在腾讯高性能应用服务HAI,StableDiffusion新人从0-1干货教程,一学就会系列!
原创
在腾讯高性能应用服务HAI,StableDiffusion新人从0-1干货教程,一学就会系列!
原创
about me
修改于 2024-04-04 10:56:33
修改于 2024-04-04 10:56:33
1.StableDiffusion是什么?(点击标题有超链接)
Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的转变。 它是一种潜在扩散模型,由慕尼黑大学的CompVis研究团体开发的各种生成性人工神经网络之一。(取自百度)
2.StableDiffusion的主流安装流程及为什么选择腾讯的StableDiffusion?
1.手动本地电脑安装StableDiffusion,吃电脑配置(用于ai生图)
2.谷歌云端硬盘的一键安装(目前不能使用了)优点方便快捷,可惜现在要收费,加上还要安装StableDiffusion的汉化对小白不友好。
3.腾讯高性能应用服务,里面自带了StableDiffusion并且是汉化版本,我们不要下载安装,就直接使用大大降低了我们的使用门槛。价格也是很低廉的。记得在外面买新用户1元8小时使用券(点击蓝色字体购买),不用的时候记得关闭!点击更多-确认关机!
3.在腾讯云的HAI怎么打开StableDiffusion
1.点击新建
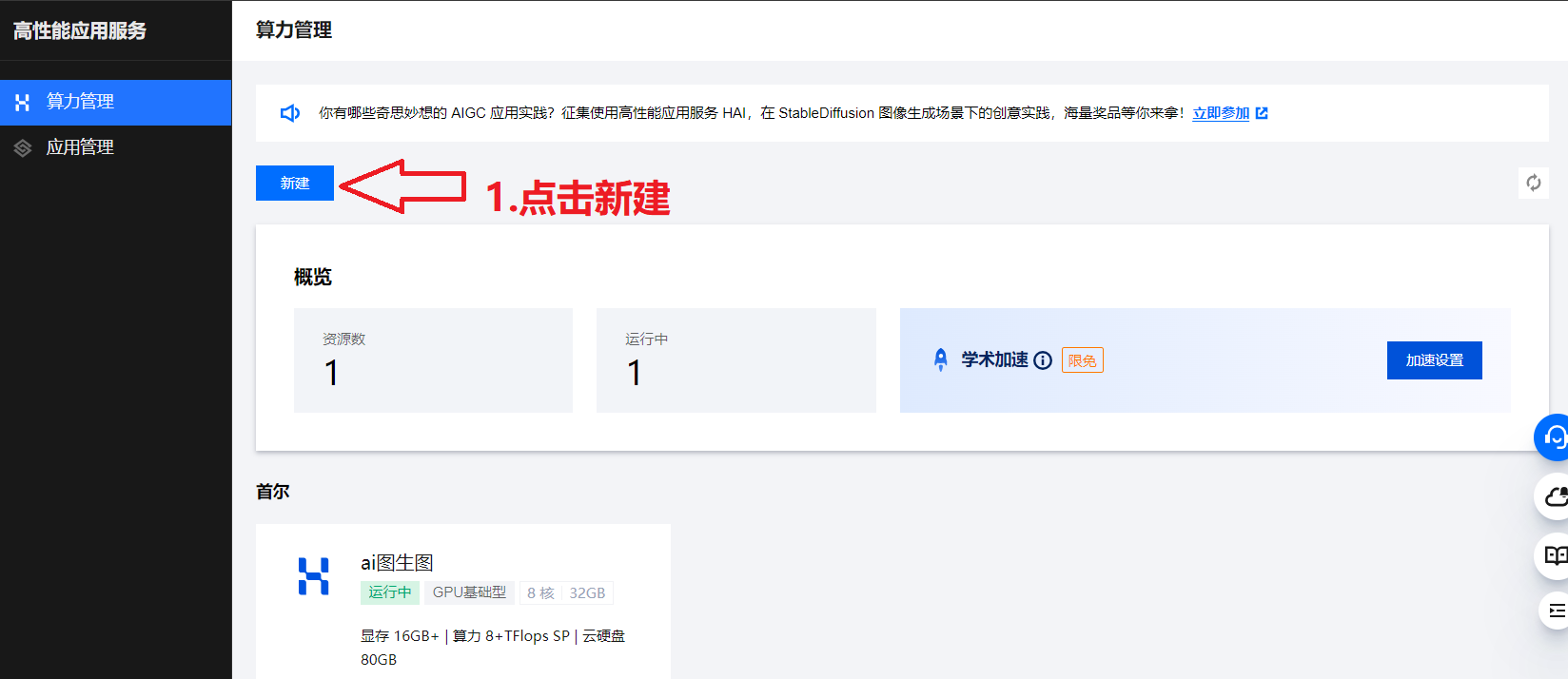
2.选择:
选择应用:StableDiffusion WebUI!
地域:国内 广州(看哪个离你家近!)
