Elasticsearch最佳实践:通过调优来节省日志和指标存储成本
原创
Elasticsearch最佳实践:通过调优来节省日志和指标存储成本
原创
点火三周
修改于 2023-10-27 15:04:37
修改于 2023-10-27 15:04:37

当我们使用Elasticsearch时,存储成本一直是需要考虑的重要因素。在上一篇文章《Elasticsearch最佳实践:不同版本之间的存储成本对比》中,我们向大家展示了仅通过升级版本而无需进行任何调优配置,就能获得的提升效果。些数据对比清晰地表明,Elasticsearch的不断更新和优化使得仅仅升级版本就能在存储成本上带来巨大的提升。但这并非我们持续优化道路上的终点,相反,这只是开始。在本文中,我们将详细介绍我们在多个不同版本中引入的新特性,以及它们如何帮助我们持续优化存储成本。让我们一起来看看如何应用这些新特性吧!
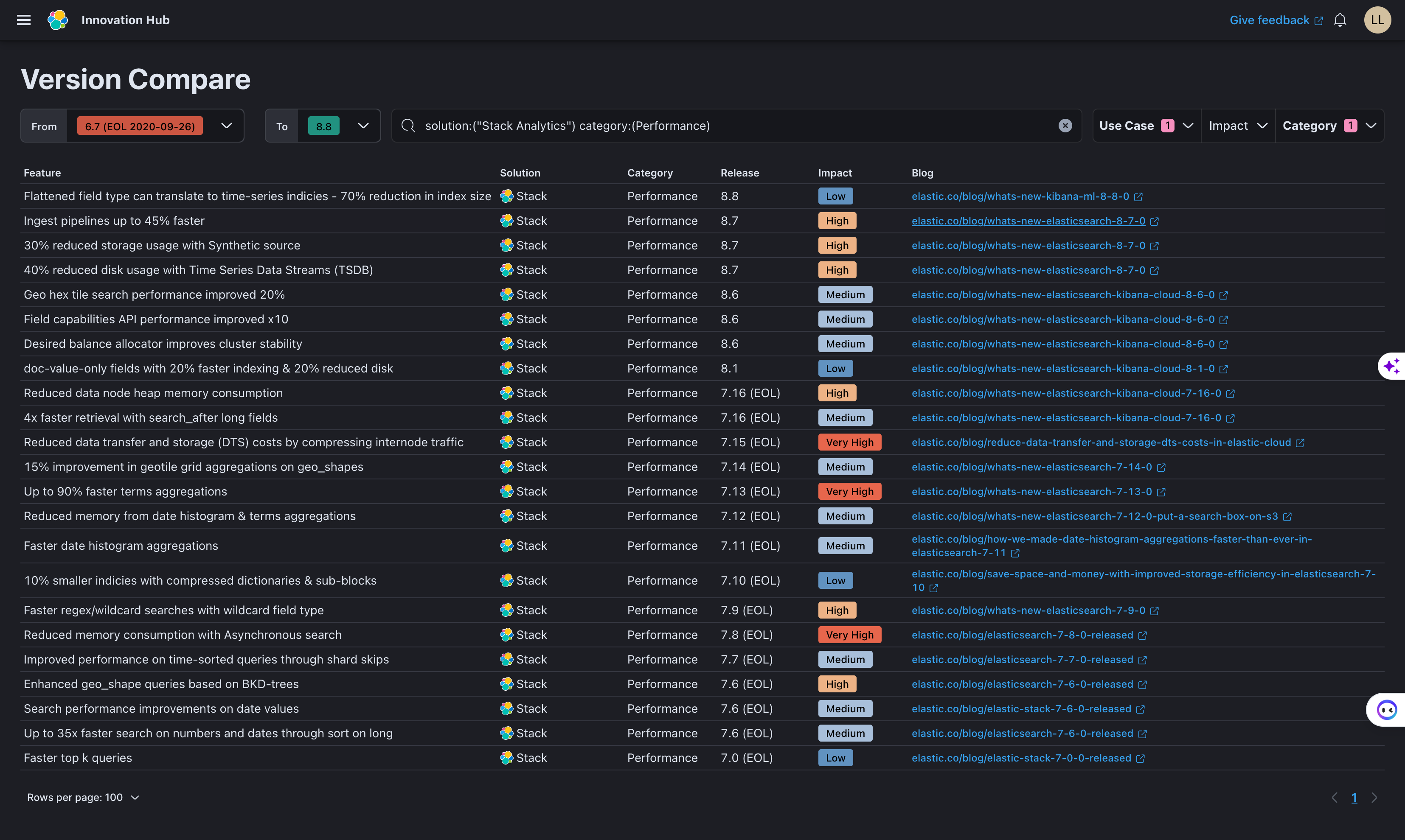
Elasticsearch多版本间的性能更新
测试前置条件
在本文中,我们将对 Elasticsearch 在日志场景和指标场景两个方面进行优化。与上篇文章不同,本文将专注在新特性上,也就是说,我们将只在一个版本上,尽可能的给大家展示对应场景的最佳实践,以及我们能够最大程度上达到的效果。
数据源和版本选择
为了尽可能真实地呈现实际环境中的情况,我们仍将使用由 Apache SkyWalking showcase 生成的日志和指标数据作为我们的数据来源。在选择 Elasticsearch 的版本时,我们将使用腾讯云上提供的最新版本8.8.1。
日志场景成本优化
要对日志场景进行有效的优化,我们特别需要掌握日志数据中每个字段我们是如何使用的以及具体的使用频率(通过 _field_usage_stats API ),以及每个字段的磁盘占用情况(通过 _disk_usage API)才能有针对性的进行优化。
因此,首先我们回顾一下原始的 Skywalking 采集的日志的数据结构,以下是 SkyWalking 日志数据的schema:
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"oap_log_analyzer": {
"type": "standard"
}
}
}
},
"mappings": {
"_source": {
"excludes": [
"tags"
]
},
"properties": {
"content": {
"type": "text",
"copy_to": [
"content_match"
]
},
"content_match": {
"type": "text",
"analyzer": "oap_log_analyzer"
},
"content_type": {
"type": "integer",
"index": false
},
"endpoint_id": {
"type": "keyword"
},
"service_id": {
"type": "keyword"
},
"service_instance_id": {
"type": "keyword"
},
"span_id": {
"type": "integer"
},
"tags": {
"type": "keyword"
},
"tags_raw_data": {
"type": "binary"
},
"time_bucket": {
"type": "long"
},
"timestamp": {
"type": "long"
},
"trace_id": {
"type": "keyword"
},
"trace_segment_id": {
"type": "keyword"
},
"unique_id": {
"type": "keyword"
}
}
}
}- 这个索引有5个分片和0个副本,使用了一个自定义的分析器
oap_log_analyzer。 - 这个索引有15个字段,大致可以分为以下几类:
- 文本类型(text):这些字段用来存储需要分词的字符串,比如
content。这些字段可以用来进行全文检索、模糊匹配等操作。 - 关键词类型(keyword):这些字段用来存储不需要分词的字符串,比如
endpoint_id、service_id等。这些字段可以用来进行精确匹配、排序、聚合等操作。 - 数值类型(integer、long等):这些字段用来存储整数或长整数,比如
content_type、span_id等。这些字段可以用来进行数值比较、范围查询、聚合等操作。 - 二进制类型(binary):这些字段用来存储二进制数据,比如
tags_raw_data。这些字段不会被索引或搜索,只能用于存储或检索。 - 复制类型(copy_to):这些字段用来存储其他字段的值的副本,比如
content_match。这些字段可以用来进行多字段查询。 - 分析器类型(analyzer):这些字段用来指定使用哪种分析器来处理文本,比如
content_match。这些字段可以用不同的分词规则来影响搜索结果。
- 文本类型(text):这些字段用来存储需要分词的字符串,比如
样例为:
{
"_index": "sw_log-20231023",
"_id": "fe620a61abca48b394358015a04a55b8",
"_score": 1,
"_source": {
"trace_id": "9ad5dfed-1def-4ed3-b233-5dce5afa66c8",
"unique_id": "fe620a61abca48b394358015a04a55b8",
"span_id": 0,
"endpoint_id": "c29uZ3M=.1_VW5kZXJ0b3dEaXNwYXRjaA==",
"service_instance_id": "c29uZ3M=.1_Mzg0ZWZlYWE2NzFjNGFhYjg2ZGFmZjA3OWE4YjljYzZAMTcyLjIyLjAuNg==",
"content": """2023-10-23 23:59:49.247 [TID:9ad5dfed-1def-4ed3-b233-5dce5afa66c8] [XNIO-1 task-2] INFO o.a.s.s.s.s.c.SongController -Listing top songs
""",
"trace_segment_id": "7e097591b9b74531a14df130f17087a8.54.16981055892474632",
"content_type": 1,
"tags_raw_data": "Cg0KBWxldmVsEgRJTkZPClAKBmxvZ2dlchJGb3JnLmFwYWNoZS5za3l3YWxraW5nLnNob3djYXNlLnNlcnZpY2VzLnNvbmcuY29udHJvbGxlci5Tb25nQ29udHJvbGxlcgoXCgZ0aHJlYWQSDVhOSU8tMSB0YXNrLTI=",
"service_id": "c29uZ3M=.1",
"time_bucket": 20231023235949,
"timestamp": 1698105589247
}
}要进行索引优化,优先需要保证业务场景不被破坏。因此,每次对索引schema的修改,都需要到业务中去进行验证。
在我们这个场景中,sw_log-* 日志主要用于在 Skywalking的UI上过滤和查询日志。
