添加投影层。 -
use_auxiliary_head(bool, optional, defaults toTrue) — 训练时是否使用辅助头。 -
auxiliary_loss_weight(float, optional, defaults to 0.4) — 辅助头的交叉熵损失权重。 -
semantic_loss_ignore_index(int, optional, defaults to 255) — 语义分割模型损失函数中被忽略的索引。 -
semantic_classifier_dropout(float, optional, defaults to 0.1) — 语义分类头的 dropout 比率。 -
backbone_featmap_shape(List[int], optional, defaults to[1, 1024, 24, 24]) — 仅用于hybrid嵌入类型。主干特征图的形状。 -
neck_ignore_stages(List[int], optional, defaults to[0, 1]) — 仅用于hybrid嵌入类型。要忽略的读出层阶段。 -
backbone_config(Union[Dict[str, Any], PretrainedConfig], optional) — 主干模型的配置。仅在is_hybrid为True或者想要利用AutoBackboneAPI 时使用。
这是配置类,用于存储 DPTModel 的配置。它用于根据指定的参数实例化一个 DPT 模型,定义模型架构。使用默认值实例化配置将产生类似于DPT Intel/dpt-large架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import DPTModel, DPTConfig
>>> # Initializing a DPT dpt-large style configuration
>>> configuration = DPTConfig()
>>> # Initializing a model from the dpt-large style configuration
>>> model = DPTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configto_dict
( )将此实例序列化为 Python 字典。覆盖默认的 to_dict()。返回:Dict[str, any]:构成此配置实例的所有属性的字典,
DPTFeatureExtractor
class transformers.DPTFeatureExtractor
( *args **kwargs )__call__
( images **kwargs )预处理图像或一批图像。
post_process_semantic_segmentation
( outputs target_sizes: List = None ) → export const metadata = 'undefined';semantic_segmentation参数
-
outputs(DPTForSemanticSegmentation)— 模型的原始输出。 -
target_sizes(长度为batch_size的List[Tuple],可选)— 对应于每个预测的请求最终大小(高度,宽度)的元组列表。如果未设置,预测将不会被调整大小。
返回
语义分割
长度为batch_size的List[torch.Tensor],其中每个项目是形状为(高度,宽度)的语义分割地图,对应于target_sizes条目(如果指定了target_sizes)。每个torch.Tensor的每个条目对应于语义类别 ID。
将 DPTForSemanticSegmentation 的输出转换为语义分割地图。仅支持 PyTorch。
DPTImageProcessor
class transformers.DPTImageProcessor
( do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BICUBIC: 3> keep_aspect_ratio: bool = False ensure_multiple_of: int = 1 do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None do_pad: bool = False size_divisor: int = None **kwargs )参数
-
do_resize(bool,可选,默认为True)— 是否调整图像的(高度,宽度)尺寸。可以被preprocess中的do_resize覆盖。 -
size(Dict[str, int]可选,默认为{"height" -- 384, "width": 384}):调整大小后的图像尺寸。可以被preprocess中的size覆盖。 -
resample(PILImageResampling,可选,默认为Resampling.BICUBIC)— 如果调整图像大小,则定义要使用的重采样滤波器。可以被preprocess中的resample覆盖。 -
keep_aspect_ratio(bool,可选,默认为False)— 如果为True,则将图像调整为保持纵横比的最大可能尺寸。可以被preprocess中的keep_aspect_ratio覆盖。 -
ensure_multiple_of(int,可选,默认为 1)— 如果do_resize为True,则将图像调整为此值的倍数。可以被preprocess中的ensure_multiple_of覆盖。 -
do_rescale(bool,可选,默认为True)— 是否按指定比例rescale_factor重新缩放图像。可以被preprocess中的do_rescale覆盖。 -
rescale_factor(int或float,optional,默认为1/255) — 如果重新缩放图像,则使用的缩放因子。可以被preprocess中的rescale_factor覆盖。 -
do_normalize(bool,optional,默认为True) — 是否对图像进行归一化。可以被preprocess方法中的do_normalize参数覆盖。 -
image_mean(float或List[float],optional,默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_mean参数覆盖。 -
image_std(float或List[float],optional,默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_std参数覆盖。 -
do_pad(bool,optional,默认为False) — 是否应用中心填充。这在 DINOv2 论文中引入,该论文将该模型与 DPT 结合使用。 -
size_divisor(int,optional) — 如果do_pad为True,则填充图像尺寸使其可被该值整除。这在 DINOv2 论文中引入,该论文将该模型与 DPT 结合使用。
构造一个 DPT 图像处理器。
preprocess
( images: Union do_resize: bool = None size: int = None keep_aspect_ratio: bool = None ensure_multiple_of: int = None resample: Resampling = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: Union = None image_std: Union = None do_pad: bool = None size_divisor: int = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )参数
-
images(ImageInput) — 要预处理的图像。期望单个图像或批量图像,像素值范围为 0 到 255。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
do_resize(bool,optional,默认为self.do_resize) — 是否调整图像大小。 -
size(Dict[str, int], optional, defaults toself.size) — 调整大小后的图像尺寸。如果keep_aspect_ratio为True,则将图像调整大小为保持纵横比的最大可能尺寸。如果设置了ensure_multiple_of,则将图像调整大小为该值的倍数。 -
keep_aspect_ratio(bool,optional,默认为self.keep_aspect_ratio) — 是否保持图像的纵横比。如果为 False,则将图像调整大小为(size,size)。如果为 True,则将图像调整大小以保持纵横比,大小将是最大可能的。 -
ensure_multiple_of(int,optional,默认为self.ensure_multiple_of) — 确保图像大小是该值的倍数。 -
resample(int,optional,默认为self.resample) — 如果调整图像大小,则要使用的重采样滤波器。这可以是枚举PILImageResampling之一,仅在do_resize设置为True时有效。 -
do_rescale(bool,optional,默认为self.do_rescale) — 是否将图像值重新缩放在[0 - 1]之间。 -
rescale_factor(float,optional,默认为self.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的缩放因子。 -
do_normalize(bool,optional,默认为self.do_normalize) — 是否对图像进行归一化。 -
image_mean(float或List[float],optional,默认为self.image_mean) — 图像均值。 -
image_std(float或List[float],optional,默认为self.image_std) — 图像标准差。 -
return_tensors(str或TensorType,optional) — 要返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf':返回类型为tf.Tensor的批处理。 -
TensorType.PYTORCH或'pt':返回类型为torch.Tensor的批处理。 -
TensorType.NUMPY或'np':返回类型为np.ndarray的批处理。 -
TensorType.JAX或'jax':返回类型为jax.numpy.ndarray的批处理。
- 未设置:返回一个
-
data_format(ChannelDimension或str,optional,默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
ChannelDimension.FIRST:图像以(num_channels,height,width)格式。 -
ChannelDimension.LAST: 图像以(高度,宽度,通道数)格式。
-
-
input_data_format(ChannelDimension或str,可选)— 输入图像的通道维度格式。如果未设置,将从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST: 图像以(通道数,高度,宽度)格式。 -
"channels_last"或ChannelDimension.LAST: 图像以(高度,宽度,通道数)格式。 -
"none"或ChannelDimension.NONE: 图像以(高度,宽度)格式。
-
对图像或图像批次进行预处理。
post_process_semantic_segmentation
( outputs target_sizes: List = None ) → export const metadata = 'undefined';semantic_segmentation参数
-
outputs(DPTForSemanticSegmentation)— 模型的原始输出。 -
