这个乱码问题,生涯罕见!


前两天我们的 AI 网站用户反馈了一个乱码问题
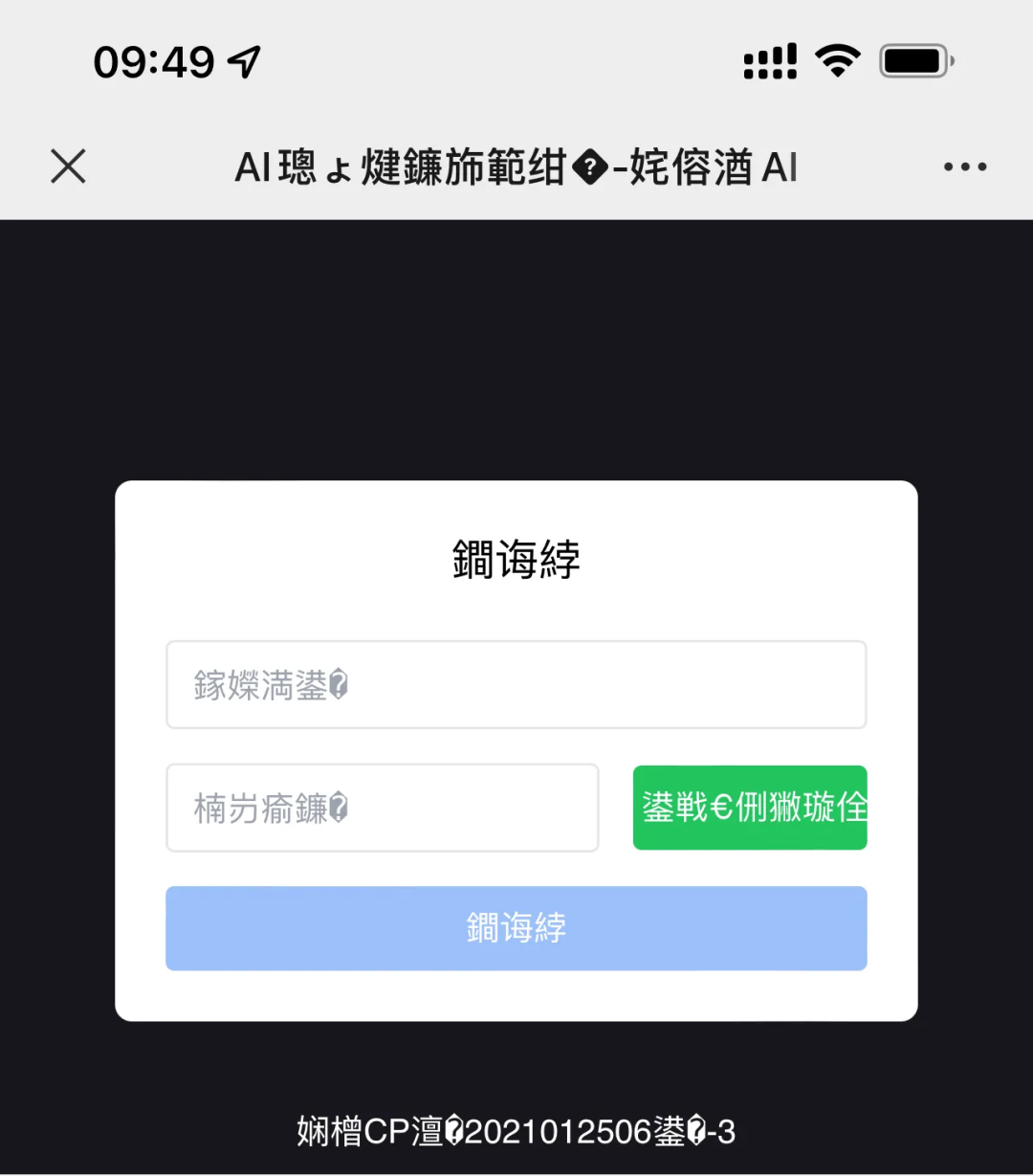
正常的情况应该如下
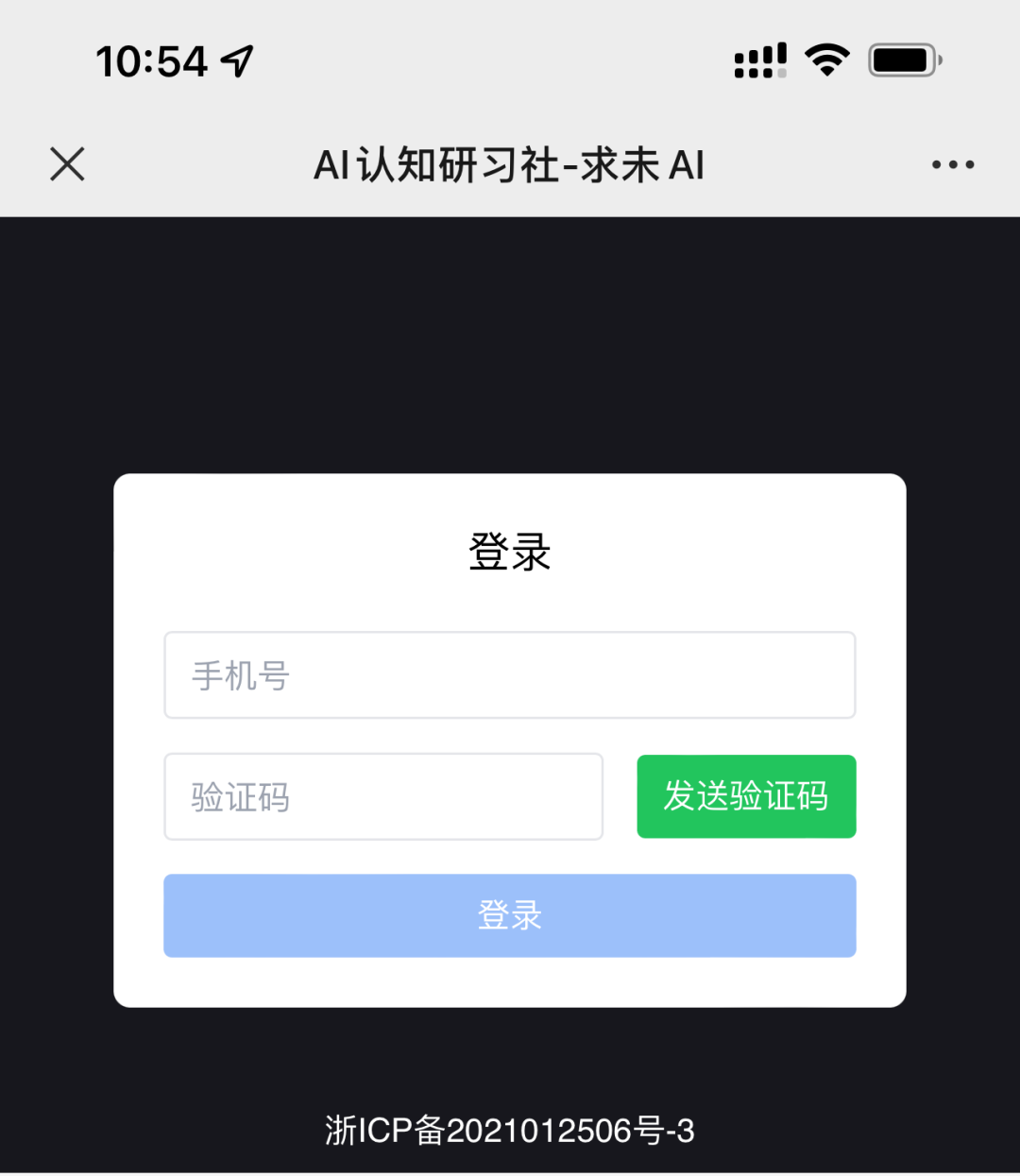
乍一看还是很奇怪的,因为上线之后大多数人是没有问题的,结果突然间出了这么一例。乱码问题,无非就是编解码不一致导致的,那为什么大多数机型的编解码一致,而少部分却不一致呢,接下来就是排查阶段。
