分享几个有趣的大模型(LLMs)应用场景,涉及金融分析、物联网、招聘、战术分析等

分享几个有趣的大模型(LLMs)应用场景,涉及金融分析、物联网、招聘、战术分析等

ShuYini
发布于 2024-06-11 19:32:38
发布于 2024-06-11 19:32:38
引言
数字化时代,大模型以其卓越的数据处理和智能决策能力,当前应用已经渗透至了各行各业。那么,今天给大家盘点了几个比较有趣的大模型(LLMs)应用场景,其中主要包括招聘面试、代码精细化、物联网感知、金融决策、战术分析、假新闻检测、检索QA问答等。这些有趣的应用不仅展现了大模型的多面性,更预示着人工智能在未来社会中的无限可能。本文论文获取,回复:LLM场景
招聘面试

https://arxiv.org/pdf/2405.18113
传统的求职和招聘方法通常依赖于对简历和职位描述的潜在语义建模,随着大模型的应用场景的不断拓展,人大等提出了MocKLLM的新框架,旨在通过模拟面试过程提升在线招聘服务中人职匹配的质量。
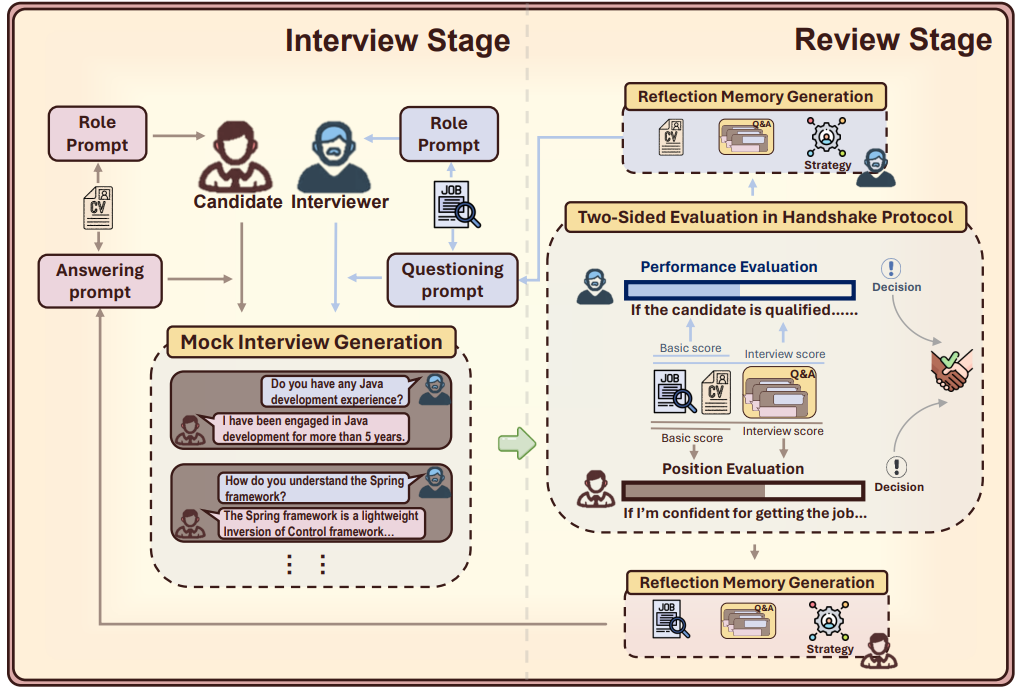
MoLLM利用大型语言模型(LLMS)扮演面试官和候选人,以提供额外的评估信息,超越了仅依赖简历和职位描述的传统方法。实验结果显示,MockLLM在提高人职匹配性能和模拟面试质量方面表现优异。
论文Idea生成
