Day6-学习R包
原创
Day6-学习R包
原创
用户11039783
发布于 2024-03-28 09:52:33
发布于 2024-03-28 09:52:33
操作练习
设置镜像
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
options(BioC_mirror="https://mirrors.ustc.edu.cn/bioc/")
install.packages("dplyr")
library(dplyr)
#使用内置数据集iris的简化版作为示例数据
test <- iris[c(1:2,51:52,101:102),]
test
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
51 7.0 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
101 6.3 3.3 6.0 2.5 virginica
102 5.8 2.7 5.1 1.9 virginica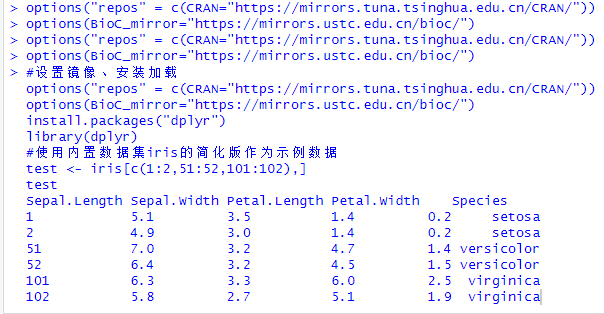
练习dplyr基础函数
# 1. mutate(), 新增列
mutate(test, new = Sepal.Length * Sepal.Width)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species new
1 5.1 3.5 1.4 0.2 setosa 17.85
2 4.9 3.0 1.4 0.2 setosa 14.70
51 7.0 3.2 4.7 1.4 versicolor 22.40
52 6.4 3.2 4.5 1.5 versicolor 20.48
101 6.3 3.3 6.0 2.5 virginica 20.79
102 5.8 2.7 5.1 1.9 virginica 15.66
# 2. select(), 按列筛选
select(test,c(1,5))
Sepal.Length Species
1 5.1 setosa
2 4.9 setosa
51 7.0 versicolor
52 6.4 versicolor
101 6.3 virginica
102 5.8 virginica
select(test,1)
Sepal.Length
1 5.1
2 4.9
51 7.0
52 6.4
101 6.3
102 5.8
select(test,Sepal.Length)
Sepal.Length
1 5.1
2 4.9
51 7.0
52 6.4
101 6.3
102 5.8
select(test, vars)
Note: Using an external vector in selections is ambiguous.
i Use `all_of(vars)` instead of `vars` to silence this message.
i See <https://tidyselect.r-lib.org/reference/faq-external-vector.html>.
This message is displayed once per session.
Petal.Length Petal.Width
1 1.4 0.2
2 1.4 0.2
51 4.7 1.4
52 4.5 1.5
101 6.0 2.5
102 5.1 1.9
select(test, one_of(vars))
Petal.Length Petal.Width
1 1.4 0.2
2 1.4 0.2
51 4.7 1.4
52 4.5 1.5
101 6.0 2.5
102 5.1 1.9# 3. filter(), 按行筛选
filter(test, Species == "setosa")
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
filter(test,Species == "setosa" & Sepal.Length > 5)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
filter(test,Species %in% c("setosa","versicolor"))
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 7.0 3.2 4.7 1.4 versicolor
4 6.4 3.2 4.5 1.5 versicolor
#4. arrange(), 按某1列或某几列对整个表格进行排序
arrange(test, Sepal.Length)#从小到大排序
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 4.9 3.0 1.4 0.2 setosa
2 5.1 3.5 1.4 0.2 setosa
3 5.8 2.7 5.1 1.9 virginica
4 6.3 3.3 6.0 2.5 virginica
5 6.4 3.2 4.5 1.5 versicolor
6 7.0 3.2 4.7 1.4 versicolor
arrange(test, desc(Sepal.Length))#用desc从大到小
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.0 3.2 4.7 1.4 versicolor
2 6.4 3.2 4.5 1.5 versicolor
3 6.3 3.3 6.0 2.5 virginica
4 5.8 2.7 5.1 1.9 virginica
5 5.1 3.5 1.4 0.2 setosa
6 4.9 3.0 1.4 0.2 setosa
# 5.summarise(),汇总
summarise(test, mean(Sepal.Length),sd(Sepal.Length)) #计算Sepal.Length的平均值和标准差
mean(Sepal.Length) sd(Sepal.Length)
1 5.916667 0.8084965
group_by(test,Species)
# A tibble: 6 x 5
# Groups: Species [3]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
<dbl> <dbl> <dbl> <dbl> <fct>
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
3 7 3.2 4.7 1.4 versicolor
4 6.4 3.2 4.5 1.5 versicolor
5 6.3 3.3 6 2.5 virginica
6 5.8 2.7 5.1 1.9 virginica
#先按照Species分组,再计算每组Sepal.Length的平均值和标准差
summarise(group_by(test, Species),mean(Sepal.Length), sd(Sepal.Length))
# A tibble: 3 x 3
Species `mean(Sepal.Length)` `sd(Sepal.Length)`
<fct> <dbl> <dbl>
1 setosa 5 0.141
2 versicolor 6.7 0.424
3 virginica 6.05 0.354dplyr处理数据
> options(stringsAsFactors = F) #在读入数据时,遇到字符串之后,不将其转换为factors,仍然保留为字符串格式
>
> test1 <- data.frame(x = c('b','e','f','x'),
+ z = c("A","B","C",'D'),
+ stringsAsFactors = F)
> test1
x z
1 b A
2 e B
3 f C
4 x D
> test2 <- data.frame(x = c('a','b','c','d','e','f'),
+ y = c(1,2,3,4,5,6),
+ stringsAsFactors = F)
> test2
x y
1 a 1
2 b 2
3 c 3
4 d 4
5 e 5
6 f 6
> inner_join(test1, test2, by = "x")#內连inner_join,取交集
x z y
1 b A 2
2 e B 5
3 f C 6
> left_join(test1, test2, by = 'x')#左连left_join
x z y
1 b A 2
2 e B 5
3 f C 6
4 x D NA
> left_join(test2, test1, by = 'x')
x y z
1 a 1 <NA>
2 b 2 A
3 c 3 <NA>
4 d 4 <NA>
5 e 5 B
6 f 6 C
> full_join( test1, test2, by = 'x')#全连full_join
x z y
1 b A 2
2 e B 5
3 f C 6
4 x D NA
5 a <NA> 1
6 c <NA> 3
7 d <NA> 4
> semi_join(x = test1, y = test2, by = 'x')#半连接:返回能够与y表匹配的x表所有记录semi_join
x z
1 b A
2 e B
3 f C
> anti_join(x = test2, y = test1, by = 'x')#反连接:返回无法与y表匹配的x表的所记录anti_join
x y
1 a 1
2 c 3
3 d 4
> test1 <- data.frame(x = c(1,2,3,4), y = c(10,20,30,40))
> test1
x y
1 1 10
2 2 20
3 3 30
4 4 40
> test2 <- data.frame(x = c(5,6), y = c(50,60))
> test2
x y
1 5 50
2 6 60
> test3 <- data.frame(z = c(100,200,300,400))
> test3
z
1 100
2 200
3 300
4 400
> bind_rows(test1, test2)#需要两个表格列数相同
x y
1 1 10
2 2 20
3 3 30
4 4 40
5 5 50
6 6 60
> bind_cols(test1, test3)#需要两个表格行数相同
x y z
1 1 10 100
2 2 20 200
3 3 30 300
4 4 40 400原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号