我首先看了下我们项目中的编码设置
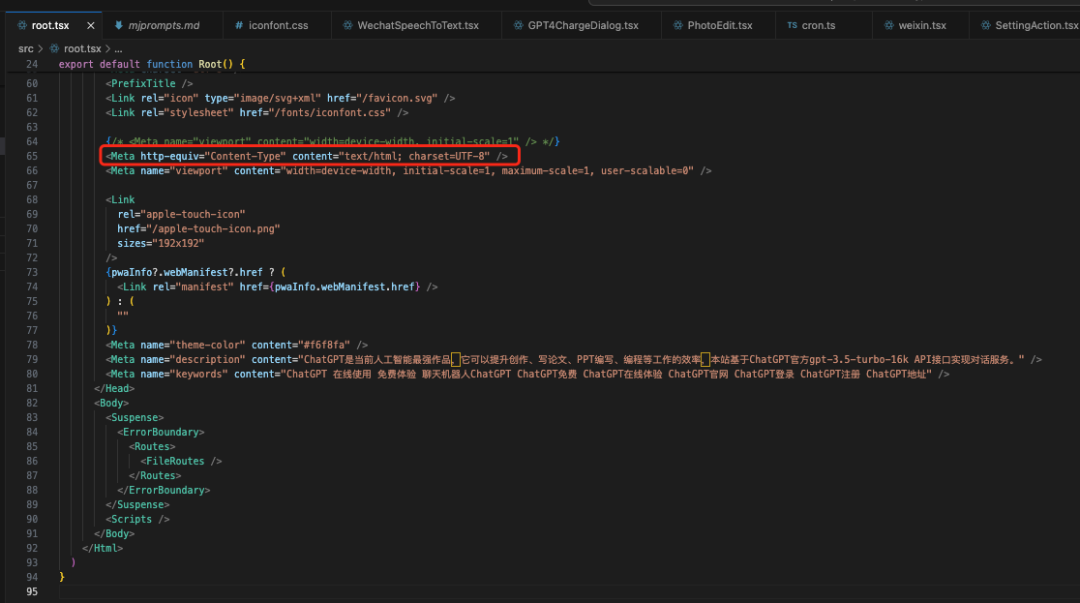
乍一看没啥问题,指定的编码确实是UTF-8,理论上只要在这里指定 UTF-8 编码,浏览器就能据此正常解码,但为什么这个用户还是有乱码问题呢
眼尖的朋友朋友估计一眼就发现了问题,上面的这些配置是配在 root.tsx, 它是一个 tsx 文件,最终是会被编译成 js 的,也就是说上面的配置是在一个 js 文件中动态生成的!
