spring boot+sharding jdbc实现分库分表
原创
spring boot+sharding jdbc实现分库分表
原创
shigen
发布于 2023-12-03 12:18:09
发布于 2023-12-03 12:18:09
shigen日更文章的博客写手,擅长Java、python、vue、shell等编程语言和各种应用程序、脚本的开发。记录成长,分享认知,留住感动。
😅😅最近几天的状态有点不对,所以有几天没有更新了。
当我们的数据量比较大(没接触过)就会考虑一下分库分表的策略。当然分库分表又分为多种策略:
- 拆分数据库,做到数据的分离(多租户的设计)
- 水平拆分表:类似于数据的分片
- 垂直拆分表:某些不常用的字段放在另外一张表,我们通过主键关联,在之前的文章mysql表设计规范中也有提到:

一张表的字段不要过多
在去年疫情的时候,其实shigen就研究了一下这个,只不过当时用的是apache-shardingsphere,采用的是官方的资源包,需要各种安装和配置:
apache-shardingsphere
最近发现它其实可以和springboot结合起来使用,于是研究了一下,最后发现很好用。
官方配置文档在这里,需要详细步骤的可以去看下官网的案例和解释。
首先我们创建两个数据库,每个数据库两张表:
-- 数据库1中的user表
CREATE TABLE ds0.user0
(
id INT PRIMARY KEY COMMENT '用户ID',
name VARCHAR(50) COMMENT '用户姓名',
age INT COMMENT '用户年龄'
);
CREATE TABLE ds0.user1
(
id INT PRIMARY KEY COMMENT '用户ID',
name VARCHAR(50) COMMENT '用户姓名',
age INT COMMENT '用户年龄'
);
-- 数据库2中的user表
CREATE TABLE ds1.user0
(
id INT PRIMARY KEY COMMENT '用户ID',
name VARCHAR(50) COMMENT '用户姓名',
age INT COMMENT '用户年龄'
);
CREATE TABLE ds1.user1
(
id INT PRIMARY KEY COMMENT '用户ID',
name VARCHAR(50) COMMENT '用户姓名',
age INT COMMENT '用户年龄'