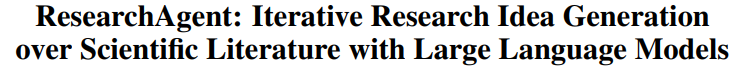
https://arxiv.org/pdf/2404.07738
本文作者利用LM构建了一个ResearchAgent系统,模仿人类产出论文idea的步骤,一步一步引导LMS生成包括问题识别、方法开发和实验设计等在内的完整研究思路,同时,引入与人类偏好一致的Revewing Agents,对生成的研究思路进行迭代优化。
该方法生成的论文idea在清晰性,相关性,原创性,可行性,重要性五大评估标准上都有不错的表现。
足球战术分析

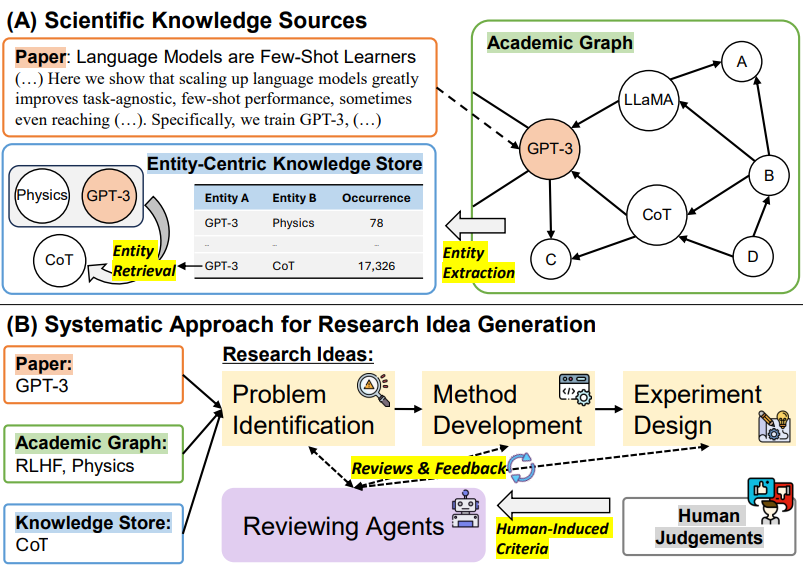
https://www.nature.com/articles/s41467-024-45965-x
TacicAI是一款人工智能系统,专门为足球比赛中的战术分析提供洞察,尤其是针对角球战术。尽管高质量的角球数据有限,但TacicAI通过使用几何深度学习方法,成功创建了更具普适性的模型,并取得了最先进的成果。在评估中,TacticAI提出的战术建议的90%都被人类专家接受。
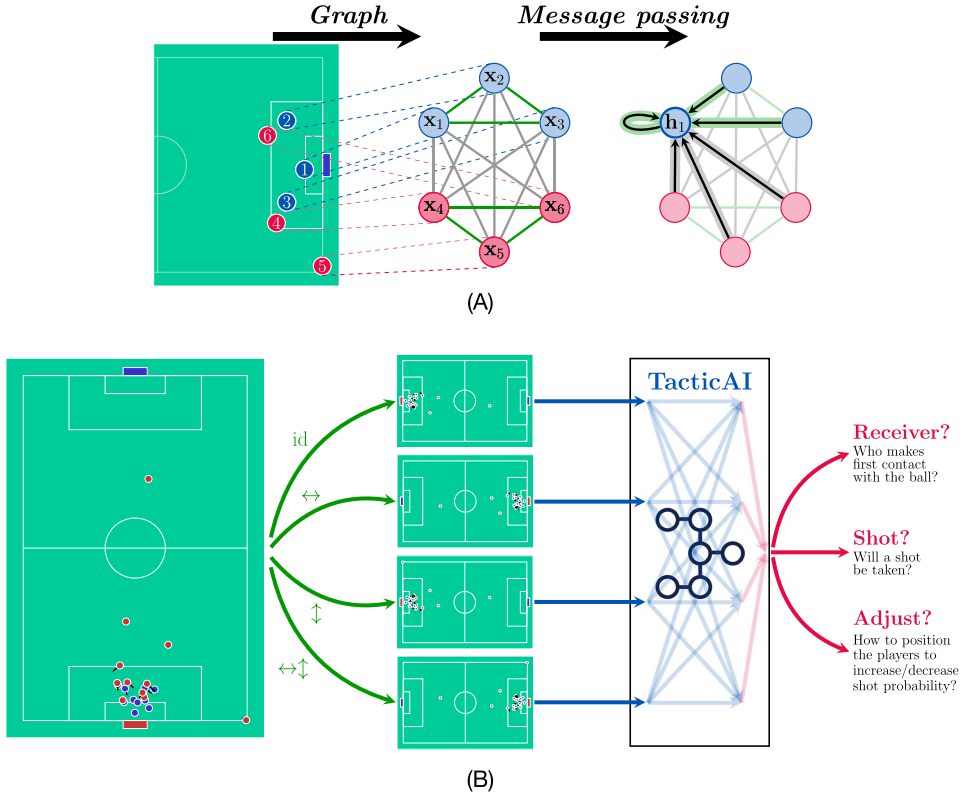
TacticAI展示了辅助性AI1技术改变体育领域的潜力,对球员、教练和球迷都可能产生革命性的影响。足球等运动是AI发展的动态领域,因为它们涉及现实世界的多智能体交互和多模态数据。在体育领域推进AI的发展可能在许多领域产生影响,从电脑游戏和机器人技术,到交通协调等方面。
