Go语言之爬虫简单爬取腾讯云开发者社区的文章基本数据
原创
Go语言之爬虫简单爬取腾讯云开发者社区的文章基本数据
原创
言志志
修改于 2023-12-08 12:13:19
修改于 2023-12-08 12:13:19
前言
本文是探讨的是"Go语言之爬虫简单爬取腾讯云开发者社区的文章基本数据"
此文章是个人学习归纳的心得,腾讯云独家发布,未经允许,严禁转载,如有不对, 还望斧正, 感谢!
一、关于爬虫的基本知识
1. 爬虫是什么
爬虫(Web crawler)是一种自动化程序或脚本,专门用于在互联网上浏览、抓取和提取信息。这些程序也被称为网络爬虫、网络蜘蛛、网络机器人或网络蠕虫。爬虫通过模拟人类对网页的访问,自动地从互联网上获取信息,并将其存储或进一步处理。
爬虫的基本工作流程通常包括以下步骤:
- 发送请求: 爬虫通过HTTP或其他网络协议向目标网站发送请求,请求特定的网页或资源。
- 接收响应: 爬虫接收目标服务器的响应,该响应包含请求的网页或资源的内容。
- 解析内容: 爬虫解析接收到的内容,通常是HTML、XML或其他标记语言,以提取有用的信息。这可能涉及到正则表达式、XPath、CSS选择器或使用解析库(如Beautiful Soup或lxml)。
- 存储数据: 爬虫将提取的信息存储在本地数据库、文件或其他数据存储系统中,以供后续分析或使用。
- 跟踪链接: 爬虫可能会在提取的页面中查找其他链接,并递归地访问这些链接,以获取更多的信息。
爬虫的应用非常广泛,主要有以下方面:
- 搜索引擎索引: 搜索引擎使用爬虫来定期抓取互联网上的网页,并建立索引,以便用户能够通过搜索引擎查找相关信息,比如国内常用的百度,其实就是一个大型的爬虫,把相关网站数据爬取之后,然后在他那边进行数据的展示和处理
- 数据采集: 企业和研究者使用爬虫来收集互联网上的数据,用于市场研究、竞品分析、舆情监测等。
- 价格比较: 一些爬虫被用于比较不同在线商店的产品价格,以帮助消费者找到最优惠的交易。
- 新闻聚合: 爬虫可以用于从各种新闻网站收集新闻,创建新闻聚合服务。
其实爬虫,就是用代码来模拟真人在浏览器上的操作,就像用户在浏览器中查看和点击网页一样,来获取互联网上的信息。但是我们通过爬虫,可以很快速,大量,精准地获取到我们想要的信息。
二、go语言写简单的爬虫
2.1 分析需求
本次是要爬腾讯云开发者社区的文章,主要是自己的个人博客完工了,我想在展示自己文章的时候,在旁边的侧边栏展示相关的技术文章,那其实很简单,获取到自己文章的标题之后,然后到腾讯云开发者社区进行搜索,然后得到前几个文章的标题和链接就行了,过程很简单。
先随便搜个东西,然后看地址栏,大概搜索的链接就是这玩意https://cloud.tencent.com/developer/search/article-Go语言实现爬虫,后面我们就向这边发请求就行了。

看了一下要爬取的内容,嗯,不是a标签,一般都是a标签里面套文章地址的,然后通过点击标题,跳转到文章详情页,看来是动态渲染,我以前用python简单爬过一些小说网站和卖二手房的网站,那种好爬一些。

这类动态渲染通常用于单页应用(Single Page Application,SPA)或使用前端框架(如React、Vue、Angular)构建的应用程序中,用浏览器插件Wappalyzer抓包看一下,嘿嘿,腾讯云是用的React

然后我们继续,在文档响应的最下面的script标签里面发现了相关数据
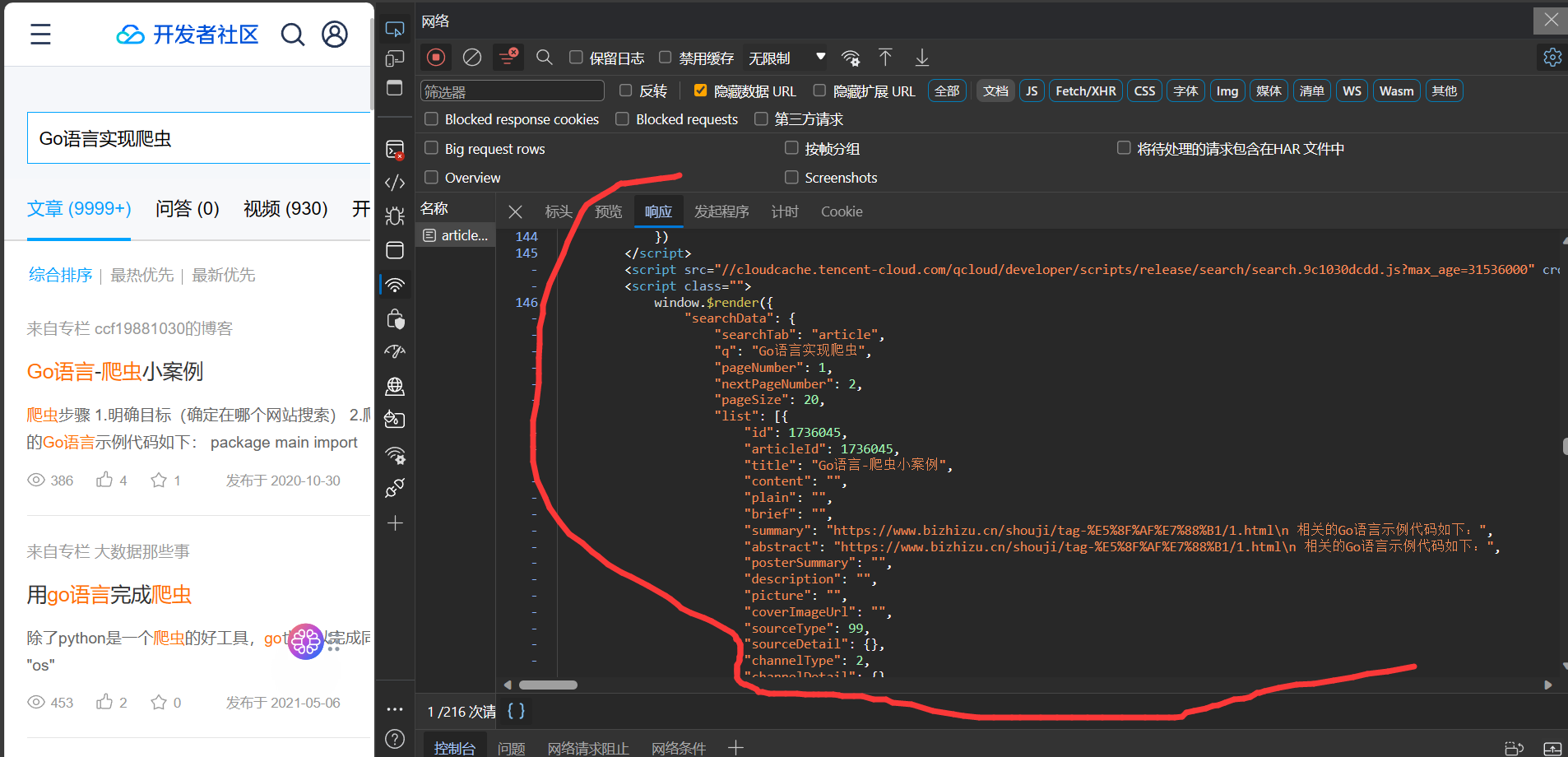
分析一下数据结构,是在list字段里面的,这玩意是一个结构体数组,然后id就是文章的id, title就是文章的标题

欧克,流程已经清晰,接下来就实现一下。
2.2 go语言写爬虫的优势
