下一代大数据技术架构:Data Fabric?
原创

前言
过去几十年,随着数据量的爆炸性增长和数据处理需求的不断演进,我们目睹了大数据架构的不断发展和变革。在这个过程中,大数据技术和服务的发展取得了令人瞩目的成就,为各行业的业务智能化提供了强大的支持,数据驱动进行决策已成为共识。
最初,大数据架构主要是以批量处理为主,因为当时的数据处理能力和计算资源有限。随着技术(硬件)的进步,流处理和实时计算逐渐成为主流,大数据架构向实时数据处理转变。在这个过程中,出现了许多优秀的开源大数据处理框架和工具,例如Hadoop、Hive、Spark、Kafka、Iceberg、ClickHouse等,这些框架和工具极大地提高了数据处理效率和质量。
到云时代,云计算技术的迅猛发展,大数据架构也开始向云端转移。云计算平台提供了大规模、高可用的数据处理资源,且自研了一些优秀的存储、计算引擎,更好地满足大数据处理的需求。同时用户也可以基于云上资源,选择厂商优化后的EMR组件集合去搭建自己的大数据平台。
近几年,大数据架构的已较为成熟,发展速度也较为缓慢,无需跟着新技术进行狂奔,可以静下心来好好思考到底要什么?每一代大数据架构有他需要去解决核心的问题,那么下一代大数据架构呢?我们可以从两种当今主流架构 Lambda、Kappa 中去寻找一些线索。以下Lambda和Kappa是更广义的描述(Lambada偏离线、异构、多冗余数据副本、流批共存的;Kappa偏实时、架构干净、单副本、流批一体等),大数据行业内的术语本身的定义也不是非常明确,讲清楚就好。
Lambda 架构 (流批混合架构)
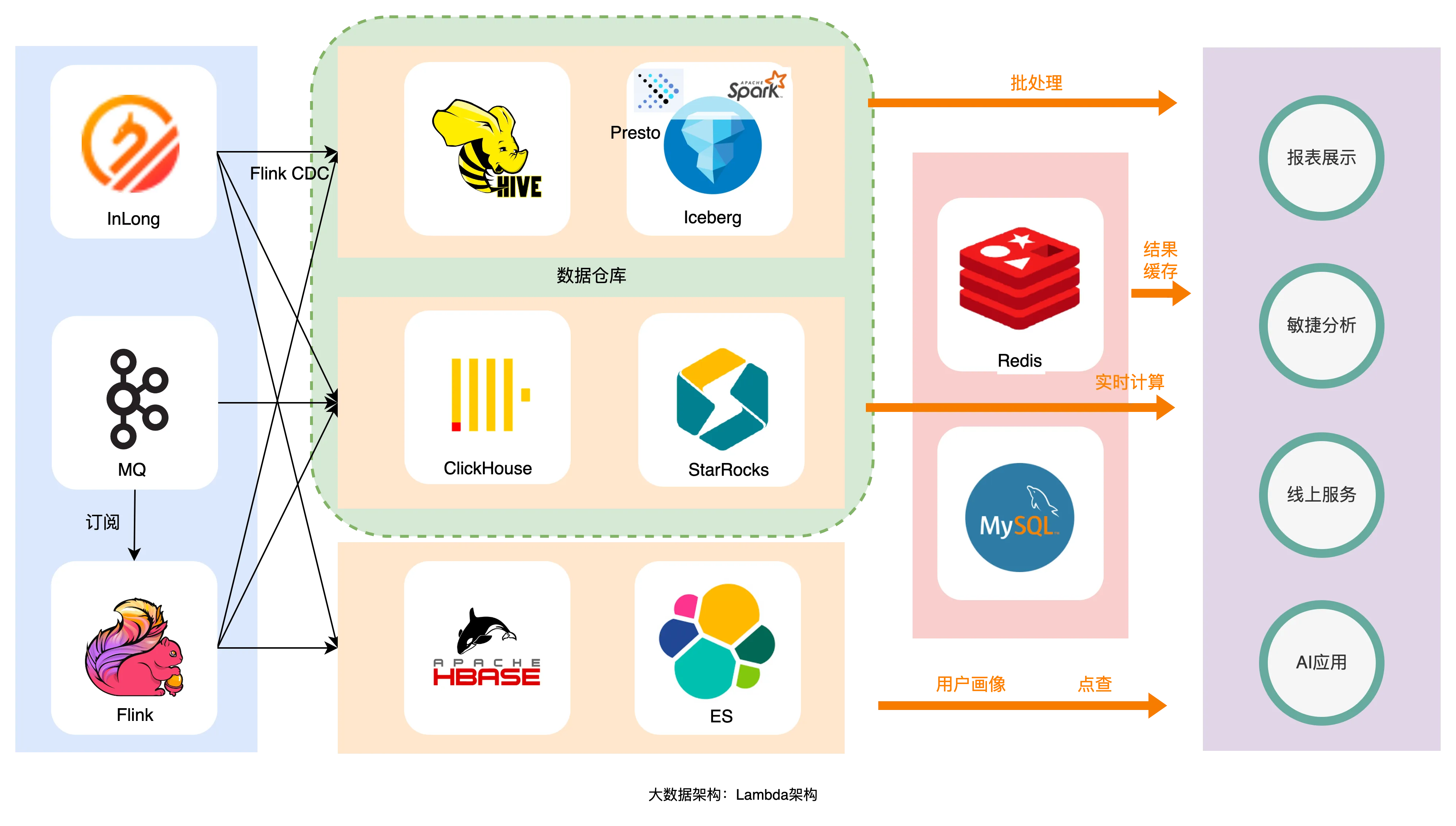
图1 大数据架构:广义Lambda架构
上图描绘了业界常用的Lambda架构,数据被实时写入到StarRocks中,然后又通过 Spark/Flink 批量/实时的写入到Hive,中间可能涉及到数据一致性、冗余数据、多次写入、异构框架维护复杂等问题。
Lambda架构是有其存在的合理性,用专业的框架解决了特定场景的问题,虽然后期要面临复杂性增高,但是前期投入少部分人就可以快速解决“能不能”的问题;其实大部分公司的研发人力也没那么充足,光解决业务问题就已经捉襟见肘,选取开源框架的组合而不是二次开发开源框架或者自研也是无奈;另外就算是上云也很难有一套组件可以解决所有问题,能上云的组件一般也是在某些场景做的比较好、用户比较多,还有一些公司为了不绑死一家云厂商用了多云的方案(上云容易下云难也是一个值得好好讨论的问题)。
Kappa 架构(基于数据湖的流批一体架构)
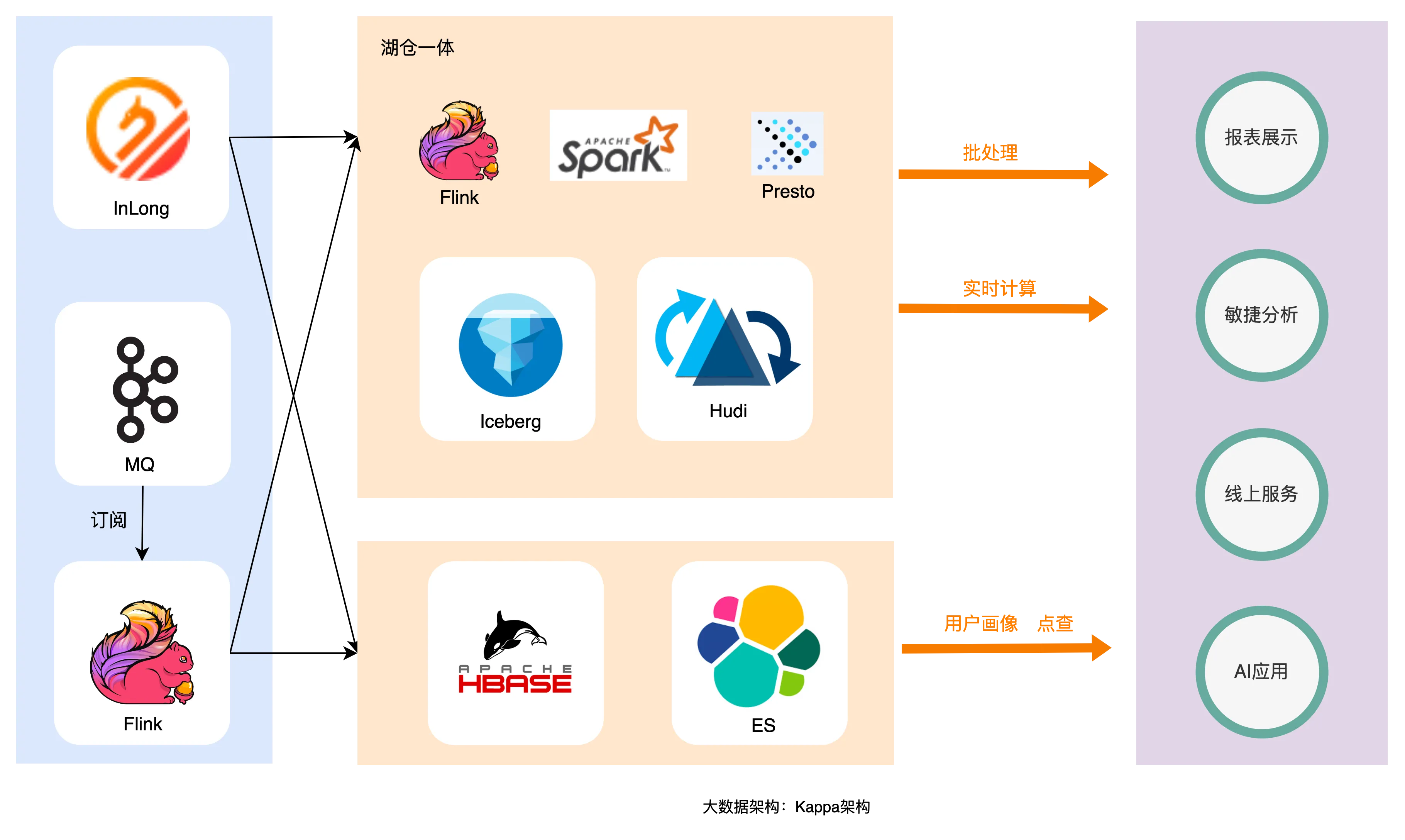
图2 大数据架构:广义的Kappa架构
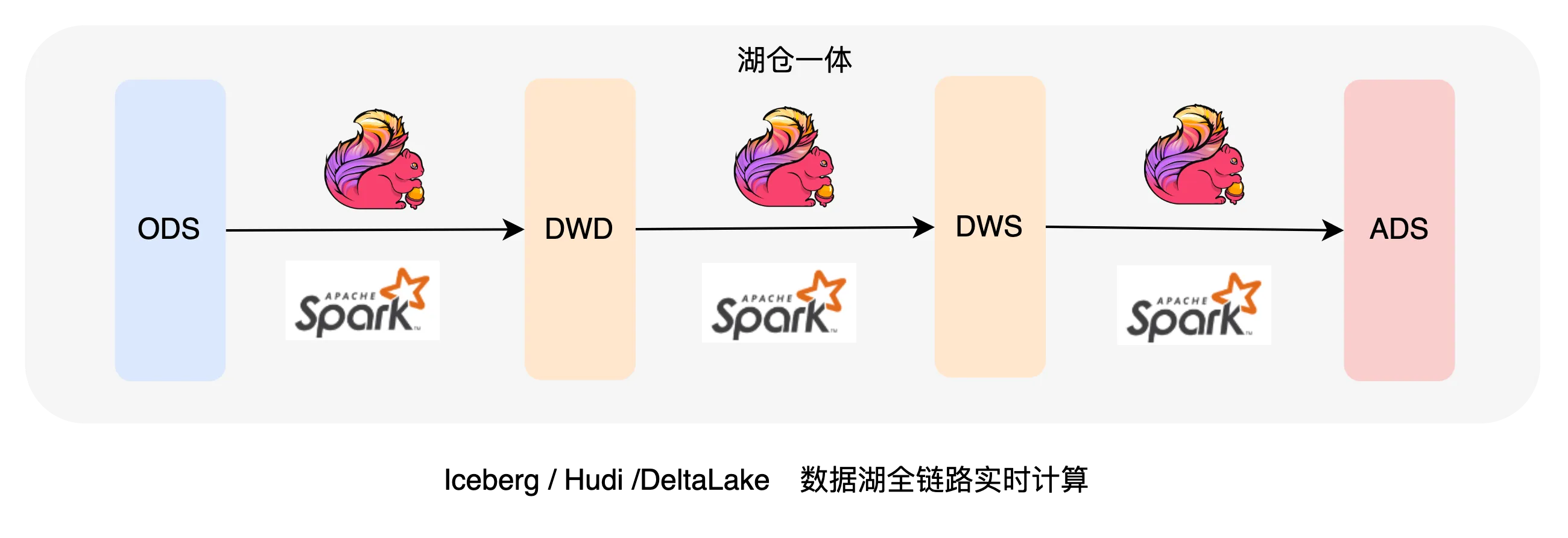
图3 数据湖全链路实时计算
上图描绘了目前业界常用的Kappa架构,数据通过实时链路写入到数据湖,还可以在数据湖中通过Flink完成数据仓库的全链路工作,整个链路中仅存在一份数据且都是实时生成。
为了解决Lambda架构引发的问题,业界希望用一份数据解决数据实时性、一致性、冗余、异构框架维护复杂等问题,虽然基于流批一体的Kappa架构可以解决很大一部分问题,但是靠Flink、Presto的查询响应速度是很难解决高并发、低延时、复杂查询等场景。有些时候为了解决“能不能”的问题还是得引入一些异构的框架变成Lambda架构。