由于 meta 这些标签是 js 动态生成的,那么浏览器下载拿到 js 文件时其实是不知道它用的是什么编码的,等你生成了 meta 标签,它已经解码完成了,我们可以通过查看一下网页的源码验证一下我们的猜想:
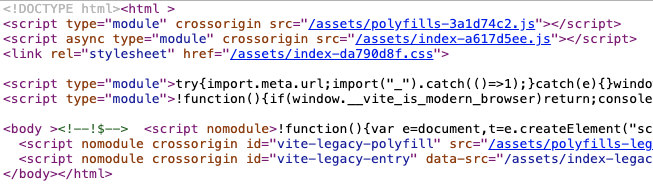
可以看到源文件中确实没有 meta utf-8,与我们的猜想相符。
问题找到了但怎么解决呢。主要有两种方法
- 写一个模板,让 vite 编译时根据这个模板编译生成带有
<head><meta charset="UTF-8"></head>这个选项的源文件,如下
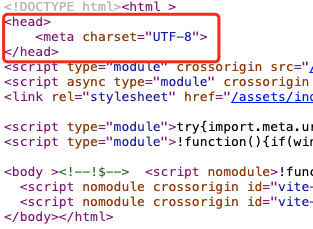
当然了你也可以编译后写个脚本将编译生成的 index.html 文件加上如上标签
- 还有一种更简单的方式
之前是因为编译出的 index.html 缺少 meta 这个标签,导致浏览器无法知道文件用的是什么编码,那除了这个还有其他办法让浏览器知道用的是什么编码吗,有的,在返回的文件中指定 Content-Type 的 charset 为 utf-8 即可,如下
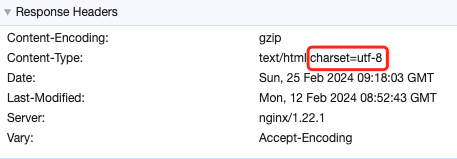
我们的工程是 node 工程,请求会先打到 nginx, 再转发到 node,最终也是通过 nginx 返回的,所以我们在 nginx 的配置文件中设置如下:
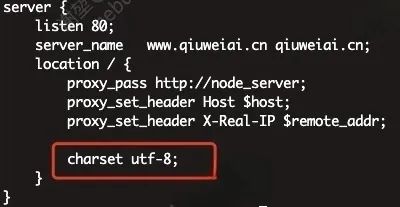
这样就会在 Content-Type 中返回 charset=utf-8,解码也就正常了
文中其实留了一个问题,为什么最开始既没指定 meta 标签也没在返回的 header 中指定 Content-Type 但大多数机型却依然展示正常呢
- 智能字符编码检测:现代浏览器和操作系统通常具有更强大和精准的字符编码检测机制。即使没有明确指定字符集,它们也能更准确地猜测和识别文本的编码,尤其是对于常见的编码格式如 UTF-8。
- 默认编码假设:许多现代浏览器和操作系统可能默认假设文本是 UTF-8 编码的,特别是当无法从内容中明确识别编码时。由于 UTF-8 是目前最广泛使用的字符编码,这种假设在大多数情况下是有效的。
- 自动字符集转换:一些现代浏览器可能在后台自动进行字符集转换,当它们检测到可能的编码问题时,会尝试使用不同的编码来解析文本,以找到最佳显示方式。
- 操作系统和浏览器更新:随着操作系统和浏览器的更新,对于国际化和多语言支持的改进也在不断进行。这包括对不同字符编码的更好支持,使得即使在缺乏明确编码声明的情况下,也能正确显示文本。
- 优化的默认设置:在新版本的操作系统和浏览器中,开发者可能已经优化了默认设置,以更好地处理全球化的网络内容,其中包括对 UTF-8 编码的优化支持。
然而,即使在最新的系统和浏览器中通常能够正确处理未明确指定字符集的情况,最佳实践仍然是在服务器端显式声明字符集或在 meta 标签中指定 UTF-8 编码。这样可以提供更可靠的用户体验,确保在各种环境和设备上的内容都能被正确地显示,减少因字符编码问题导致的潜在乱码问题。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-02-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号