其实,如果只是说写爬虫的话,基本上所有的语言都可以,Python,java,JavaScript,c++,c 之类的,都可以拿来写爬虫,尤其是Python,在爬虫这方面生态很完善,但是我还是要用Go来写一下,原因无他,只有突破自己的舒适区,才能进步得更快。
当然也是想尝试一下,并且Go天生支持并发,在处理大规模并发任务时表现出色。用go来写爬虫的话,可以提高爬取效率。
2.3 代码实现
2.3.1 go语言中的Colly爬虫框架
python写爬虫的话,有很多框架,go语言的话,也有几个比较火的框架,本次使用最火的Colly,目前在github上有21.3k的star了
项目地址:gocolly/colly: Elegant Scraper and Crawler Framework for Golang (github.com)

官方文档也很详细,可以看一下
How to install | Colly (go-colly.org)
先安装
go get -u github.com/gocolly/colly/...然后导入
import "github.com/gocolly/colly"然后创建一个爬虫实例
c := colly.NewCollector()然后可以给这个爬虫加上事件监听器,可以在特定的时间做特定的事情,可以看下面完整的小示例
package main
import (
"fmt"
"log"
"github.com/gocolly/colly/v2"
)
func main() {
// 创建一个新的爬虫实例
c := colly.NewCollector()
// 在请求发送之前执行的回调函数
c.OnRequest(func(r *colly.Request) {
fmt.Println("正在访问:", r.URL)
})
// 在发生错误时执行的回调函数
c.OnError(func(_ *colly.Response, err error) {
log.Println("发生错误:", err)
})
// 在收到响应时执行的回调函数
c.OnResponse(func(r *colly.Response) {
fmt.Println("已访问:", r.Request.URL)
})
// 在HTML中找到所有带有href属性的a标签时执行的回调函数
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
// 访问链接的href属性
e.Request.Visit(e.Attr("href"))
})
// 在HTML中找到所有表格行的第一个单元格时执行的回调函数
c.OnHTML("tr td:nth-of-type(1)", func(e *colly.HTMLElement) {
fmt.Println("表格行的第一列:", e.Text)
})
// 在XML中找到所有h1标签时执行的回调函数
c.OnXML("//h1", func(e *colly.XMLElement) {
fmt.Println(e.Text)
})
// 在所有处理完成后执行的回调函数
c.OnScraped(func(r *colly.Response) {
fmt.Println("爬取完成:", r.Request.URL)
})
// 启动爬虫并访问指定的URL
err := c.Visit("https://example.com")
if err != nil {
log.Fatal(err)
}
}2.3.2 开干
然后上面的基本函数介绍完了,下面配置一些简单的反爬设置,这玩意可以看官方文档,很详细
我就是在创建爬虫实例之后简单地使用了Colly库中的 extensions.RandomUserAgent 和 extensions.Referer:
extensions.RandomUserAgent(c) // 使用随机的UserAgent,最好能使用代理。这样就不容易被ban
extensions.Referer(c) // 在访问的时候带上Referrer,意思就是这一次点击是从哪个页面产生的这里是使用Colly库提供的两个扩展函数,其中 extensions.RandomUserAgent 用于随机设置请求的UserAgent,而 extensions.Referer 则在访问时带上Referrer。
设置随机的UserAgent有助于模拟不同类型的浏览器或设备,减少被识别为爬虫的可能性。而设置Referrer则模拟用户通过某个页面跳转而来的访问,有时网站会检查Referrer来判断请求的来源。
为了解析里面的数据,我们要先定义一个对应结构的结构体,后面要先把数据读到这里面来,字段什么的一定要通过后面的json表示对应好,不然读取不到的
type SearchResult struct {
SearchData struct {
List []struct {
ID int `json:"id"`
Title string `json:"title"`
} `json:"list"`
} `json:"searchData"`
}然后就是最重要的,将数据精准地分离出来,一般我们常用
- 通过CSS选择器或XPath定位:
- 使用CSS选择器或XPath表达式可以非常精确地定位目标元素。这些选择器可以根据元素的标签名、类名、ID、属性等进行选择,实现对目标元素的准确定位。
- 使用正则表达式:
- 当目标数据具有特定的模式或格式时,可以使用正则表达式来匹配和提取需要的数据。这在文本数据的抽取中比较常见。
具体地话,你可以看看前面提到的各个函数,我下面的定位方法就比较粗糙了。
c.OnHTML("script:nth-last-child(2)", func(e *colly.HTMLElement) {
if e.Attr("class") == "" { // 我看那个标签的class为空,我当时还以为是做的标识,后面就懒得删了,记录一下,不影响运行
scriptContent := e.Text
// 使用正则表达式提取一下数组部分
re := regexp.MustCompile(`\{.*\}`)
matches := re.FindStringSubmatch(scriptContent)[0]
// 解析 JSON 字符串
var result SearchResult
err := json.Unmarshal([]byte(matches), &result)
if err != nil {
log.Fatal(err)
}
// 提取前三个结构体的 id 和 title
for i, item := range result.SearchData.List {
if i < 3 {
fmt.Printf("ID: %d, Title: %s\n", item.ID, item.Title)
}
}
}
})三、完整代码如下
package main
import (
"encoding/json"
"fmt"
"github.com/gocolly/colly"
"github.com/gocolly/colly/extensions"
"log"
"math/rand"
"regexp"
)
type SearchResult struct {
SearchData struct {
List []struct {
ID int `json:"id"`
Title string `json:"title"`
} `json:"list"`
} `json:"searchData"`
}
func main() {
c := colly.NewCollector()
