【爬虫软件】用python开发的快手评论批量采集工具:含二级评论
原创
【爬虫软件】用python开发的快手评论批量采集工具:含二级评论
原创
马哥python说
修改于 2025-05-16 13:39:40
修改于 2025-05-16 13:39:40
一、背景说明
1.1 效果演示
我是马哥python说,一名拥有10年编程经验的开发者。
我开发了一款基于Python的快手评论采集软件,该软件能够自动抓取快手视频的评论数据,包括二级评论和展开评论。为便于不懂编程的用户使用,我提供了图形用户界面(GUI),用户无需安装Python环境或编写代码,只需双击即可运行。
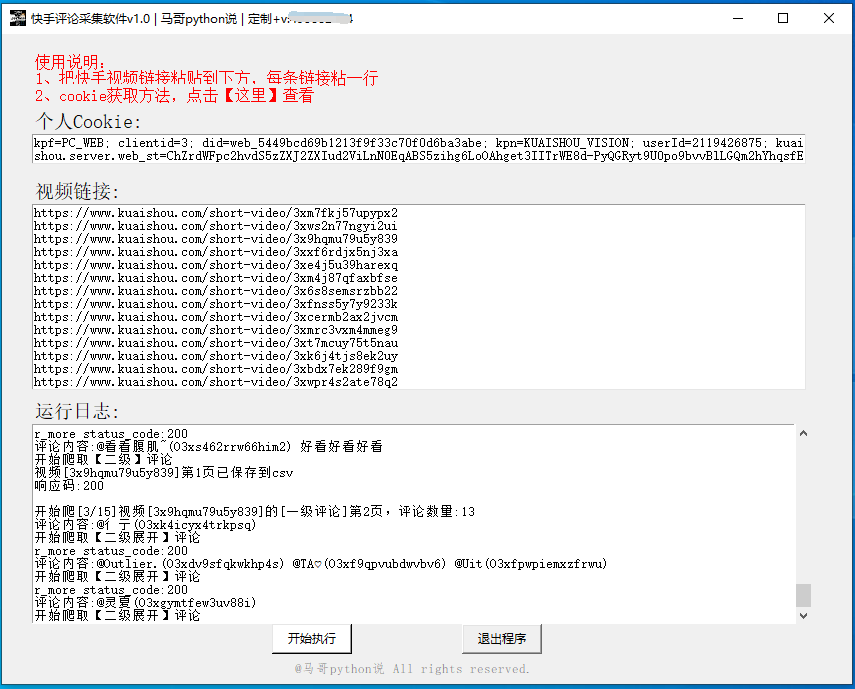
1.2 演示视频
观看软件运行演示视频,了解软件的实际操作过程和效果。
演示视频:
1.3 软件说明
系统兼容性:Windows系统用户可直接使用,无需额外安装Python环境。
操作简便:用户需填写cookie和爬取目标视频链接,支持同时爬取多个视频评论。
数据丰富:可爬取包括目标链接、页码、评论者昵称、评论者ID、评论者主页链接、评论时间、评论点赞数、评论级别和评论内容在内的9个关键字段。
二级评论支持:软件支持抓取二级评论及二级展开评论,确保数据的完整性。
结果导出:爬取结果自动导出为CSV文件,方便用户后续分析和处理。

二、代码讲解
2.1 爬虫采集模块
- 定义请求地址和请求头
请求地址(URL)是快手的GraphQL API。
请求头(headers)用于伪造浏览器访问,确保请求被正常处理。
代码如下:
# 请求头
h1 = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Type': 'application/json',
'Cookie': '换成自己的cookie值',
'Host': 'www.kuaishou.com',
'Origin': 'https://www.kuaishou.com',
'Referer': 'https://www.kuaishou.com',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
}- 设置请求参数
其中一个关键参数是cookie,需要从软件界面获取。
其他参数根据具体的爬取需求进行设置。
- 发送请求和接收数据
使用Python的requests库发送POST请求。
接收返回的JSON数据,并进行后续处理。
代码如下:
# 发送请求
r = requests.post(url, json=params, headers=h1)
# 接收json数据
json_data = r.json()- 解析字段数据
遍历返回的JSON数据,提取所需的字段信息。
将提取的字段数据保存到对应的列表中。
代码如下:
# 循环解析
for data in json_data['data']['visionCommentList']['rootComments']:
# 评论内容
content = data['content']
self.tk_show('评论内容:' + content)
content_list.append(content)- 保存数据到CSV文件
使用Pandas库将数据整理为DataFrame格式。
判断文件是否存在,设置是否添加表头。
将DataFrame数据保存到CSV文件。
如下:
# 保存数据到DF
df = pd.DataFrame(
{
'目标链接': 'https://www.kuaishou.com/short-video/' + video_id,
'页码': page,
'评论者昵称': author_name_list,
'评论者id': author_id_list,
'评论者主页链接': author_link_list,
'评论时间': create_time_list,
'评论点赞数': like_count_list,
'评论级别': comment_level_list,
'评论内容': content_list,
}
)
# 保存到csv
if os.path.exists(self.result_file): # 如果文件存在,不再设置表头
header = False
else: # 否则,设置csv文件表头
header = True
df.to_csv(self.result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
self.tk_show('视频[{}]第{}页已保存到csv'.format(video_id, page))2.2 软件界面模块
软件界面采用Python的Tkinter库进行开发,确保界面友好且易于操作。
主窗口:创建主窗口并设置窗口标题和大小。
输入框:包括视频链接输入框和cookie输入框,用户需填写相关信息。
按钮:设置开始采集按钮,用户点击后触发爬虫采集模块的运行。
日志显示:实时显示采集过程中的日志信息,方便用户了解采集进度和可能的问题。
结果导出:自动将采集结果保存到CSV文件,并在界面上显示保存路径和文件名。
2.3 其他关键实现逻辑
游标控制翻页:根据返回的数据判断是否需要翻页,并更新请求参数进行下一页的采集。
循环结束条件:根据设定的条件(如最大页数、达到某个时间等)判断采集是否结束。 时间戳转换:将API返回的时间戳转换为易于理解的日期时间格式。
二级评论及二级展开评论采集:根据API返回的数据结构,递归地采集二级评论及二级展开评论。
END、软件声明
“爬快手评论软件”首发于众公号 “老男孩的平凡之路”,仅限于学术交流技术探讨,请勿用于商业用途。
我是@马哥python说,一名10年程序猿,持续分享python干货!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号