而从界面上看,我们可以看到 service_id(服务)、endpoint_id(端点)、service_instance_id(实例)、trace_id(追踪)、trace_segment_id、unique_id 主要被用来对日志进行过滤,并且整个界面上没有可以对日志数据进行聚合的地方。content则被用来搜索,另外,主要的存储空间的占用在于tags_raw_data字段。通过分析字段的用途,我们才能做到对下一步的优化操心中有数。
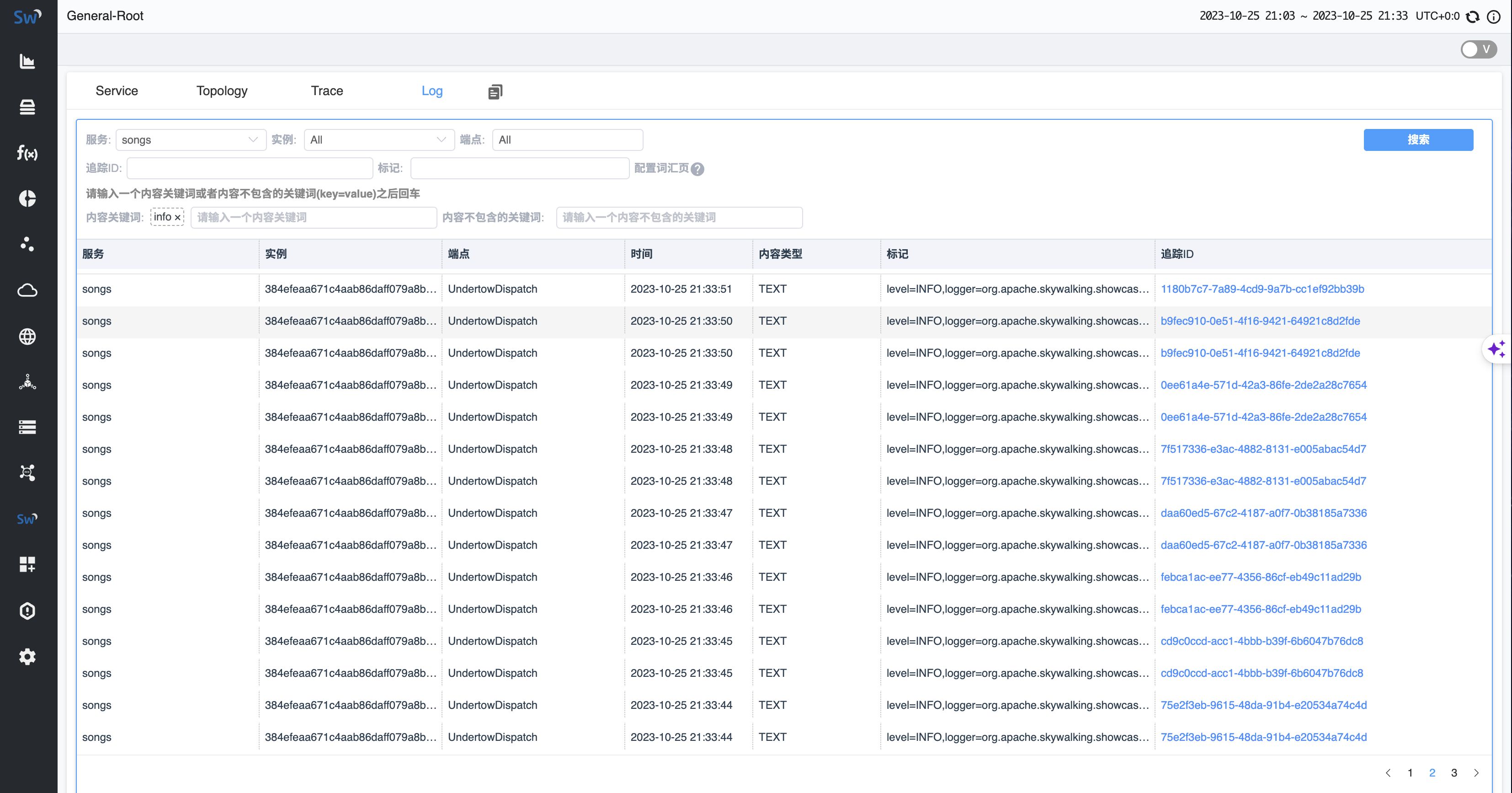
Skywalking的日志查看界面
了解字段使用情况
另外,我们可以通过 _field_usage_stats API 来查看每个字段的具体使用情况。
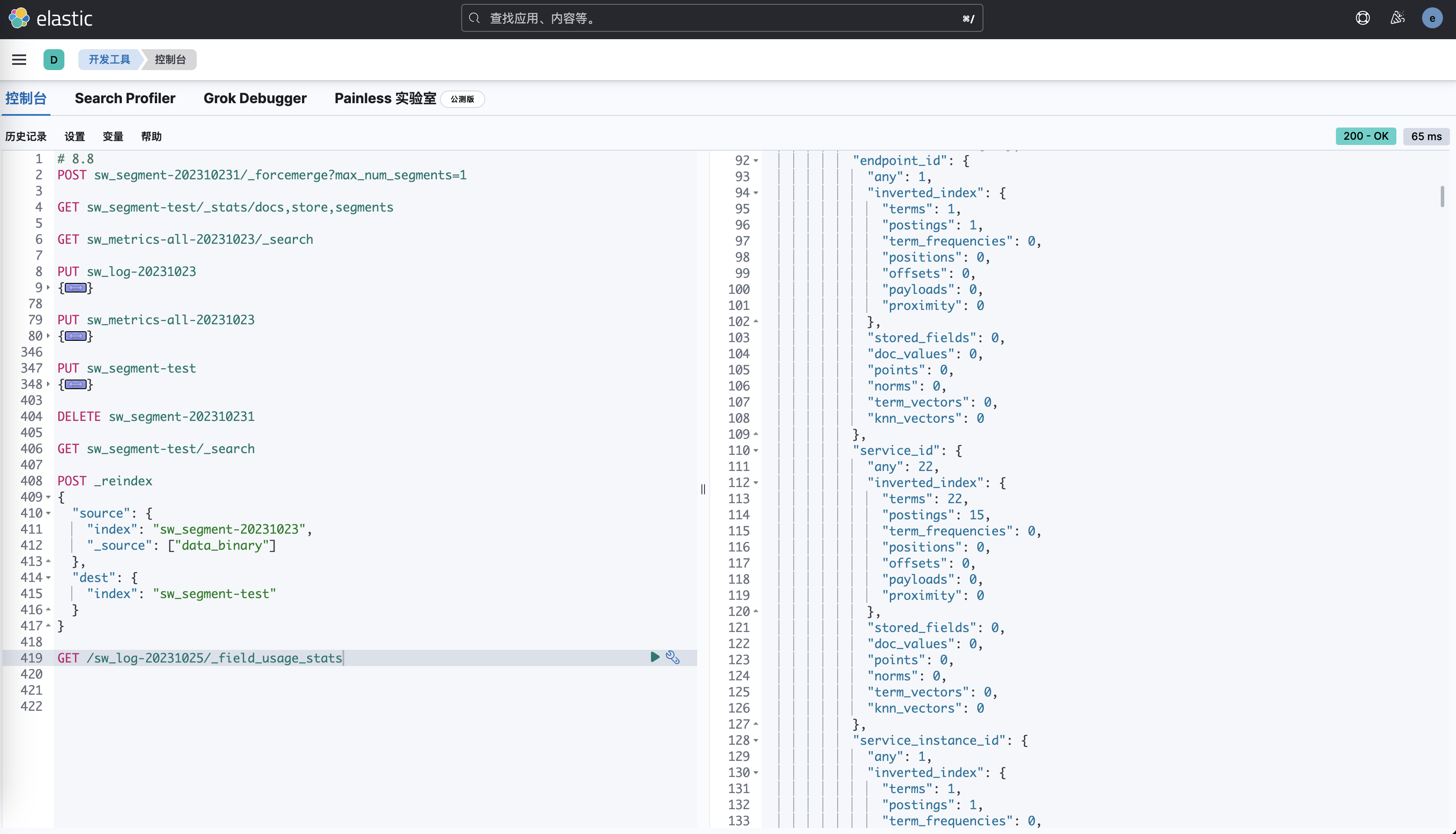
Skywalking日志索引的字段使用情况
样例:
"stats": {
"all_fields": {
"any": 120,
"inverted_index": {
"terms": 35,
"postings": 20,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 16,
"doc_values": 46,
"points": 69,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},
"fields": {
"_id": {
"any": 8,
"inverted_index": {
"terms": 0,
"postings": 0,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 8,
"doc_values": 0,
"points": 0,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},
"_source": {
"any": 8,
"inverted_index": {
"terms": 0,
"postings": 0,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 8,
"doc_values": 0,
"points": 0,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},
"content_match": {
"any": 7,
"inverted_index": {
"terms": 7,
"postings": 2,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 0,
"doc_values": 0,
"points": 0,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},
"endpoint_id": {
"any": 1,
"inverted_index": {
"terms": 1,
"postings": 1,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 0,
"doc_values": 0,
"points": 0,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},
"service_id": {
"any": 23,
"inverted_index": {
"terms": 23,
"postings": 16,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 0,
"doc_values": 0,
"points": 0,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},
"service_instance_id": {
"any": 1,
"inverted_index": {
"terms": 1,
"postings": 1,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 0,
"doc_values": 0,
"points": 0,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},
"time_bucket": {
"any": 23,
"inverted_index": {
"terms": 0,
"postings": 0,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 0,
"doc_values": 23,
"points": 23,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},
"timestamp": {
"any": 46,
"inverted_index": {
"terms": 0,
"postings": 0,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 0,
"doc_values": 23,
"points": 46,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},
"trace_id": {
"any": 3,
"inverted_index": {
"terms": 3,
"postings": 0,
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 0,
"doc_values": 0,
"points": 0,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
}
}
}以上是_field_usage_stats API的返回。以 service_id 为例,我们可以看到该字段的使用情况:
"service_id": {
# 23 该字段一共被使用了23次
"any": 23,
# 23 次均是使用倒排索引,仅索引文档编号。用于验证字词在字段中是否存在。
"inverted_index": {
"terms": 23,
"postings": 16,
# 无相关性打分的使用
"term_frequencies": 0,
"positions": 0,
"offsets": 0,
"payloads": 0,
"proximity": 0
},
"stored_fields": 0,
# 从未对该字段进行聚合、排序等操作
"doc_values": 0,
"points": 0,
"norms": 0,
"term_vectors": 0,
"knn_vectors": 0
},因此可以得到以下判断:
- 需要保留
index: true,因为用到了倒排索引inverted_index,用于验证字词在字段中是否存在。 - 可以配置:
doc_values: false,因为 doc_values 等数据结构则没有调用过
而content_match则只进行了匹配,没有使用相关性打分。可以考虑改成 match_only_text 类型
了解字段的占用
除了了解每个字段的使用情况和使用频率。配合使用_disk_usage API,我们可以大致判断出优化的方向,以及具体优化哪些字段或者类型可以最大化效果:
{