target_sizes(长度为batch_size的List[Tuple],可选)— 与每个预测的请求最终大小(高度,宽度)对应的元组列表。如果未设置,预测将不会被调整大小。
返回
semantic_segmentation
长度为batch_size的 List[torch.Tensor],其中每个项目是形状为(高度,宽度)的语义分割地图,对应于 target_sizes 条目(如果指定了 target_sizes)。每个 torch.Tensor 的每个条目对应于一个语义类别 id。
将 DPTForSemanticSegmentation 的输出转换为语义分割地图。仅支持 PyTorch。
DPTModel
class transformers.DPTModel
( config add_pooling_layer = True )参数
config(ViTConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的 DPT 模型变压器输出原始的隐藏状态,没有特定的头部。这个模型是 PyTorch torch.nn.Module 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: FloatTensor head_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.dpt.modeling_dpt.BaseModelOutputWithPoolingAndIntermediateActivations or tuple(torch.FloatTensor)参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)— 像素值。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 DPTImageProcessor.call()。 -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于使自注意力模块的选定头部无效的掩码。掩码值选定在[0, 1]之间:- 1 表示头部为
未屏蔽, - 0 表示头部为
已屏蔽。
- 1 表示头部为
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通元组。
返回
transformers.models.dpt.modeling_dpt.BaseModelOutputWithPoolingAndIntermediateActivations 或 tuple(torch.FloatTensor)
一个transformers.models.dpt.modeling_dpt.BaseModelOutputWithPoolingAndIntermediateActivations或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(DPTConfig)和输入的各种元素。
-
last_hidden_state(torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 -
pooler_output(torch.FloatTensorof shape(batch_size, hidden_size)) — 序列第一个标记(分类标记)的最后一层隐藏状态(经过用于辅助预训练任务的层进一步处理后)的输出。例如,对于 BERT 系列模型,这返回经过线性层和 tanh 激活函数处理后的分类标记。线性层权重是从预训练期间的下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。 -
intermediate_activations(tuple(torch.FloatTensor),可选) — 可用于计算各层模型隐藏状态的中间激活。
DPTModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, DPTModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("Intel/dpt-large")
>>> model = DPTModel.from_pretrained("Intel/dpt-large")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 577, 1024]DPTForDepthEstimation
class transformers.DPTForDepthEstimation
( config )参数
config(ViTConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
带有深度估计头部的 DPT 模型(包含 3 个卷积层),例如用于 KITTI、NYUv2。
这个模型是 PyTorch 的torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( pixel_values: FloatTensor head_mask: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.DepthEstimatorOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 AutoImageProcessor 获得。有关详细信息,请参阅 DPTImageProcessor.call()。 -
head_mask(形状为(num_heads,)或(num_layers, num_heads)的torch.FloatTensor,可选)— 用于使自注意力模块中的选定头部失效的掩码。掩码值选择在[0, 1]之间:- 1 表示头部未被屏蔽,
- 0 表示头部被屏蔽。
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请查看返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回 ModelOutput 而不是普通元组。 -
labels(形状为(batch_size, height, width)的torch.LongTensor,可选)— 用于计算损失的地面真实深度估计图。
返回
transformers.modeling_outputs.DepthEstimatorOutput 或tuple(torch.FloatTensor)
transformers.modeling_outputs.DepthEstimatorOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(DPTConfig)和输入的不同元素。
-
loss(形状为(1,)的torch.FloatTensor,可选,当提供labels时返回)— 分类(或如果config.num_labels==1则为回归)损失。 -
predicted_depth(形状为(batch_size, height, width)的torch.FloatTensor)— 每个像素的预测深度。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组(如果模型有嵌入层的输出一个,+ 每一层的输出一个)。 模型在每一层输出的隐藏状态加上可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)— 形状为(batch_size, num_heads, patch_size, sequence_length)的torch.FloatTensor元组(每层一个)。 在自注意力头中用于计算加权平均值的注意力权重在注意力 softmax 之后。
DPTForDepthEstimation 的前向方法,覆盖__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, DPTForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("Intel/dpt-large")
>>> model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
... predicted_depth = outputs.predicted_depth
>>> # interpolate to original size
>>> prediction = torch.nn.functional.interpolate(
... predicted_depth.unsqueeze(1),
... size=image.size[::-1],
... mode="bicubic",
... align_corners=False,
... )
>>> # visualize the prediction
>>> output = prediction.squeeze().cpu().numpy()
>>> formatted = (output * 255 / np.max(output)).astype("uint8")
>>> depth = Image.fromarray(formatted)DPTForSemanticSegmentation
class transformers.DPTForSemanticSegmentation
( config )参数
config(ViTConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
带有语义分割头的 DPT 模型,例如 ADE20k,CityScapes。
这个模型是一个 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: Optional = None head_mask: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.SemanticSegmenterOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 AutoImageProcessor 获取。有关详细信息,请参阅 DPTImageProcessor.call()。 -
head_mask(torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块的选定头部失效的掩码。掩码值选定在[0, 1]中:- 1 表示头部未被遮罩,
- 0 表示头部被遮罩。
-
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 -
labels(torch.LongTensor,形状为(batch_size, height, width),可选) — 用于计算损失的地面真实语义分割地图。索引应在[0, ..., config.num_labels - 1]中。如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SemanticSegmenterOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SemanticSegmenterOutput 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False)包含各种元素,具体取决于配置(DPTConfig)和输入。
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果config.num_labels==1)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels, logits_height, logits_width)) — 每个像素的分类分数。 返回的 logits 不一定与作为输入传递的pixel_values具有相同的大小。这是为了避免进行两次插值并在用户需要将 logits 调整为原始图像大小时丢失一些质量。您应该始终检查您的 logits 形状并根据需要调整大小。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, patch_size, hidden_size)的torch.FloatTensor元组(如果模型具有嵌入层,则为嵌入的输出的一个+每层输出的一个)。 模型在每一层输出时的隐藏状态加上可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, patch_size, sequence_length)的torch.FloatTensor元组(每层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