从上述两个主流架构的说明总结三点:
- 用户业务场景比较简单时完全可以基于Kappa架构或者一套EDW完美解决;但是当用户的业务场景比较复杂之后,在现有合理成本的解决方案下,基本上最终都会变成Lambda架构。
- 各个团队在一开始选择大数据架构时也受限于时间成本、未来预期不稳定、知识范围等,不可能花费大量的精力去选取理论上的最优结果;选择之后的迭代也是时刻面临着ROI的考虑(性能更好、架构更优雅的组件就一定要选择吗?够用就行?),所以演化下去肯定会存在较多的问题,例如数据孤岛、数据不一致、维护成本高等。
- 大数据架构许多流程是人参与的、需要和公司内部许多部门合作的、融合其他业务部门之前留下的数据平台业务等,想想历史债都是头大的,想搞一个干净的大数据架构基本不太可能。
从以上描述中,那我们如何去做下一代大数据架构呢?大数据架构是人造的、人用的、发展的,但是由于人的稳定性不如程序、组织的变动、ROI的诉求等,所以用发展的眼光看问题,我们选择拥抱不稳定性、高复杂性。海外这两年提的比较火热的Data Fabric架构也许可以解决上述问题,通过抽象虚拟化层向用户屏蔽底层异构、通过主动元数据进行数据治理、通过联邦查询和数据自动化移动解决数据孤岛问题。
如何理解Data Fabric?
Data Fabric 最早开始流行于2000年代初,主要与内对对象网格关联。随后Forrester开始撰写更通用的解决方案,到2013年成为一个完整的研究类别。2016 年Forrester 在 Forrester Wave 中增加了Big Data Fabric类别,2019年开始入选Gartner各年度的技术趋势,2020年出现在新兴技术成熟度曲线以及数据管理成熟度曲线中(并从创新萌芽期发展到了2021年的过高期望的峰值)[1],甚至Gartner宣称“Data Fabric是数据管理的未来”。
如今,2023年已处于新兴技术成熟度曲线阶段"The Trough of Disillusionment",许多老牌外企和一些新兴外企处于领导者定位;但是在国内则处于新兴技术成熟度曲线阶段"Innovation Trigger",目前有一些创业公司在追逐该风口。
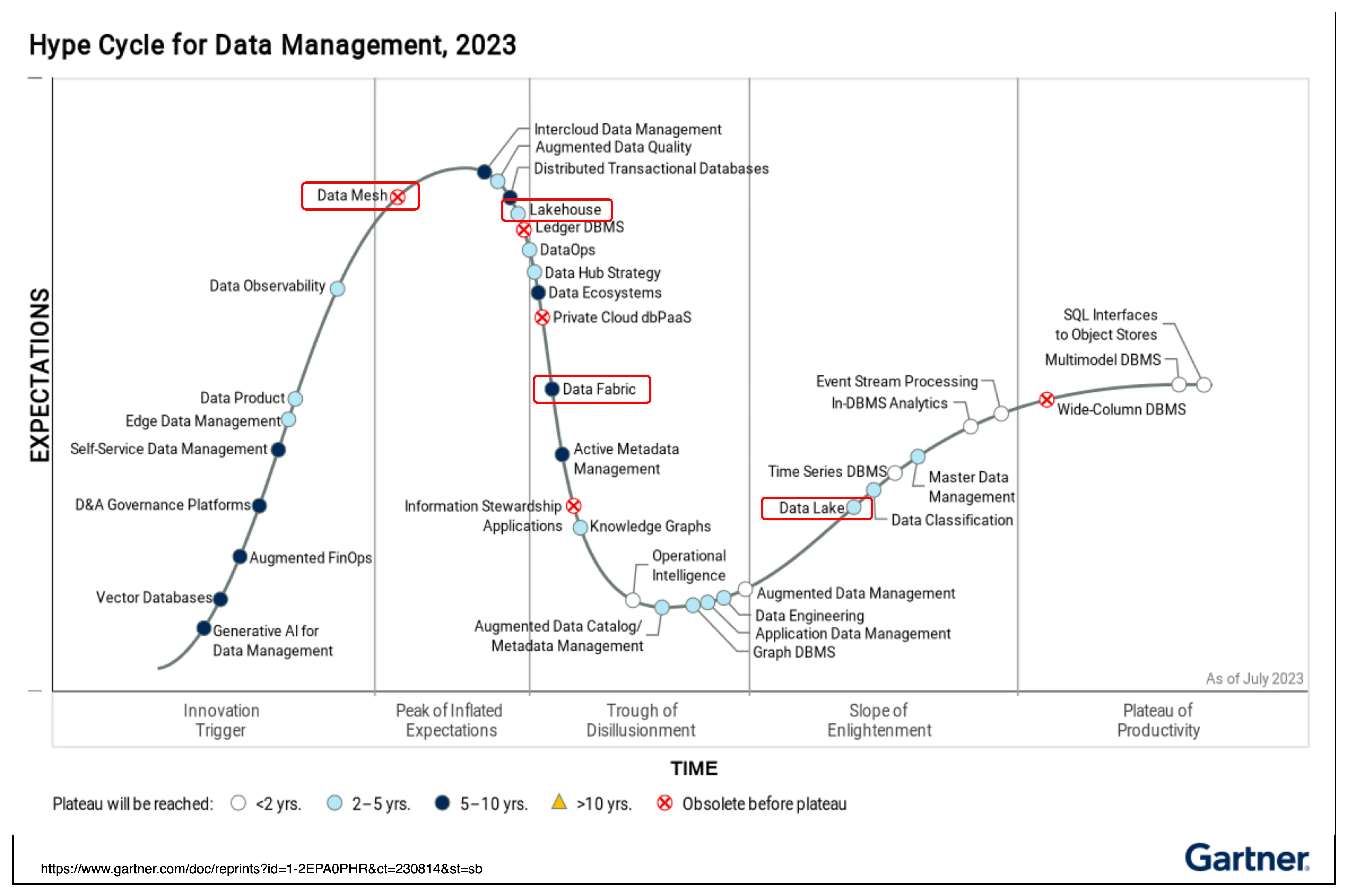
图4 Gartner 数据管理全球技术成熟度曲线
如图,在海外 Data Fabric 的热度已经在下降了,技术大概需要5-10年才到平台期,目前有较多的海外公司入局该赛道。
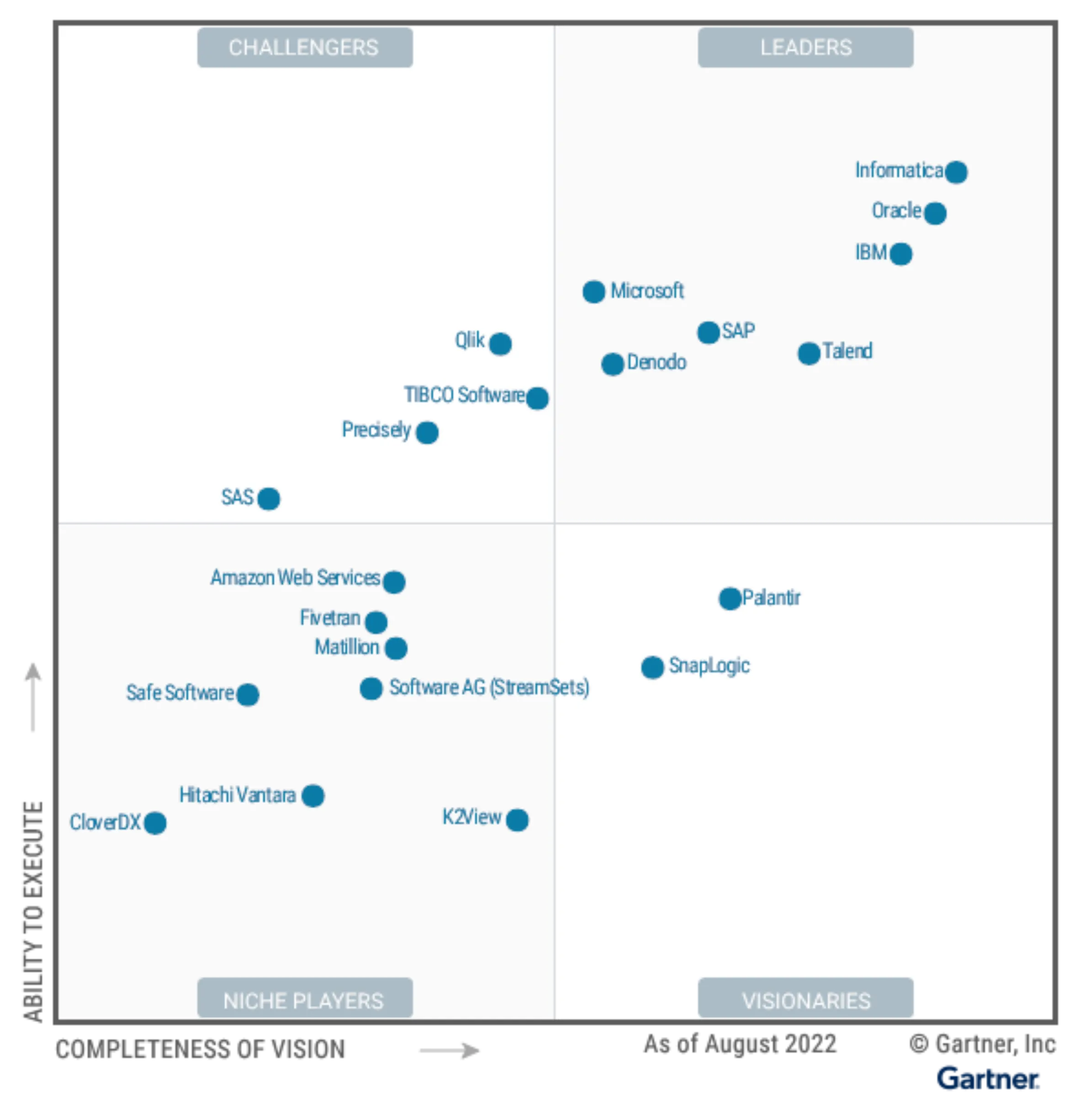
图5 Gartner魔力4象限
如图,Gartner描绘的头部的公司主要是几家知名老外企和几家新兴公司。
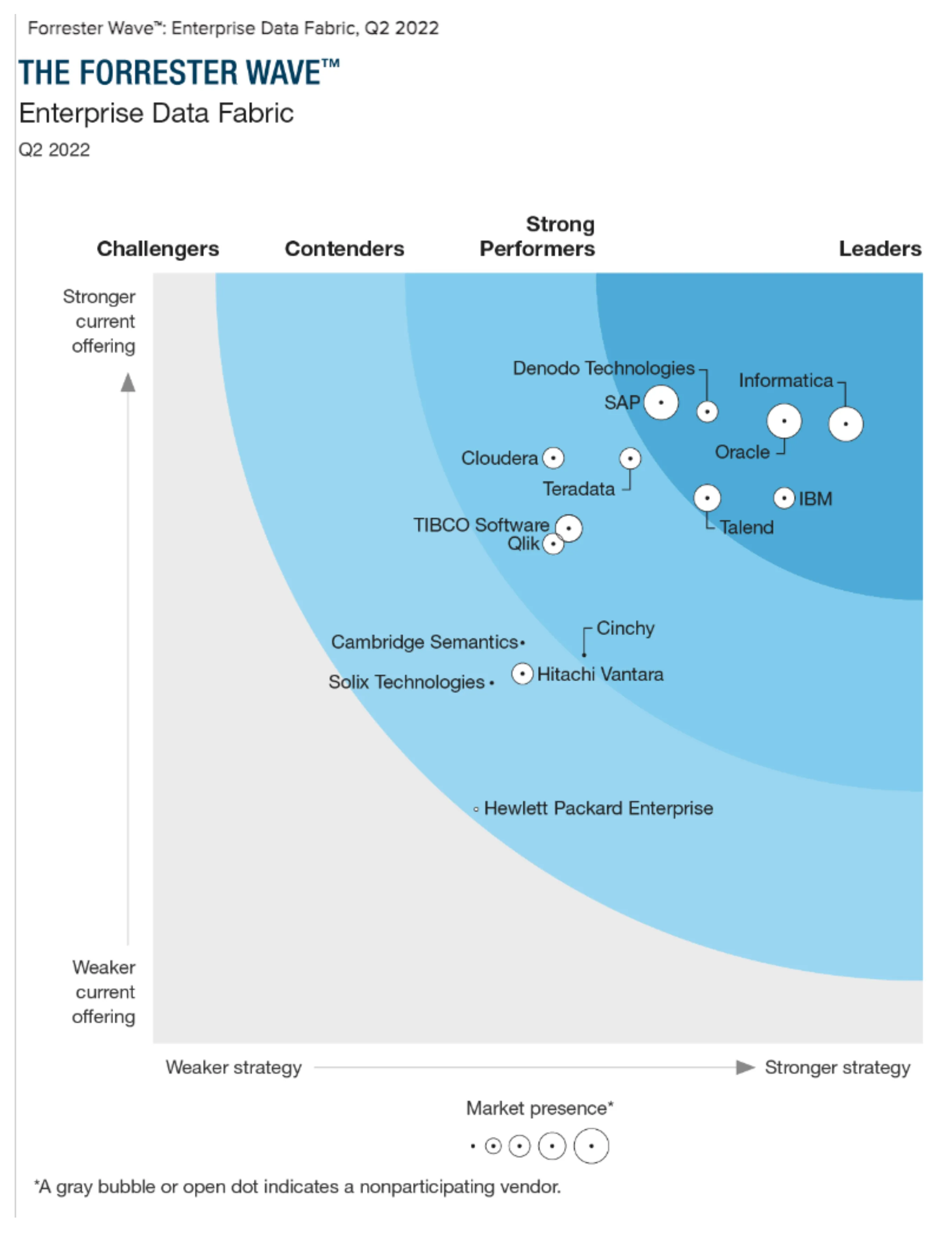
图6 Forrester 魔力4象限
如图,Forrester描绘的头部的公司有几家知名老外企和几家新兴公司,其中 Denodo 目前在国内也有业务,也算做的比较好的。
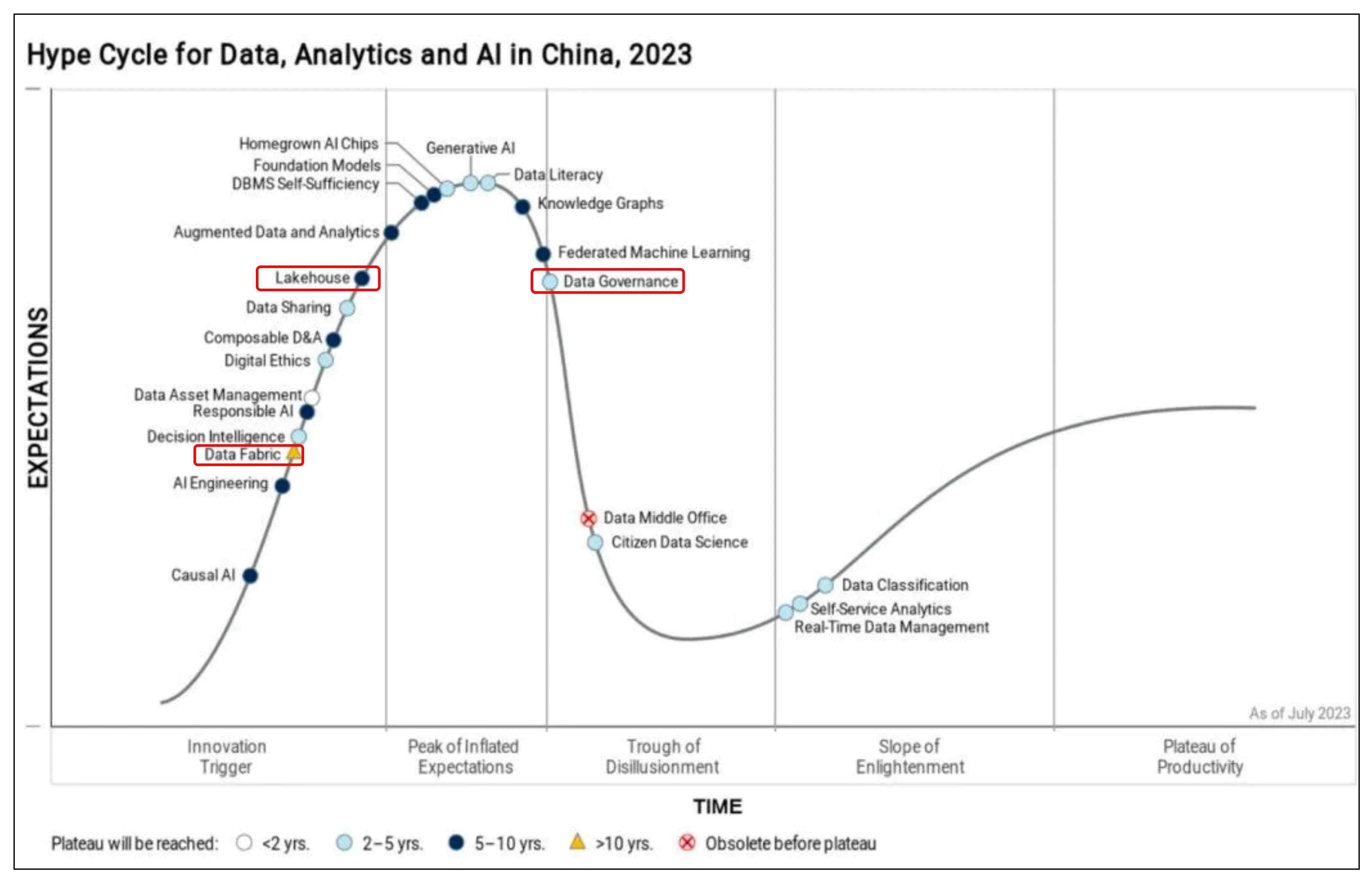
图7 Gartner 数据、数据分析、AI国内技术成熟度曲线
