CVPR 2023 | MIME: 人物感知的 3D 场景生成

CVPR 2023 | MIME: 人物感知的 3D 场景生成

用户1324186
发布于 2024-01-23 17:30:57
发布于 2024-01-23 17:30:57
来源:CVPR 2023 论文题目:MIME: Human-Aware 3D Scene Generation 论文链接:https://arxiv.org/abs/2212.04360 论文作者:Hongwei Yi 等人 内容整理: 林宗灏 本文提出了从 3D 人物运动生成 3D 室内场景方法 MIME,该方法由人物运动推断室内的自由空间和物体,采用自回归 Transformer 架构,将场景中人物动作和已生成的物体作为输入,输出下一个可信的物体。为了训练 MIME,本文构建了一个包含交互人物和自由空间人物的 3D 场景数据集 3D FRONT HUMAN。实验表明,MIME 生成的 3D 场景支持人物接触和运动,并能够在自由空间中填充可信的物体。
引言
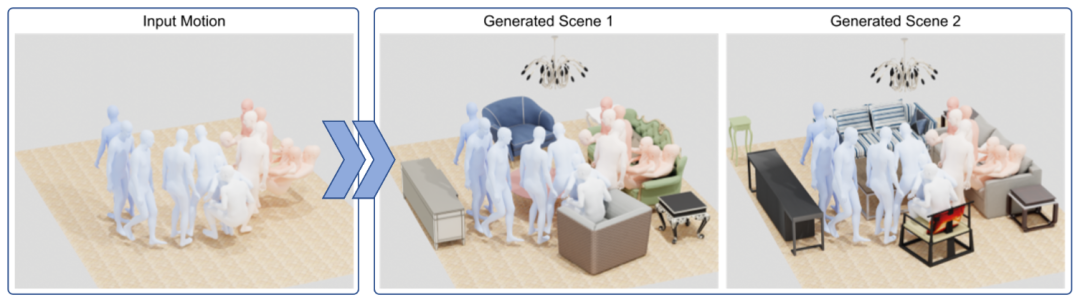
图 1:从人物运动估计 3D 场景。给定 3D 人物动作,我们可以重建运动可能发生的 3D 场景。我们的生成模型能够生成多个逼真的场景,这些场景考虑了人物的位置和姿势,并具有合适的人物-场景交互。
人类与周围环境处于持续的互动之中,例如在房间里行走、触摸物体、在椅子上休息、在床上睡觉等。所有这些互动都包含有关场景布局和物体摆放的信息。事实上,默剧表演者就是利用对这些互动的理解,通过肢体动作来传达一个想象中的三维世界。为了从 3D 人物运动生成 3D 室内场景,我们提出了 MIME(Mining Interaction and Movement to infer 3D Environments)来生成与人物运动相一致的室内场景。直观而言,人物运动表示室内的自由空间,而人物接触表示支持坐、躺、触摸等活动的表面或物体。MIME 采用自回归 Transformer 架构,将场景中人物动作和已生成的物体作为输入,输出下一个可信的物体。为了训练 MIME,我们向 3D FRONT 数据集中填充 3D 人物,构建了名为 3D FRONT Human 的新数据集。实验表明,MIME 生成的 3D 场景支持人物接触和运动,并能够在自由空间中填充可信的物体。本文的主要贡献总结如下:
- 一种新颖的基于运动条件的 3D 室内场景生成模型,该模型可自回归生成与人物接触和非接触的物体。
- 一个包含交互人物和自由空间人物的 3D 场景数据集,该数据集通过将 RenderPeople 的静态姿势和 AMASS 的运动数据填充至 3D FRONT 来构建。
方法
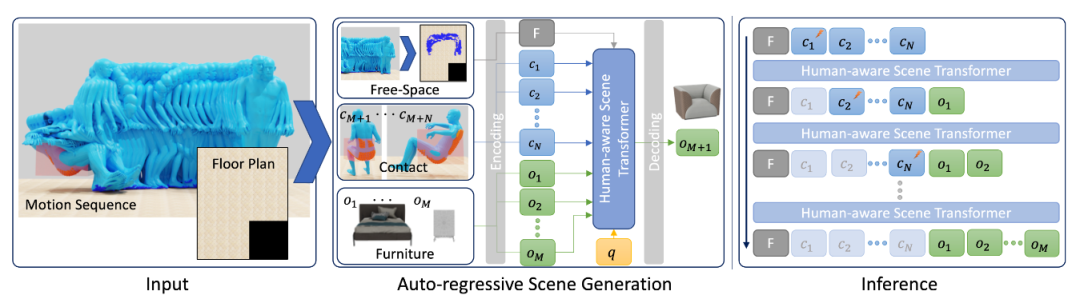
图 2:方法总览。在训练阶段,我们的方法基于平面图、自由空间、接触人物、现有物体和一个可学习的查询,通过 Transformer 编码器和解码器模块来生成下一个物体,并最小化生成物体与真值分布的负对数似然。在推理阶段,我们从输入平面图、自由空间、接触人物来自回归生成物体。在每一步,我们移除与已生成物体重合的接触人物,并生成下一个物体直至结束符号。
生成式人物感知场景合成
我们将 3D 场景
表示为物体的无序集合,包含与人物接触的物体
和无接触的物体
,即
。平面图
、自由空间掩膜
、接触人物
以及已存在的物体
编码后送入自回归 Transformer 模型,来预测用于生成下一个物体的特征,然后由 MLP 解码物体的类别、平移、旋转和大小。
场景生成的对数似然包括接触物体和无接触物体:
接触物体的对数似然由各接触物体的似然累加:
表示以平面图、自由空间、其余接触人物和已生成物体为条件生成第
个物体的概率,
是场景中生成物体的随机排列函数。无接触物体的对数似然通过将输入中的接触人物替换为已生成的接触物体计算。在训练过程中,我们移除所有的接触人物,此时所有接触物体
可视为无接触物体
:
我们在训练过程中使用蒙特卡洛抽样来近似所有不同物体的排列,从而使我们的模型不受生成对象顺序的影响。
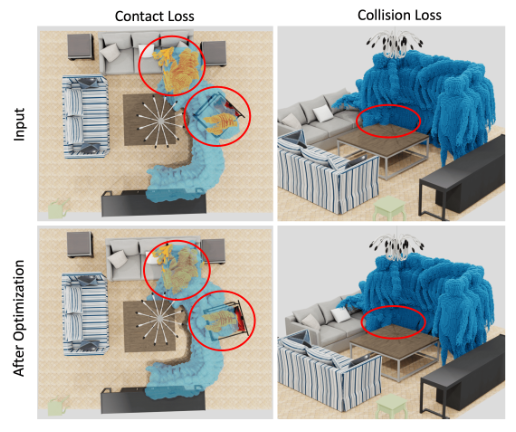
图 3:使用碰撞损失和接触损失进行场景细化。
模型生成的场景由 3D 边界框表示。根据边界框的大小和类别标签,我们从 3D FUTURE 中检索最接近的网格模型。为了改善输入人物和生成场景之间的交互,我们采用碰撞损失和接触损失来细化物体位置,即计算统一的 SDF 和所有接触点,联合优化物体对齐来改善人物与物体的接触,解决人物与场景之间的穿模问题。
数据集