算力方案:我这边选择Gpu基础型,(看你的需求)
名称:例如:第一个AI生图
云硬盘:我这边300g(看你的需求)
3.点击算力链接 后选择 Gradio WebUI
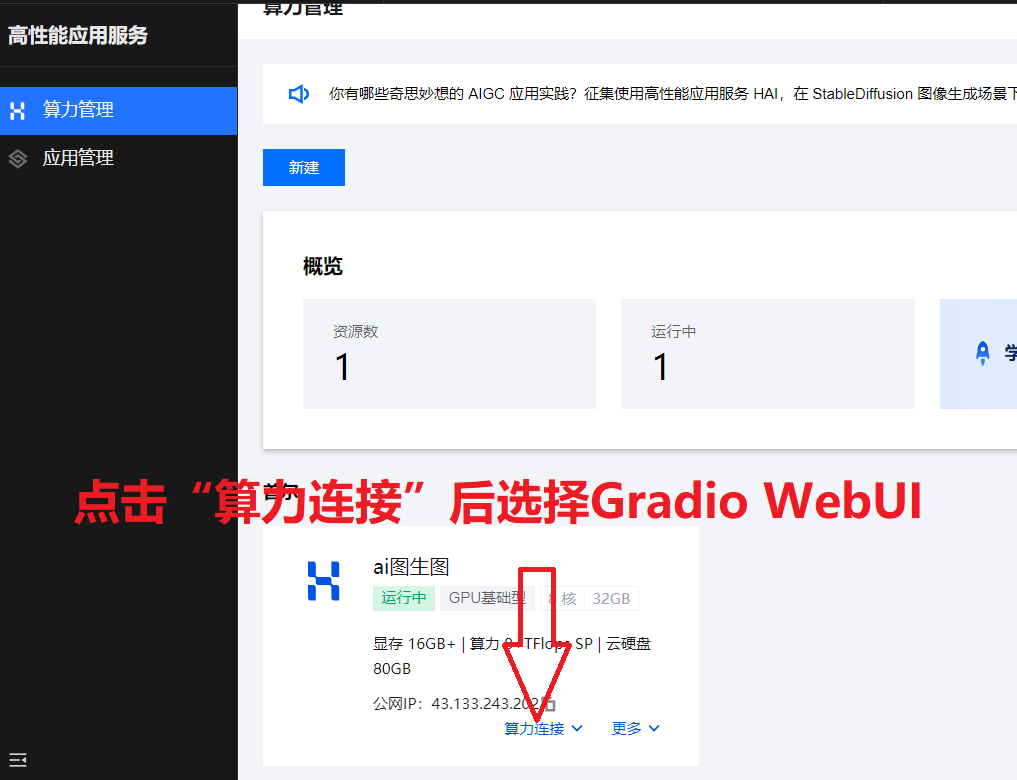
4.进入这个页面就算完成了你AI生图中的第一小步!
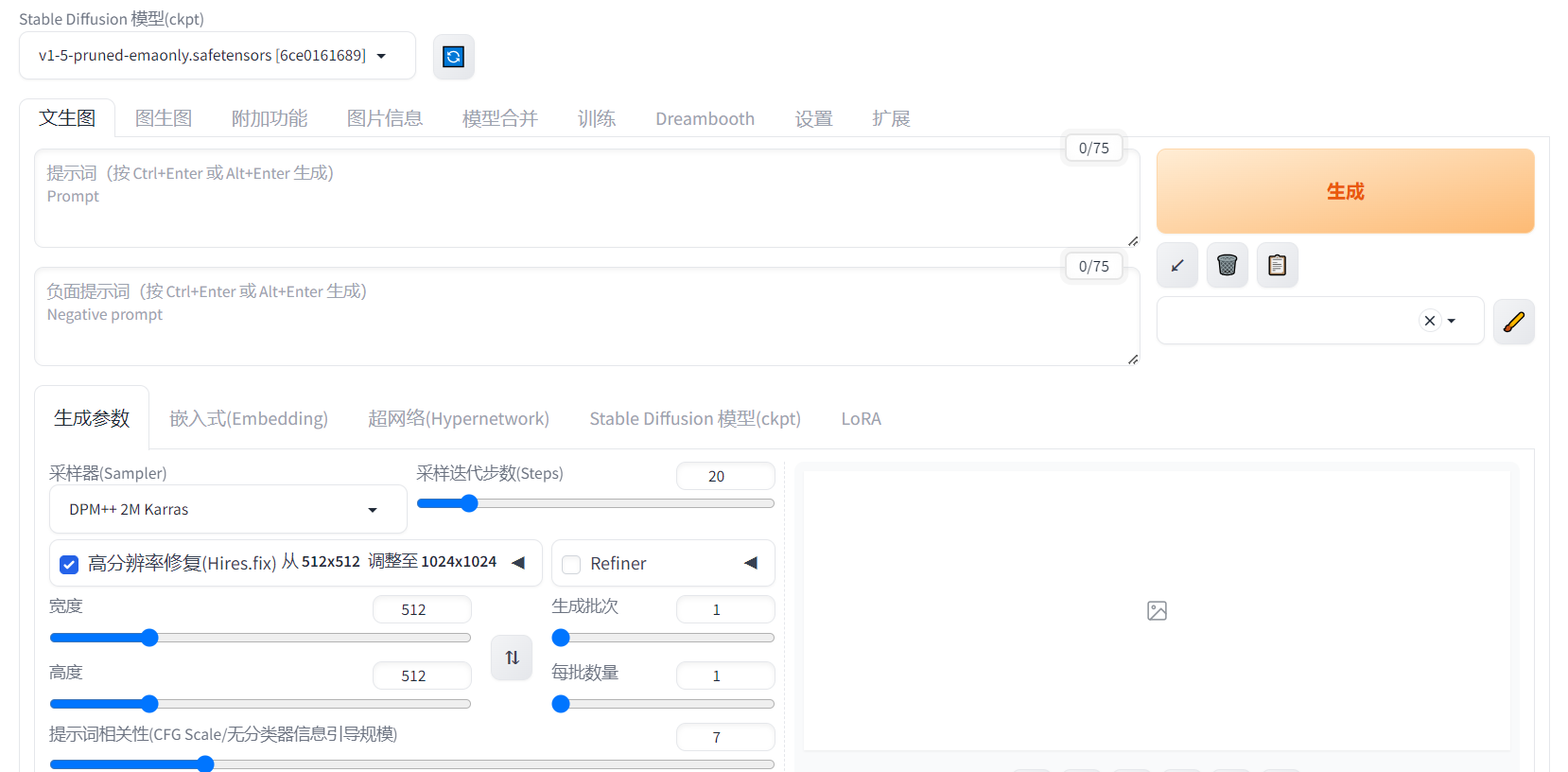
4.StableDiffusion的操作流程-见习功法第一篇:提示词
我们点开文生图可以看见下面很多信息:感觉一头雾水!下面我来简单介绍一下:
首先我们可以在提示词里面输入中文:“一个可爱的狗狗,它在和一只猫咪在玩耍。”大概率生成出来的图片和我们描述的毫不相关,这是为什么呢?因为ai没有理解你的意思!提示词里面的有个组件叫Transformer是对文字的降维,把中文变成StableDiffusion所能理解的语言,来进行AI生图。(遗憾的是目前我们目前提示词以英文为主,生成的图片才准确)
例如:1.提示词输入:a cut dog (见图一 )2.提示词输入:一只可爱小狗 (见图二生成图片不堪入目)

图一

图二
5.StableDiffusion介绍-见习功法第二篇StableDiffusion常用组件
模型:就是可以提供运算辅助的数据库,不同模型,展现AIGC出来的是有不同风格的!
