112-exadata从一个6亿大表取最大值需要将近5分钟,如何优化?

112-exadata从一个6亿大表取最大值需要将近5分钟,如何优化?

老虎刘
发布于 2023-12-20 20:50:50
发布于 2023-12-20 20:50:50
下面是某客户生产系统的sql monitor截图,一个380G的大表全表扫描,耗时4.53分钟, 看来这个exadata的配置不算太高, 平均1.4GB/秒的IO吞吐量:
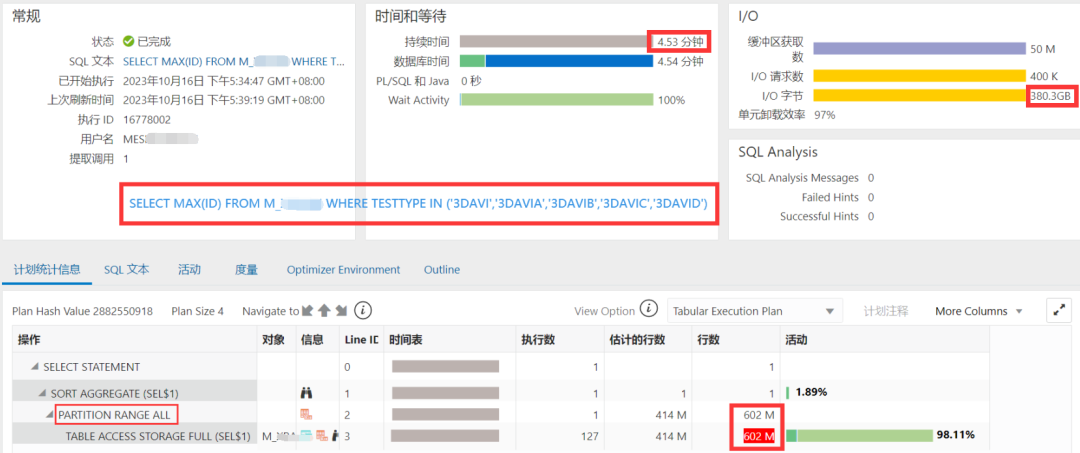
已知ID字段是表的主键, 如何让这个SQL呢?
最简单的优化方法就是改写, 我们以一个500万记录的测试表为例(表名T5m):
--创建一个500万记录的表(占用空间 592M),并增加主键约束:
create table T5m as
select /*+ leading(b) */rownum as id,a.*
from dba_objects a,xmltable('1 to 1000') b
where rownum<=5e6;
alter table t5m add constraint pk_t5m_id primary key(id);模拟业务SQL:
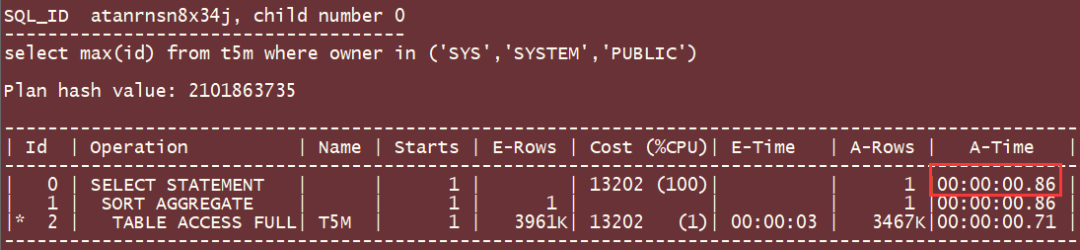
select max(id) from t5m where owner in ('SYS','SYSTEM','PUBLIC');
全表扫描, 执行时间0.86秒:
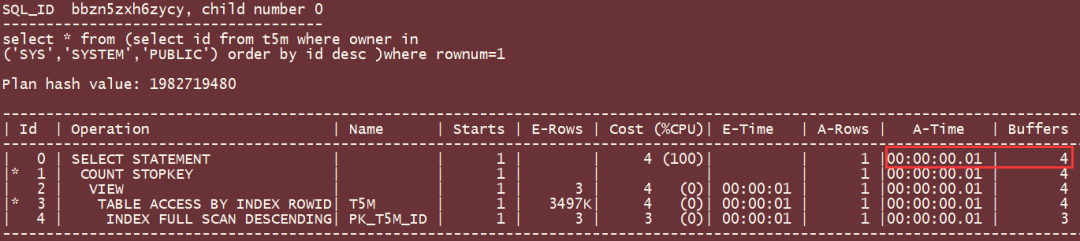
将SQL改写成下面这样:
select * from (select id from t5m where owner in ('SYS','SYSTEM','PUBLIC') order by id desc )where rownum=1;
执行时间只有1~2毫秒, 有几百倍的性能提升(表越大, 提升倍数越大):
这个SQL的优化到这里就结束了, 生产使用的业务SQL也会从接近5分钟降到1~2毫秒, 大概有10几万倍的性能提升,资源消耗基本上可以忽略不计.