代码精细化

https://arxiv.org/pdf/2405.17503
利用大模型(LMS)迭代改进源代码,即代码精细化。代码精细化是一种生成复杂程序的流行方法。给定一组测试用例,以及一个候选程序,LM可以通过prompt错误测试案例来改进该程序。但如何最好地迭代优化代码仍然是一项巨大挑战,之前的主要是工作采用了简单的贪心或广度优先策略。
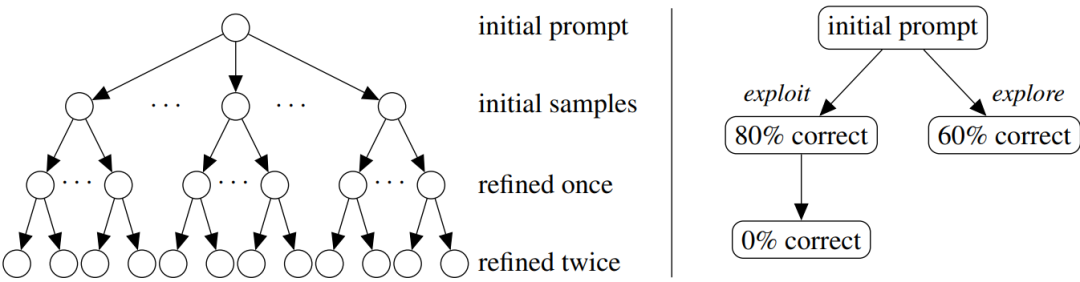
而本文作者将代码精细化视为explore-explot权衡问题:是利用通过最多测试用例的程序进行精细化,还是探索较少考虑的程序。作者将这个问题框架化为arm-acquiringbandt 问题,并使用Thompson Sampling来解决。结果表明,基于LM的程序合成算法具有广泛的适用性。在循环不变式合成、视觉推理谜题和竞赛编程问题等多个领域新方法能够使用更少的语言模型调用解决更多的问题。
物联网感知
https://arxiv.org/pdf/2405.14691
随着物联网(I0T)传感器的快速发展,产生了大量不断变化的混合数据(时空数据)。为了能够有效的处理这些混合数据,本文作者提出了CibyGPT 的框架,用于分析和学习物联网时间序列数据。
