数据库设计革命:逻辑模型的演变与面向对象的突破


数据模型

数据模型三种类型
概念模型又称信息模型,是从用户观方面来对数据和信息进行建模的结果,是对现实世界的事物及其联系的第一级抽象,它不依赖于具体的计算机系统,不是 DBMS 支持的模型,主要用于描述用户所关心的信息结构,属于信息世界中的模型,用于数据库的设计。
逻辑模型是对客观事物及其联系的数据描述,包括网状模型、层次模型、关系模型和面向对象模型等,它是从计算机系统观方面来进行建模,主要用于 DBMS 的实现,属于计算机世界的模型。
物理模型是对数据最底层的抽象,用于描述数据在计算机系统内部的表示方式和存取方法,其实现由 DBMS 完成。
数据模型的两大主要功能是用于描述数据及其关联。它包含三个基本要素,即数据结构、数据操作和数据的约束条件。
数据模型的基本要素
1.数据结构
定义:用于描述数据的静态特性,它是所研究对象类型的集合。
分类:
数据描述对象
定义:用于描述数据的性质、内容和类型等相关的对象指出对象所包含的项,并对项进行命名,指出项的数据类型和取值范围等。
数据关系描述对象
定义:是用于描述数据间关系信息的对象指明各种不同对象类型之间的关系及关系的性质,并对这些关系进行命名。
2.数据操作
定义:用于对数据动态特性的描述,它是对数据库中各种对象类型的实例允许执行的所有操作及相关操作规则的集合。
分类:
查询
更新
更新操作又包括插入、删除和修改。在数据模型中,要明确定义操作的各项属性,如操作符、操作规则以及实现操作的语言等。
3.数据的完整性约束条件
数据的约束条件是一组完整性规则的集合。完整性规则是指既定的数据模型中数据及其关系所具有的制约性规则和依存性规则。这些规则是通过限定符合数据模型的数据库状态及其变化的方法来保证数据的正确性、有效性和相容性。
三个要素的作用
- 数据结构是基础,它确定着数据模型的性质。
- 数据操作是关键,它确定着数据模型的动态特性。
- 约束条件主要起辅助作用。
四种主要的逻辑模型

1.层次模型
它的数据结构是根树
特点:
- 有且仅有一个节点没有父节点,这个节点就是根树的根节点。
- 除了根节点外,其他节点有且仅有一个父节点,但可能由0个或者多个子节点。
在层次模型中,具有相同父节点的子节点称为兄弟节点,没有子节点的节点称为叶节点。
在根树的层次结构中,每个节点代表一个实体型。但由于层次模型中的实体型是用记录型来表示,所以根树中的每个节点实际上是代表着一个记录型。由于每个记录型节点有且仅有一个父节点(根节点除外),所以只要每个节点指出它的父节点,就可以表示出层次模型的数据结构。如果要访问某一个记录型节点,则可以运用相关的根树遍历方法从根节点开始查找该节点,然后对其访问。