(注: 在没有结果集返回的情况,与原SQL不完全等价)
扩展知识点:
上面这个改写有个缺点: sql的执行效率受数据分布情况的影响,像下面没有符合条件的记录, 优化器还是会选择全表扫描, 执行时间还是会比较长(生产上的数据分布不是这种情况):
select * from (select id from t5m where owner in ('SYS2','SYSTEM2','PUBLIC2') order by id desc )where rownum=1;
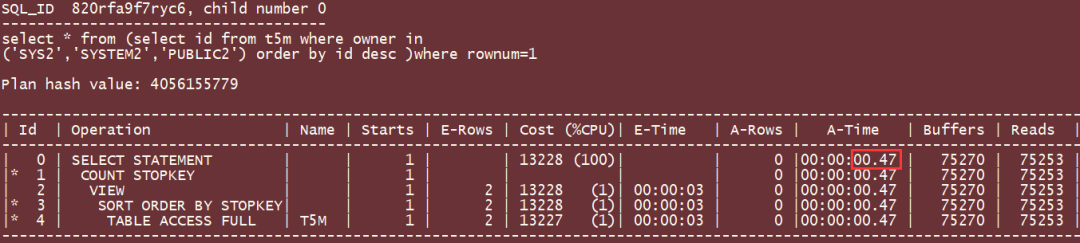
有没有办法能让SQL无论在什么样的数据分布下, 都能高效执行呢?
答案是有的, 需要创建(owner,id)两字段, 同时将SQL改成下面这样:
select max(max_id) from
(
select max(ID) as max_id FROM T5m WHERE OWNER ='SYS'
union all
select max(ID) FROM T5m WHERE OWNER ='PUBLIC'
union all
select max(ID) FROM T5m WHERE OWNER ='SYSTEM'
);SQL执行时间2~3 毫秒左右:
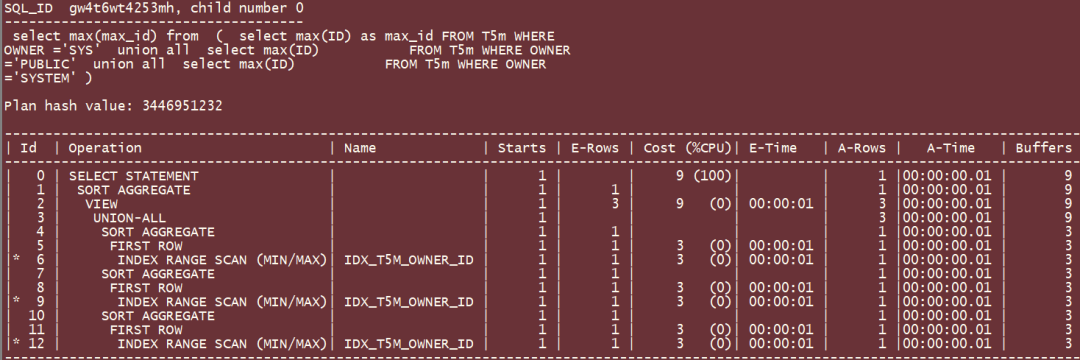
简洁一点的写法是这样的(in列表个数越多,上面的union all就更多, 下面的sql代码越显得简洁):
select max(max_id) from
(
select
(select max(id) from t5m b where a.column_value=b.owner) as max_id
from table(sys.ODCIVARCHAR2LIST('SYS','SYSTEM','PUBLIC'))a
);对于Mysql来说, 第一种改写是下面这样的(只有ID字段上的主键,没有owner,id联合索引的情况), 使用如下条件, 效率也非常高:
select id from t5m where owner in ('SYS','PUBLIC','SYSTEM') order by id desc limit 1;
但是如果使用如下条件, 效率反而会更差(仍会使用索引扫描,这一点不如oracle):
select id from t5m where owner in ('SYS2','PUBLIC2','SYSTEM2') order by id desc limit 1;
Mysql 不考虑数据分布的简洁写法可以是下面这样(创建了owner,id两字段联合索引的前提):
select max(max_id) from (select owner,max(id) as max_id from t5m where owner in ('SYS','PUBLIC','SYSTEM') group by owner)x;
对于postgresql来说, 跟oracle差不多, 它的简洁写法我是这样写的:
select max(max_id) from
(
select
(select max(id) from t5m b where a.owner=b.owner) as max_id
from
(select regexp_split_to_table('SYS,SYSTEM,PUBLIC',',') as owner)a
)x;本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-12-15,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 老虎刘谈oracle性能优化 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号