c.UserAgent = "xy"
c.AllowURLRevisit = true
extensions.RandomUserAgent(c) // 使用随机的UserAgent,最好能使用代理。这样就不容易被ban
extensions.Referer(c) // 在访问的时候带上Referrer,意思就是这一次点击是从哪个页面产生的
c.OnError(func(_ *colly.Response, err error) {
log.Println("Something went wrong:", err)
})
c.OnResponse(func(r *colly.Response) {
fmt.Println("Visited", r.Request.URL)
})
c.OnHTML("script:nth-last-child(2)", func(e *colly.HTMLElement) {
if e.Attr("class") == "" {
scriptContent := e.Text
// 使用正则表达式提取一下数组部分
re := regexp.MustCompile(`\{.*\}`)
matches := re.FindStringSubmatch(scriptContent)[0]
// 解析 JSON 字符串
var result SearchResult
err := json.Unmarshal([]byte(matches), &result)
if err != nil {
log.Fatal(err)
}
// 提取前三个结构体的 id 和 title
for i, item := range result.SearchData.List {
if i < 3 {
fmt.Printf("ID: %d, Title: %s\n", item.ID, item.Title)
}
}
}
})
c.OnScraped(func(r *colly.Response) {
fmt.Println("Finished", r.Request.URL)
})
c.Visit("https://cloud.tencent.com/developer/search/article-go语言爬虫")
}运行结果:

我们可以通过在https://cloud.tencent.com/developer/article/的后面拼接上文章的id,就可以得到文章的详情链接。
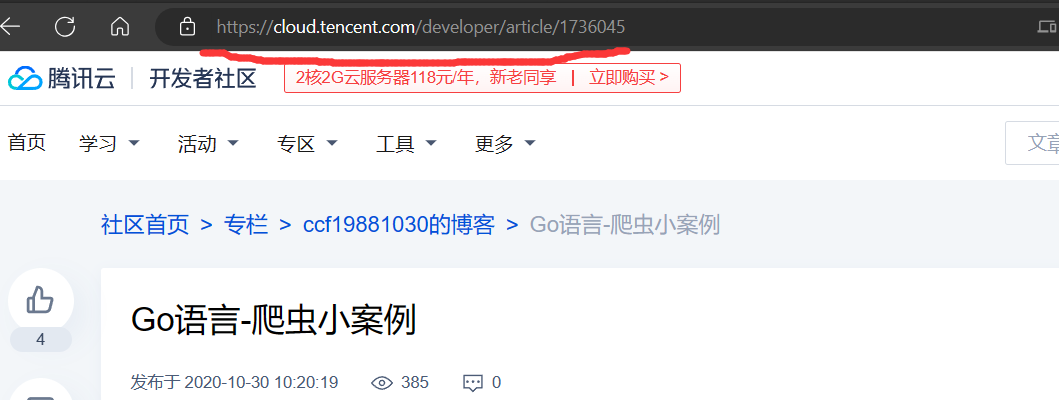
当然,上面的还是单线程的,我们可以稍加更改,一次性爬取多个, 完整代码如下,感兴趣的可以看看
package main
import (
"context"
"encoding/json"
"fmt"
"github.com/gocolly/colly"
"github.com/gocolly/colly/extensions"
"log"
"regexp"
"sync"
)
type SearchResult struct {
SearchData struct {
List []struct {
ID int `json:"id"`
Title string `json:"title"`
} `json:"list"`
} `json:"searchData"`
}
func main() {
// 创建一个等待组,以便等待所有的 goroutines 完成
var wg sync.WaitGroup
// 在 main 函数内部创建 Colly Collector
c := colly.NewCollector()
// 随机 User-Agent 和 Referer
extensions.RandomUserAgent(c)
extensions.Referer(c)