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"sw_log-20231023": {
"store_size": "74.6mb",
"store_size_in_bytes": 78307161,
"all_fields": {
"total": "74.3mb",
"total_in_bytes": 77995159,
"inverted_index": {
"total": "34.2mb",
"total_in_bytes": 35956797
},
"stored_fields": "24.3mb",
"stored_fields_in_bytes": 25585241,
"doc_values": "13.7mb",
"doc_values_in_bytes": 14391804,
"points": "1.6mb",
"points_in_bytes": 1729041,
"norms": "324.4kb",
"norms_in_bytes": 332276,
"term_vectors": "0b",
"term_vectors_in_bytes": 0,
"knn_vectors": "0b",
"knn_vectors_in_bytes": 0
}
...
"content": {
"total": "9.1mb",
"total_in_bytes": 9592092,
"inverted_index": {
"total": "8.9mb",
"total_in_bytes": 9425954
},
"stored_fields": "0b",
"stored_fields_in_bytes": 0,
"doc_values": "0b",
"doc_values_in_bytes": 0,
"points": "0b",
"points_in_bytes": 0,
"norms": "162.2kb",
"norms_in_bytes": 166138,
"term_vectors": "0b",
"term_vectors_in_bytes": 0,
"knn_vectors": "0b",
"knn_vectors_in_bytes": 0
},
"content_match": {
"total": "9.1mb",
"total_in_bytes": 9599222,
"inverted_index": {
"total": "8.9mb",
"total_in_bytes": 9433084
},
"stored_fields": "0b",
"stored_fields_in_bytes": 0,
"doc_values": "0b",
"doc_values_in_bytes": 0,
"points": "0b",
"points_in_bytes": 0,
"norms": "162.2kb",
"norms_in_bytes": 166138,
"term_vectors": "0b",
"term_vectors_in_bytes": 0,
"knn_vectors": "0b",
"knn_vectors_in_bytes": 0
},
...
"trace_segment_id": {
"total": "3.3mb",
"total_in_bytes": 3495441,
"inverted_index": {
"total": "1.3mb",
"total_in_bytes": 1422089
},
"stored_fields": "0b",
"stored_fields_in_bytes": 0,
"doc_values": "1.9mb",
"doc_values_in_bytes": 2073352,
"points": "0b",
"points_in_bytes": 0,
"norms": "0b",
"norms_in_bytes": 0,
"term_vectors": "0b",
"term_vectors_in_bytes": 0,
"knn_vectors": "0b",
"knn_vectors_in_bytes": 0
},
"unique_id": {
"total": "10.4mb",
"total_in_bytes": 10993201,
"inverted_index": {
"total": "5.2mb",
"total_in_bytes": 5527964
},
"stored_fields": "0b",
"stored_fields_in_bytes": 0,
"doc_values": "5.2mb",
"doc_values_in_bytes": 5465237,
"points": "0b",
"points_in_bytes": 0,
"norms": "0b",
"norms_in_bytes": 0,
"term_vectors": "0b",
"term_vectors_in_bytes": 0,
"knn_vectors": "0b",
"knn_vectors_in_bytes": 0
}简单总结一下:
- _source: 31.23% - 23.3mb
- trace_id: 14.26% - 10.6mb
- unique_id: 14.04% - 10.4mb
- content_match: 12.26% - 9.1mb
- content: 12.25% - 9.1mb
- _id: 7.15% - 5.3mb
- trace_segment_id: 4.46% - 3.3mb
- timestamp: 1.63% - 1.2mb
- time_bucket: 1.20% - 914.3kb
- _seq_no: 1.07% - 819.6kb
- service_instance_id: 0.01% - 8.6kb
- endpoint_id: 0.01% - 8.3kb
- service_id: 0.01% - 8kb
- tags: 0.01% - 8kb
- span_id: 0.01% - 4.5kb
- _primary_term: 0.00% - 0b
- _recovery_source: 0.00% - 0b
- _version: 0.00% - 0b
- content_type: 0.00% - 0b
也就是说,我们的优化只需要重点考虑前五个字段。当字段过多的时候,这种分析能够有效的减少我们的分析的符合。
配合上面的_field_usage_stats API 的返回内容,我们可以看到doc_values数据结构没有被使用过,查询不用打分排序,因此,如果我们优化 doc_values (共13.7mb),可以减少15%左右的存储空间。而content和content_match,都是9.1mb,如果都变为match_only_text,可以分别减少30%的存储(从9mb -> 6mb)。
而 unique_id 和 trace_segment_id,几乎在界面上不可见,也无法用来过滤。则可以考虑变为runtime field。几乎可以完全100%节省。
将shcema优化一番,改为如下配置:
"mappings": {
"dynamic": "runtime",
"_source": {
"excludes": [
"tags"
]
},
"properties": {
"content": {
"type": "match_only_text",
"copy_to": [