StableDiffusion模型(ckpt):我称之为主模型,主模型占用一般几个G的容量,占用内存大;举个例子就想王者荣耀的英雄

Lora模型:可以让生成的图片中带有特定的风格,一般占用100-200M,占用小;举个例子:就像你王者荣耀的皮肤一样,感觉影响了建模,但是又还是那个英雄。

采样器:不同的采样器采用出来的效果不同;比如说:清理一堆石头的方法,有的人用手捡起来石头,有人用扫把等等
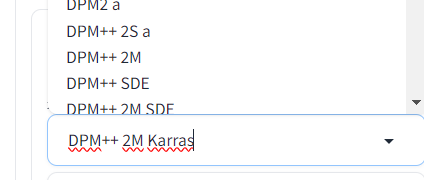
采样迭代步数:数值越高,图片的质量越好;就比如你可以理解为像素点越来越多了,图片分辨率就大了。
6.StableDiffusion实际操作-见习功法:文生图
1.提示词模板:画质词:(masterpiece:1.2), best quality,extremely detailed CG,perfect lighting,8k wallpaper,
真实系:photograph, photorealistic,
插画风:Illustration, painting, paintbrush,
二次元:anime, comic, game CG, 3D:3D,C4D render,unreal engine,octane render,
2.负面词模板:NSFW, (worst quality:2), (low quality:2), (normal quality:2),,normal quality, ((monochrome)), skin spots, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.5), (too many fingers:1.5), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
3.(xxxxx:数字):例如(masterpiece:1.2) 数字1.2我们称呼为“权重”,权重默认值是:1。一般权重设置0.4-0.6(权重不是越高越好)
4.提示词:提示词之间是用英文逗号分隔开,结尾提示词也要逗号,可以换行写需要英文逗号结尾
5.(),[],{}:分别代表权重值不同的倍数,
例如:masterpiece =1
(masterpiece)=1.1 [masterpiece]=0.9 {masterpiece}=1.1
实操:例如1:
提示词:(masterpiece:1.2), best quality, Cyber punk,A 17-year-old boy, wearing a white shirt and black pants, is playing basketball,
负面提示词:NSFW,(他的作用是不要产生不适合公告场合的图片) 负面提示词可以直接照抄下面的!