【例子】
一个学校包含多个学院,一个学院又包含多个系和研究所等。这样,学校、学院、系和研究所等实体非常自然地构成了现实世界中的层次关系。层次模型正是为了满足描述这种层次关系的需要而产生的。所以,它的表达方式自然、直观,但是其缺点也是明显。
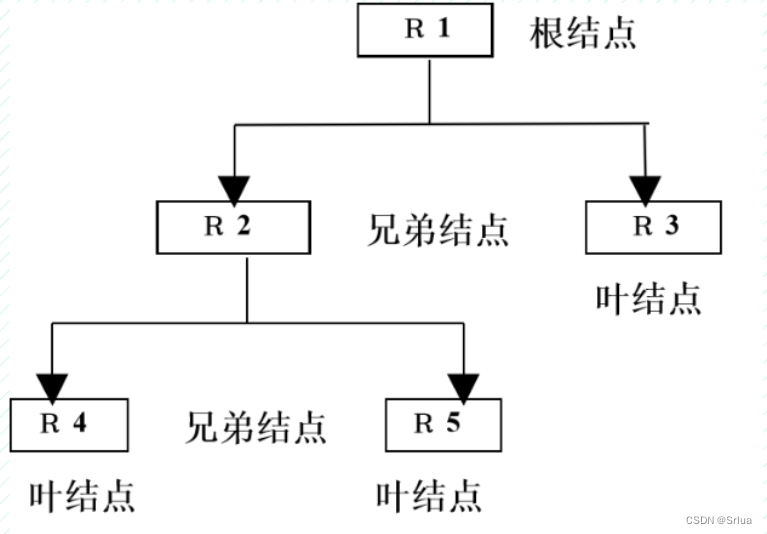
层次模型的特点:
- 结点的双亲是唯一的
- 只能直接处理一对多的实体联系
- 每个记录类型可以定义一个排序字段,也称为码字段
- 任何记录值只有按其路径查看时,才能显出它的全部意义
- 没有一个子女记录值能够脱离双亲记录值而独立存在
层次模型缺点:
处理效率低
这是因为层次模型的数据结构是一种根树结构,对任何节点的访问都必须从根节点开始。这使得对底层节点的访问效率变低,并且难以进行反向查询。
不易进行更新操作
更新操作包括插入、修改和删除等操作。对某一个树节点进行这种更新操作时,都有可能导致整棵根树大面积的变动。对大数据集来说这可是一个沉重的负担。
安全性不好
这主要体现在,当删除一个节点时,则它的子节点和孙子节点都将被删除。所以,必须慎用删除操作。
数据独立性较差
当用层次命令操作数据的时候,它要求用户了解数据的物理结构,并需要显式地说明存取途径。
2.网状模型
网状模型的数据结构是网状结构。网状模型反映着现实世界中实体间更为复杂的联系。由以下特点可以看出节点间没有明确的从属关系,一个节点可以与其它多个节点有联系。
特点:
允许存在一个以上的节点没有父节点。
点可以有多余一个的父节点。
缺点:
由于在使用网状模型时,用户必须熟悉数据的逻辑结构所以结构的复杂性增加了用户查询和定位的难度。
不支持对于层次结构的表达等。
与层次模型类似,网状结构中的每个节点代表一个实体型,而这种实体型是用记录型来表示。与层次结构不同的是:在层次结构中有且仅有一个根节点,而在网状结构中则允许同时存在多个“根节点”;在层次结构中每个节点有且仅有一个父节点(根节点除外),而在网状结构中则允许一个节点同时有多个“父节点”。
这种结构上的差异,也导致了节点对应的记录型结构的变化。网状模型中节点间联系的实现必须由节点同时指出其父节点和子节点的方法来完成。而在层次模型中,每个节点只需指定其父节点即可(根节点除外)。也正是由于这种差异的存在,使得网状模型在性质和功能上发生了重要的改变。这主要体现在:网状模型比层次模型具有更大的灵活性和更强的数据建模能力。
【例子】
图中,表示了学生A、B和课程C、D、E之间的一种选修联系的网状结构图
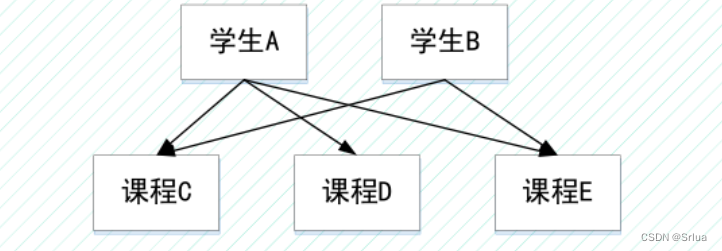
课程选修网状结构