"content_match"
]
},
"content_match": {
"type": "match_only_text"
},
"content_type": {
"type": "integer"
},
"endpoint_id": {
"type": "keyword",
"doc_values": false
},
"service_id": {
"type": "keyword",
"doc_values": false
},
"service_instance_id": {
"type": "keyword",
"doc_values": false
},
"span_id": {
"type": "integer"
},
"tags": {
"type": "keyword",
"doc_values": false
},
"tags_raw_data": {
"type": "binary",
"store": false
},
"time_bucket": {
"type": "long"
},
"timestamp": {
"type": "long"
},
"trace_id": {
"type": "keyword",
"doc_values": false
}
}
}这里的改造包括:
- 因为没有用到聚合和排序功能,将所有的
keyword类型的字段添加"doc_values":false - 因为没有用到相关性打分功能,将所有的
text字段改为match_only_text - 对于连过滤都没用上,几乎在所有文档中都没有的 trace_segment_id 和 unique_id 字段,则把所有功能关掉,甚至可以将其设置为
runtimefield。
通过以上改造,我们可以看到在保证skywalking仍然能够正常使用所有UI功能的前提下:
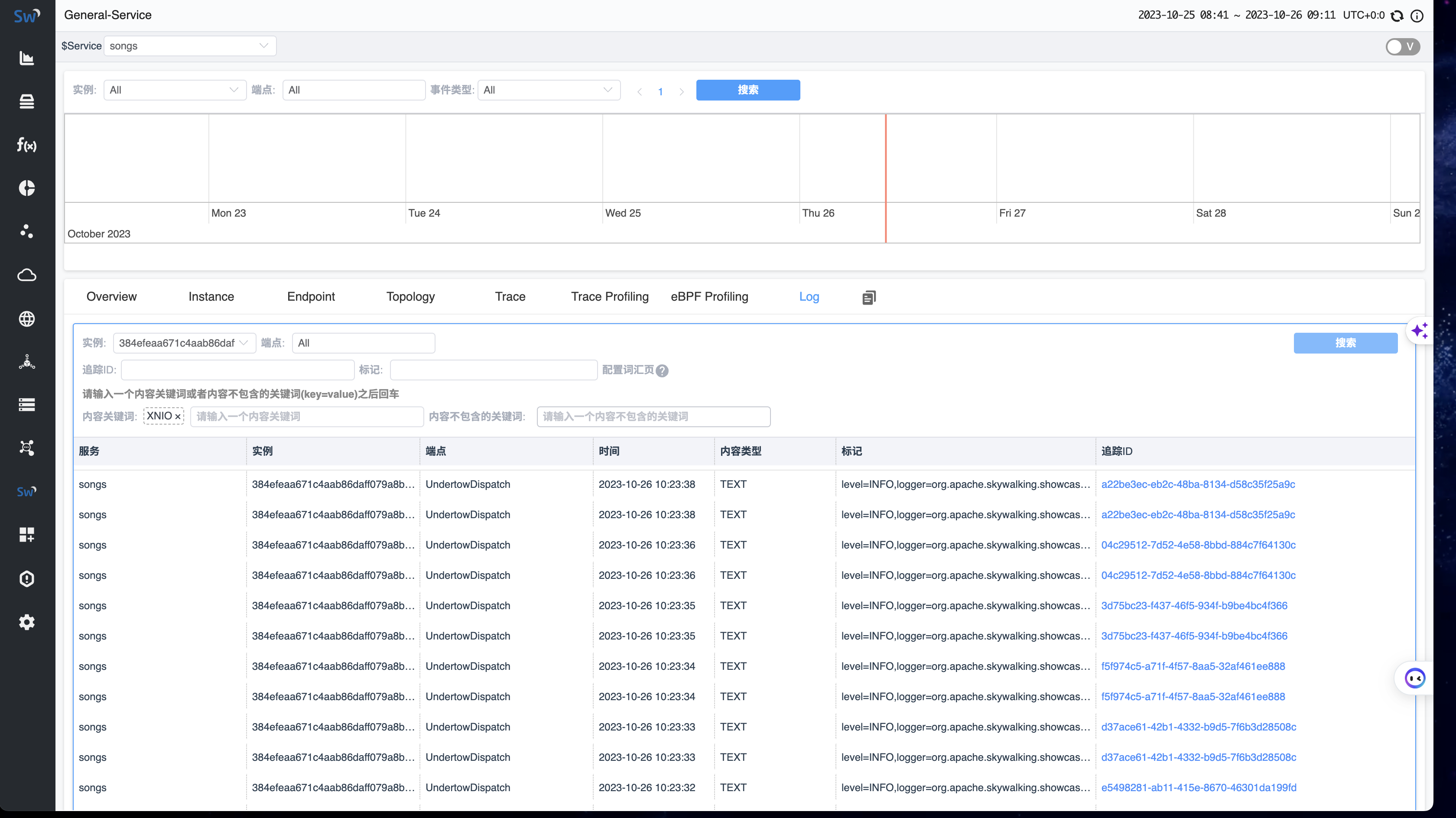
使用改造后的索引,功能一切正常
同样的一个索引,经过改造后,存储空间节省了28.6%:
- inverted_index: 34.2mb - > 22.2mb
- doc_values: 13.7mb -> 1.2mb
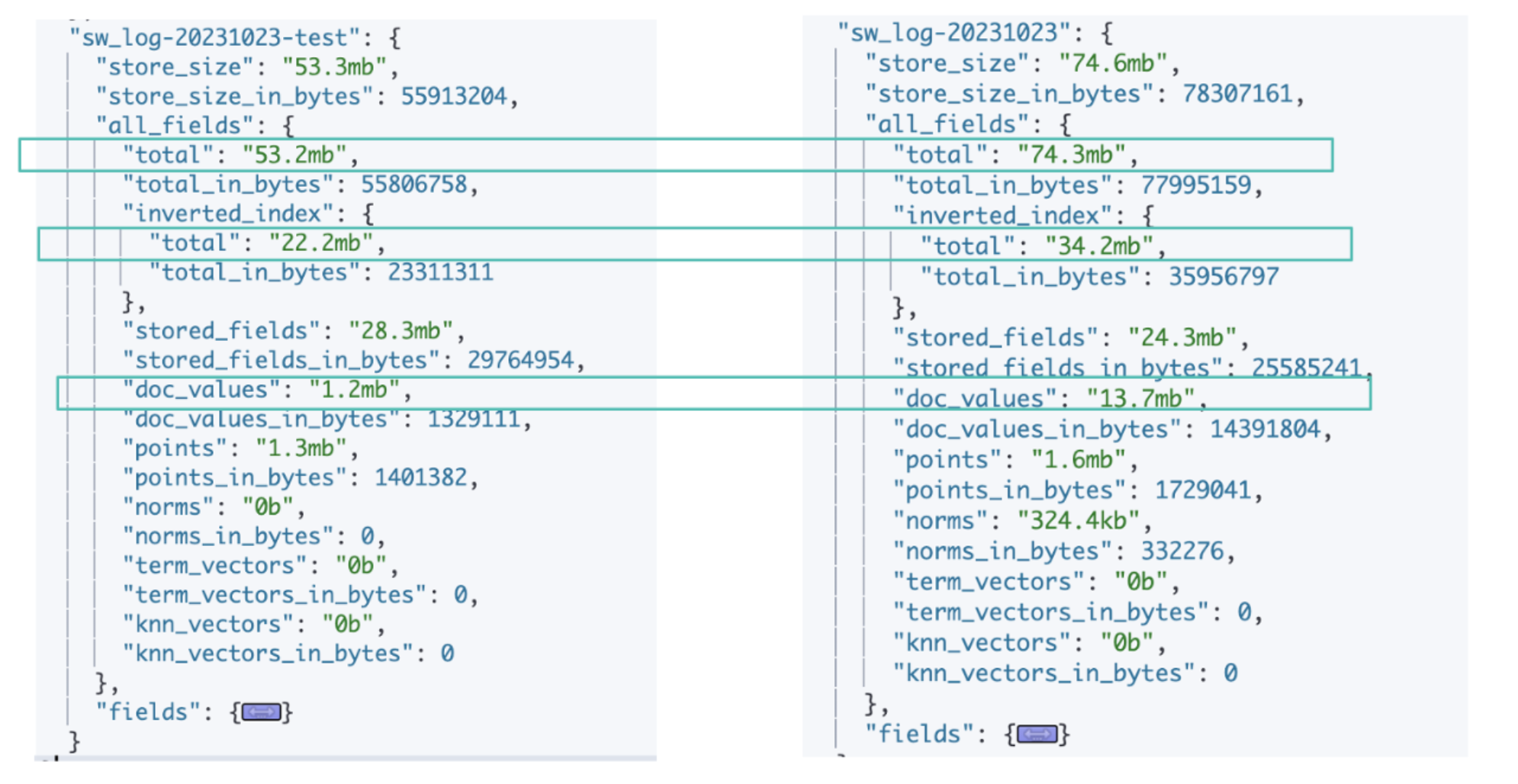
字段优化
需要注意的是,因为每个场景中字段的分布不同,可以优化的空间也不一样的。但像 Skywalking这种数据结构,主要以二进制的方式存储,其实也限制了更深入的优化(二进制的字段限制了synthetic _source,也限制了有效压缩)。所以,对于大多数的日志场景,根据字段的使用频率和方法来进行有针对性的优化,是非常有希望做到30%以上的优化的,这还是在不开任何压缩的情况下。
而如果我们打开压缩,则效果能过达到40%以上。

"index.codec": "best_compression"
指标场景成本优化
而指标数据,则会更加明显,因为我们可以通过 synthetic _source 配置,直接把行存去掉。
以下是 SkyWalking 指标数据的schema:
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 1,
"analysis": {
"analyzer": {
"oap_analyzer": {
"type": "standard"
}
}
}
},
"mappings": {
"properties": {
"address": {
"type": "keyword"
},
"agent_id": {
"type": "keyword"
},
"component_id": {
"type": "integer",
"index": false
},
"component_ids": {
"type": "keyword",
"index": false
},
"count": {
"type": "long",
"index": false
},
"dataset": {
"type": "text",
"index": false
},
"datatable_count": {
"type": "text",
"index": false
},
"datatable_summation": {
"type": "text",
"index": false
},
"datatable_value": {
"type": "text",
"index": false
},
"denominator": {
"type": "long"
},
"dest_endpoint": {
"type": "keyword"
},
"dest_process_id": {
"type": "keyword"
},
"dest_service_id": {
"type": "keyword"
},
"dest_service_instance_id": {
"type": "keyword"
},
"detect_type": {
"type": "integer"
},
"double_summation": {
"type": "double",
"index": false
},
"double_value": {
"type": "double"
},
"ebpf_profiling_schedule_id": {
"type": "keyword"
},
"end_time": {
"type": "long"
},
"endpoint": {
"type": "keyword"
},
"endpoint_traffic_name": {
"type": "keyword",
"copy_to": [
"endpoint_traffic_name_match"
]
},
"endpoint_traffic_name_match": {
"type": "text",
"analyzer": "oap_analyzer"
},
"entity_id": {
"type": "keyword"
},
"instance_id": {
"type": "keyword"
},
"instance_traffic_name": {
"type": "keyword",
"index": false
},
"int_value": {
"type": "integer"
},
"label": {
"type": "keyword"
},
"labels_json": {
"type": "keyword",
"index": false
},
"last_ping": {
"type": "long"
},
"last_update_time_bucket": {
"type": "long"
},
"layer": {
"type": "integer"
},
"match": {
"type": "long",
"index": false
},
"message": {
"type": "keyword"
},
"metric_table": {
"type": "keyword"
},
"name": {
"type": "keyword"
},
"numerator": {
"type": "long"
},
"parameters": {
"type": "keyword",
"index": false
},
"percentage": {
"type": "integer"
},
"precision": {
"type": "integer",