// 在 main 函数内部创建一个上下文和取消函数
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// 在请求发起时,使用闭包将上下文添加到请求中
c.OnRequest(func(r *colly.Request) {
// 将标准库的 context 转换为 colly.Context
collyCtx := colly.NewContext()
collyCtx.Put("stdContext", ctx)
r.Ctx = collyCtx
})
// 处理错误
c.OnError(func(_ *colly.Response, err error) {
log.Println("Something went wrong:", err)
// 可以在这里添加一些处理错误的逻辑
})
// 处理响应
c.OnResponse(func(r *colly.Response) {
fmt.Println("Visited", r.Request.URL)
})
// 在 HTML 中查找指定元素
c.OnHTML("script:nth-last-child(2)", func(e *colly.HTMLElement) {
if e.Attr("class") == "" {
scriptContent := e.Text
// 使用正则表达式提取数组部分
re := regexp.MustCompile(`\{.*\}`)
matches := re.FindStringSubmatch(scriptContent)
if len(matches) == 0 {
log.Println("No matches found in script content")
return
}
// 解析 JSON 字符串
var result SearchResult
err := json.Unmarshal([]byte(matches[0]), &result)
if err != nil {
log.Println("Error unmarshalling JSON:", err)
return
}
// 提取前三个结构体的ID和Title
for i, item := range result.SearchData.List {
if i < 3 {
fmt.Printf("ID: %d, Title: %s\n", item.ID, item.Title)
}
}
}
})
// 处理完成
c.OnScraped(func(r *colly.Response) {
fmt.Println("Finished", r.Request.URL)
})
// 要访问的 URL 列表
urls := []string{"https://cloud.tencent.com/developer/search/article-go语言爬虫", "https://cloud.tencent.com/developer/search/article-python爬虫"}
// 遍历 URL 列表,每个 URL 启动一个 goroutine
for _, url := range urls {
// 增加等待组计数
wg.Add(1)
// 启动 goroutine
go func(u string) {
defer wg.Done()
err := c.Visit(u)
if err != nil {
log.Println("Error visiting URL:", err)
}
}(url)
}
// 等待所有 goroutines 完成
wg.Wait()
}原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号