DPTForSemanticSegmentation 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的步骤需要在这个函数中定义,但应该在此之后调用 Module 实例,而不是这个函数,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, DPTForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("Intel/dpt-large-ade")
>>> model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logitsEfficientFormer
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/efficientformer
概述
EfficientFormer 模型是由 Yanyu Li, Geng Yuan, Yang Wen, Eric Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren 在EfficientFormer: Vision Transformers at MobileNet Speed中提出的。EfficientFormer 提出了一个维度一致的纯 Transformer,可以在移动设备上运行,用于像图像分类、目标检测和语义分割这样的密集预测任务。
论文摘要如下:
Vision Transformers(ViT)在计算机视觉任务中取得了快速进展,在各种基准测试中取得了令人满意的结果。然而,由于参数数量庞大和模型设计(如注意力机制)等原因,基于 ViT 的模型通常比轻量级卷积网络慢。因此,将 ViT 部署到实时应用中尤为具有挑战性,特别是在资源受限的硬件上,如移动设备。最近的努力通过网络架构搜索或与 MobileNet 块混合设计来减少 ViT 的计算复杂性,但推理速度仍然不尽人意。这带来了一个重要问题:可以让 transformers 像 MobileNet 一样快速运行并获得高性能吗?为了回答这个问题,我们首先重新审视了 ViT-based 模型中使用的网络架构和运算符,并确定了低效的设计。然后,我们引入了一个维度一致的纯 Transformer(不包含 MobileNet 块)作为设计范式。最后,我们进行了基于延迟的精简,得到了一系列被称为 EfficientFormer 的最终模型。大量实验证明了 EfficientFormer 在移动设备上性能和速度方面的优越性。我们最快的模型 EfficientFormer-L1,在 iPhone 12 上(使用 CoreML 编译),仅需 1.6 毫秒的推理延迟就能实现 ImageNet-1K 的 79.2% top-1 准确率,这与 MobileNetV2×1.4(1.6 毫秒,74.7% top-1)一样快,而我们最大的模型 EfficientFormer-L7,在仅 7.0 毫秒的延迟下获得了 83.3%的准确率。我们的工作证明了经过合理设计的 transformers 可以在移动设备上达到极低的延迟,同时保持高性能。
这个模型是由novice03和Bearnardd贡献的。原始代码可以在这里找到。这个模型的 TensorFlow 版本是由D-Roberts添加的。
文档资源
- 图像分类任务指南
EfficientFormerConfig
class transformers.EfficientFormerConfig
( depths: List = [3, 2, 6, 4] hidden_sizes: List = [48, 96, 224, 448] downsamples: List = [True, True, True, True] dim: int = 448 key_dim: int = 32 attention_ratio: int = 4 resolution: int = 7 num_hidden_layers: int = 5 num_attention_heads: int = 8 mlp_expansion_ratio: int = 4 hidden_dropout_prob: float = 0.0 patch_size: int = 16 num_channels: int = 3 pool_size: int = 3 downsample_patch_size: int = 3 downsample_stride: int = 2 downsample_pad: int = 1 drop_path_rate: float = 0.0 num_meta3d_blocks: int = 1 distillation: bool = True use_layer_scale: bool = True layer_scale_init_value: float = 1e-05 hidden_act: str = 'gelu' initializer_range: float = 0.02 layer_norm_eps: float = 1e-12 image_size: int = 224 batch_norm_eps: float = 1e-05 **kwargs )参数
-
depths(List(int), 可选, 默认为[3, 2, 6, 4]) — 每个阶段的深度。 -
hidden_sizes(List(int), 可选, 默认为[48, 96, 224, 448]) — 每个阶段的维度。 -
downsamples(List(bool), 可选, 默认为[True, True, True, True]) — 是否在两个阶段之间对输入进行下采样。 -
dim(int, 可选, 默认为 448) — Meta3D 层中的通道数量 -
key_dim(int, 可选, 默认为 32) — meta3D 块中键的大小。 -
attention_ratio(int, 可选, 默认为 4) — MSHA 块中查询和值的维度与键的维度之比 -
resolution(int, 可选, 默认为 7) — 每个 patch 的大小 -
num_hidden_layers(int, 可选, 默认为 5) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, 可选, 默认为 8) — 3D MetaBlock 中每个注意力层的注意力头数量。 -
mlp_expansion_ratio(int,可选,默认为 4) — MLP 隐藏维度大小与其输入维度大小的比率。 -
hidden_dropout_prob(float,可选,默认为 0.1) — 嵌入和编码器中所有全连接层的丢弃概率。 -
patch_size(int,可选,默认为 16) — 每个补丁的大小(分辨率)。 -
num_channels(int,可选,默认为 3) — 输入通道的数量。 -
pool_size(int,可选,默认为 3) — 池化层的核大小。 -
downsample_patch_size(int,可选,默认为 3) — 下采样层中补丁的大小。 -
downsample_stride(int,可选,默认为 2) — 下采样层中卷积核的步幅。 -
downsample_pad(int,可选,默认为 1) — 下采样层中的填充。 -
drop_path_rate(int,可选,默认为 0) — 在 DropPath 中增加丢失概率的速率。 -
num_meta3d_blocks(int,可选,默认为 1) — 最后阶段中的 3D MetaBlocks 的数量。 -
distillation(bool,可选,默认为True) — 是否添加蒸馏头。 -
use_layer_scale(bool,可选,默认为True) — 是否对标记混合器的输出进行缩放。 -
layer_scale_init_value(float,可选,默认为 1e-5) — 从标记混合器输出进行缩放的因子。 -
hidden_act(str或function,可选,默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 -
initializer_range(float,可选,默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float,可选,默认为 1e-12) — 层归一化层使用的 epsilon。 -
image_size(int,可选,默认为224) — 每个图像的大小(分辨率)。
这是一个配置类,用于存储 EfficientFormerModel 的配置。根据指定的参数实例化 EfficientFormer 模型,定义模型架构。使用默认值实例化配置将产生类似于 EfficientFormer snap-research/efficientformer-l1 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import EfficientFormerConfig, EfficientFormerModel
>>> # Initializing a EfficientFormer efficientformer-l1 style configuration
>>> configuration = EfficientFormerConfig()
>>> # Initializing a EfficientFormerModel (with random weights) from the efficientformer-l3 style configuration
>>> model = EfficientFormerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configEfficientFormerImageProcessor
class transformers.EfficientFormerImageProcessor
( do_resize: bool = True size: Optional = None resample: Resampling = <Resampling.BICUBIC: 3> do_center_crop: bool = True do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 crop_size: Dict = None do_normalize: bool = True image_mean: Union = None image_std: Union = None **kwargs )参数
-
do_resize(bool,可选,默认为True) — 是否将图像的(高度、宽度)维度调整为指定的(size["height"], size["width"])。可以被preprocess方法中的do_resize参数覆盖。 -
size(dict,可选,默认为{"height" -- 224, "width": 224}):调整大小后的输出图像大小。可以被preprocess方法中的size参数覆盖。 -
resample(PILImageResampling,可选,默认为PILImageResampling.BILINEAR) — 调整图像大小时要使用的重采样滤波器。可以被preprocess方法中的resample参数覆盖。 -
do_center_crop(bool,可选,默认为True) — 是否将图像居中裁剪到指定的crop_size。可以被preprocess方法中的do_center_crop覆盖。 -