图 4:填充 3D 场景示意图。给定一个房间,我们随机放置一些静态站立的人物,在自由空间中添加多种具有不同起始位置和方向的行走运动序列。我们还填充了多种接触人物至场景中,使他们与物体之间具有合理的交互,例如坐、躺、触摸。
我们通过在 3D FRONT 中的 3D 房间中填充互动人物来生成一个包含大量房间和各种人物互动的新数据集 3D FRONT HUMAN。我们将人物表示为 SMPL-X 模型,并将来自 RenderPeople 的接触人物以可信的交互方式随机分配至房间中的各种可接触物体。在自由空间中,我们随机填充了一些静态站立的人物,添加了来自 AMASS 的具有随机起始位置和方向的行走动作序列,并移除了与场景中物体相交的人物。
实验
定量结果

表 1:3D FRONT HUMAN 测试集上的定量比较。穿模损失、2D IoU 和 3D IoU 用于评估生成场景中人物与场景的交互。FID 分数和类别 KL 散度用于评估生成场景相较真实场景的真实性与多样性。

表 2:PROXD 数据集上的 3D 物体准确性比较。
定性结果

图 5:3D FRONT HUMAN 测试集上的定性比较。在输入自由空间和接触人物的情况下,MIME 生成的场景中接触人物与物体进行了互动,自由空间人物与所有生成物体的碰撞较少。我们还展示了输入或不输入自由空间掩膜的原始 ATISS。
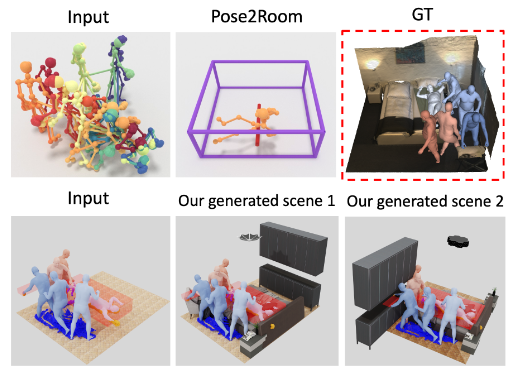
图 6:PROX 数据集上的评估。与 Pose2Room 相比,MIME 不仅能生成更准确的接触物体,还能在自由空间中生成合适的物体。
消融实验

图 7:关于不同数量接触人物和不同密度自由空间人物的消融实验。更多的接触人物作为输入,生成场景中将包含更多接触物体。更多的自由空间人物将导致场景中更少的物体。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-20,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号