如图,国内目前处于上升期,技术到平台期大概需要10年+,目前国内也有一些创业公司入局。
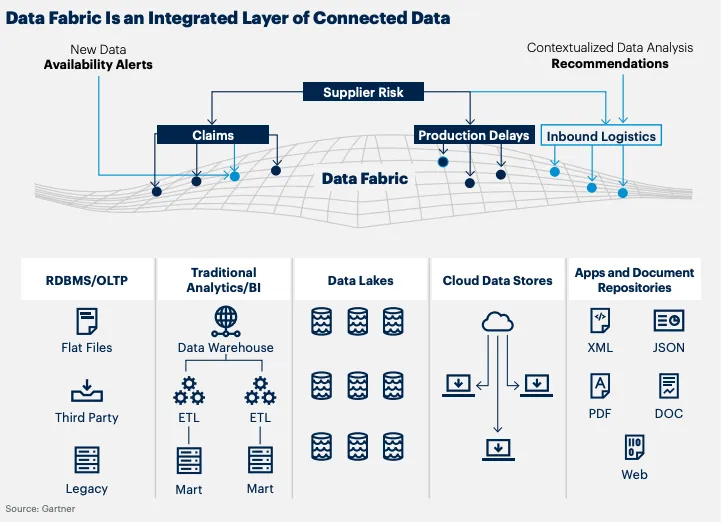
图8 Data Fabric 处于的位置
一般来说,人们普遍认为没有单一的工具能够涵盖Data Fabric的全部范围。它涵盖了许多数据集成和治理的“风格”,以实现一个协调一致的解决方案[2]。Forrester 认 为 DataFabric “是以一种智能和安全的并且是自服务的方式,动态地协调分布式的数据源,跨数据平台地提供集成和可信赖的数据,支持广泛的不同应用的分析和使用场景”, 其专注于对数据集成、转换、准备、策展、安全、治理和编排的自动化,从而实现了快速的数据分析和洞察,帮助业务获得成功[4]。Gartner 将 Data Fabric 定义为:”一种架构模式,可以提供关于数据对象的设计、集成和部署的信息并使上述操作自动化,不受部署平台和架构方法的限制。它利用对所有元数据资产的持续分析和 AI/ML(人工 智能/机器学习),提供有关数据管理以及集成设计和部署模式的可行见解和建议。这将使数据访问和共享更快、 更明智,甚至完全自动化(在特定场景下)”[3]。
Data Fabric 的一些核心理念[3]:
- 所有数据源和全体使用者通用的访问层,能够隐藏部署的复杂性,提供单一的可供使用的逻辑系统。
- 提供多种数据集成策略,能够基于不同应用场景无缝使用,同时满足分析和运行场景需求。
- 附加语义,能够让数据元素(以及数据元素之间的关系和联系)的使用、运行和操作变得更加容易。
- 更广泛的治理、文档和安全功能,能够提高人们对数据的信任和信心。
- 自动化,能够利用主动元数据和AI,显著提升开发、运行和使用此类系统的便捷性。
Aloudata:Data Fabric 实质上是一种数据管理架构思想,其主要目标是打破企业内部的数据孤岛、最大化释放数据价值。其核心理念是通过优化跨源异构数据的发现与访问,将可信数据从所有数据源中以灵活且业务可理解的方式交付给所有相关数据消费者,让数据消费者自助服务和高效协作,实现极致敏捷的数据交付,同时通过主动、智能、持续的数据治理让数据架构持续健康,从而提供比传统数据管理更多的价值[4]。
Denodo:Data Fabric的最终目标是:实现更加敏捷、无缝的数据访问和数据集成,并在许多应用场景中实现自动化。Data Fabric 应具备足够的复杂性以实现高级分析,同时提供一个友好的界面,让业务用户可以与该界面交互。成熟的Data Fabric应该能够同时支持分析和运行场景[3]。
我的理解是:如今的大数据架构复杂性已远超 EDW,我们需要自顶向下设计一套架构解决复杂性引发的问题;为了减少最上层用户的使用成本(体验、效率等),我们需要构建一层虚拟化层将底层的复杂性进行屏蔽,并通过”人工智能“对下层的性能和成本进行充分优化,以达到降本提效的目的。
为什么要Data Fabric,收益何如?

图9 实践 Data Fabric 技术架构方法论的收益
如图,上面的数据来源于知名咨询公司,看上去还是比较美好的,毕竟还要5~10年才到达平台期,还是得具体情况具体分析。
业界大数据架构存在的一些挑战[3]:
- 高级分析和机器学习(AI)实践中的新方法导致数据需求日益复杂化。