"index": false
},
"process_id": {
"type": "keyword"
},
"profiling_support_status": {
"type": "integer"
},
"properties": {
"type": "text",
"index": false
},
"remote_service_name": {
"type": "keyword"
},
"represent_service_id": {
"type": "keyword"
},
"represent_service_instance_id": {
"type": "keyword"
},
"s_num": {
"type": "long",
"index": false
},
"service": {
"type": "keyword"
},
"service_group": {
"type": "keyword"
},
"service_id": {
"type": "keyword"
},
"service_instance": {
"type": "keyword"
},
"service_instance_id": {
"type": "keyword"
},
"service_name": {
"type": "keyword"
},
"service_traffic_name": {
"type": "keyword",
"copy_to": [
"service_traffic_name_match"
]
},
"service_traffic_name_match": {
"type": "text",
"analyzer": "oap_analyzer"
},
"short_name": {
"type": "keyword"
},
"source_endpoint": {
"type": "keyword"
},
"source_process_id": {
"type": "keyword"
},
"source_service_id": {
"type": "keyword"
},
"source_service_instance_id": {
"type": "keyword"
},
"span_name": {
"type": "keyword"
},
"start_time": {
"type": "long"
},
"summation": {
"type": "long",
"index": false
},
"t_num": {
"type": "long",
"index": false
},
"tag_key": {
"type": "keyword"
},
"tag_type": {
"type": "keyword"
},
"tag_value": {
"type": "keyword"
},
"task_id": {
"type": "keyword"
},
"time_bucket": {
"type": "long"
},
"total": {
"type": "long",
"index": false
},
"total_num": {
"type": "long",
"index": false
},
"type": {
"type": "keyword"
},
"uuid": {
"type": "keyword"
},
"value": {
"type": "long"
}
}
}
}显然,当索引字段超过50个的时候,通过肉眼去观察已经比较困难了。而从样例数据去观察:
{
"_index": "sw_metrics-all-20231023",
"_id": "meter_datasource_202310230003_c29uZ3M=.1_Mzg0ZWZlYWE2NzFjNGFhYjg2ZGFmZjA3OWE4YjljYzZAMTcyLjIyLjAuNg==",
"_score": 1,
"_source": {
"metric_table": "meter_datasource",
"datatable_summation": "8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-minimumIdle,30|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-threadsAwaitingConnection,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-connectionTimeout,90000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleConnections,30|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleTimeout,1800000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-validationTimeout,15000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-activeConnections,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-leakDetectionThreshold,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-maximumPoolSize,30|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-totalConnections,30",
"datatable_value": "8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-minimumIdle,10|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-threadsAwaitingConnection,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-connectionTimeout,30000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleConnections,10|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleTimeout,600000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-validationTimeout,5000|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-activeConnections,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-leakDetectionThreshold,0|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-maximumPoolSize,10|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-totalConnections,10",
