再来说说sparksql中count(distinct)原理和优化手段吧~

再来说说sparksql中count(distinct)原理和优化手段吧~

数据仓库践行者
发布于 2024-01-16 14:43:27
发布于 2024-01-16 14:43:27
元旦前一周到现在总共接到9个sparksql相关的优化咨询,这些案例中,有4个和count(distinct)有关。
本来以为count(distinct)是老知识点了,之前有总结过相关的内容:
sparksql源码系列 | 一文搞懂with one count distinct 执行原理
但发现这块还是会成为大家解决运行效率问题的卡点。
我们知道sparksql处理count(distinct)时,分两种情况:
- with one count distinct
- more than one count distinct
这两种情况,sparksql处理的过程是不相同的
其中【with one count distinct】在sparksql源码系列 | 一文搞懂with one count distinct 执行原理 一文中详细介绍过啦,这篇主要分析一下【more than one count distinct】这种情况下的运行原理及优化手段。
运行过程分析
sql:
select
count(distinct a) as a_num,
count(distinct b) as b_num
from testdata2各阶段执行计划:
== unresolved logical plan ==
'Project ['count(distinct 'a) AS a_num#20, 'count(distinct 'b) AS b_num#21]
+- 'UnresolvedRelation [testdata2], [], false
== Analyzed Logical Plan ==
Aggregate [count(distinct a#3) AS a_num#20L, count(distinct b#4) AS b_num#21L]
+- SubqueryAlias testdata2
+- View (`testData2`, [a#3,b#4])
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#3, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#4]
+- ExternalRDD [obj#2]
== Optimized Logical Plan ==
Aggregate [count(testdata2.a#27) FILTER (WHERE (gid#26 = 1)) AS a_num#20L, count(testdata2.b#28) FILTER (WHERE (gid#26 = 2)) AS b_num#21L]
+- Aggregate [testdata2.a#27, testdata2.b#28, gid#26], [testdata2.a#27, testdata2.b#28, gid#26]
+- Expand [[a#3, null, 1], [null, b#4, 2]], [testdata2.a#27, testdata2.b#28, gid#26]
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#3, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#4]
+- ExternalRDD [obj#2]
== Physical Plan ==
HashAggregate(keys=[], functions=[count(testdata2.a#27), count(testdata2.b#28)], output=[a_num#20L, b_num#21L])
+- HashAggregate(keys=[], functions=[partial_count(testdata2.a#27) FILTER (WHERE (gid#26 = 1)), partial_count(testdata2.b#28) FILTER (WHERE (gid#26 = 2))], output=[count#31L, count#32L])
+- HashAggregate(keys=[testdata2.a#27, testdata2.b#28, gid#26], functions=[], output=[testdata2.a#27, testdata2.b#28, gid#26])
+- HashAggregate(keys=[testdata2.a#27, testdata2.b#28, gid#26], functions=[], output=[testdata2.a#27, testdata2.b#28, gid#26])
+- Expand [[a#3, null, 1], [null, b#4, 2]], [testdata2.a#27, testdata2.b#28, gid#26]
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#3, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#4]
+- Scan[obj#2]
== executedPlan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[], functions=[count(testdata2.a#27), count(testdata2.b#28)], output=[a_num#20L, b_num#21L])
+- Exchange SinglePartition, ENSURE_REQUIREMENTS, [plan_id=36]
+- HashAggregate(keys=[], functions=[partial_count(testdata2.a#27) FILTER (WHERE (gid#26 = 1)), partial_count(testdata2.b#28) FILTER (WHERE (gid#26 = 2))], output=[count#31L, count#32L])
+- HashAggregate(keys=[testdata2.a#27, testdata2.b#28, gid#26], functions=[], output=[testdata2.a#27, testdata2.b#28, gid#26])
+- Exchange hashpartitioning(testdata2.a#27, testdata2.b#28, gid#26, 5), ENSURE_REQUIREMENTS, [plan_id=32]
+- HashAggregate(keys=[testdata2.a#27, testdata2.b#28, gid#26], functions=[], output=[testdata2.a#27, testdata2.b#28, gid#26])
+- Expand [[a#3, null, 1], [null, b#4, 2]], [testdata2.a#27, testdata2.b#28, gid#26]
+- SerializeFromObject [knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).a AS a#3, knownnotnull(assertnotnull(input[0, org.apache.spark.sql.test.SQLTestData$TestData2, true])).b AS b#4]
+- Scan[obj#2]执行过程:
将源码翻译成执行图
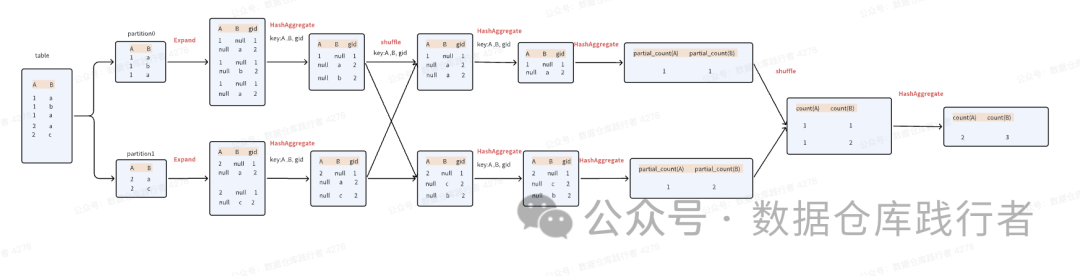
多个count(distinct)的场景下:
- 生成expand算子,生成gid,不同distinct的列gid不同
- 以expand中生成的列[testdata2.a#27, testdata2.b#28, gid#26]为key做聚合
- 计算count时,不同的列,用gid区分。比如计算a时,过滤gid=1;而计算b时,过滤gid=2:partial_count(testdata2.a#27) FILTER (WHERE (gid#26 = 1)), partial_count(testdata2.b#28) FILTER (WHERE (gid#26 = 2))
从执行过程中能看出,expand会导致数据翻倍,expand属于窄依赖算子,也就是说,task总数是不变的,由于数据翻倍,单个task处理的数据量膨胀了。
源码分析
这里关注两个模块儿的源码
1、expand在什么时候被生成
count(distinct)这种情况下,expand是在逻辑执行计划优化阶段被生成,对应的类是:RewriteDistinctAggregates
RewriteDistinctAggregates类可分为三部分来理解