NSFW, (worst quality:2), (low quality:2), (normal quality:2),,normal quality, ((monochrome)), skin spots, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.5), (too many fingers:1.5), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),

7.StableDiffusion实际操作-见习功法:Controlnet控制网络
1.Controlnet(控制网络)我们是已经预装好了的,打开JupyterLab执行:
需要单格执行下面代码(文档中有一模一样的),点击Run Run selected cell 执行完要重启web版
## 下载ControlNet及预处理器(适配SD1.5及SDXL,需 23GB 存储空间)
!wget -N http://mirrors.tencentyun.com/install/HAI/install_hai_tools.sh -P /tmp && bash /tmp/install_hai_tools.sh && python3 /root/hai_application/qcloud_hai/hai_tools/download_models_main.py --model-class controlnet Annotators2.controlent可以做什么?怎么做?
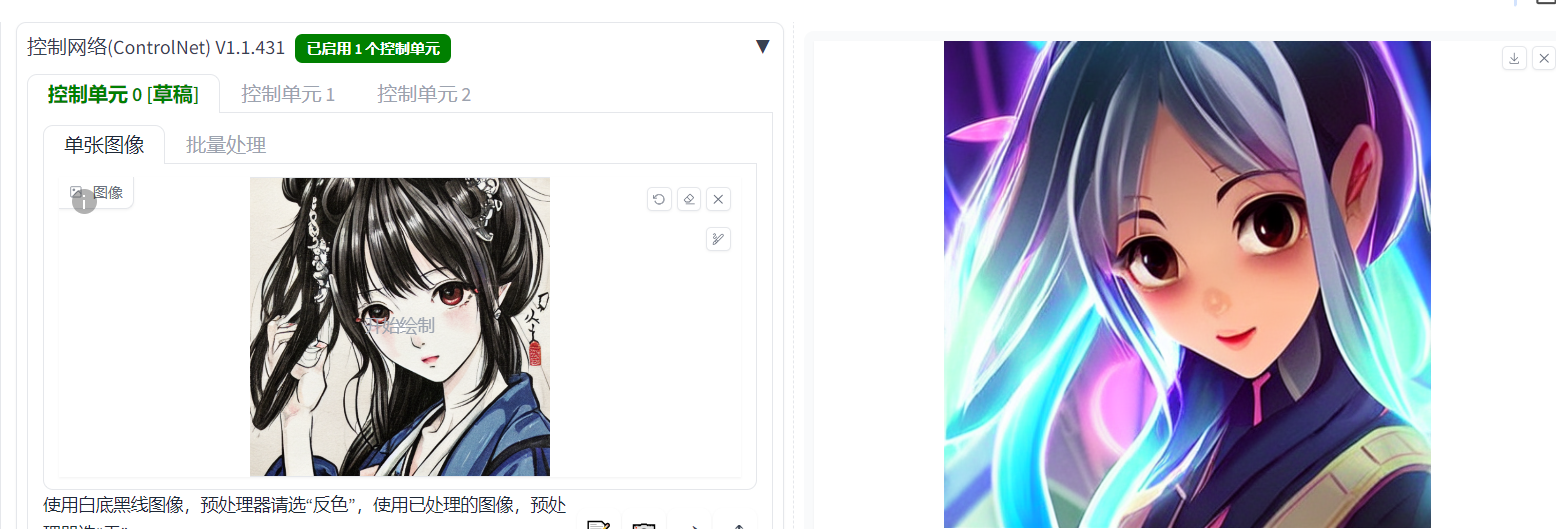
例1:我们想要一个线稿图,control里面有很多功能,例如:法线贴图,线稿一键上色,一键取线稿图,显示动作骨骼等

例2:上传一张照片,“控制模式”选择“以控制网络为主”,直接生图,ai会按照你给图片和选择的需求随机给生成和这张图片相关的AIGC
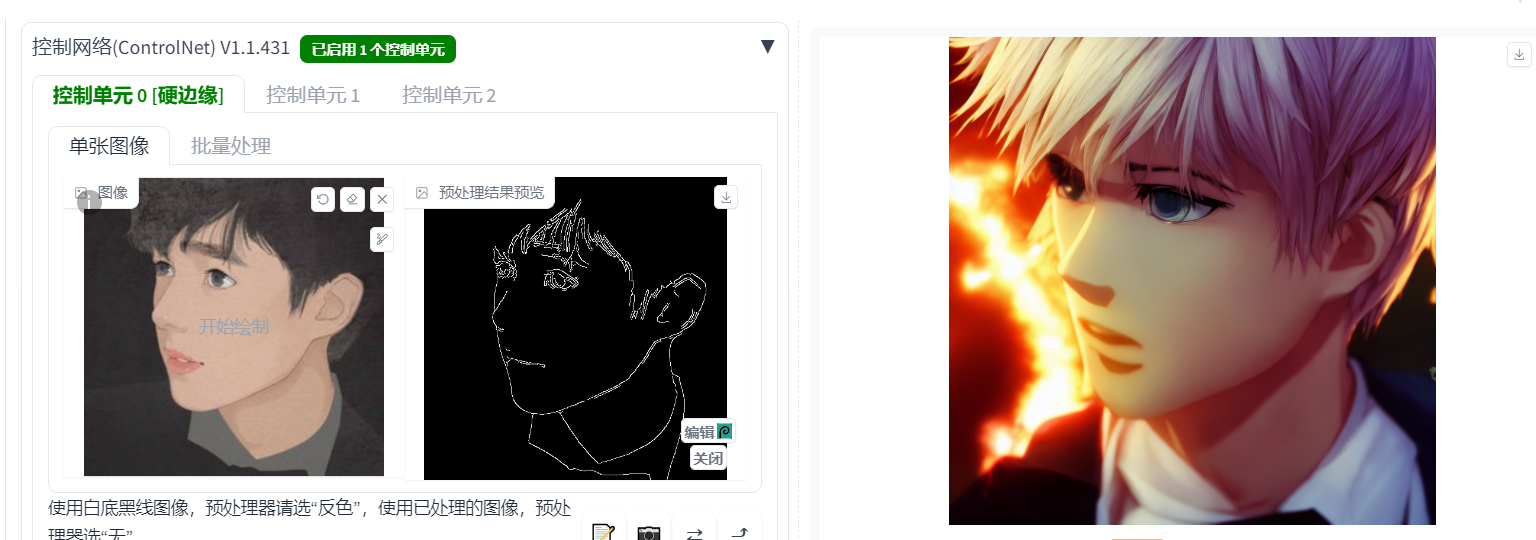
例3:线稿生图:
1.启用,开启预览,预处理器与模型:硬边缘
2.控制强度:1,控制介入时机:0,控制结束时机:1
3.控制模式:以提示词为主
提示词参考:anime, comic, game CG,perfect lighting,wallpaper, A boy with blond hair,
反面提示词:NSFW, (worst quality:2), (low quality:2), (normal quality:2),,normal quality, ((monochrome)), skin spots, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.5), (too many fingers:1.5), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