对于小数据量而言,层次模型和网状模型的缺点可能不太明显但是当作用于大数据量时,其缺点就显得非常突出。所以,这两种模型不适合用于当今以处理海量数据为特征的数据处理任务中。目前,它们基本上退出了市场,取而代之的是关系模型。
优点
能够更为直接地描述现实世界,如一个结点可以有多个双亲
具有良好的性能,存取效率较高
缺点
结构比较复杂,而且随着应用环境的扩大,数据库的结构就变得越来越复杂,不利于最终用户掌握
DDL、DML语言复杂,用户不容易使用
3.关系模型
关系模型是当今最为流行的一种数据模型。在关系模型中,实体间的联系是通过二维关系(简称关系)来定义,其数据结构就是二维关系。每个一种二维关系都可以用一张二维表来表示,表达直观、明了。所以,很多时候是把二维表和关系直接等同起来简称为(二维)关系表。关系模型就是若干张关系表的集合。
在用户观点下,关系模型中数据的逻辑结构是一张二维表,它由行和列组成。
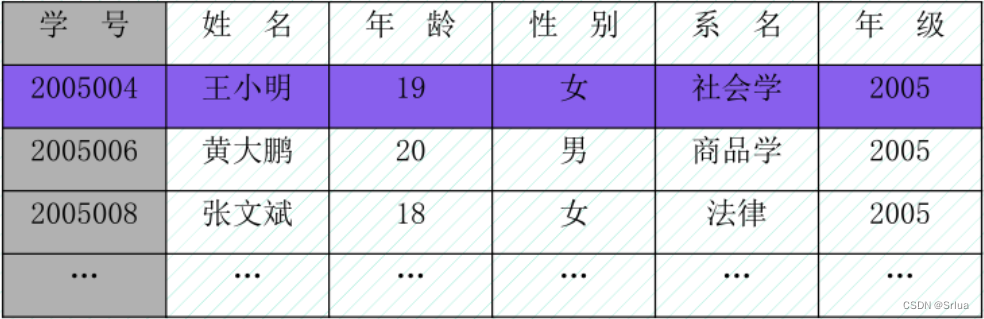
关系模型的术语:
- 关系:一张二维表。
- 记录(或元组):关系表中的一行。
- 字段(或属性):关系表中的一列。
- 域:即字段的值域,也就是字段的取值范围,
- 数据项(或分量):某一个记录中的一个字段值。
- 主关键字段(或主码):简称主键,是关系表中一个或者多个字段的集合,这些记录的值能够唯一标识每一个记录。
- 关系模式:是对关系的一种抽象的描述,其描述格式为“关系名(字段1,字段2,....字段n)”,其中“字段1”带不划线,表示该字段是主关键字段。
术语对比

实体及实体间的联系的表示方法
实体型:直接用关系(表)表示。
属性:用属性名表示。
一对一联系:隐含在实体对应的关系中。
一对多联系:隐含在实体对应的关系中。
多对多联系,直接用关系表示。

关系模型的特点:
- 具有严密的数学基础。关系代数、关系演算等都可以用于对关系模型进行定性或者定量的分析,探讨关系的分开和合并及其有关性质等。
- 概念单一化、表达直观,但又具有较强的数据表达和建模能力。一般来说个关系只表达一个主题,如果有多个主题在一起,则需要将它们分开用多个关系来表示,这就是概念的单一化。
- 关系都已经规范化。即关系要满足一定的规范条件,这使得关系模型表现出特有的一些性质。例如,在一个关系中数据项是最基本的数据单位,它不能再进行分解:同一个字段的字段值具有相同的数据类型;各字段的顺序是任意,记录的顺序也是任意的,等等。
- 在关系模型中,对数据的操作是集合操作,即操作的对象是记录的集合操作所产生的结果也是记录的集合。这种操作不具有明显的方向性,不管如何操作,其难度都一样。而在层次模型和网状模型中,对数据的操作带有明显的方向性,在正反两个方向上操作的难度完全不一样。