"service_id": "c29uZ3M=.1",
"datatable_count": "8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-minimumIdle,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-threadsAwaitingConnection,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-connectionTimeout,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleConnections,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-idleTimeout,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-validationTimeout,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-activeConnections,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-leakDetectionThreshold,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-maximumPoolSize,3|8f4533b8-9761-4c49-b902-f88257c06d05_localhost:-1-totalConnections,3",
"time_bucket": 202310230003,
"entity_id": "c29uZ3M=.1_Mzg0ZWZlYWE2NzFjNGFhYjg2ZGFmZjA3OWE4YjljYzZAMTcyLjIyLjAuNg=="
}
}我们不仅难以理解数据,也很难定位哪些字段可能会包含值或者会频繁使用。
因此,调用 _disk_usage API 和 _field_usage_stats API,从中分析数据成了调优之前必要工作:
_source: store_size: 27.8mb , store_percentage: 36.979777%, usage: 2489930, usage_detail: ('stored_fields', 2489930)_id: store_size: 26.7mb , store_percentage: 35.502739%, usage: 2491026, usage_detail: ('inverted_index', 343232), ('stored_fields', 2489930)time_bucket: store_size: 4.2mb , store_percentage: 5.657617%, usage: 6, usage_detail: ('doc_values', 6), ('points', 6)_seq_no: store_size: 4.2mb , store_percentage: 5.627694%, usage: 0, usage_detail:value: store_size: 2.7mb , store_percentage: 3.600615%, usage: 0, usage_detail:summation: store_size: 2mb , store_percentage: 2.777582%, usage: 0, usage_detail:entity_id: store_size: 1.8mb , store_percentage: 2.487291%, usage: 6, usage_detail: ('doc_values', 6)metric_table: store_size: 1.8mb , store_percentage: 2.400633%, usage: 18625, usage_detail: ('inverted_index', 37251)count: store_size: 449.6kb , store_percentage: 0.583405%, usage: 0, usage_detail:service_id: store_size: 445.8kb , store_percentage: 0.578414%, usage: 85, usage_detail: ('inverted_index', 209)_version: store_size: 408.3kb , store_percentage: 0.529785%, usage: 0, usage_detail:percentage: store_size: 384.7kb , store_percentage: 0.499202%, usage: 0, usage_detail:total: store_size: 356.6kb , store_percentage: 0.462709%, usage: 0, usage_detail:match: store_size: 232kb , store_percentage: 0.301037%, usage: 0, usage_detail:source_service_id: store_size: 199kb , store_percentage: 0.258202%, usage: 6, usage_detail: ('inverted_index', 15)dest_service_id: store_size: 197.9kb , store_percentage: 0.256800%, usage: 6, usage_detail: ('inverted_index', 14)dest_endpoint: store_size: 115.3kb , store_percentage: 0.149610%, usage: 0, usage_detail:precision: store_size: 107.4kb , store_percentage: 0.139355%, usage: 0, usage_detail:source_endpoint: store_size: 101kb , store_percentage: 0.131136%, usage: 0, usage_detail:source_service_instance_id: store_size: 100kb , store_percentage: 0.129858%, usage: 0, usage_detail:dest_service_instance_id: store_size: 99.3kb , store_percentage: 0.128939%, usage: 0, usage_detail:component_id: store_size: 64.6kb , store_percentage: 0.083919%, usage: 0, usage_detail:component_ids: store_size: 64.6kb , store_percentage: 0.083852%, usage: 0, usage_detail:int_value: store_size: 