基于Aidlux平台的智能版面分析
原创
基于Aidlux平台的智能版面分析
原创
用户10686717
发布于 2024-01-09 19:52:01
发布于 2024-01-09 19:52:01
版面分析是将文档图像进行文档对象识别并判断各区域所属类别,如配图、表格、公式、分栏等,并对不同类型的区域进行切分、识别。后面的工作是实现包括组卷、以题搜题、文档电子化存储、结构化解析等功能。
版面分析的背景介绍:

目标:
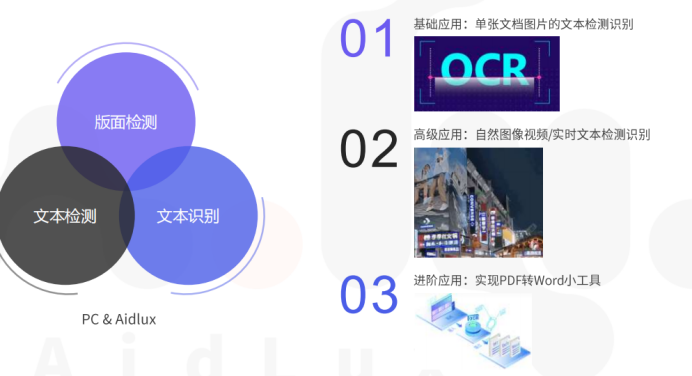
图像版面分析任务拆解:

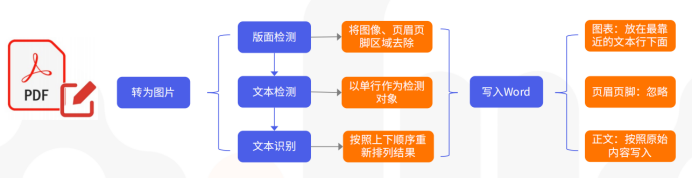
PDF转Word:
本实战采用CDLA数据集(A Chinese document layout analysis (CDLA) dataset 进行YOLOv8训练,将训练结果生成的best.pth进行onnx转化:
首先,ONNX是一种通用的深度学习模型格式,支持广泛的深度学习框架,包括
PyTorch、TensorFlow、MXNet等。
因此,将PyTorch模型转换为ONNX格式可以方便地在其他框架上部署和运行。
其次,ONNX支持模型优化和压缩,可以将模型大小和计算性能进一步优化,以满足实际应用的需求。
在Aidlux平台上上传代码包后,分别进行相关配置后,进行PDF转图片->版面检测->文本检测和识别等流程,输出Word。
具体的代码如下:
from layout_engine import *
# cap = cvs.VideoCapture()
if __name__ == "__main__":
print("----------------------------- 相关配置 --------------------------------")
# 加载检测和识别模型
OCR_model = OcrEngine()
layout_model = predictor.load_layout_model()
print("-->模型加载成功")
# 输入的PDF路径
pdf_path = "inputs/paper1.pdf"
pdf_name = pdf_path.split("/")[-1].split(".pdf")[0]
print("----------------------------- PDF转图片 --------------------------")
# 获取当前请求时间
ti = time.localtime()
date = f"{ti[0]}_{ti[1]}_{ti[2]}"
uid = uuid.uuid4().hex[:10]
# 需要储存图片的目录
imagePath = f"outputs/pdf/{ti[0]}_{ti[1]}_{ti[2]}_{ti[3]}_{ti[4]}_{ti[5]}_{uid}"
os.makedirs(imagePath, exist_ok=True)
pyMuPDF_fitz(pdf_path, imagePath)
# 创建一个doc文档,用于后续填充内容
doc = docx.Document()
default_section = doc.sections[0]
default_section.page_width = Cm(21)
default_section.page_height = Cm(30)
pdf_image_path_list = os.listdir(imagePath)
# os.listdir的数字从小到大排序
pdf_image_path_list.sort(key=lambda x: int(x[:-4]))
img_num = 0
for pdf_image in tqdm.tqdm(pdf_image_path_list):
print("----------------------------- 版面检测--------------------------")
pdf_image_path = os.path.join(imagePath, pdf_image)
im_cv2 = cv2.imread(pdf_image_path)
im_b64 = np2base64(im_cv2)
layout_result,results = predictor.layout_predict(layout_model, im_b64)
results = results[0].plot()
# 填充图像、表格、页眉、页脚区域为白色,避免文本OCR的干扰
im_cv2_plot = im_cv2.copy()
for item in layout_result:
points = item.values()
for point in points:
im_cv2_plot = cv2.rectangle(im_cv2_plot, (point[0], point[1]), (point[2], point[3]), (255, 255, 255),
-1)
print("----------------------------- 文本检测和识别--------------------------")
img_draw, result_list = OCR_model.text_predict(im_cv2_plot, 960) # 文本检测和识别
# 将绘制后的图片从BGR格式转换为RGB格式
img_draw_PIL = Image.fromarray(cv2.cvtColor(results, cv2.COLOR_BGR2RGB))
ocr_result = []
for result in result_list:
ocr_dict = {}
box, text = result[0].tolist(), result[1]
box_xy = [box[0][0], box[0][1], box[2][0], box[2][1]]
ocr_dict[text] = box_xy
ocr_result.append(ocr_dict)
img_draw_PIL = cv2ImgAddText(img_draw_PIL, text, box[0][0], box[0][1])
img_draw_cv = cv2.cvtColor(np.asarray(img_draw_PIL), cv2.COLOR_RGB2BGR)
# cvs.imshow(img_draw_cv)
cv2.imwrite(f"outputs/plot/{img_num}.jpg",img_draw_cv)
img_num = img_num + 1
print("----------------------------- 写入Word--------------------------")
# 图片和文本行按照y轴方向进行排序(单栏适用,多栏请先做好分栏操作)
final_result = ocr_result + layout_result
final_result_sort = sorted(final_result, key=lambda x: x[list(x.keys())[0]][1])
for item in final_result_sort:
keys_list = item.keys()
for key in keys_list:
# 对图片和表格进行处理:裁剪-->保存-->写入Word文档
if key in ["Figure", "Table"]:
points = item[key]
crop_img = im_cv2[points[1]:points[3], points[0]:points[2]]
uid = uuid.uuid4().hex[:10]
name = f"{ti[0]}_{ti[1]}_{ti[2]}_{ti[3]}_{ti[4]}_{ti[5]}_{uid}"
crop_img_path = f"outputs/crop/{name}.jpg"
cv2.imwrite(crop_img_path, crop_img)
doc.add_picture(crop_img_path, width=Cm(11))
# 对页眉和页脚不做写入操作,跳过
elif key in ["Header", "Footer"]:
continue
# 对其他情况(Text正文部分):保存并设置字体和大小
else:
paragraph = doc.add_paragraph()
run = paragraph.add_run(key)
font = run.font
font.name = 'Times New Roman'
font.size = docx.shared.Pt(11)
# 保存文档
word_name = f"{pdf_name}_{ti[0]}_{ti[1]}_{ti[2]}_{ti[3]}_{ti[4]}_{ti[5]}_{uid}"
word_path = f'outputs/words/{word_name}.docx'
doc.save(word_path)
print("Done!")原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号