- 满足不同数据管理需求的不同专业工具不断发展,成为了组织建立“单一可信来源”的障碍。这些新工具包括 EDW、数据集市、关系数据库 (RDBMS)、数据湖、NoSQL 系统、内部和外部 REST API、实时数据源(包括社 交媒体源)等等。
- 多个角色需要访问数据: 商业智能 (BI) 分析师、大众集成者、数据科学家、数据专员、IT 及数据安全专 业人员,每个人都有不同的技能和需求。
- 向云端(或多个云平台)过渡时,混合生态系统应运而生。在此生态系统中,数据在物理上变得碎片化。IT 需 要灵活地适应新架构,同时尽可能减少中断以支持业务。
- 组织必须在合规性和治理方面实行更高标准,以满足特定的法律框架(GDPR、CCPA)并应对外部威胁。
- 保护和治理混合生态系统可能很复杂且容易出错。
面对上述挑战,Data Fabric 如何去解决的呢?
- 数据需求的复杂性日益增长,那么就得尽量屏蔽掉这些复杂性,让上层通过较为易用的方式使用,例如UI、SQL等。
- 将数据集成、ETL/ELT、数据加热/降冷、跨源查询等通过自动化的方式完成,提供统一的元数据服务,让用户在一个入口上有全局视角。
- 统一权限管理,优化使用流程,按角色提供合理的操作流程。
- 通过虚拟化技术,融合多云/多部门的技术产品,在最上层提供统一的入口。
- 统一全链路的数据治理、数据安全、数据地图、数据字典、数据审计等。
- 通过虚拟化技术,提供唯一的标准,对于最上层的用户友好不容易出错。
采用Data Fabric的方法来管理数据最显著的一些优势是[3]:
- 更好的数据发现和自助服务: 通过整合集成数据目录(可提供简单而强大的工具来探索跨系统的数据)和语 义的高级用法(可给出数据的含义和上下文),逻辑数据编织使自助服务成为了更精简、更可信的活动。
- 更灵活: IT人员在管理数据方面拥有多种触手可及的方法和系统。他们只需单击几下,就可以整合新的数据 集并为其提供保护,还可以从单一的集成设计工作室,并有多种集成技术(虚拟化联合、完整复制到另一个系统、ELT 等)可供选择。
- 高度分布式数据环境中经改良的查询性能:智能查询加速和高级缓存选项等高级技术,以及支持扩展的架构,可以确保即便在苛刻的场景中,也能提供良好性能。
- 全面自动化: 主动元数据与基于AI的建议相结合,简化了平台的使用和操作。
- 集中式安全和治理: Data Fabric 提供了一个全局访问层,无论每个单独来源的功能如何,都可以通过该层在整个组织内强化安全和治理。
因为具体的业务诉求,Data Fabric 的概念已经外延了很多,和最初提出来的定义可能也有差别;例如最初的时候基本都是通过联邦查询(NoETL)来进行统一查询,但是性能是比较差的,所以后续就支持通过数据加热和ETL的方式进行加速查询。所以我们只需要面向解决问题出发就好,无需太在意具体方法论的局限,也可以往上舔砖加瓦。
Data Fabric 通过融合现今已存在的许多大数据技术能力去解决用户的问题,虽然看上去没啥新东西,但是作为一个架构方法论去指导公司内的大数据架构演进还是一个不错的选择;就像很多公司没有根据维度建模理论去建设数据仓库,但是在实际过程中为了解决问题,也会朝着类似的架构演进,最后看似功能都有但是不成体系,会引发较多的问题;例如很多架构实践中会出现许多因为人的问题,如果不进行提前约束,后续的历史债就会非常重。
如何朝着 Data Fabric 架构进行演进呢?