如果上图,说两个点:
1.1、regularAggProjection(非distinct聚合)以及distinctAggProjections(带distinct聚合)
如果sql中存在非distinct类的聚合,比如,sql是:
select
sum(a) as s_num,
sum(b) as m_num,
count(distinct a) as a_num,
count(distinct b) as b_num
from testdata2那么
- regularAggProjection是[null, null, 0, a#3, b#4] --只有一组 gid=0
- distinctAggProjections是[a#3, null, 1, null, null],[null, b#4, 2, null, null] --有几个count(distinct) 就有几组 gid=1,2...
如果sql中没有非distinct类的聚合,比如,sql是:
select
count(distinct a) as a_num,
count(distinct b) as b_num
from testdata2那么
- regularAggProjection是 Seq.empty[Seq[Expression]] (一个没有元素的List)
- distinctAggProjections是[a#3, null, 1],[null, b#4, 2]
1.2、被RewriteDistinctAggregates处理过后的逻辑执行计划
sql:
select
count(distinct a) as a_num,
count(distinct b) as b_num
from testdata2生两个Aggregate节点,最后一个Aggregate count时,用gid做过滤

2、expand算子的运行原理
ExpandExec是expand的执行类,执行过程如下
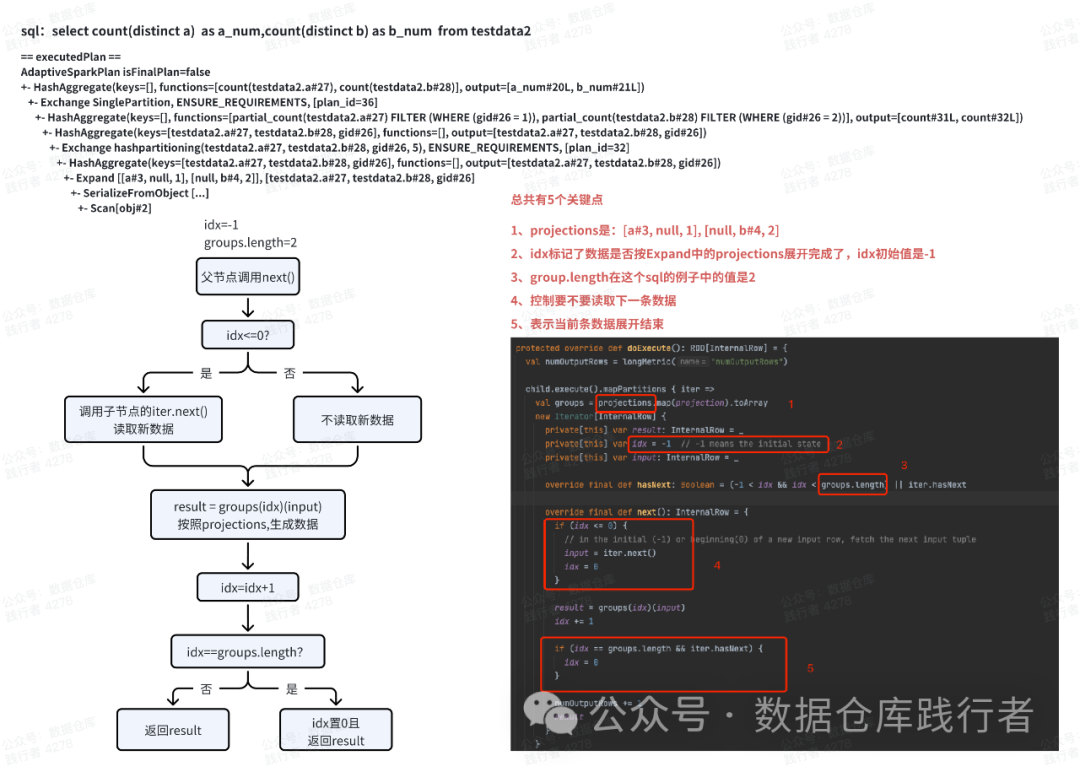
ExpandExec类在读取数据时,会按照 projections列表去对数据翻倍
常用优化手段
1、sql改写:
----------原始sql------------
select
count(distinct if(b=1,a,null)) as a_num1,
count(distinct if(b=3,a,null)) as a_num2 ,
count(distinct if(b=4,a,null)) as a_num3
from testdata2
----------改写------------
select
count(if(b1_flag=1,a,null)) as a_num1,
count(if(b3_flag=1,a,null)) as a_num2,
count(if(b4_flag=1,a,null)) as a_num3
from (
select
a,
max(if(b=1,1,0)) as b1_flag,
max(if(b=3,1,0)) as b3_flag,
max(if(b=4,1,0)) as b4_flag
from testdata2 group by a
)2、改参数,让单个task处理更少的数据:
情况1
count(distinct) 在读表后
减少单个task读表时的数据量,核心参数:
spark.sql.files.maxPartitionBytes --适当改小
情况2
count(distinct)在join或者其他shuffle后
利用aqe,增加shuffle的partition数量,核心参数:
spark.sql.adaptive.maxNumPostShufflePartitions --适当改大
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号