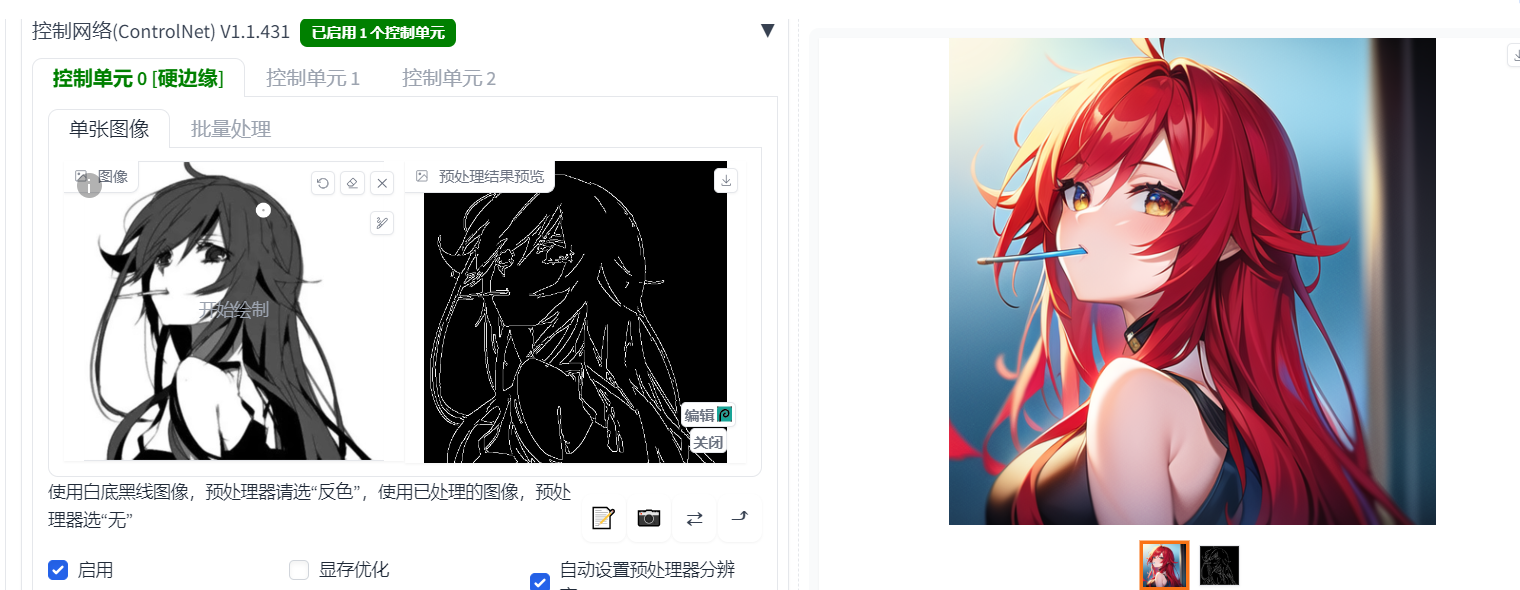
例4:用黑白图片来生成动漫图片:
0.采用的AnythingV5模型;
AnythingV5是已经预装好了的,打开JupyterLab执行:
需要单格执行下面代码(文档中有一模一样的),点击Run Run selected cell 执行完要重启web版
## 下载常用基础模型(SDXL、anthingv5,需 8.5GB 存储空间)
!wget -N http://mirrors.tencentyun.com/install/HAI/install_hai_tools.sh -P /tmp && bash /tmp/install_hai_tools.sh && python3 /root/hai_application/qcloud_hai/hai_tools/download_models_main.py --model-class checkpoint1.加入一张黑白图片,选择 启动 开启预览 自动设置预处理器分辨率;
2.选择Canny 按爆炸按钮 先生成线稿图;
3.输入提示词:masterpiece, best quality, photography, 8K, highres,A girl with red hair eating a lollipop,
负面提示词:nsfw, ugly, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, (monochrome), (grayscale),
4.因为ControlNet的约束,和提示词的结合,我们会在线稿图的基础上,进行AI生图
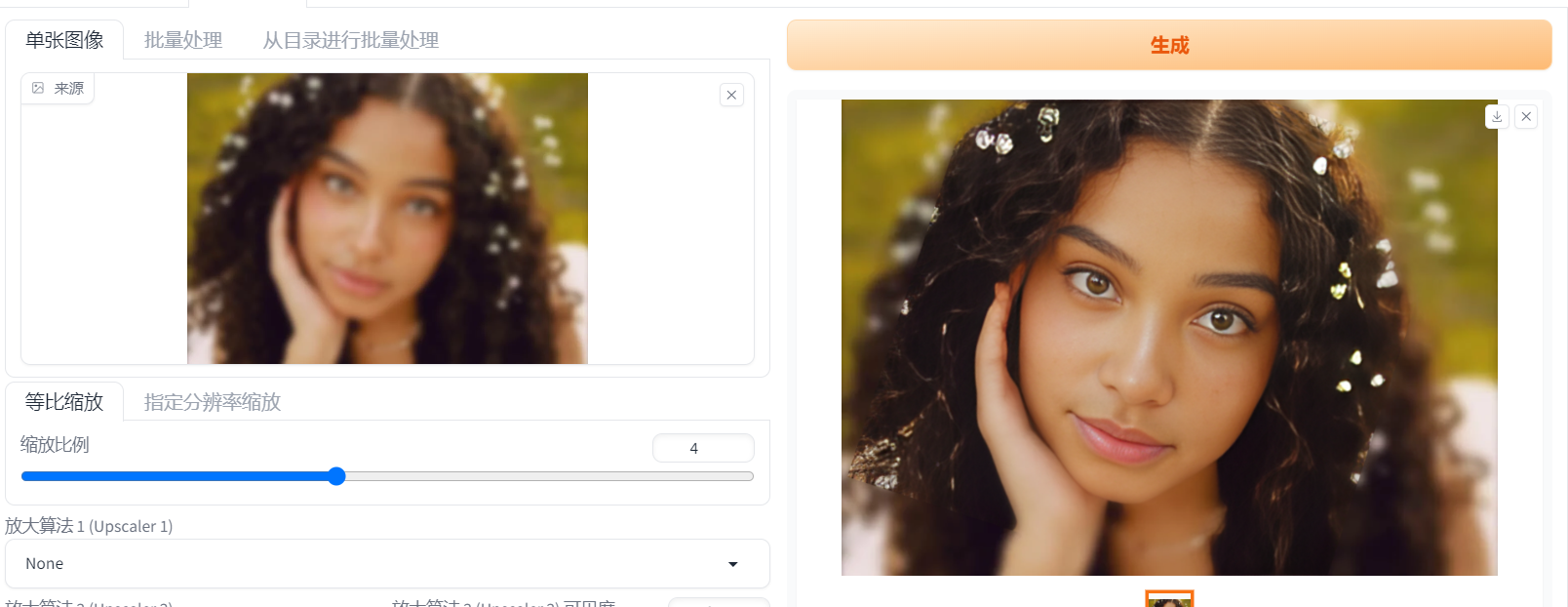
8.StableDiffusion实际操作-见习功法:图片高清化(附加功能)
图片高清化:这边使用的是:4x-UltraSharp修复工具(点击提取码1234):下载后打开JupyterLab,把文件放到/stable-diffusion-webui/models-ESRGAN里面就可以了。
设置:打开GFPGAN:1;
或者打开codeFormer的值全为1;就可以了
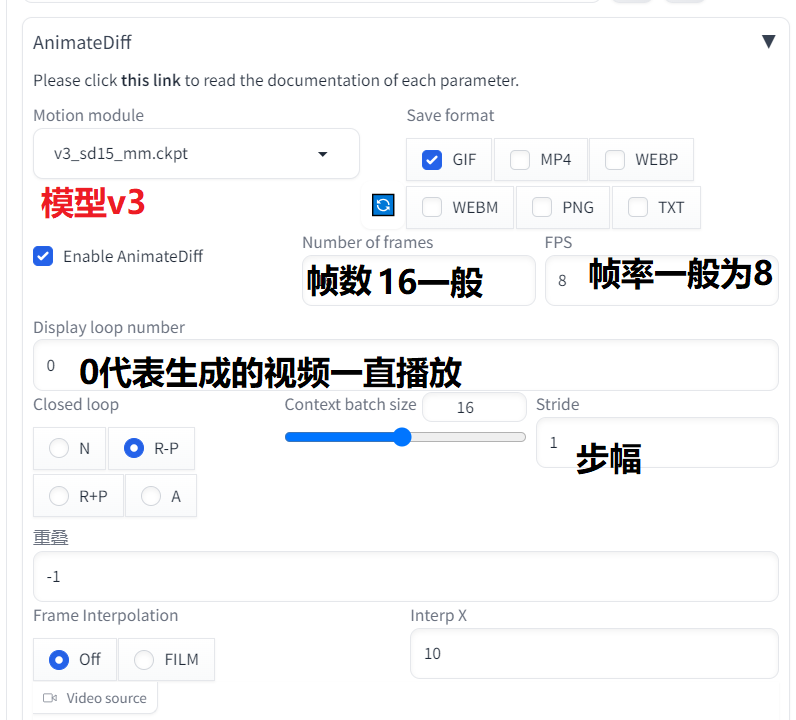
9.StableDiffusion实际操作-见习功法:AI动画制作(AnimateDiff)
1.AnimateDiff我们是已经预装好了的,打开JupyterLab执行:
需要单格执行下面代码(文档中有一模一样的),点击Run Run selected cell执行完要重启web版
