【分享】影刀使用xpath捕获指定的元素


xpath捕获元素比较精准,前面也介绍了xpath的用法
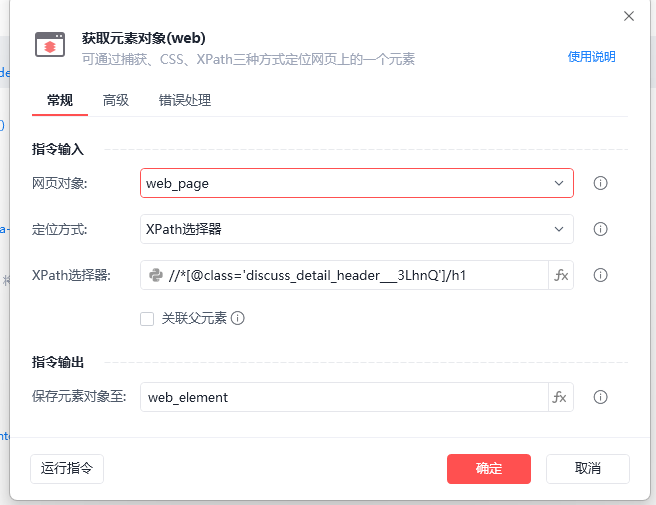
现在捕获社区里帖子详情页的标题
//*[@class='discuss_detail_header___3LhnQ']/h1
找到class是discuss_detail_header___3LhnQ的子元素h1
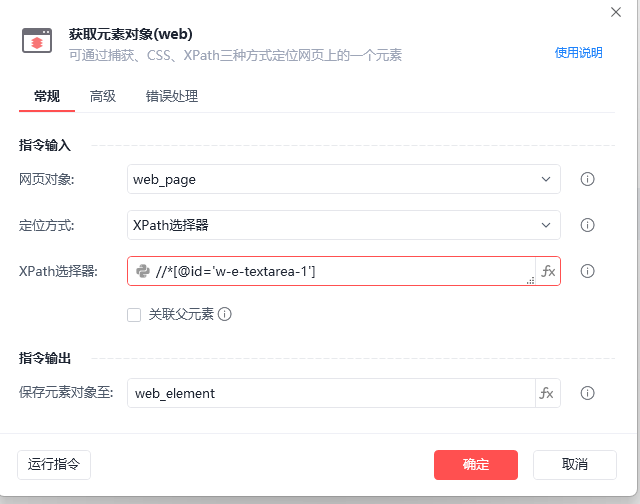
获取文章内容
//*[@id='w-e-textarea-1']
找到id是w-e-textarea-1的元素
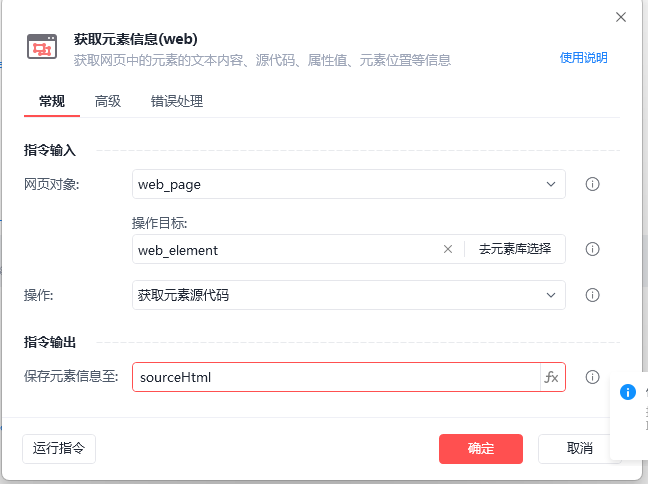
获取元素的源代码,就可以获取到html内容了
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-10-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号