39.5kb , store_percentage: 0.051355%, usage: 0, usage_detail:uuid: store_size: 28.1kb , store_percentage: 0.036489%, usage: 0, usage_detail:numerator: store_size: 26.2kb , store_percentage: 0.034065%, usage: 0, usage_detail:s_num: store_size: 21.6kb , store_percentage: 0.028058%, usage: 0, usage_detail:total_num: store_size: 21.6kb , store_percentage: 0.028058%, usage: 0, usage_detail:denominator: store_size: 21.4kb , store_percentage: 0.027872%, usage: 0, usage_detail:double_value: store_size: 16kb , store_percentage: 0.020834%, usage: 0, usage_detail:t_num: store_size: 14.4kb , store_percentage: 0.018767%, usage: 0, usage_detail:double_summation: store_size: 7.3kb , store_percentage: 0.009496%, usage: 0, usage_detail:end_time: store_size: 4.2kb , store_percentage: 0.005495%, usage: 12, usage_detail: ('doc_values', 12), ('points', 12)start_time: store_size: 4.2kb , store_percentage: 0.005493%, usage: 60, usage_detail: ('doc_values', 30), ('points', 60)layer: store_size: 1.9kb , store_percentage: 0.002502%, usage: 22, usage_detail: ('points', 22)message: store_size: 1.6kb , store_percentage: 0.002143%, usage: 0, usage_detail:name: store_size: 1.5kb , store_percentage: 0.001951%, usage: 0, usage_detail:type: store_size: 1.5kb , store_percentage: 0.001951%, usage: 0, usage_detail:service: store_size: 1.5kb , store_percentage: 0.001946%, usage: 30, usage_detail: ('inverted_index', 42)service_instance: store_size: 1.4kb , store_percentage: 0.001939%, usage: 0, usage_detail:endpoint: store_size: 1.4kb , store_percentage: 0.001937%, usage: 0, usage_detail:tag_value: store_size: 379b , store_percentage: 0.000480%, usage: 0, usage_detail:tag_key: store_size: 313b , store_percentage: 0.000397%, usage: 1, usage_detail: ('doc_values', 1)tag_type: store_size: 188b , store_percentage: 0.000238%, usage: 1, usage_detail: ('inverted_index', 3)_primary_term: store_size: 0b , store_percentage: 0.000000%, usage: 0, usage_detail:_recovery_source: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:__soft_deletes: store_size: 0b , store_percentage: 0.000000%, usage: 0, usage_detail:address: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:agent_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:dataset: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:datatable_count: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:datatable_summation: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:datatable_value: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:dest_process_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:detect_type: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:ebpf_profiling_schedule_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:endpoint_traffic_name: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:endpoint_traffic_name_match: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:instance_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:instance_traffic_name: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:label: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:labels_json: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:last_ping: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:last_update_time_bucket: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