Elasticsearch中,Painless脚本通常用于计算评分、排序、聚合或者其他计算任务

Elasticsearch中,Painless脚本通常用于计算评分、排序、聚合或者其他计算任务

小冷coding
发布于 2024-05-14 12:31:08
发布于 2024-05-14 12:31:08
商品的数据存储在ES中,需要通过spuIds进行排序查询数据返回。这时就需要用到ES中的排序部分,它需要使用一个Painless脚本,根据传递的参数值对id进行排序。
最终正确返回的数据结构如下:
{
"id": "3",
"name": "第1组",
"spuIds": [19, 7, 20, 10, 2, 6, 3, 18, 9, 8, 1],
"backgroundColor": "#1677FF",
"productPages": {
"data":[
{
"id": "19",
"spuId": "1106",
"skuId": "1106",
"name": "人工牛黄甲硝唑胶囊",
"price": 39.9,
"underlinedPrice": 78.0,
"shopId": "27"
},.....],
"totalCount": 15,
"pageSize": 10,
"totalPages": 2,
"nextPage": false,
"current": 2
},
"nextPage": true,
"sort": 7
}在Elasticsearch中,Painless是一种安全、沙盒化的脚本语言,专门用于执行复杂的计算和操作。Painless的设计目标是提供一个功能强大但又足够安全的脚本环境,以便在Elasticsearch查询和聚合中执行自定义逻辑。
以下是Painless脚本在Elasticsearch中的一些常见用途:
计算评分:在搜索查询中,你可以使用Painless脚本来定义自定义的评分函数,从而影响文档的排序和排名。例如,你可以根据文档的某个字段值或其他计算来调整文档的得分。
排序:除了默认的基于字段值的排序外,你还可以使用Painless脚本来定义更复杂的排序逻辑。这意味着你可以根据文档内容的计算结果或其他动态条件对搜索结果进行排序。
聚合:在聚合查询中,Painless脚本可以用来定义聚合的桶键(bucket keys)或度量(metrics)。这允许你根据文档内容的计算结果来分组或计算聚合结果。
脚本字段:你可以使用Painless脚本来动态地添加或修改搜索结果的字段。这对于在搜索结果中包含计算后的值或格式化后的数据非常有用。
更新文档:虽然不推荐频繁使用脚本来更新文档,但在某些情况下,你可以使用Painless脚本来执行简单的文档更新操作。
需要注意的是,虽然Painless脚本提供了很大的灵活性,但过度使用或不当使用可能会对Elasticsearch集群的性能和稳定性产生负面影响。因此,在设计查询和聚合时,应谨慎使用脚本,并尽可能优化其性能。
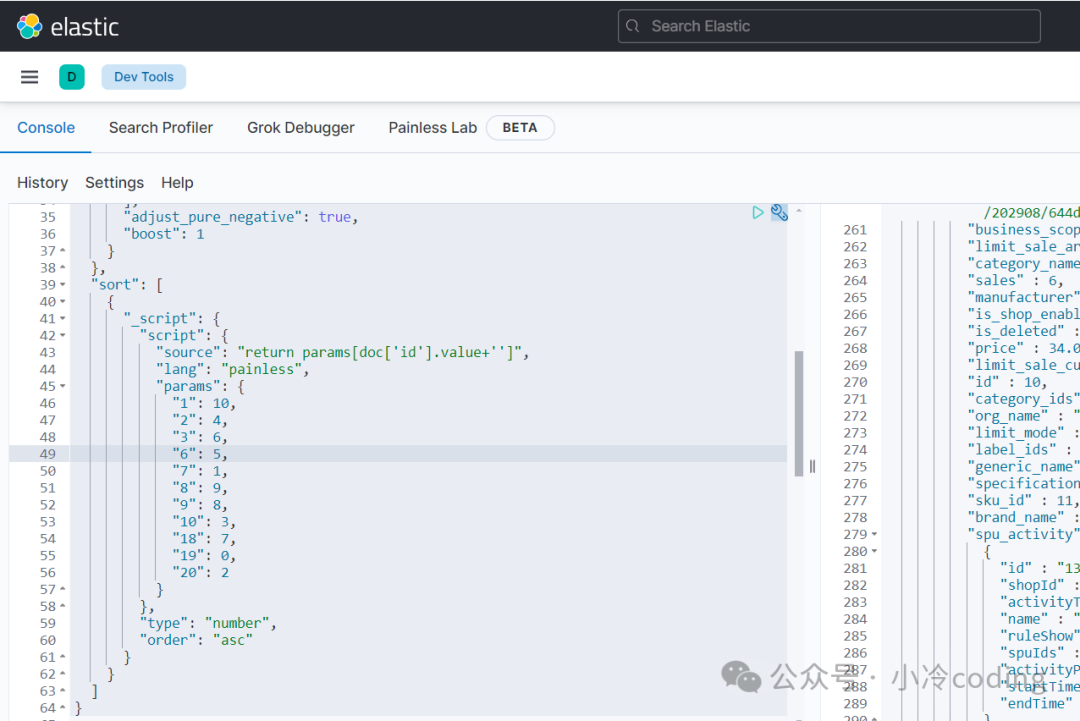
因此这次Elasticsearch的DSL查询用到的脚本如下:
GET /spu/_search
{
"from": 0,
"size": 5,
"query": {
"bool": {
"must": [
{
"terms": {
"id": [19, 7, 20, 10, 2, 6, 3, 18, 9, 8, 1]
}
},
{
"term": {
"status": 1
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"sort": [
{
"_script": {
"script": {
"source": "return params.doc['id'].value",
"lang": "painless",
"params": {
"1": 10,
"2": 4,
"3": 6,
"6": 5,
"7": 1,
"8": 9,
"9": 8,
"10": 3,
"18": 7,
"19": 0,
"20": 2
}
},
"type": "number",
"order": "asc"
}
}
]
}
你会发现params是一个Map结构,通过id进行查询排序的。
params中key就是spuId里面的参数,value就是排序的数值。
那Java中如何实现呢?代码如下:
//query.getSpuIds()查询条件
int size = query.getSpuIds().size();
Map<String, Object> scriptParams = new HashMap<>(size);
for (int i = 0; i < size; i++) {
scriptParams.put(String.valueOf(query.getSpuIds().get(i)), i);
}
// 构建排序脚本
ScriptSortBuilder scriptSortBuilder = new ScriptSortBuilder(new Script(ScriptType.INLINE, "painless",
"return params[doc['id'].value+'']",
scriptParams), ScriptSortBuilder.ScriptSortType.NUMBER);
// 执行查询
queryBuilder.withPageable(PageRequest.of(query.getCurrent() - 1, query.getPageSize()));
queryBuilder.withSort(scriptSortBuilder);写到这里问题就解决了,前台页面就能很好地展示分页结构了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号