上述我们讲了很多概念、问题和方法,接下来直接参考业界头部的产品的实践。
Denodo [3]
Denodo 是 Data Fabric 领域的领导者,它总部位于Palo Alto, California。它提供本地部署和公共云(AWS、Azure、GCP)上的Denodo平台。它的业务遍布全球,主要客户超过1000家,主要在金融服务、制造业和技术行业。
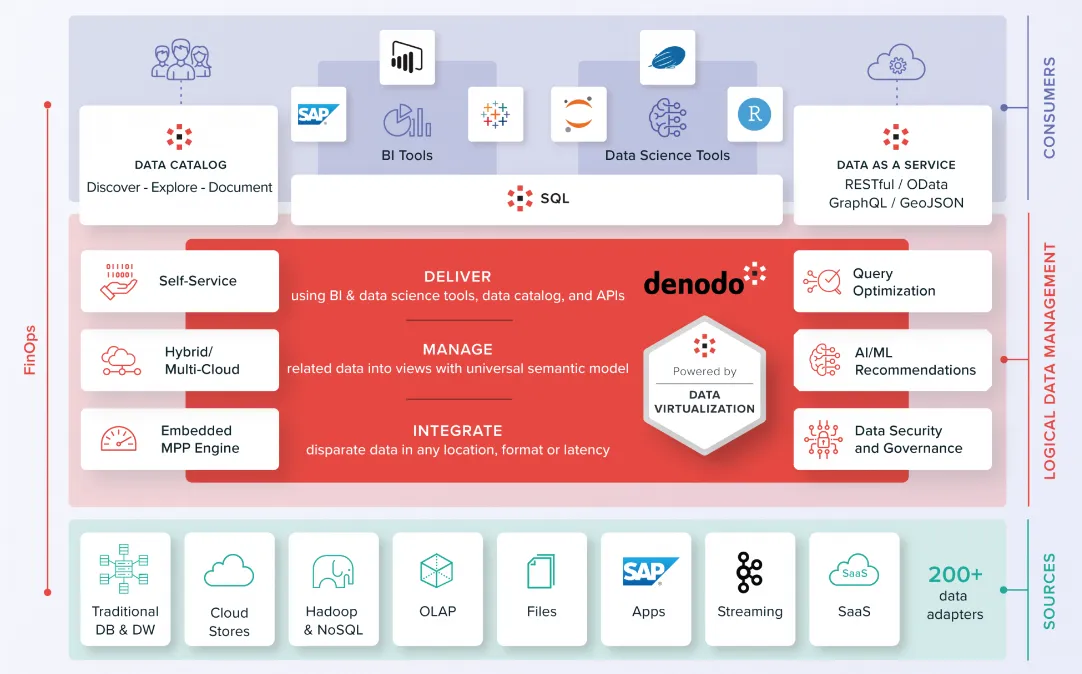
图10 Denodo Data Fabric 技术架构具体实现
如上图,Denodo 的架构图,上层用户基于统一元数据Data Catalog通过UI工具或者SQL访问虚拟化层,数据虚拟化的核心层提取底层多数据源,可集中进行访问和数据集成,并确保数据安全。主动元数据、AI 引擎、数据目录等功能扩展了数据虚拟化的功能,进而奠定了数据编织策略的基础。
优势:
- 专注于分布式数据架构:Denodo从不同的数据源开始虚拟化,并通过数据科学工具(Jupyter,R语言等)扩展其功能。它可以将缓存层写入持久存储。通过构建商业友好的语义模型,它适用于逻辑数据仓库和Data Fabric的使用案例。
- 复杂的优化器:Denodo使用统计数据评估(CBO)查询模式的当前操作,然后使用基于机器学习的DataOps来提高性能,以实现更快的响应和更小的资源分配占用,达到降本提效的目的。
- “先试用后购买”的参与模式:Denodo的客户对其售前支持和概念验证活动是比较赞赏的。大约80%的付费客户在销售周期的某个阶段尝试过Denodo Express(其免费产品,对于单个用户具有标准功能,但容量有限)。其定价模型基于客户需求驱动的核心数量,从小型部门到企业级部署不等。
不足:
- 对传统批量工作负载的支持有限:Denodo在当前的数据集成产品中不支持变更数据捕获。因此,鉴于其专注于联邦和分布式查询处理,它不适用于传统的批量相关的抽取、转换和加载(ETL)操作,不过为了优化性能还是在后续的版本上做了。
- 多地点部署需要手动配置:Denodo支持混合和云间数据集成使用案例。然而,跨不同地理位置运行的Denodo实例之间的连接涉及大量的手动配置(特别是在Denodo 7.x版本中)和持续的运营支持,以确保多地点部署的有效性。Denodo声称在最新版本(8.x)中解决了这个问题,但需要客户升级。
- 数据安全配置可能具有挑战性:Denodo从业人员报告了在安全认证配置过程中的挑战,以及在云环境中建立SSL连接和频繁超时的问题。一些客户抱怨平台准备就绪的延迟,因为一些配置设置在通过脚本进行时难以管理,而不是使用Denodo UI。
Informatica [5]
Informatica 也是 Data Fabric 领域的领导者,总部位于Redwood City, California。它提供了几种本地数据集成产品,包括PowerCenter、PowerExchange、Data Engineering Integration、Enterprise Data Preparation和Data Engineering Streaming。作为其智能数据管理云(IDMC)平台的一部分,它还提供了各种数据集成服务,包括Cloud Data Integration、Cloud Data Integration Elastic、Cloud Mass Ingestion、Cloud Integration Hub和Cloud B2B Gateway。Informatica在这些产品线上拥有超过5700个客户。它的业务地域多样化,其客户分布在多个行业,其中金融服务、医疗保健和公共部门是主要领域。
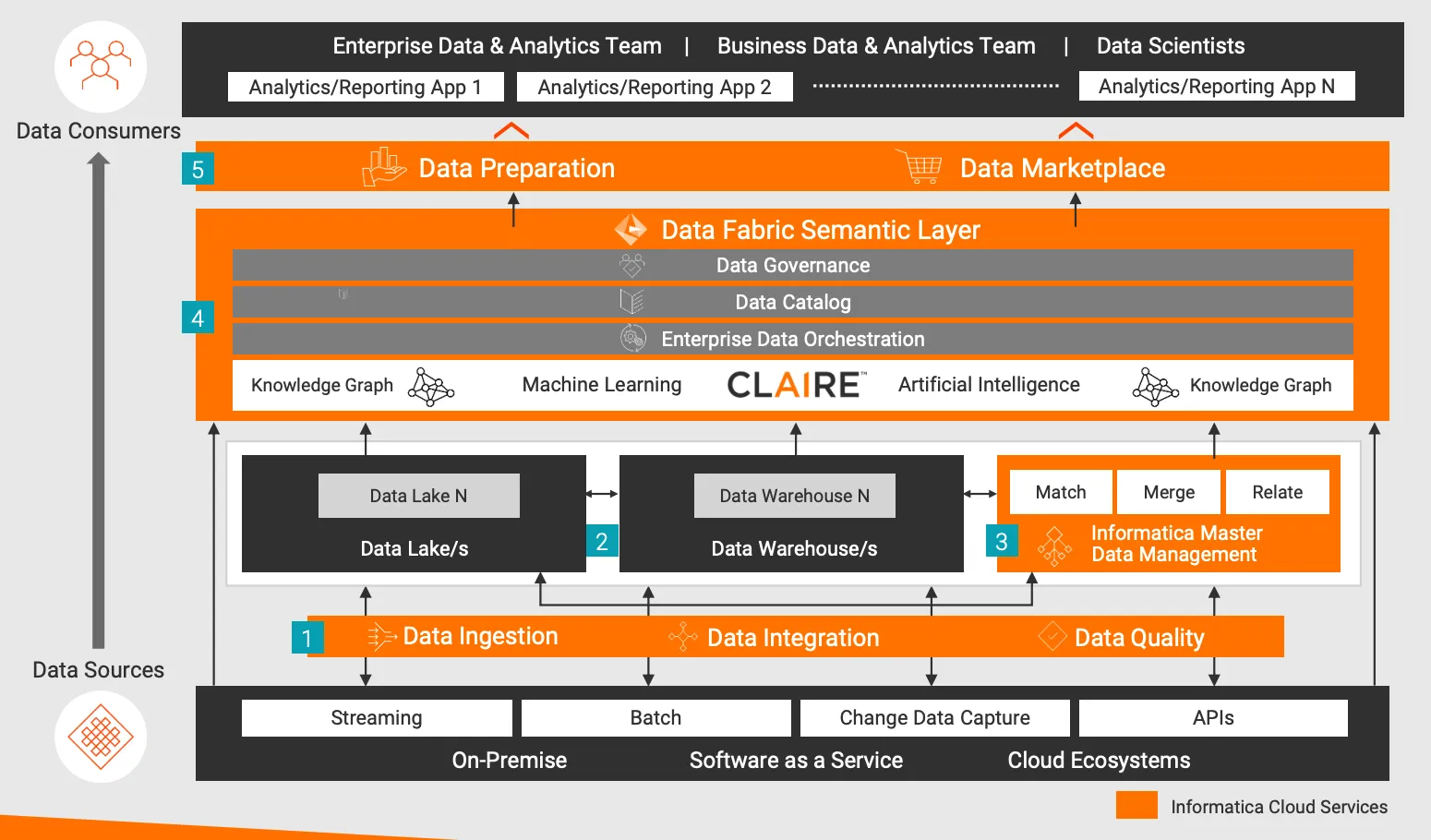
图11 Informatica Data Fabric 技术架构具体实现
如上图,Informatica 的智能 Data Fabric 架构。
架构流程描述:
- 数据摄取、数据集成和数据质量——使用可扩展的流式处理、批处理、变更数据捕获和API,从本地环境、软件即服务(SaaS)或云生态系统中以任意速度摄取、标准化和清洗任何数据,并具备全面和高性能的连接能力。
- 数据湖、数据仓库和其他分析数据存储——使用适合目的的数据管理技术(关系型数据库管理系统、Spark、云存储对象、NoSQL数据库)存储结构化和非结构化数据。
- 主数据管理——协调跨领域碎片化的常见企业数据。匹配重复数据,将常见数据合并为“黄金主数据”,并将这些共享的高价值数据与其他相关数据关联起来。使这些“黄金数据”在整个Data Fabric中可访问。
- 语义层——支持所有数据存储中的“元数据记录系统”。机器学习/人工智能自动从不同的数据源中捕获和增强元数据,并填充知识图谱以记录数据与业务之间的关联。数据目录提供了一个语义可搜索的存储库,包括数据血统、数据分析结果和部落知识,以促进数据的发现和理解。数据治理为技术理解、业务相关性、数据的使用和访问提供了上下文。企业数据编排协调这些语义支持过程和数据交付。
- 数据准备和数据市场——为数据消费者提供受管控的自助式分析数据供应。数据准备提供了一个用户友好的界面,用于收集、组合、结构化和组织这些数据,而数据市场则创建了一个“购物数据”的体验,以查找和交付数据。
优势:
- 增强的数据集成支持:客户选择Informatica的数据集成工具的主要原因之一是其对复杂和重复的数据集成任务的自动化支持。Informatica在其主动元数据驱动的机器学习引擎CLAIRE上进行了重大投资,该引擎对收集的所有元数据进行持续分析,以显著自动化模式漂移、数据流水线编排、性能监控和优化以及数据建模。