## 下载animatediff模型(需 1.7GB 存储空间)
!wget -N http://mirrors.tencentyun.com/install/HAI/install_hai_tools.sh -P /tmp && bash /tmp/install_hai_tools.sh && python3 /root/hai_application/qcloud_hai/hai_tools/download_models_main.py --model-class animatediff_model2.模型:majicMIX realistic
提示词:best quality, high resolution, masterpiece, professional photography, sharp focus, resolution, intricate detail, sophisticated detail, depth of field, extremely detailed CG unity wallpaper,a girl,red_hair, face, looking_at_viewer, white shirt,sitting in desk , background, indoor,film look
负面提示词:NSFW, (worst quality:2), (low quality:2), (normal quality:2),,normal quality, ((monochrome)), skin spots, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.5), (too many fingers:1.5), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
3.AnimateDiff设置如下:

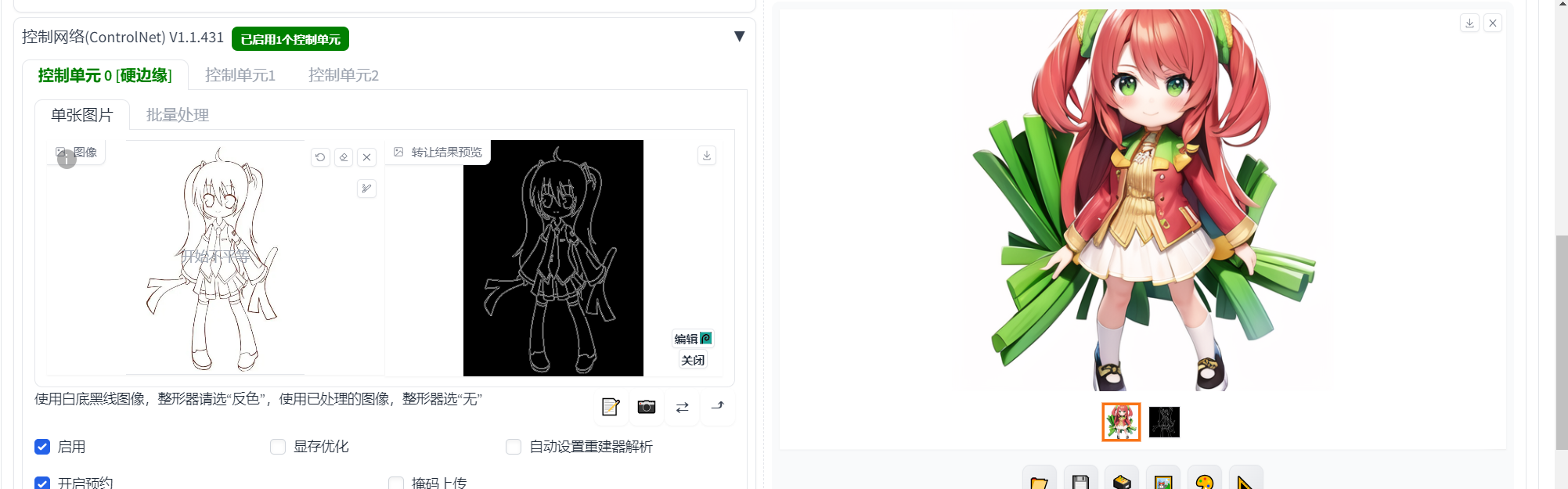
10.StableDiffusion实际操作-见习功法:2D图片转3D模型(Tripo3D)
1.使用采用的AnythingV5模型;使用采用blindbox_v1的lora(点击下载,这个Lora是为了生成盲盒画风)
配置:选择启用-开启预约-使用canny模式,线稿来约束生成模型和线稿图的一致性。
微调控制强度0.4-1之间。
提示词:Best quality, high resolution, masterpiece, simple drawing of a cute red-haired girl in a white patterned shirt, holding green onions, full body, chibi, white background, <lora:blindbox_v1_mix:1>
