web系统性能优化排查思路
原创

前言
从目前的系统来看,系统的优化无非就几个方向。第一个是CPU的使用,可以去分析哪一个线程占用的CPU最多,以及哪一个线程耗时最久,从这个角度去分析。第二点就是内存,你也可以去从对象的实例中去判断哪一个对象的实例最多,从而进行一个优化。再者从java的底层去分析GC的次数频不频繁。哪一些代码写的不太合理,最后就是整个架构层面的。消息积压消费,缓存是否设置的合理。这都会影响到整个架构的性能。这个章节主要是简单的描述一下。架构如何去优化他的排查思路是什么。
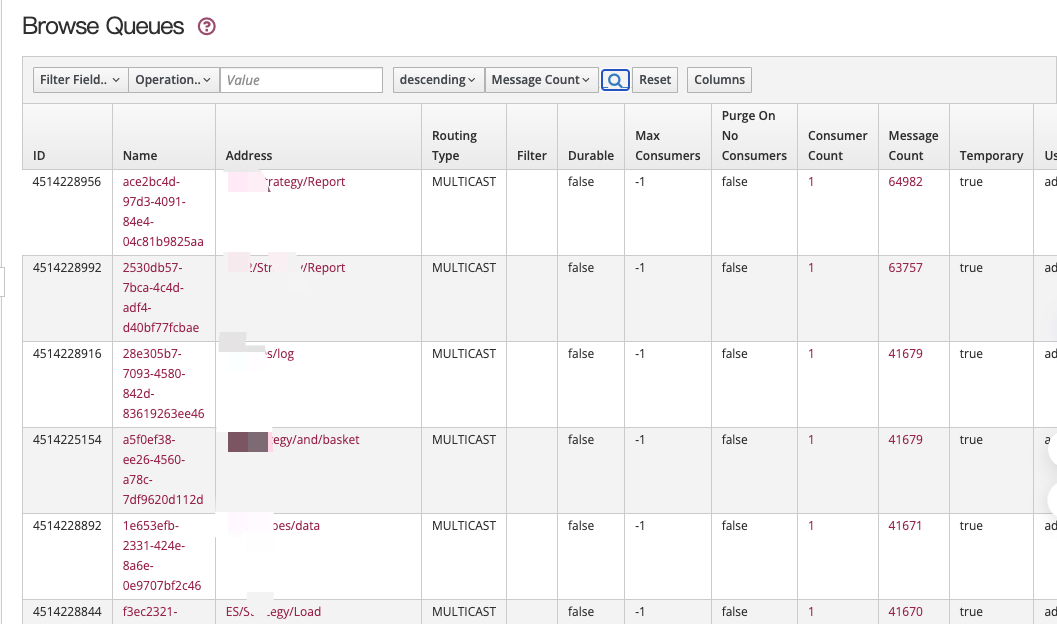
队列积压
这是我们项目目前测试环境进行一个压车的情况,将当前的消息积压已经很多了,总共达到了几十万。
队列控制台
消息日志的消息延迟