- 与云采用相一致的定价和许可:Informatica已经转向了一个更简单、基于消费的许可模型,基于Informatica处理单元(IPU)。这个通用的容量单位可以在IDMC伞下提供的所有云服务中使用。用户可以订阅一定数量的IPU(基于预测使用量),然后可以在其所有主要数据集成产品线中互换使用。这种新的定价模型的早期采用者报告了易于理解、采用和扩展的优点。
- 操作数据集成用例交付:寻求支持操作数据集成用例的数据中心架构的技术实施的客户认为Informatica的解决方案成熟。Cloud Integration Hub的功能经常被客户评估和选择,因为它能够支持所有数据模式(包括批处理、虚拟、流式和基于API的集成),并且能够在多云/混合环境中进行数据和应用集成方案的集成、治理和共享。
不足:
- PowerCenter到Informatica Cloud迁移存在挑战:一些客户在从PowerCenter迁移到Informatica Cloud时报告了一些挑战。Informatica提供了一个迁移工具(自动化了一定比例的手动映射转换任务),但需要额外付费。一些客户报告称,他们的开发人员需要投入时间,以便能够有效地利用Informatica Cloud的升级(以及某些新功能),以优化新的云环境中的现有集成工作负载。一些早期迁移的客户报告了需要手动解决方案和迁移后的测试。Informatica在这个领域进行了投资,通过培训和认证包括Accenture、KPMG和Deloitte在内的各种全球系统集成合作伙伴,以协助Informatica客户进行迁移项目。
- 过于专注于端到端数据管理场景的市场推广:Informatica提供了广泛的工具组合,以支持各种数据集成场景。尽管大型企业客户对此表示认可,但中小企业和希望从基本数据摄取管道开始的业务部门常常发现Informatica的产品组合和信息传递(因其专注于增强集成、CLAIRE和Data Fabric)过于庞大和复杂。Informatica应该在端到端的丰富功能和针对性的最好的工具之间取得平衡,以支持“落地并扩展”的策略。为了解决其中一些挑战,Informatica最近推出了一个免费的Data Loader服务,以支持简化的构建数据管道工作流程。
- 对DataOps相关增强的呼声:一些客户表示不知道Informatica的数据集成工具如何与流行的第三方或开源编排和任务工作流管理工具(如dbt、Apache Airflow、Luigi、Prefect和Dagster)集成和互操作。数据工程师们赞赏Informatica的低代码集成支持,但表示他们不知道其可扩展性功能,以适用于某些需要编码的用例。一些客户还提出了在Informatica的工具组合中改进变更管理、版本控制和CI/CD能力的需求。
IBM Cloud Pak for Data [6]
IBM 同样也是 Data Fabric 领域的领导者。IBM总部位于Armonk, New York。IBM Cloud Pak for Data(包括DataStage Enterprise Plus Cartridge)、IBM Cloud Pak for Integration(用于应用集成场景)、Cloud Pak for Data as a Service(包括DataStage as a Service、Watson Query as a Service和Watson Knowledge Catalog as a Service)和IBM Data Replication都针对各种数据集成用例场景。该产品系列的客户基础超过10,000个组织。其业务遍布全球,其客户主要是银行和金融服务、保险、医疗保健和制药行业的企业B2B和B2C组织。
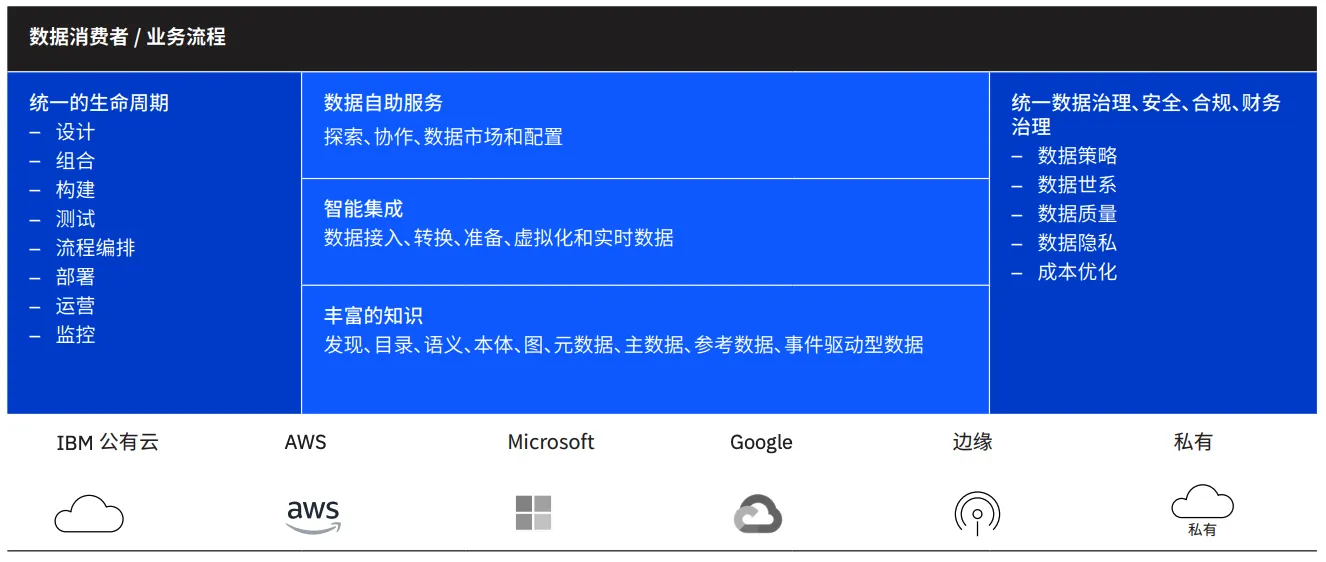
图12 IBM(Cloud Pak for Data)Data Fabric 技术架构
如上图,IBM Cloud Pak for Data 平台的能力:支持 AI 开发和Data Fabric。
优势:
- 支持Data Fabric设计:IBM软件与IBM研究合作,在其Cloud Pak for Data(CPD)平台和服务中嵌入了增强数据集成的能力。通过在Watson Knowledge Catalog中捕获和激活元数据的能力,支持DataOps模式以改进编排和敏捷性,以及利用知识图谱支持语义建模和无结构内容的分类到本体映射,进一步提高了其对Data Fabric用例的支持。
- 全面的操作和分析用例支持组合:IBM在CPD中拥有一个全面的工具组合,包括DataStage(用于批量/批处理集成)、IBM Cloud Pak for Integration(用于应用集成和API管理)、Watson Query(用于数据虚拟化)、IBM Data Replication(用于数据复制和同步)和IBM Streams(用于流数据集成场景)。除了这些能力外,IBM CPD还与其他数据管理技术(包括数据质量、MDM和数据治理)紧密集成。
- 模块化架构和DataOps支持:IBM的数据集成工具以紧密集成但松散耦合的服务形式交付在基于Kubernetes的Red Hat OpenShift平台上。客户赞赏IBM的远程运行时能力,通过允许开发人员构建一次流水线并将工作负载推送到他们选择的执行环境中,降低了出口成本。IBM对CI/CD的支持以及与Git(用于版本控制)、Jenkins(用于任务调度)和其他第三方任务和工作流管理器的集成受到高度评价。