crop_size(Dict[str, int]可选,默认为 224) — 应用center_crop后输出图像的大小。可以被preprocess方法中的crop_size覆盖。 -
do_rescale(bool,可选,默认为True) — 是否按指定比例rescale_factor重新缩放图像。可以被preprocess方法中的do_rescale参数覆盖。 -
rescale_factor(int或float,可选,默认为1/255) — 如果重新缩放图像,则使用的比例因子。可以被preprocess方法中的rescale_factor参数覆盖。do_normalize — 是否对图像进行归一化。可以被preprocess方法中的do_normalize参数覆盖。 -
image_mean(float或List[float],可选,默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像中通道数相同长度的浮点数列表。可以被preprocess方法中的image_mean参数覆盖。 -
image_std(float或List[float],可选,默认为IMAGENET_STANDARD_STD) — 如果do_normalize设置为True,则使用的标准差。这是一个浮点数或与图像中通道数相同长度的浮点数列表。可以被preprocess方法中的image_std参数覆盖。
构建一个 EfficientFormer 图像处理器。
preprocess
( images: Union do_resize: Optional = None size: Dict = None resample: Resampling = None do_center_crop: bool = None crop_size: int = None do_rescale: Optional = None rescale_factor: Optional = None do_normalize: Optional = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: Union = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )参数
-
images(ImageInput) — 要预处理的图像。期望单个或批量图像,像素值范围为 0 到 255。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
do_resize(bool,可选,默认为self.do_resize) — 是否调整图像大小。 -
size(Dict[str, int],可选,默认为self.size) — 以{"height": h, "width": w}格式指定调整大小后输出图像的大小的字典。 -
resample(PILImageResampling过滤器,可选,默认为self.resample) — 调整图像大小时要使用的PILImageResampling过滤器,例如PILImageResampling.BILINEAR。仅在do_resize设置为True时有效。 -
do_center_crop(bool,可选,默认为self.do_center_crop) — 是否对图像进行中心裁剪。 -
do_rescale(bool,可选,默认为self.do_rescale) — 是否将图像值重新缩放在[0 - 1]之间。 -
rescale_factor(float,可选,默认为self.rescale_factor) — 如果do_rescale设置为True,则重新缩放图像的缩放因子。 -
crop_size(Dict[str, int],可选,默认为self.crop_size) — 中心裁剪的大小。仅在do_center_crop设置为True时有效。 -
do_normalize(bool,可选,默认为self.do_normalize) — 是否对图像进行归一化。 -
image_mean(float或List[float],可选,默认为self.image_mean) — 如果do_normalize设置为True,则使用的图像均值。 -
image_std(float或List[float],可选,默认为self.image_std) — 如果do_normalize设置为True,则使用的图像标准差。 -
return_tensors(str或TensorType,可选) — 要返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf':返回类型为tf.Tensor的批处理。 -
TensorType.PYTORCH或'pt':返回类型为torch.Tensor的批处理。 -
TensorType.NUMPY或'np':返回类型为np.ndarray的批处理。 -
TensorType.JAX或'jax':返回类型为jax.numpy.ndarray的批处理。
- 未设置:返回一个
-
data_format(ChannelDimension或str,可选,默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以(通道数,高度,宽度)格式。 -
"channels_last"或ChannelDimension.LAST:图像以(高度,宽度,通道数)格式。 - 未设置:使用输入图像的通道维度格式。
-
-
input_data_format(ChannelDimension或str,可选) — 输入图像的通道维度格式。如果未设置,则从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以(通道数,高度,宽度)格式。 -
"channels_last"或ChannelDimension.LAST:图像以(高度,宽度,通道数)格式。 -
"none"或ChannelDimension.NONE:图像以(高度,宽度)格式。
-
预处理一张图像或一批图像。
PytorchHide Pytorch 内容
EfficientFormerModel
class transformers.EfficientFormerModel
( config: EfficientFormerConfig )参数
config(EfficientFormerConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
EfficientFormer 模型是一个裸的 transformer 模型,输出原始的隐藏状态,没有特定的头部。这个模型是 PyTorch nn.Module的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor) — 像素值。可以使用 ViTImageProcessor 获取像素值。有关详细信息,请参阅 ViTImageProcessor.preprocess()。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool,可选) — 是否返回一个 ModelOutput 而不是一个普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含各种元素,取决于配置(EfficientFormerConfig)和输入。
-
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor) — 模型最后一层的输出的隐藏状态序列。 -
pooler_output(形状为(batch_size, hidden_size)的torch.FloatTensor) — 序列的最后一层隐藏状态的第一个标记(分类标记)经过用于辅助预训练任务的层进一步处理后的隐藏状态。例如,对于 BERT 系列模型,这返回经过线性层和 tanh 激活函数处理后的分类标记。线性层的权重是从预训练期间的下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor), 可选的, 当传递output_hidden_states=True或者当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。 模型在每一层输出的隐藏状态以及可选的初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), 可选的, 当传递output_attentions=True或者当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组。 在自注意力头中用于计算加权平均值的注意力 softmax 之后的注意力权重。
EfficientFormerModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, EfficientFormerModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("snap-research/efficientformer-l1-300")
>>> model = EfficientFormerModel.from_pretrained("snap-research/efficientformer-l1-300")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 49, 448]高效的图像分类器
class transformers.EfficientFormerForImageClassification
( config: EfficientFormerConfig )参数
config(EfficientFormerConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
高效的图像分类器模型变换器,顶部带有一个图像分类头(在[CLS]标记的最终隐藏状态之上的线性层),例如用于 ImageNet。
这个模型是 PyTorch 的nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有信息。
forward
( pixel_values: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.ImageClassifierOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 ViTImageProcessor 获取。查看 ViTImageProcessor.preprocess()获取详细信息。 -
output_attentions(bool, 可选的) — 是否返回所有注意力层的注意力张量。查看返回的张量中的attentions以获取更多细节。 -
output_hidden_states(bool, 可选的) — 是否返回所有层的隐藏状态。查看返回的张量中的hidden_states以获取更多细节。 -
return_dict(bool, 可选的) — 是否返回一个 ModelOutput 而不是一个普通的元组。 -
labels(torch.LongTensor,形状为(batch_size,),可选的) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.ImageClassifierOutput 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.ImageClassifierOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包含根据配置(EfficientFormerConfig)和输入的各种元素。
-
loss(torch.FloatTensor,形状为(1,),可选,当提供labels时返回) — 分类(如果 config.num_labels==1 则为回归)损失。 -
logits(torch.FloatTensor,形状为(batch_size, config.num_labels)) — 分类(如果 config.num_labels==1 则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组。模型在每个阶段输出的隐藏状态(也称为特征图)。 -