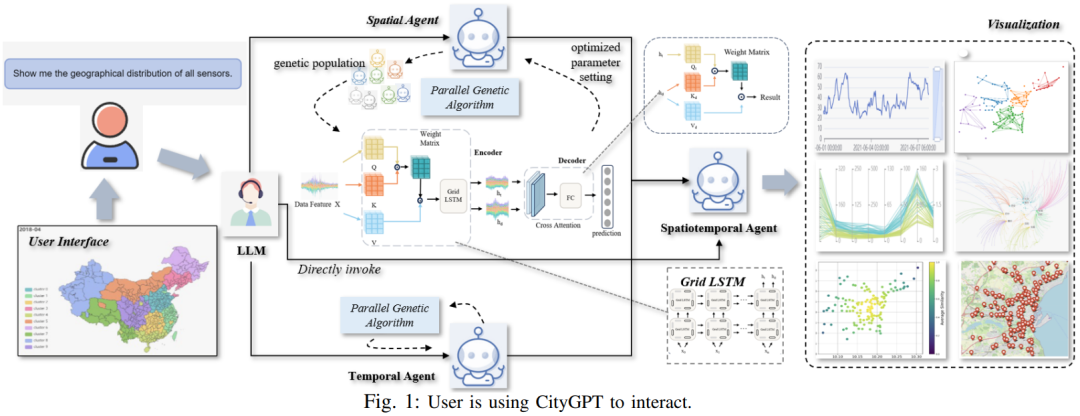
CiyGPT 采用了三个协同工作的代理:需求代理:接收用户以自然语言输入的分析任务需求;数据分析代理(时间和空间):每个代理专注于数据的-个特定方面(时间或空间)来完成分析任务;时空融合代理:将来自其他代理的结果进行组合、可视化,并根据用户需求提供文本解释,实验结果表明CGPT 在分析物联网数据方面表现良好。
金融决策

https://arxiv.org/pdf/2405.14767
本文提出了一个开源大模型Agent平台:finRobot,旨在帮助金融专业人士和普通用户利用大型语言模型(LLMS)进行高级金融分析。
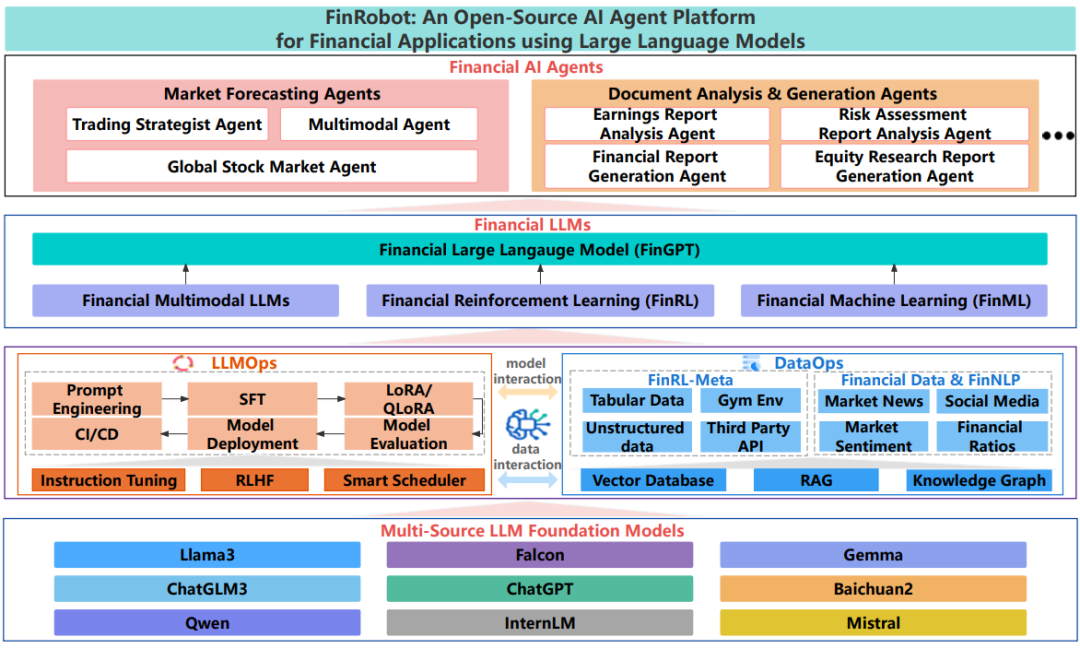
FinRobot由AI4Finance等提出,它主要包含四个主要层:1、金融AI代理层:将复杂问题分解为逻辑步骤。2、金融LLM算法层:为特定任务配置模型应用策略。3、LLMops和DataOps层:通过训练和微调技术,使用相关数据生成准确模型,4、多源LLM基础模型层:集成多种山M,提供直接访问,FinRobot通过这些层,推动金融领域AI的更广泛应用。【AI4finance 之前还发布过金融领域大模型:FinGPT,相关链接:FinGPT:一个「专用于金融领域」的开源大语言模型(LLM)框架,源码公开!】