不足:
- 数据复制产品成熟度:IBM通过目前支持的IBM Data Replication软件包提供变更数据捕获(CDC)技术。然而,一些客户仍在使用其传统的CDC工具。IBM的参考客户报告称,该产品系列的用户界面不够出色。一些客户强调了工作负载监控、性能优化和高可用性方面的挑战。IBM应加快将客户迁移到IBM Cloud Pak for Data上的IBM Data Replication服务(从传统的IBM CDC产品)并改进其流数据集成支持能力,以确保现有客户不必评估第三方数据复制解决方案。
- 迁移和升级缺乏明确性:尽管IBM正在积极努力将传统的IBM Infosphere Information Server客户迁移到IBM Cloud Pak for Data,但一些客户报告称缺乏关于最佳实践和许可证可移植性的明确性,并指出缺乏良好结构的迁移和升级路线图。尽管IBM确实提供了嵌入式迁移工具来帮助进行迁移到CPD,但客户对这种能力了解甚少。
- 市场认知和收入增长放缓:一些IBM的潜在客户(在Gartner的客户咨询服务中)仍然认为IBM的工具价格昂贵、实施复杂,并且针对具备强大数据工程技能的大型组织。Gartner对我们的提案审查数据的分析表明,除非他们是现有的IBM客户,否则很少有中小企业评估或考虑IBM的工具。IBM将Cloud Pak for Data定位为一套模块化服务(而不是端到端平台),并转向无服务器、按使用量计费的许可模式,这应该能缓解一些这些顾虑。
Tibco [7]
TIBCO Software是 Data Fabric 领域的挑战者。和Denodo一样TIBCO总部也位于Palo Alto, California 。其数据集成工具组合包括TIBCO数据虚拟化(TDV)、TIBCO云集成、TIBCO消息传递、TIBCO流处理和TIBCO OmniGen。该产品系列的客户基础超过7,500个组织。其业务地理分布广泛,其客户包括金融服务、电信和制造业等行业的公司。

图13 Tibco Data Fabric 技术架构具
如上图,TIBCO 的Data Fabric 架构图,旨在帮助组织解决复杂的数据问题和应用场景,通过管理用户的数据来实现这一目标,无论数据存储在哪种应用程序、平台和位置上。Data Fabric 在分布式数据环境中实现了无摩擦的访问和数据共享。
优势:
- 产品间的互操作性改进:TIBCO Cloud Metadata能够在TIBCO的所有数据和分析产品之间共享元数据。TIBCO Cloud Passport通过单一的消费模型,为客户提供了利用各种TIBCO云服务(包括TIBCO云集成)的灵活性。这是TIBCO努力将其能力定位为松散耦合、高度协同的一部分。
- 适用于大多数数据交付方式的专业化:TIBCO Software在流数据集成方面一直表现良好,通过TIBCO流处理和TIBCO云事件,在消息传递方面通过TIBCO消息传递,在数据虚拟化方面通过TDV。最近的一次收购将这个产品组合扩展到了ETL和ELT。TIBCO现在专注于可以结合这些方式的能力,例如在TDV中进行流数据虚拟化。
- 强大的Data Fabric愿景:TIBCO敏捷Data Fabric通过插件算法将其人工智能/机器学习能力嵌入到所有产品中,用于增强数据管理。围绕数据分类和标记的新专利技术支持创建基于业务的逻辑模型。改进了多个产品的用户体验,以增强Data Fabric的数据准备组件。
不足:
- 缺乏对DataOps的支持:TIBCO在对DataOps的快速升级的客户需求方面反应相对较慢,例如对数据交付的端到端编排,自动化的数据管理代码版本控制、代码测试和代码部署到生产环境的步骤。尽管TIBCO确实支持与一些CI/CD和版本控制工具(如Git)的集成,以及TDV Deployment Manager可用于在开发/生产/测试环境之间移动模型,但缺乏对DataOps的整体愿景。
- 在云迁移用例方面的影响有限:在将分析工作负载迁移到公共云并维护混合云环境时,客户很少评估TIBCO。TIBCO目前为其数据集成产品提供容器化支持,并已在2022年的路线图中全面提供SaaS服务。此外,尽管TDV在这种用例中发挥了一定作用,但基于日志的双向数据复制在这里通常是一个要求,这是TIBCO需要改进的领域。
- 需要改进文档:客户要求在TDV的帮助wiki中添加更多内容,为新用户提供更好的学习材料,并提供有关与第三方平台的系统集成的更新文档。TIBCO正在通过推出一个新的数字社区来解决这个问题,该社区将包括客户支持和产品文档等内容。
大致总结一下现在主流 Data Fabric 的产品的架构特点
Data Fabric 产品关键能力 | 当前主流大数据架构的能力 |
|---|---|
主动元数据与知识图谱 | 统一元数据、数据血缘、数据审计 |
数据虚拟化引擎 | 联邦查询、数据集成、ETL/ELT、数据编排 |
增强数据目录 | 数据地图、数据字典、数据治理 |
DataOps | DataOps |
AI增强 | AI增强 |
- 主动元数据与知识图谱:主动获取全局统一元数据、生成血缘关系、提供数据审计等。
- 数据虚拟化引擎: 统一访问入口、支持联邦查询、屏蔽底层异构,自适应通过数据加热或ETL优化查询性能等。
- 增强版数据目录: 生成数据地图和数据字典,加强团队协作和数据治理。
- DataOps :降低管理和运营成本,兼容多云场景。
- AI增强: 可以从使用中学习,并简化数据管理实践的开发、运营和性能调整等整个生命周期。