:parameters: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:process_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:profiling_support_status: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:properties: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:remote_service_name: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:represent_service_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:represent_service_instance_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:service_group: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:service_instance_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:service_name: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:service_traffic_name: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:service_traffic_name_match: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:short_name: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:source_process_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:span_name: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:task_id: store_size: 0 , store_percentage: 0.000000%, usage: 0, usage_detail:
从上面的数据,我们可以知道:优化的重点应该放在占比最多的_id字段和_source字段,并且,大部分的字段都没有被使用,可将其设置为runtime。
synthetic _source
因此,初步的修改的方案为:
- 通过ingest pipeline删掉原始的
_id字段 - 通过配置
"_source":{"mode":"synthetic"},将_source字段改为从列存中组合提取 - 对于不常使用的字段,设置为
runtime
我们可以通过修改index template来实现以上变化:
POST _index_template/sw_metrics-all
{
"index_patterns": [
"sw_metrics-all-*"
],
"template": {
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
# 删除冗长的_id字段,由ES自动生成
"default_pipeline":"remove_id",
"refresh_interval": "30s",
"analysis": {
"analyzer": {
"oap_analyzer": {
"type": "stop"
}
}
},
"number_of_shards": "1",
"number_of_replicas": "1"
}
},
"mappings": {
# 动态字段均使用 runtime
"dynamic": "runtime",
# 使用合成 _source
"_source": {
"mode": "synthetic"
},
"dynamic_templates": [],
"properties": {
"address": {
"type": "keyword"
},
"agent_id": {
"type": "keyword"
},
...
},
"aliases": {
"sw_metrics-all": {}
}
}
}通过以上的核心改造。我们可以看到,索引大小出现了明显的缩减,整体由75.3mb变为了27.8mb,减少了63.1%:
- stored_field: 41.7mb -> 4.3mb
- inverted_inex: 15.2mb -> 7.7mb

使用所有优化措施
谨慎检查调优可能对业务的影响
但考虑到在 skywalking 的配置中, _id字段是将多个字段的值组合之后的自定义_id字段(如:endpoint_relation_server_side_20231026_VXNlcg==.0-VXNlcg==-YXBw.1-Lw==)。在进行以上改造后,变为elasticsearch自动生成的值(如:33453423abf240deb822a9ffc7049c57),导致应用无法正常工作:
修改_id后无法读值
因此,我们放弃了对_id的改造。即便如此,也仍然节省了40%的存储空间:

仅优化synthetic _source
此时,Skywalking可以正常工作:
仅优化后 _source 仍可正常工作
如果把压缩打开则达到了50%。( 注意:Skywalking中大部分的数据都是base64格式,导致压缩的比率不高)

"index.codec": "best_compression"
总结
至此,我们完成了一次简单的日志成本调优。
在上一篇文章《Elasticsearch最佳实践:不同版本之间的存储成本对比》中,我们向大家展示了仅通过升级版本而无需进行任何调优配置,就能获得的提升效果。而在本文,通过调优我们还能看到巨大的提升。日志场景再减少40%。指标场景最高减少63%。同一份日志数据,对比6.8版本上的91mb,在8.8上经过优化后,减少到43mb。而同一份指标数据,对比6.8版本上的270mb,减少到了80mb。
值得我们关注的调优手段,包括但不限于以下手段:
- dynamtic runtime field
- match_only_text field
- doc_value_only field
- synthetic _source
- 压缩
虽然本文的调优能够带来更多的收益,但相对于上篇文章仅仅需要做的升级操作,通过本文的案例,我们也显然意识到,调优需要更多的专家知识(特别需要掌握_field_usage_stats API 和 _disk_usage API 的使用),也需要对业务更加了解并能谨慎的反复验证修改数据结构可能对应用带来的影响,才能达到最终的降本目的。
但反过来说,这也是因为 Elasticsearch 提供了所需灵活性,我们才能按需定制我们的应用和数据。
最后,如果你对本文的内容有任何疑问或建议,欢迎在评论区留言,我们将尽快回复你。同时,也请继续关注我们这一系列主题的文章。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号