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, patch_size, sequence_length)的torch.FloatTensor元组。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
EfficientFormerForImageClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在这个函数内定义,但应该在此之后调用Module实例,而不是在此之后调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, EfficientFormerForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("snap-research/efficientformer-l1-300")
>>> model = EfficientFormerForImageClassification.from_pretrained("snap-research/efficientformer-l1-300")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
Egyptian catEfficientFormerForImageClassificationWithTeacher
class transformers.EfficientFormerForImageClassificationWithTeacher
( config: EfficientFormerConfig )参数
config(EfficientFormerConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
EfficientFormer 模型变压器,顶部带有图像分类头(在[CLS]令牌的最终隐藏状态上方有一个线性层,以及在蒸馏令牌的最终隐藏状态上方有一个线性层),例如用于 ImageNet。
此模型仅支持推断。目前不支持使用蒸馏(即使用教师)进行微调。
这个模型是 PyTorch nn.Module的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
forward
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.efficientformer.modeling_efficientformer.EfficientFormerForImageClassificationWithTeacherOutput or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 ViTImageProcessor 获取。有关详细信息,请参阅 ViTImageProcessor.preprocess()。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.efficientformer.modeling_efficientformer.EfficientFormerForImageClassificationWithTeacherOutput或tuple(torch.FloatTensor)
一个transformers.models.efficientformer.modeling_efficientformer.EfficientFormerForImageClassificationWithTeacherOutput或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包含根据配置(EfficientFormerConfig)和输入的各种元素。
-
logits(torch.FloatTensorof shape(batch_size, config.num_labels)) — 预测分数,作为 cls_logits 和蒸馏 logits 的平均值。 -
cls_logits(torch.FloatTensorof shape(batch_size, config.num_labels)) — 分类头的预测分数(即类令牌的最终隐藏状态之上的线性层)。 -
distillation_logits(torch.FloatTensorof shape(batch_size, config.num_labels)) — 蒸馏头部的预测分数(即蒸馏令牌的最终隐藏状态之上的线性层)。 -
hidden_states(tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个层的输出)。模型在每个层的输出隐藏状态加上初始嵌入输出。 -
attentions(tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
EfficientFormerForImageClassificationWithTeacher 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, EfficientFormerForImageClassificationWithTeacher
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("snap-research/efficientformer-l1-300")
>>> model = EfficientFormerForImageClassificationWithTeacher.from_pretrained("snap-research/efficientformer-l1-300")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
Egyptian catTensorFlow 隐藏 TensorFlow 内容
TFEfficientFormerModel
class transformers.TFEfficientFormerModel
( config: EfficientFormerConfig **kwargs )参数
config(EfficientFormerConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 EfficientFormer 模型变压器输出原始隐藏状态,没有特定的头部。此模型是一个 TensorFlow tf.keras.layers.Layer。将其用作常规 TensorFlow 模块,并参考 TensorFlow 文档以获取与一般用法和行为相关的所有事项。
call
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None training: bool = False ) → export const metadata = 'undefined';transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling or tuple(tf.Tensor)参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的tf.Tensor) — 像素值。可以使用 AutoImageProcessor 获取像素值。有关详细信息,请参阅 EfficientFormerImageProcessor.call()。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,optional) — 是否返回一个 ModelOutput 而不是一个普通元组。
返回
transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling 或一个 tf.Tensor 元组(如果传递 return_dict=False 或 config.return_dict=False 时)包含根据配置(EfficientFormerConfig)和输入的各种元素。
-
last_hidden_state(tf.Tensor,形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 -
pooler_output(tf.Tensor,形状为(batch_size, hidden_size)) — 序列第一个标记(分类标记)的最后一层隐藏状态,经过线性层和 Tanh 激活函数进一步处理。线性层的权重是在预训练期间从下一个句子预测(分类)目标中训练的。 这个输出通常不是输入语义内容的良好摘要,通常最好对整个输入序列的隐藏状态序列进行平均或池化。 -
hidden_states(tuple(tf.Tensor),optional,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于嵌入输出,一个用于每一层的输出)。 模型在每一层输出处的隐藏状态以及初始嵌入输出。 -
attentions(tuple(tf.Tensor),optional,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。 注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFEfficientFormerModel 的前向方法,覆盖了 __call__ 特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用 Module 实例,而不是在此处调用,因为前者会处理运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, TFEfficientFormerModel
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("snap-research/efficientformer-l1-300")
>>> model = TFEfficientFormerModel.from_pretrained("snap-research/efficientformer-l1-300")
>>> inputs = image_processor(image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 49, 448]TFEfficientFormerForImageClassification
class transformers.TFEfficientFormerForImageClassification
( config: EfficientFormerConfig )参数
config(EfficientFormerConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
在池化的最后隐藏状态之上具有图像分类头的 EfficientFormer 模型变压器,例如用于 ImageNet。
此模型是一个 TensorFlow tf.keras.layers.Layer。将其用作常规的 TensorFlow 模块,并参考 TensorFlow 文档以获取与一般用法和行为相关的所有内容。
call
( pixel_values: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None training: bool = False ) → export const metadata = 'undefined';transformers.modeling_tf_outputs.TFImageClassifierOutput or tuple(tf.Tensor)参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的tf.Tensor) — 像素值。像素值可以使用 AutoImageProcessor 获取。有关详细信息,请参阅 EfficientFormerImageProcessor.call()。 -
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 -