看起来业界现在领先的 Data Fabric 产品和国内主流的大数据平台是非常类似的,技术上也没什么特别的,当然目前国内将这些技术融合的很好的产品基本没有。 Data Fabric 提供了一个比较体系化的架构方法论,而且确实在许多场景可以解决现在存在的一些问题,作为下一代大数据架构的选项是完全OK的。
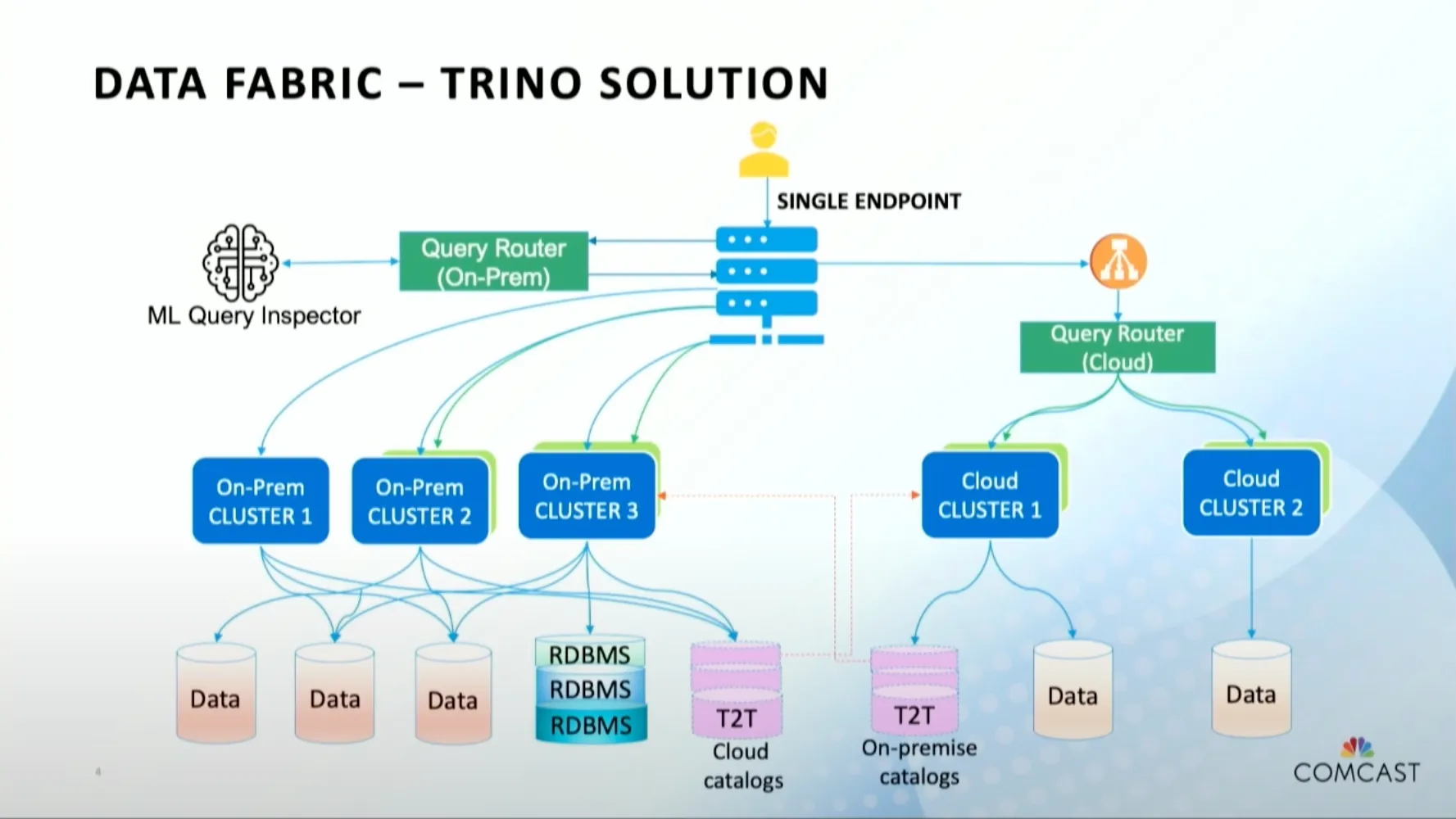
图14 Trino(Presto) Data Fabric 技术架构具体实现
如图是 Trino(Presto) 的创业公司提出基于Trino的 Data Fabric 架构,看来很多主流的框架都会往这个概念上去靠。
接下来国内会有一批创业公司会基于 Data Fabric 这个概念进行创业,大家陆续会在各个行业分享会上看到Data Fabric这个概念,数据平台、数据中台等这些概念已经有些”老了“,没有新概念也很难忽悠到投资人的钱。
提一下 Data Mesh
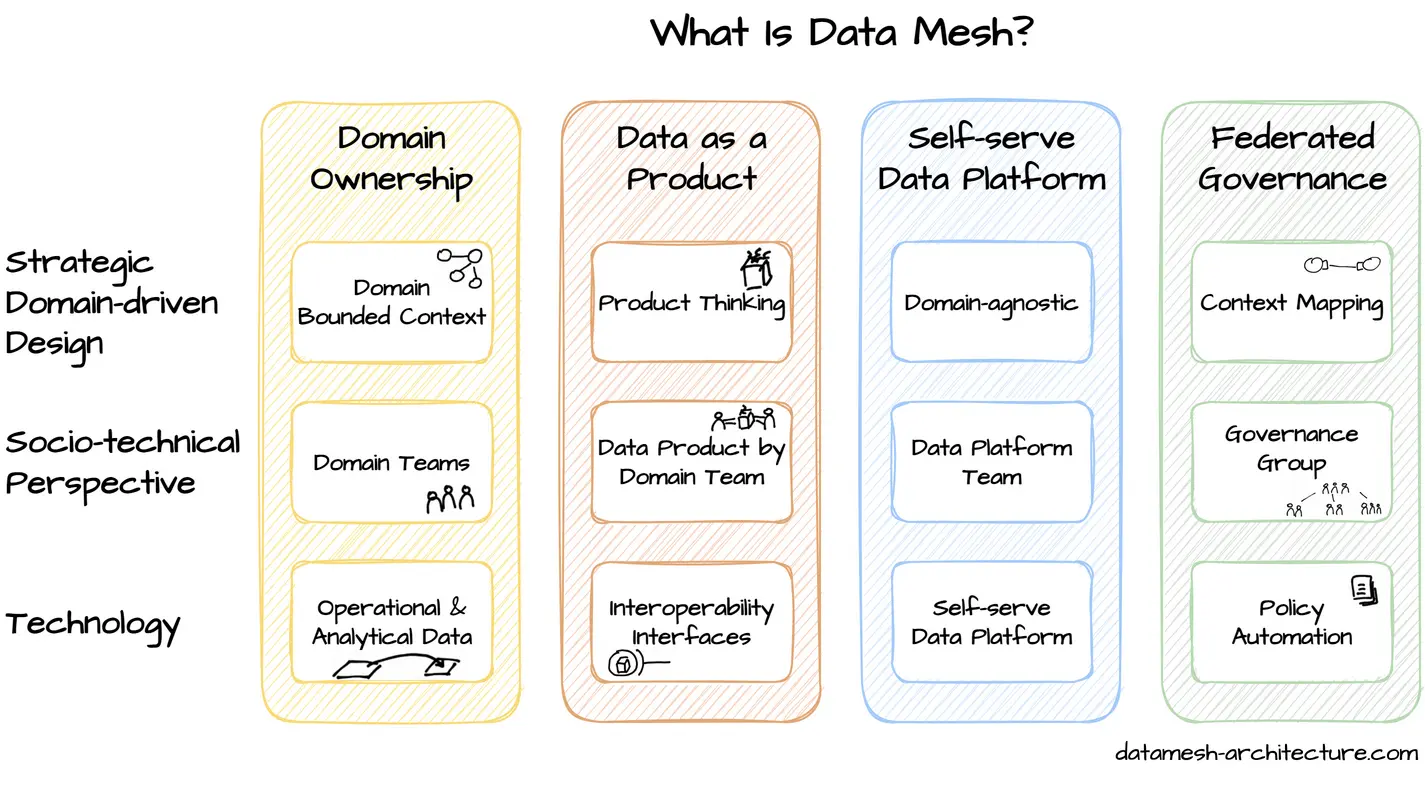
图15
Data Mesh 这个术语是由Zhamak Dehghani在2019年提出的,基于四个基本原则:
- 领域所有权原则(Domain Ownership Principle)要求领域团队对其数据负责。根据这个原则,分析数据应该围绕领域进行组织,类似于团队边界与系统的有界上下文相一致。遵循领域驱动的分布式架构,分析和操作数据的所有权被移交给领域团队,远离中央数据团队。即拥有该数据的团队,一般对自己的数据是最了解的、利用率最高的,可考虑自行处理;有些时候将数据统一放到中央数据团队,可能由于流程、节奏、场景等问题拖累数据的应用。
- 数据作为产品原则(Data as a Product Principle)将产品思维的理念应用于分析数据。这个原则意味着除了领域之外,数据还有其他消费者。领域团队负责通过提供高质量的数据来满足其他领域的需求。基本上,领域数据应该像其他公共API一样对待。即数据需要进行共享才是释放最大的价值,但是最好不要直接共享数据(效率低成本高),而是将数据转化为数据资产、数据产品后通过API提供给其他用户。
- 自助式数据基础设施平台(Self-Serve Data Infrastructure Platform)的理念是将平台思维应用于数据基础设施。一个专门的数据平台团队提供与领域无关的功能、工具和系统,用于构建、执行和维护可互操作的数据产品。通过其平台,数据平台团队使领域团队能够无缝地使用和创建数据产品。即完善流程和工具,让用户可以做到自助使用。
- 联邦治理原则(Federated Governance Principle)通过标准化实现所有数据产品的互操作性,这是由治理小组在整个数据网格中推动的。联邦治理的主要目标是创建一个遵守组织规则和行业法规的数据生态系统。即通过制定标准和规范,以方便进行联邦查询、治理。
很多时候基于Data Mesh做出来的产品和基于Data Fabric的类似,Denodo等公司的产品也宣传可以解决Data Mesh场景,因为就算是Data Mesh从概念上更倾向于领域自治,也是需要一个全局视角去解决数据孤岛问题,以达到数据共享的目的。
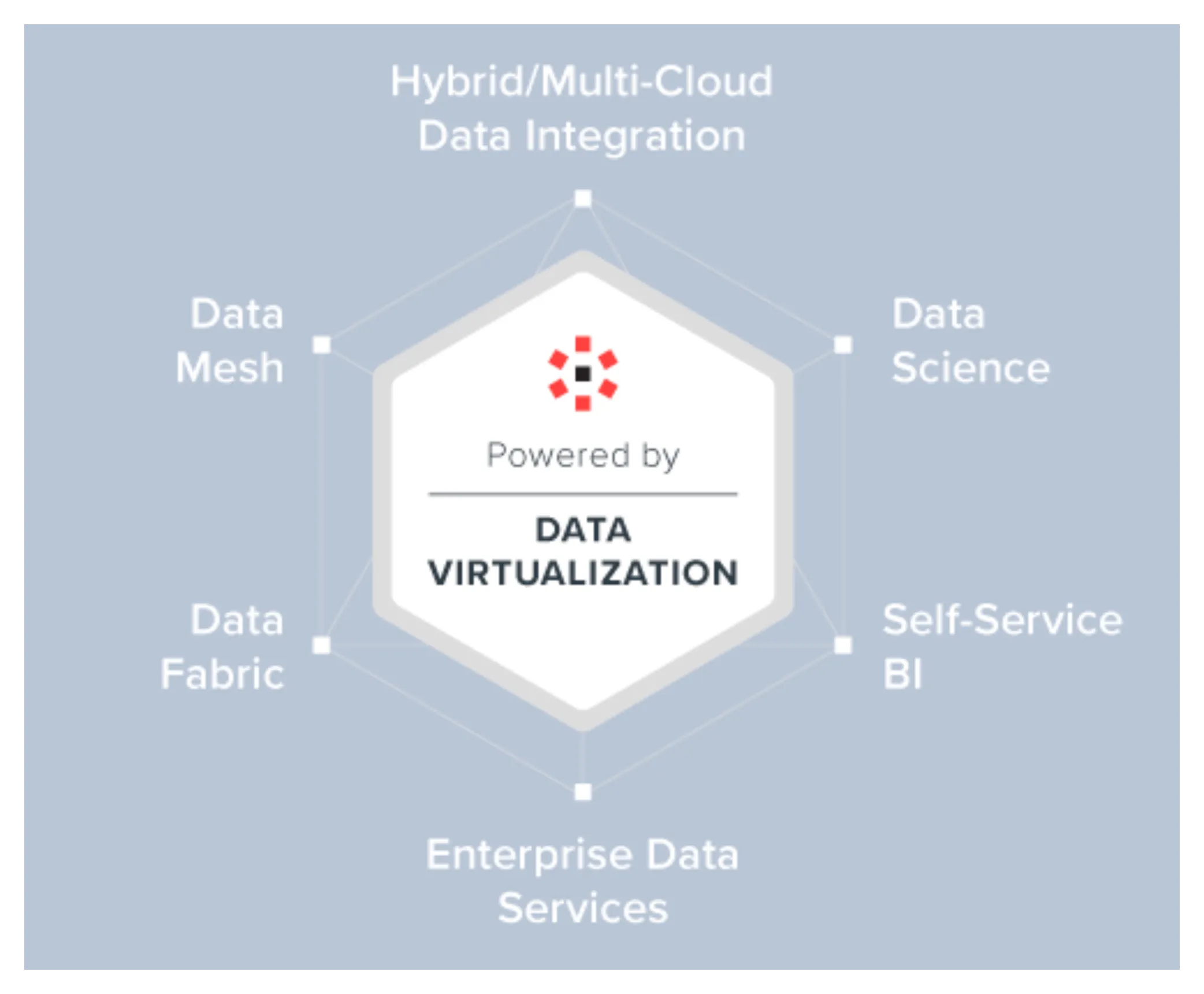
图16 虚拟化的应用场景
如上图,是Data Virtualization(数据虚拟化)解决的核心的几个场景。目前业界的大数据架构会基于Spark等计算框架进行跨源查询,进行统一抽象底层数据源,也做了数据虚拟化的一些工作,不过总的来说还是虚拟化的不够彻底,用户的使用成本相对还是比较高。所以Data Fabric、Data Mesh的产品在进行宣传是一般都会着重强调自己的虚拟化层,且在“人工智能”的作用下“降本提效”效果明显。
区别于 Data Mesh 自底向上通过宽泛的标准进行整合,Data Fabric 是自顶向下进行强约束的架构,更适合在同一个组织内部进行实践。另外还是说明一下 Data Mesh、Data Fabric 这两个概念目前还不是很成熟,需要较长的时间进行演化、实践,最终达成业界共识。
综述
我们可以发现很多架构中,会通过流程把人“编程”到特定的逻辑中,但是人的稳定性比代码可差太多了,在公司发展的过程中,无论是组织架构、人员的变动、能力的差异等,都会导致“历史债”的产生。所以需要用发展的眼光看问题,大数据架构也是合久必分、分久必合;当前我们可以参考 Data Fabric 方法论,通过抽象一层虚拟化层,然后辅助AI等能力来演化出一个智能化、易用、高效的大数据架构。
现今,基本上所有企业进行决策的时候都是基于数据驱动的,越大的公司数据源越复杂、业务越复杂、大数据架构也越复杂;当前主流的大数据架构已经可以基本满足业务需求,解决了“能不能”的问题,接下来业界主要的演进是“好不好”。Data Fabric 是一种具有前瞻性的数据管理方法,它整合了许多组件的功能,创建出一个强大的分布式逻辑架构用于屏蔽复杂性,旨在应对当今企业数据领域的巨大挑战。
参考
[1] Wikipedia 数据虚拟化
[2] Technology Brief: Dynamic Data Fabric and Trusted Data Mesh using the Oracle GoldenGate Platform
[3] Denodo 官网
[4] Aloudata 官网
[5] Informatica 官网
[7] Tibco官网
[8] Data Mesh 架构
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号