>>> 6579650/1000/60
109.66083333333333
1个半小时!
CPU占用
从目前的情况来看系统是满负载在跑的。
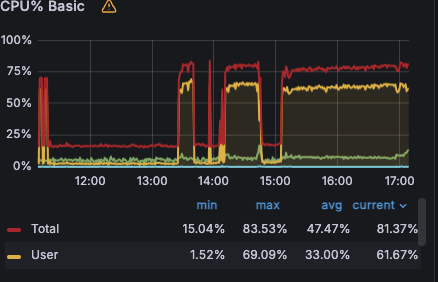
使用Arthas分析线程执行情况
发送消息优化
MessageSendService主要发送ws stomp消息,定位到具体的线程发现大量的线程等待,可以看出有很多消息正在发送导致了其他的线程处于等待状态。
优化思路:
目前是配置了一个线程,进行对比较旧的消息进行了丢弃,因为本身发送频繁有些消息发送需要6M发送耗时2秒,实在难以等待,选择丢弃一部分消息保留最新的消息推送,提高系统的可用性,不然一条消息发送2秒导致其他线程等待,得不偿失。
线程阻塞排查
oesStrategyLoadThreadPoolExecutor主要加载策略,好奇怪为什么其他的线程直接锁住了。
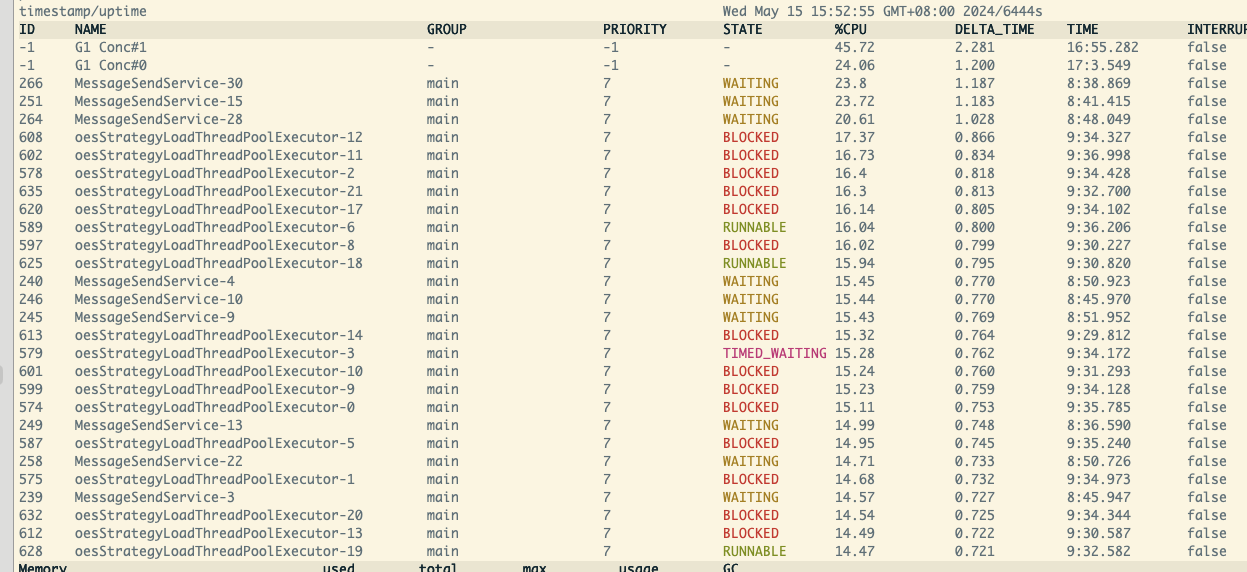
定位到具体的线程才发现他上锁了,一个线程获得了锁导致其他的线程全部阻塞等待。轻量级锁是自旋抢占,重量级锁是直接wait等待,这里可以看出这里获得锁和释放锁还是很快的。

定位到具体代码
org.apache.commons.beanutils.BeanUtilsBean#getInstance
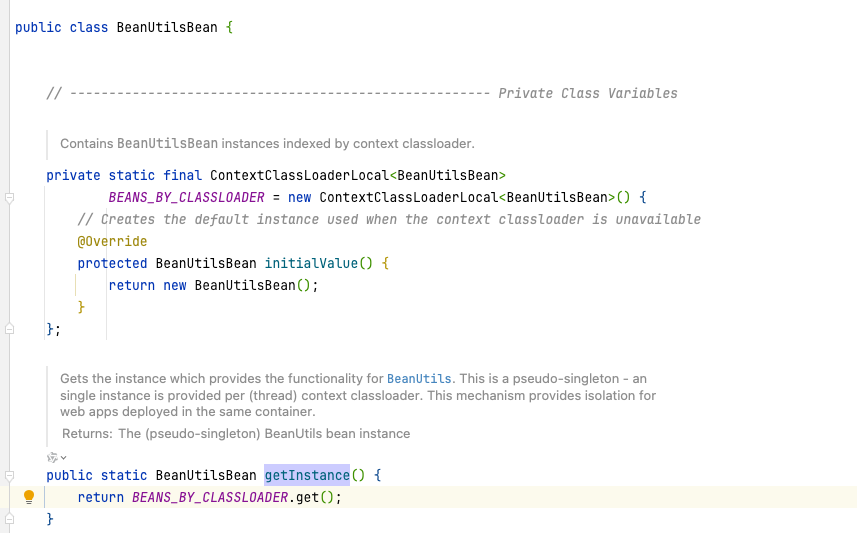
org.apache.commons.beanutils.ContextClassLoaderLocal#get