labels(tf.Tensor,形状为(batch_size,),可选) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_tf_outputs.TFImageClassifierOutput或tuple(tf.Tensor)
一个transformers.modeling_tf_outputs.TFImageClassifierOutput或一个tf.Tensor元组(如果传递return_dict=False或config.return_dict=False)包含根据配置(EfficientFormerConfig)和输入的各种元素。
-
loss(tf.Tensor,形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果config.num_labels==1)损失。 -
logits(tf.Tensor,形状为(batch_size, config.num_labels)) — 分类(或回归,如果config.num_labels==1)得分(SoftMax 之前)。 -
hidden_states(tuple(tf.Tensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(如果模型具有嵌入层,则为嵌入的输出 + 每个阶段的输出)。模型在每个阶段输出的隐藏状态(也称为特征图)。 -
attentions(tuple(tf.Tensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, patch_size, sequence_length)的tf.Tensor元组(每层一个)。 在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
TFEfficientFormerForImageClassification 前向方法,覆盖了__call__特殊方法。
尽管前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, TFEfficientFormerForImageClassification
>>> import tensorflow as tf
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("snap-research/efficientformer-l1-300")
>>> model = TFEfficientFormerForImageClassification.from_pretrained("snap-research/efficientformer-l1-300")
>>> inputs = image_processor(image, return_tensors="tf")
>>> logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = int(tf.math.argmax(logits, axis=-1))
>>> print(model.config.id2label[predicted_label])
LABEL_281TFEfficientFormerForImageClassificationWithTeacher
class transformers.TFEfficientFormerForImageClassificationWithTeacher
( config: EfficientFormerConfig )参数
config(EfficientFormerConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
EfficientFormer 模型转换器,顶部带有图像分类头(位于最终隐藏状态的顶部的线性层和位于蒸馏令牌的最终隐藏状态的顶部的线性层),例如用于 ImageNet。
… 警告:: 此模型仅支持推断。尚不支持使用蒸馏进行微调(即使用教师)。
此模型是一个 TensorFlow tf.keras.layers.Layer。将其用作常规的 TensorFlow 模块,并参考 TensorFlow 文档以获取与一般用法和行为相关的所有事项。
call
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None training: bool = False ) → export const metadata = 'undefined';transformers.models.efficientformer.modeling_tf_efficientformer.TFEfficientFormerForImageClassificationWithTeacherOutput or tuple(tf.Tensor)参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的tf.Tensor) — 像素值。像素值可以使用 AutoImageProcessor 获取。有关详细信息,请参阅 EfficientFormerImageProcessor.call()。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.efficientformer.modeling_tf_efficientformer.TFEfficientFormerForImageClassificationWithTeacherOutput或tuple(tf.Tensor)
一个transformers.models.efficientformer.modeling_tf_efficientformer.TFEfficientFormerForImageClassificationWithTeacherOutput或一个tf.Tensor元组(如果传递了return_dict=False或当config.return_dict=False时),包括根据配置(EfficientFormerConfig)和输入的各种元素。
TFEfficientFormerForImageClassificationWithTeacher 前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
- EfficientFormerForImageClassificationWithTeacher 的
Output类型。logits(形状为(batch_size, config.num_labels)的tf.Tensor)- 预测分数,作为 cls_logits 和蒸馏 logits 的平均值。cls_logits(形状为(batch_size, config.num_labels)的tf.Tensor)- 分类头部的预测分数(即类令牌最终隐藏状态顶部的线性层)。distillation_logits(形状为(batch_size, config.num_labels)的tf.Tensor)- 蒸馏头部的预测分数(即蒸馏令牌最终隐藏状态顶部的线性层)。hidden_states(tuple(tf.Tensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于嵌入的输出 + 一个用于每个层的输出)。模型在每个层的输出状态加上初始嵌入输出。attentions(tuple(tf.Tensor),可选,当传递output_attentions=True或config.output_attentions=True时返回)- 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每个层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
示例:
>>> from transformers import AutoImageProcessor, TFEfficientFormerForImageClassificationWithTeacher
>>> import tensorflow as tf
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("snap-research/efficientformer-l1-300")
>>> model = TFEfficientFormerForImageClassificationWithTeacher.from_pretrained("snap-research/efficientformer-l1-300")
>>> inputs = image_processor(image, return_tensors="tf")
>>> logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = int(tf.math.argmax(logits, axis=-1))
>>> print(model.config.id2label[predicted_label])
LABEL_281EfficientNet
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/efficientnet
概述
EfficientNet 模型是由 Mingxing Tan 和 Quoc V. Le 在EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks中提出的。EfficientNets 是一系列图像分类模型,实现了最先进的准确性,同时比以前的模型小一个数量级且更快。
从论文中摘录的如下:
卷积神经网络(ConvNets)通常在固定的资源预算下开发,如果有更多资源可用,则会扩展以获得更好的准确性。在本文中,我们系统地研究了模型的缩放,并确定了仔细平衡网络深度、宽度和分辨率可以带来更好的性能。基于这一观察,我们提出了一种新的缩放方法,使用简单但非常有效的复合系数均匀缩放深度/宽度/分辨率的所有维度。我们展示了这种方法在扩展 MobileNets 和 ResNet 时的有效性。为了更进一步,我们使用神经架构搜索设计了一个新的基准网络,并将其扩展为一系列模型,称为 EfficientNets,这些模型在准确性和效率方面比以前的 ConvNets 要好得多。特别是,我们的 EfficientNet-B7 在 ImageNet 上实现了最先进的 84.3%的 top-1 准确性,同时比最佳现有 ConvNet 在推理时小 8.4 倍,快 6.1 倍。我们的 EfficientNets 也具有良好的迁移性能,并在 CIFAR-100(91.7%)、Flowers(98.8%)和其他 3 个迁移学习数据集上实现了最先进的准确性,参数数量少一个数量级。
EfficientNetConfig
class transformers.EfficientNetConfig
( num_channels: int = 3 image_size: int = 600 width_coefficient: float = 2.0 depth_coefficient: float = 3.1 depth_divisor: int = 8 kernel_sizes: List = [3, 3, 5, 3, 5, 5, 3] in_channels: List = [32, 16, 24, 40, 80, 112, 192] out_channels: List = [16, 24, 40, 80, 112, 192, 320] depthwise_padding: List = [] strides: List = [1, 2, 2, 2, 1, 2, 1] num_block_repeats: List = [1, 2, 2, 3, 3, 4, 1] expand_ratios: List = [1, 6, 6, 6, 6, 6, 6] squeeze_expansion_ratio: float = 0.25 hidden_act: str = 'swish' hidden_dim: int = 2560 pooling_type: str = 'mean' initializer_range: float = 0.02 batch_norm_eps: float = 0.001 batch_norm_momentum: float = 0.99 dropout_rate: float = 0.5 drop_connect_rate: float = 0.2 **kwargs )参数