);对应关系是这样的:
数据库 | 数据表 | 备注 |
|---|---|---|
Ds0 | User0 | 数据源1的分表1 |
Ds0 | User1 | 数据源1的分表2 |
Ds1 | User0 | 数据源2的分表1 |
Ds1 | User1 | 数据源2的分表2 |
在shigen之前创建的数据库和数据表用到了类似这样的名字:
demo-ds-0, user_1,发现配置起来老有问题了,直接炸了啊。
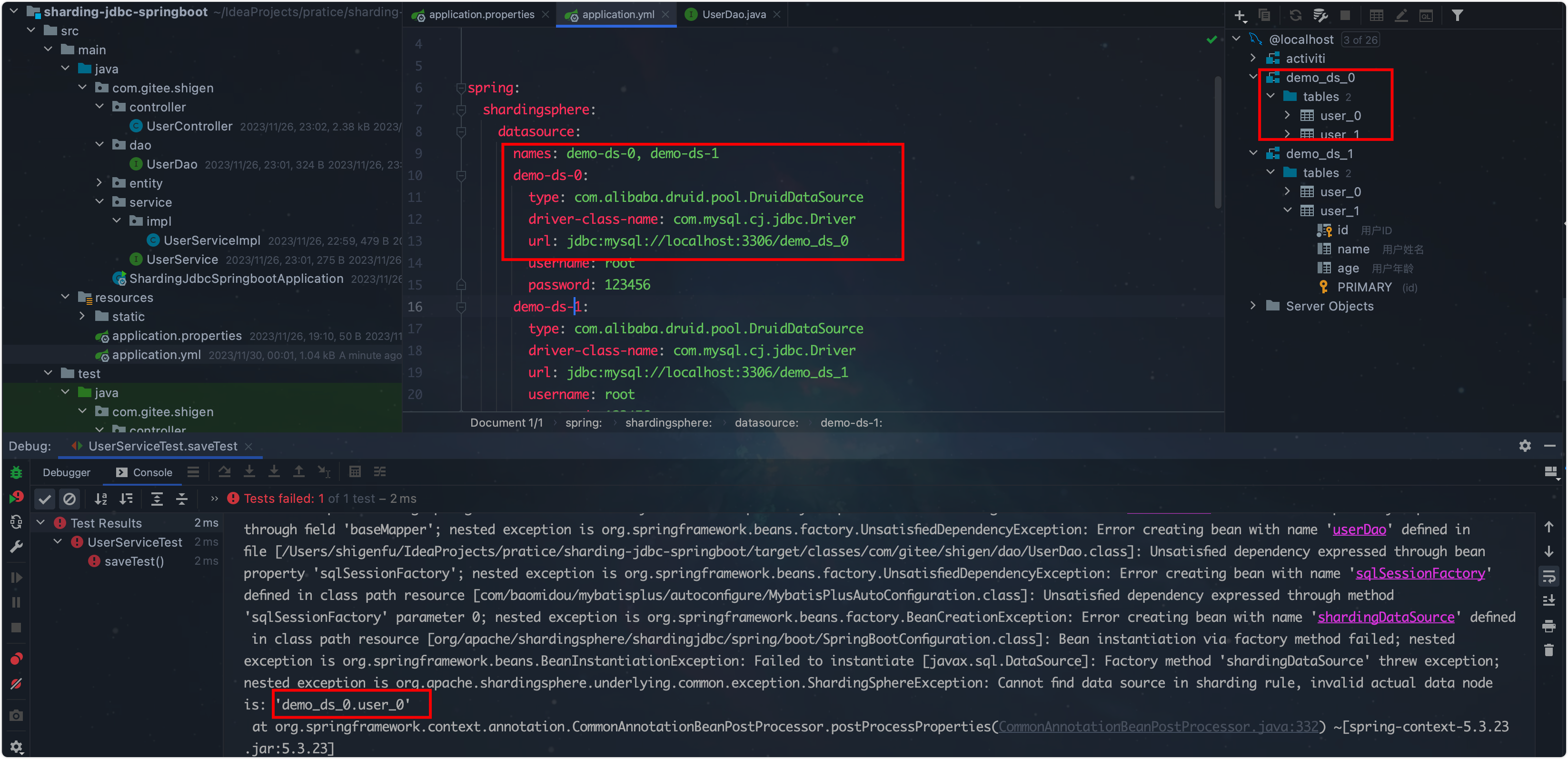
踩坑记录
最后改成不要下划线的才算正常。
在一切准备好之后,我们开始今天的案例。
基于sharding-jdbc实现数据水平切分
引入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>这是最核心的依赖,当然,mysql的驱动、mybatis-plus这里也是需要的。
生成基础代码
我们用魔法生成对应的controller、service、dao。
生成代码
编写配置文件
这里我就直接贴上我的配置了,更多的配置可以参考官网。
spring:
shardingsphere:
datasource:
names: ds0, ds1
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds0
username: root
password: 123456
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ds1
username: root
password: 123456
sharding:
tables:
user:
actual-data-nodes: ds$->{0..1}.user$->{0..1}
table-strategy:
inline:
sharding-column: id
algorithm-expression: user$->{id % 2}
key-generator:
column: id
type: SNOWFLAKE
binding-tables: user
broadcast-tables:
default-database-strategy:
inline:
sharding-column: age
algorithm-expression: ds$->{age % 2}
props:
sql:
show: true