优化思路
定位到具体的代码。主要发现是由于静态类里面有一个进行一个对象属性的赋值操作。从而导致该对象被频繁的进行一个读取。可以配置成一个全局的对象,也就是常说的饿汉式或者懒汉式读取赋值方式,防止资源被频繁调用。从而进行一个锁抢占堵塞其他线程。
pg数据库慢sql
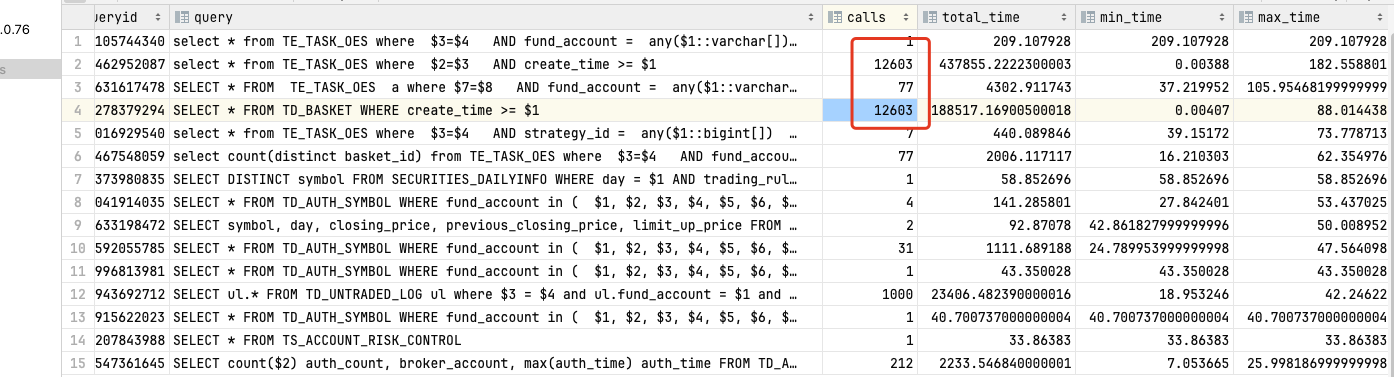
进行压测前需要对统计结果进行清空,另外pg数据默认是不会开启慢sql的需要手动开启慢sql进行统计,如何卡其自行搜索吧,这里不赘述了,这里从两个维度来查询慢sql一个是单次查询最长的sql,一个是总共统计耗时最长的sql。
-- 清空当前数据库的统计信息
SELECT pg_stat_reset();
-- 清空 pg_stat_statements 插件截止目前收集的统计信息
SELECT pg_stat_statements_reset();
-- 询执行时间最长的 5 条 SQL
SELECT total_time/1000/60 AS minute, * FROM pg_stat_statements ORDER BY total_time DESC LIMIT 15;
SELECT max_time/1000 AS second, * FROM pg_stat_statements ORDER BY max_time DESC LIMIT 15;单次耗时最长的sql,可以看到他们的总共查询次数也是最多的。这里可以定位到具体的代码来进行一个逻辑的优化。
反向推理代码

优化思路
一般数据库层面的优化除了优化sql建立索引之外,剩下的如果频繁查询可能需要建立缓存。还是要从业务层面进行一个优化,数据量大就要对数据进行一个拆分,数据量小但是查询频繁可以考虑建立缓存。
总结
最后还需要优化GC,目前来说CPU性能基本差不多压榨完了。再优化就是业务优化了,优化GC也能节省一部分时间。但优化的也不多了。总体来看的话,基本上你对一个线程或者内存进行一个优化,可能优化提高20%的样子。在之后你还是要去用多服务来进行一个消化,毕竟一台机器的能力有限。
引用
https://github.com/alibaba/arthas/issues/434
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号