-
num_channels(int, optional, 默认为 3) — 输入通道数。 -
image_size(int, optional, 默认为 600) — 输入图像大小。 -
width_coefficient(float, optional, 默认为 2.0) — 每个阶段网络宽度的缩放系数。 -
depth_coefficient(float, optional, 默认为 3.1) — 每个阶段网络深度的缩放系数。 -
depth_divisorint, optional, 默认为 8) — 网络宽度的一个单位。 -
kernel_sizes(List[int], optional, 默认为[3, 3, 5, 3, 5, 5, 3]) — 用于每个块的内核大小列表。 -
in_channels(List[int], optional, 默认为[32, 16, 24, 40, 80, 112, 192]) — 用于卷积层中每个块的输入通道大小列表。 -
out_channels(List[int], optional, 默认为[16, 24, 40, 80, 112, 192, 320]) — 用于卷积层中每个块的输出通道大小列表。 -
depthwise_padding(List[int], optional, 默认为[]) — 具有方形填充的块索引列表。 -
strides(List[int], optional, 默认为[1, 2, 2, 2, 1, 2, 1]) — 用于卷积层中每个块的步幅大小列表。 -
num_block_repeats(List[int], optional, 默认为[1, 2, 2, 3, 3, 4, 1]) — 每个块重复的次数列表。 -
expand_ratios(List[int], optional, 默认为[1, 6, 6, 6, 6, 6, 6]) — 每个块的缩放系数列表。 -
squeeze_expansion_ratio(float, optional, 默认为 0.25) — 挤压扩展比率。 -
hidden_act(str或function, optional, 默认为"silu") — 每个块中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"、"gelu_new"、"silu"和"mish"。 -
hiddem_dim(int, optional, defaults to 1280) — 分类头之前的隐藏维度。 -
pooling_type(strorfunction, optional, defaults to"mean") — 在密集分类头之前应用的最终池化类型。可用选项为["mean","max"] -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
batch_norm_eps(float, optional, defaults to 1e-3) — 批量归一化层使用的 epsilon。 -
batch_norm_momentum(float, optional, defaults to 0.99) — 批量归一化层使用的动量。 -
dropout_rate(float, optional, defaults to 0.5) — 应用于最终分类器层之前的丢弃率。 -
drop_connect_rate(float, optional, defaults to 0.2) — 跳跃连接的丢弃率。
这是用于存储 EfficientNetModel 配置的配置类。它用于根据指定的参数实例化一个 EfficientNet 模型,定义模型架构。使用默认值实例化配置将产生类似于 EfficientNet google/efficientnet-b7架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import EfficientNetConfig, EfficientNetModel
>>> # Initializing a EfficientNet efficientnet-b7 style configuration
>>> configuration = EfficientNetConfig()
>>> # Initializing a model (with random weights) from the efficientnet-b7 style configuration
>>> model = EfficientNetModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configEfficientNetImageProcessor
class transformers.EfficientNetImageProcessor
( do_resize: bool = True size: Dict = None resample: Resampling = 0 do_center_crop: bool = False crop_size: Dict = None rescale_factor: Union = 0.00392156862745098 rescale_offset: bool = False do_rescale: bool = True do_normalize: bool = True image_mean: Union = None image_std: Union = None include_top: bool = True **kwargs )参数
-
do_resize(bool, optional, defaults toTrue) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以被preprocess中的do_resize覆盖。 -
size(Dict[str, int]optional, defaults to{"height" -- 346, "width": 346}):resize后的图像大小。可以被preprocess中的size覆盖。 -
resample(PILImageResamplingfilter, optional, defaults to 0) — 如果调整图像大小,则使用的重采样滤波器。可以被preprocess中的resample覆盖。 -
do_center_crop(bool, optional, defaults toFalse) — 是否中心裁剪图像。如果输入尺寸沿任何边小于crop_size,则图像将填充 0,然后进行中心裁剪。可以被preprocess中的do_center_crop覆盖。 -
crop_size(Dict[str, int], optional, defaults to{"height" -- 289, "width": 289}): 应用中心裁剪时的期望输出大小。可以被preprocess中的crop_size覆盖。 -
rescale_factor(intorfloat, optional, defaults to1/255) — 如果重新调整图像,则使用的比例因子。可以被preprocess方法中的rescale_factor参数覆盖。 -
rescale_offset(bool, optional, defaults toFalse) — 是否将图像重新调整到[-scale_range, scale_range]而不是[0, scale_range]。可以被preprocess方法中的rescale_factor参数覆盖。 -
do_rescale(bool, optional, defaults toTrue) — 是否按照指定的比例rescale_factor重新调整图像。可以被preprocess方法中的do_rescale参数覆盖。 -
do_normalize(bool, optional, defaults toTrue) — 是否对图像进行归一化。可以被preprocess方法中的do_normalize参数覆盖。 -
image_mean(float或List[float], 可选, 默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以通过preprocess方法中的image_mean参数覆盖。 -
image_std(float或List[float], 可选, 默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以通过preprocess方法中的image_std参数覆盖。 -
include_top(bool, 可选, 默认为True) — 是否再次对图像进行重新缩放。如果输入用于图像分类,则应设置为 True。
构建一个 EfficientNet 图像处理器。
preprocess
( images: Union do_resize: bool = None size: Dict = None resample = None do_center_crop: bool = None crop_size: Dict = None do_rescale: bool = None rescale_factor: float = None rescale_offset: bool = None do_normalize: bool = None image_mean: Union = None image_std: Union = None include_top: bool = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )参数
-
images(ImageInput) — 要预处理的图像。期望单个图像或批次的图像,像素值范围为 0 到 255。如果传入像素值在 0 到 1 之间的图像,请将do_rescale=False。 -
do_resize(bool, 可选, 默认为self.do_resize) — 是否对图像进行调整大小。 -
size(Dict[str, int], 可选, 默认为self.size) —resize后的图像大小。 -
resample(PILImageResampling, 可选, 默认为self.resample) — 调整图像大小时要使用的 PILImageResampling 过滤器。仅在do_resize设置为True时有效。 -
do_center_crop(bool, 可选, 默认为self.do_center_crop) — 是否对图像进行中心裁剪。 -
crop_size(Dict[str, int], 可选, 默认为self.crop_size) — 居中裁剪后的图像大小。如果图像的一条边小于crop_size,则会用零填充,然后裁剪。 -
do_rescale(bool, 可选, 默认为self.do_rescale) — 是否将图像值重新缩放在 [0 - 1] 之间。 -
rescale_factor(float, 可选, 默认为self.rescale_factor) — 如果do_rescale设置为True,则重新缩放图像的重新缩放因子。 -
rescale_offset(bool, 可选, 默认为self.rescale_offset) — 是否将图像重新缩放在 [-scale_range, scale_range] 范围内,而不是 [0, scale_range]。 -
do_normalize(bool, 可选, 默认为self.do_normalize) — 是否对图像进行归一化。 -
image_mean(float或List[float], 可选, 默认为self.image_mean) — 图像均值。 -
image_std(float或List[float], 可选, 默认为self.image_std) — 图像标准差。 -
include_top(bool, 可选, 默认为self.include_top) — 如果设置为 True,则再次对图像进行图像分类的重新缩放。 -
return_tensors(str或TensorType, 可选) — 要返回的张量类型。可以是以下之一:-