假新闻检测
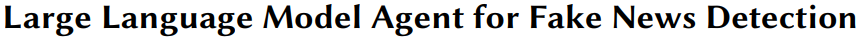
https://arxiv.org/pdf/2405.01593
在数字化时代,网络谣言对社会构成威胁,因此自动检测假新闻的需求上升。大型语言模型(LMS)因其在自然语言处理领域的卓越表现,被探索用于新闻事实核查。
本文提出了FactAgent,一种无需训练即可使用LMS识别假新间的新方法。Factgent模拟专家,通过简化的步骤和内置知识或工具来验证新闻真实性,并在决策过程中提供清晰解释。它比传统人工核查更高效,并且能够适应不同新闻领域。
检索QA问答

https://arxiv.org/pdf/2404.19705
本文探讨了大模型(LMS)如何学习使用信息检索(IR)系统进行问答,尤其是在需要额外上下文时。研究表明,在PpQA数据集中,常见问题可以通过LM的内置记忆解决,而不常见的问题则需要取系统。
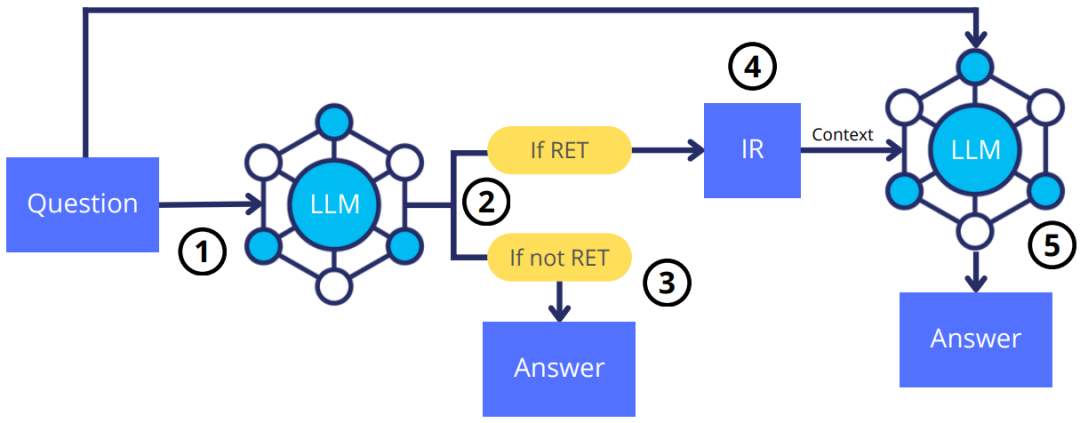
为此,提出了一种训练山Ms的新方法,使它们在不知道答案时生成特殊标记。实验显示,新方法改进了模型在PopOA数据集上的表现,模型能够智能地决定何时使用内置记忆,何时使用IR系统,且在仅使用内置记忆时准确度很高。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号