反面提示词:NSFW, (worst quality:2), (low quality:2), (normal quality:2),,normal quality, ((monochrome)), skin spots, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.5), (too many fingers:1.5), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
2.Tripo3D(点击进入网址)免费生成模型,并且生成模型后可以精修再修改模型(可以选择各种文件到处格式,obj,fbx)

11.StableDiffusion实际操作-见习功法:AI跳舞动画(Temporal Kit)
这段是由我本地部署来操作的 总共需要下载3个插件( Temporal-Kit ,EbSynth,FFmpeg)
0.拓展-从网站安装-复制GitHub链接 检查并重启web端
1.Temporal Kit:https://github.com/CiaraStrawberry/TemporalKit.git
打开web端,选择Temporal-Kit-预处理-导入视频
每边张数:1;高分辨率:1024;每5帧;帧率:30开启EBSynth 模式
批量处理勾选-边界关键帧数为0 EbSynth设置:分割视频
目标文件地址为:在StableDiffusion里面的文件夹选择output文件夹放入视频
例如:D:\SD\Stable Diffusion\sd-webui-aki\sd-webui-aki-v4.7\output(我的地址)
重点1:(一定要使用StableDiffusion里面的文件夹为地址,不然后面操作会报错,地址索引失败)
如果:不能使用Temporal Kit 需配置电脑环境变量 下载FFmpeg(点击下载)

环境变量:新建-添加解压ffmpeg-复制到bin目录的路径地址

重点2:生成完关键帧照片,打开关键帧导入一张关键帧(D:\SD\AI vido\input)的照片导入文生图
文生图:步数25;宽度576和高度1024(看你生成图片的属性);
两个controlnet控制生成图片
第一个:canny:启用,低显存,完美像素模式,
第二个:平铺(tile_resample):启用,低显存,完美像素模式, 生成一张来做样板,如果可以就批量生成
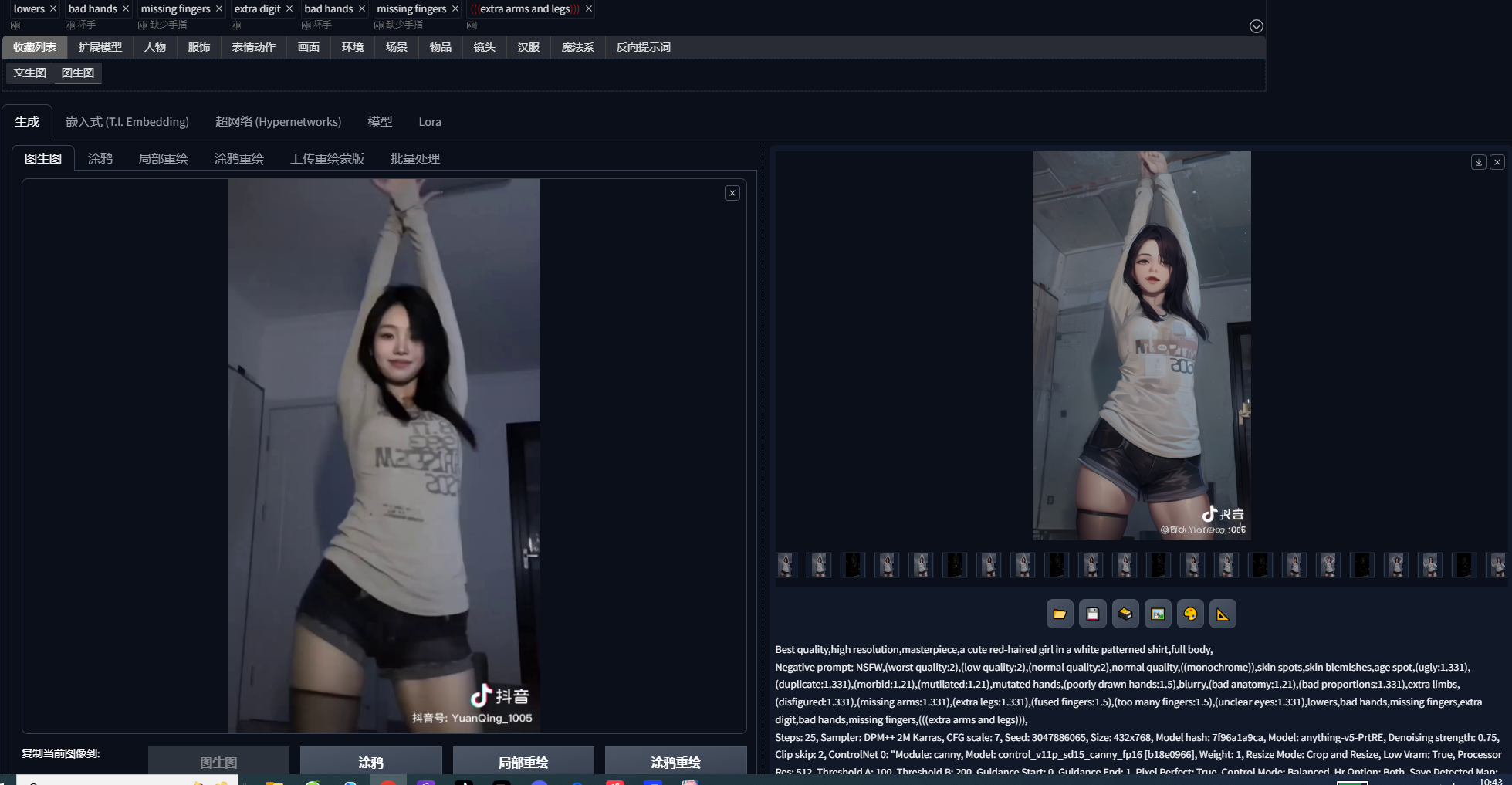
提示词:Best quality, high resolution, masterpiece, a cute red-haired girl in a white patterned shirt, full body,