None: 返回一个np.ndarray列表。 -
TensorType.TENSORFLOW或'tf': 返回类型为tf.Tensor的批次。 -
TensorType.PYTORCH或'pt': 返回类型为torch.Tensor的批次。 -
TensorType.NUMPY或'np': 返回类型为np.ndarray的批次。 -
TensorType.JAX或'jax': 返回类型为jax.numpy.ndarray的批次。
-
-
data_format(ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
ChannelDimension.FIRST: 图像格式为 (通道数, 高度, 宽度)。 -
ChannelDimension.LAST: 图像格式为 (高度, 宽度, 通道数)。
-
-
input_data_format(ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST: 图像格式为 (通道数, 高度, 宽度)。 -
"channels_last"或ChannelDimension.LAST: 图像格式为 (高度, 宽度, 通道数)。 -
"none"或ChannelDimension.NONE: 图像格式为 (高度, 宽度)。
-
预处理一个图像或一批图像。
EfficientNetModel
class transformers.EfficientNetModel
( config: EfficientNetConfig )参数
config(EfficientNetConfig)- 模型的配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 EfficientNet 模型输出原始特征,没有特定的头部。这个模型是 PyTorch torch.nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有信息。
forward
( pixel_values: FloatTensor = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width))- 像素值。像素值可以使用 AutoImageProcessor 获取。有关详细信息,请参阅AutoImageProcessor.__call__()。 -
output_hidden_states(bool,可选)- 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)- 是否返回一个 ModelOutput 而不是一个普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention或tuple(torch.FloatTensor)
一个transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含根据配置(EfficientNetConfig)和输入的各种元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, num_channels, height, width))- 模型最后一层输出的隐藏状态序列。 -
pooler_output(torch.FloatTensor,形状为(batch_size, hidden_size))- 在空间维度上进行池化操作后的最后一层隐藏状态。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)- 形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每一层的输出)。 模型在每一层输出的隐藏状态加上可选的初始嵌入输出。
EfficientNetModel 的前向方法,覆盖__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, EfficientNetModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("google/efficientnet-b7")
>>> model = EfficientNetModel.from_pretrained("google/efficientnet-b7")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 768, 7, 7]EfficientNetForImageClassification
class transformers.EfficientNetForImageClassification
( config )参数
config(EfficientNetConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
在顶部带有图像分类头部的 EfficientNet 模型(在池化特征的顶部有一个线性层),例如用于 ImageNet。
此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: FloatTensor = None labels: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.ImageClassifierOutputWithNoAttention or tuple(torch.FloatTensor)参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。可以使用 AutoImageProcessor 获取像素值。查看AutoImageProcessor.__call__()获取详细信息。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。查看返回张量中的hidden_states以获取更多详细信息。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。 -
labels(torch.LongTensorof shape(batch_size,), 可选) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.ImageClassifierOutputWithNoAttention 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包含各种元素,取决于配置(EfficientNetConfig)和输入。
-
loss(torch.FloatTensorof shape(1,), 可选, 当提供labels时返回) — 分类(如果config.num_labels==1则为回归)损失。 -
logits(torch.FloatTensorof shape(batch_size, config.num_labels)) — 分类(如果config.num_labels==1则为回归)得分(SoftMax 之前)。 -
hidden_states(tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组。模型在每个阶段输出的隐藏状态(也称为特征图)。
EfficientNetForImageClassification 的前向方法,覆盖了__call__特殊方法。
虽然前向传播的步骤需要在此函数内定义,但应该在之后调用Module实例,而不是在此处调用,因为前者会处理运行前后的处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, EfficientNetForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("google/efficientnet-b7")
>>> model = EfficientNetForImageClassification.from_pretrained("google/efficientnet-b7")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby catassifierOutputWithNoAttention or tuple(torch.FloatTensor)
参数
+ `pixel_values` (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`) — 像素值。可以使用 AutoImageProcessor 获取像素值。查看`AutoImageProcessor.__call__()`获取详细信息。
+ `output_hidden_states` (`bool`, *可选*) — 是否返回所有层的隐藏状态。查看返回张量中的`hidden_states`以获取更多详细信息。
+ `return_dict` (`bool`, *可选*) — 是否返回 ModelOutput 而不是普通元组。
+ `labels` (`torch.LongTensor` of shape `(batch_size,)`, *可选*) — 用于计算图像分类/回归损失的标签。索引应在`[0, ..., config.num_labels - 1]`范围内。如果`config.num_labels == 1`,则计算回归损失(均方损失),如果`config.num_labels > 1`,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention 或 `tuple(torch.FloatTensor)`
一个 transformers.modeling_outputs.ImageClassifierOutputWithNoAttention 或一个`torch.FloatTensor`元组(如果传递`return_dict=False`或`config.return_dict=False`时)包含各种元素,取决于配置(EfficientNetConfig)和输入。
+ `loss` (`torch.FloatTensor` of shape `(1,)`, *可选*, 当提供`labels`时返回) — 分类(如果`config.num_labels==1`则为回归)损失。
+ `logits` (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`) — 分类(如果`config.num_labels==1`则为回归)得分(SoftMax 之前)。
+ `hidden_states` (`tuple(torch.FloatTensor)`, *可选*, 当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回) — 形状为`(batch_size, num_channels, height, width)`的`torch.FloatTensor`元组。模型在每个阶段输出的隐藏状态(也称为特征图)。
EfficientNetForImageClassification 的前向方法,覆盖了`__call__`特殊方法。
虽然前向传播的步骤需要在此函数内定义,但应该在之后调用`Module`实例,而不是在此处调用,因为前者会处理运行前后的处理步骤,而后者会默默地忽略它们。
示例:
```py
>>> from transformers import AutoImageProcessor, EfficientNetForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("google/efficientnet-b7")
>>> model = EfficientNetForImageClassification.from_pretrained("google/efficientnet-b7")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby cat本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号