关系模型的缺点
对复杂问题的建模能力差。在对复杂问题建模时一般都会呈现出错综复杂的关系,而关系模型仅限于用二维关系来表示这些复杂关系,无法用递归和嵌套的方式来描述(因为它不允许嵌套记录和嵌套关系的存在)。所以在许多时候关系模型显得力不从心。
对象语义的表达能力比较差。现实世界中,对象之间的关系往往不仅限于量的关系,而且还可能体现语义之间的联系,蕴涵着特定的内涵。但关系模型为了规范化这些关系,可能会强行拆开这种语义联系,造成不自然的分解,从而使得在查询等操作时出现语义不合理的结果。
可扩充性差。关系模式只支持记录的集合这一种数据结构,并且数据项不可再分,无法形成嵌套记录和嵌套关系,所以它无法扩充成层次模型或网状模型。且它不支持抽象数据类型,不能对多种类型数据对象进行管理。
4.面向对象模型
面向对象方法(Object-Oriented Paradigm,简称OO)基本出发点就是按照人类认识世界的方法和思维方式来分析和解决问题。面向对象模型作为数据库设计的重要部分,其主要目标是更好地理解和模拟现实世界中的实体和实体间的联系。近年来,面向对象模型已经取得了一系列的进展。
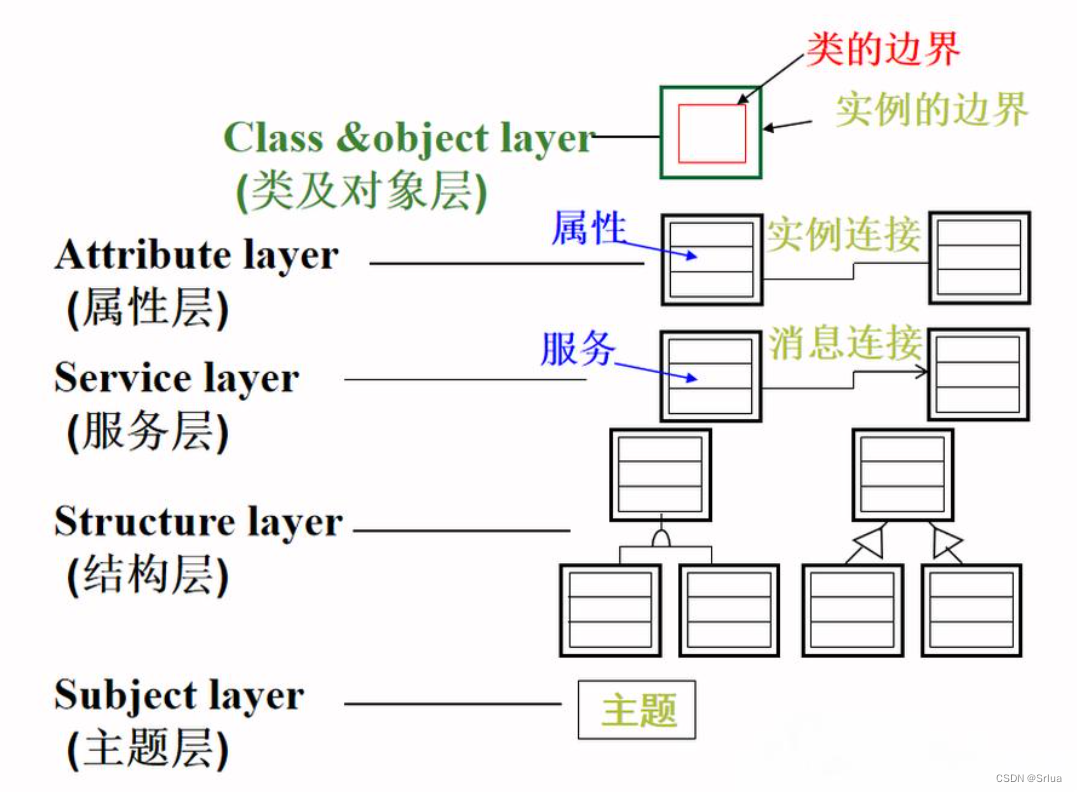
面向对象模型是由面向对象方法进行建模和表示而形成的数据模型。
一方面,面向对象模型不断精细化,更加贴近现实世界的特性。例如,关系模型中的属性可以细化为不同的类型,如字符型、整型、浮点型等,而面向对象模型则可以进一步描述这些属性的取值范围、单位等信息,使得模型更加精确。
另一方面,面向对象模型也在不断融合和拓展。例如,面向对象模型与规则引擎、机器学习等技术相结合,可以更好地处理复杂的数据分析与挖掘任务。同时,面向对象模型也在向分布式、云计算等新兴领域拓展,以适应不断变化的业务需求和技术环境。
面向对象模型的优化也在持续进行。例如,通过引入缓存机制、延迟加载等技术,可以提高系统的响应速度。同时,开发者也在探索如何更好地利用新型数据存储技术,如NoSQL数据库,以进一步提高系统的性能和扩展性。 总的来说,面向对象模型作为数据库设计中的重要一环,其进展体现在精细化、融合拓展和优化等方面,不断为我们理解和应用数据库提供了新的思路和方法。
目前面向对象模型的相关理论和方法还不够成熟,主要是处于理论研究和实验阶段。
希望对你有帮助!加油!
若您认为本文内容有益,请不吝赐予赞同并订阅,以便持续接收有价值的信息。衷心感谢您的关注和支持!
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-03-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号