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl其实看起来也很有意思的:
- 采用了druid作为数据库的连接池工具,它自带后台,可以监控我们的sql
- 我们表的拆分根据的是user.id,id是偶数就放在user0,奇放在user1
- 数据库的拆分根据的是user.age,这里的age是偶数,放在ds0,反之放在ds1
- 打印详细的sql执行语句
就这些,其实已经帮我们把复杂的配置简单了。现在,我们写一个测试类测试吧。
测试类测试
@Test
public void saveTest() {
for (int i = 100; i < 120; i++) {
User user = new User().setId(i+10000).setName("shigen-" + i).setAge(RandomUtil.randomInt(5, 100));
userMapper.insert(user);
}
}1-99的我已经测试了。
观察一下运行的结果:
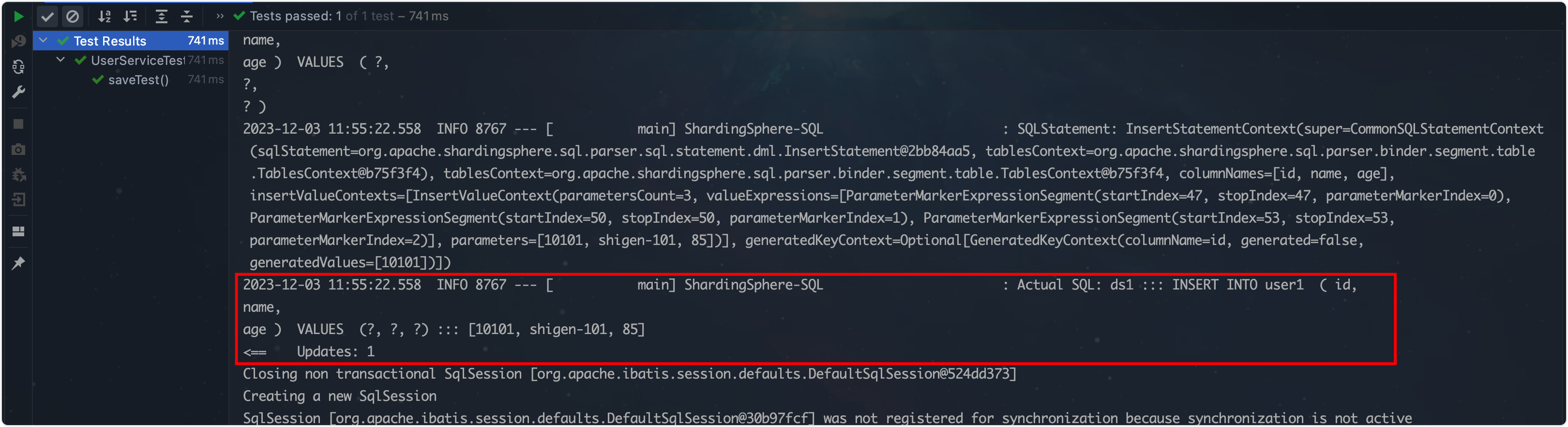
查看到的实际的sql
我们再到数据库看一下:
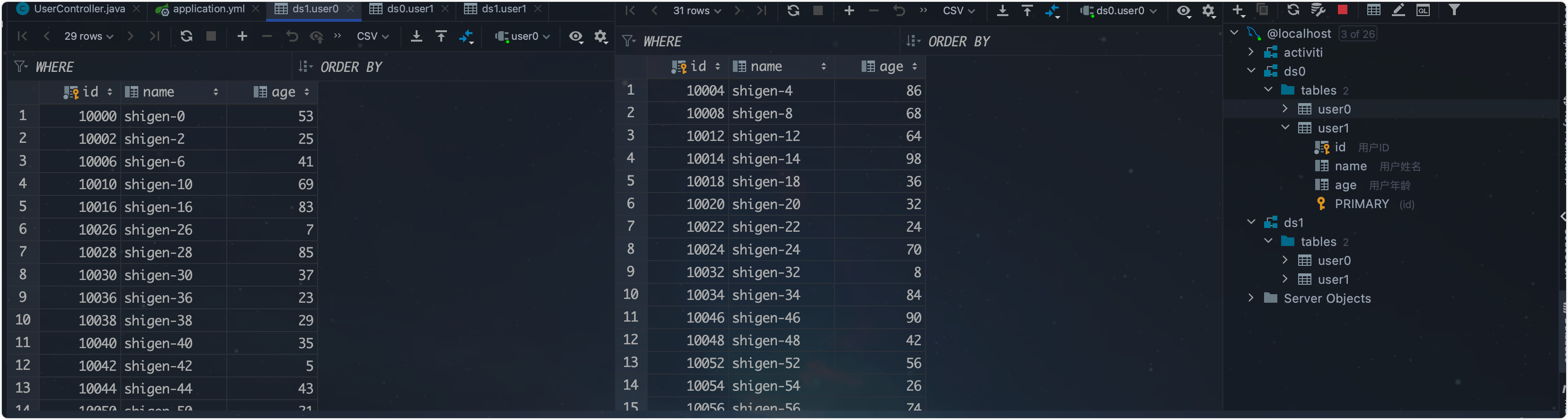
实际的数据
很符合预期啊,年龄为奇数的在ds0,id为偶数的在user0;表明我们的测试顺利。
其实还是那句话,具体场景具体的分析,没有这么大的数据量,分库分表反而是复杂、完全没必要的设计。也希望提供一种技术选型和参考。
当然,sharding-jdbc还支持读写分离,正好shigen之前也有一个文章是关于springboot+mybtais-plus实现读写分离的,那就期待下期的文章吧!
以上就是今天分享的全部内容了,觉得不错的话,记得点赞 在看 关注支持一下哈,您的鼓励和支持将是shigen坚持日更的动力。同时,shigen在多个平台都有文章的同步,也可以同步的浏览和订阅:
平台 | 账号 | 链接 |
|---|---|---|
CSDN | shigen01 | |
知乎 | gen-2019 | |
掘金 | shigen01 | |
腾讯云开发者社区 | shigen | |
微信公众平台 | shigen | 公众号名:shigen |
与shigen一起,每天不一样!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号