负面提示词:NSFW, (worst quality:2), (low quality:2), (normal quality:2),,normal quality, ((monochrome)), skin spots, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.5), (too many fingers:1.5), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
重点3:生成图片符合预期 选择图生图的种子复制后 再图生图批量处理
例种子:3047886065(复制)
批量处理:
输入目录:D:\SD\Stable Diffusion\sd-webui-aki\sd-webui-aki-v4.7\output\input
输出目录:D:\SD\Stable Diffusion\sd-webui-aki\sd-webui-aki-v4.7\output\output
宽度:432(具体看你生成关键帧的图片大小)
高度:768(具体看你生成关键帧的图片大小)
ControlNet:开启两个ControlNet 和上面一样
模式:一个canny(硬边缘)和一个tile(分块)
都是启用-低现存-完美像素
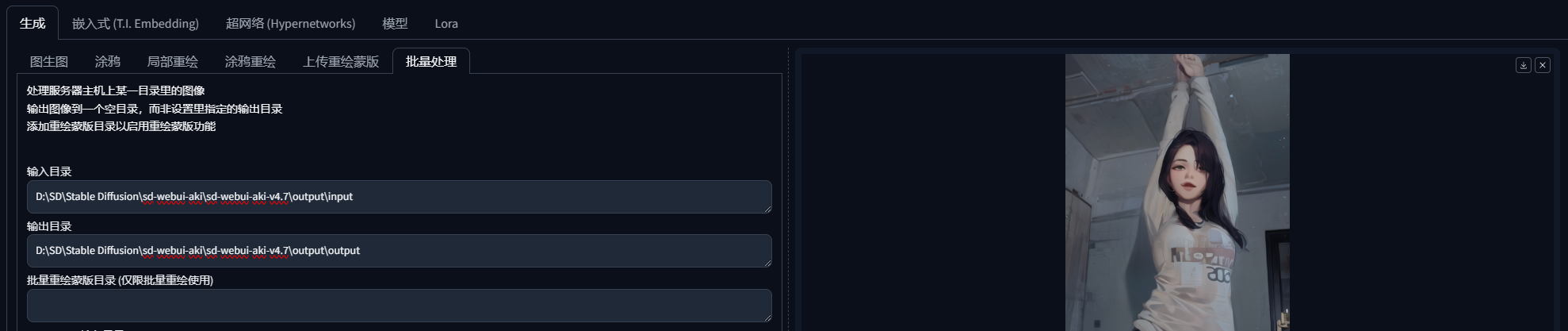
重点4:输入StableDiffusion自带的output的目录
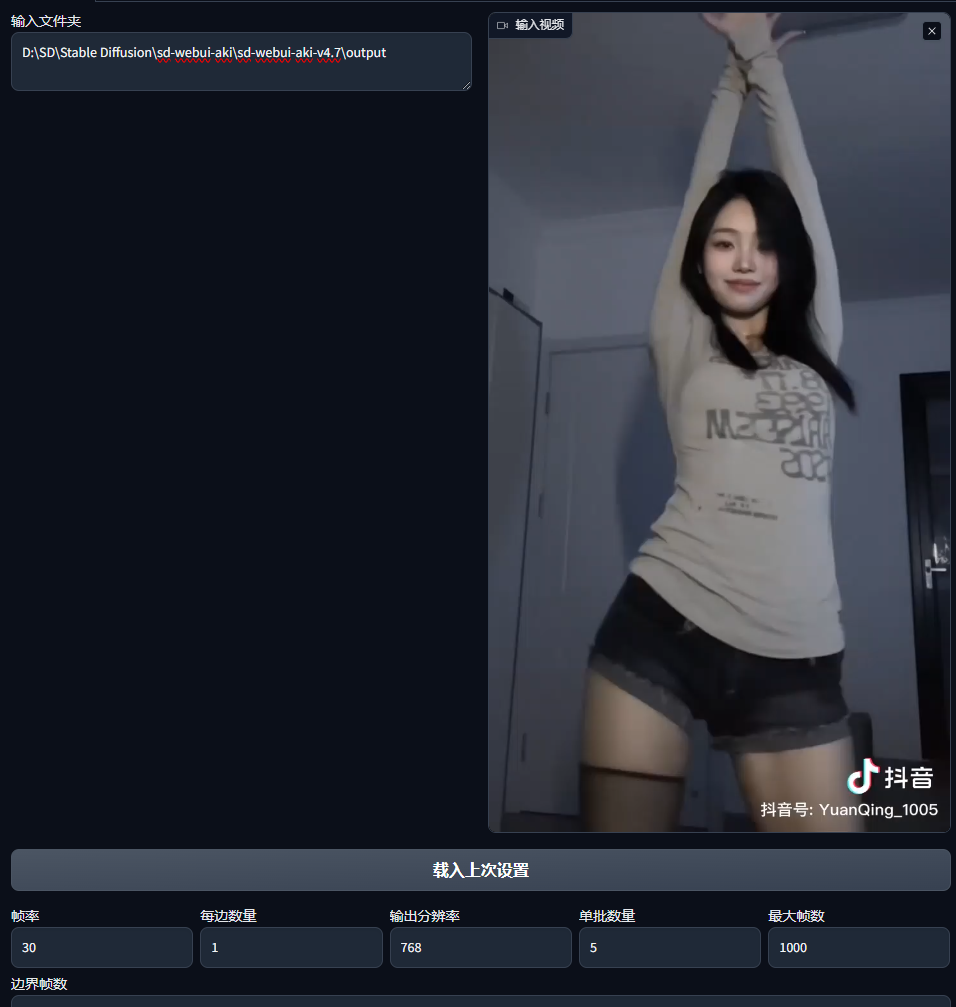
帧率:30 边数量:1 输出分辨率:768 单批数量:5 最大帧数:3秒150,自己算一下, 边界帧数:1
重点5:下载EbSynth
Keyframes:选择output里面名字为“0”的文件夹的keys文件第一张照片
video:选择output里面名字为“0”的文件夹的frames文件第一张照片
点击EbSynth下方 run all
然后还有数字“1”的文件夹也是重复上面操作
直到所有数字文件夹都run all完
重点6:输出AI绘画视频
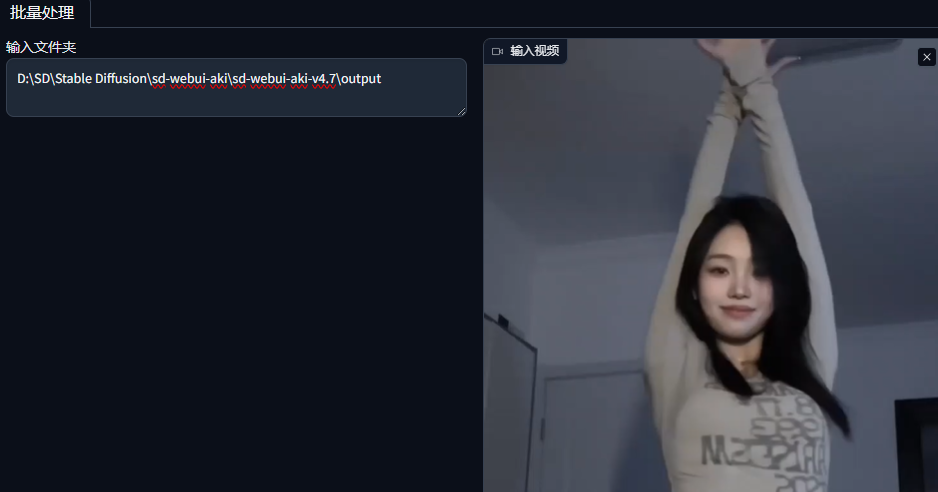
点击 重组Ebsynth-下载视频
成品: 面部和动作还是有点糊,我这边电脑配置不高,大家可以加上roop插件配合会+高分辨率会效果更好
(在腾讯高性能应用服务HAI里面就不要担心电脑配置问题,我核显电脑的9小时生成3s视频,3060显卡要30min,HAI服务器就更快了,还是推荐HAI上生成,省时间省事情。)

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号