EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER(翻译)优化器架构

EFFICIENCY IN THE COLUMBIA DATABASE QUERY OPTIMIZER(翻译)优化器架构

jhonye
修改于 2023-09-27 20:54:03
修改于 2023-09-27 20:54:03
基于Cascades框架,Columbia优化器专注于优化的效率。本章将详细描述Columbia优化器的设计和实现,并进行与Cascades的比较讨论。
Columbia 优化器总览
图9展示了Columbia优化器的接口。Columbia接受一个初始的查询文本文件作为输入,使用由DBI提供的 Catalog 和 成本模型信息,生成查询的最优计划作为输出。
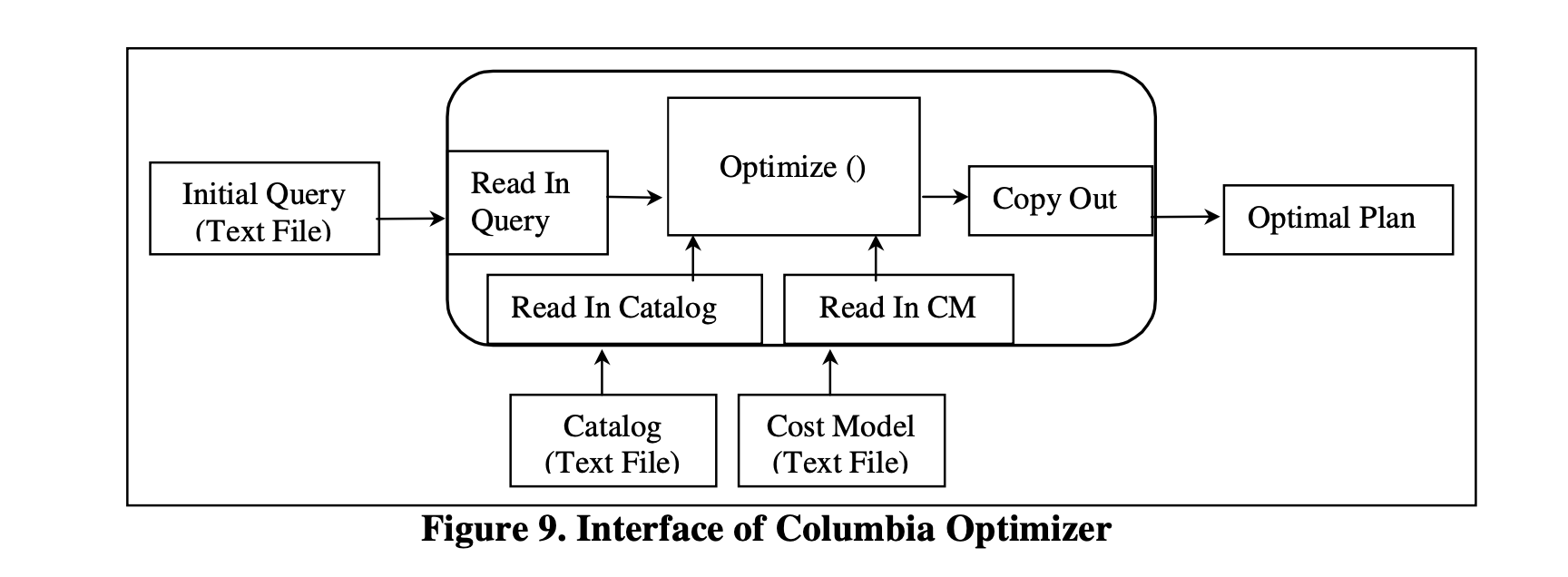
图9
优化器输入
在Columbia优化器中,输入是一个文本文件,其中包含以 LISP风格的树表示的初始Query树。树由顶层算子和其输入(如果存在)组成,这些输入被表示为子树。每个树或子树都用括号分隔。
表2 显示了Query树的文本格式的 BNF 定义。在查询文本文件中,允许使用注释,并以每行注释开始的“//”进行标识。查询解析器将忽略注释行。有时,注释对于编写或阅读查询文本文件的人非常有帮助,因为它们提供了额外的可读信息。每个查询文本文件只表示一个Query树。我们当前的逻辑运算符实现包括GET、EQJOIN、PROJECT和SELECT,足以表示大多数典型的选择-投影-连接查询。这种设计还可以轻松扩展以支持其他逻辑运算符。
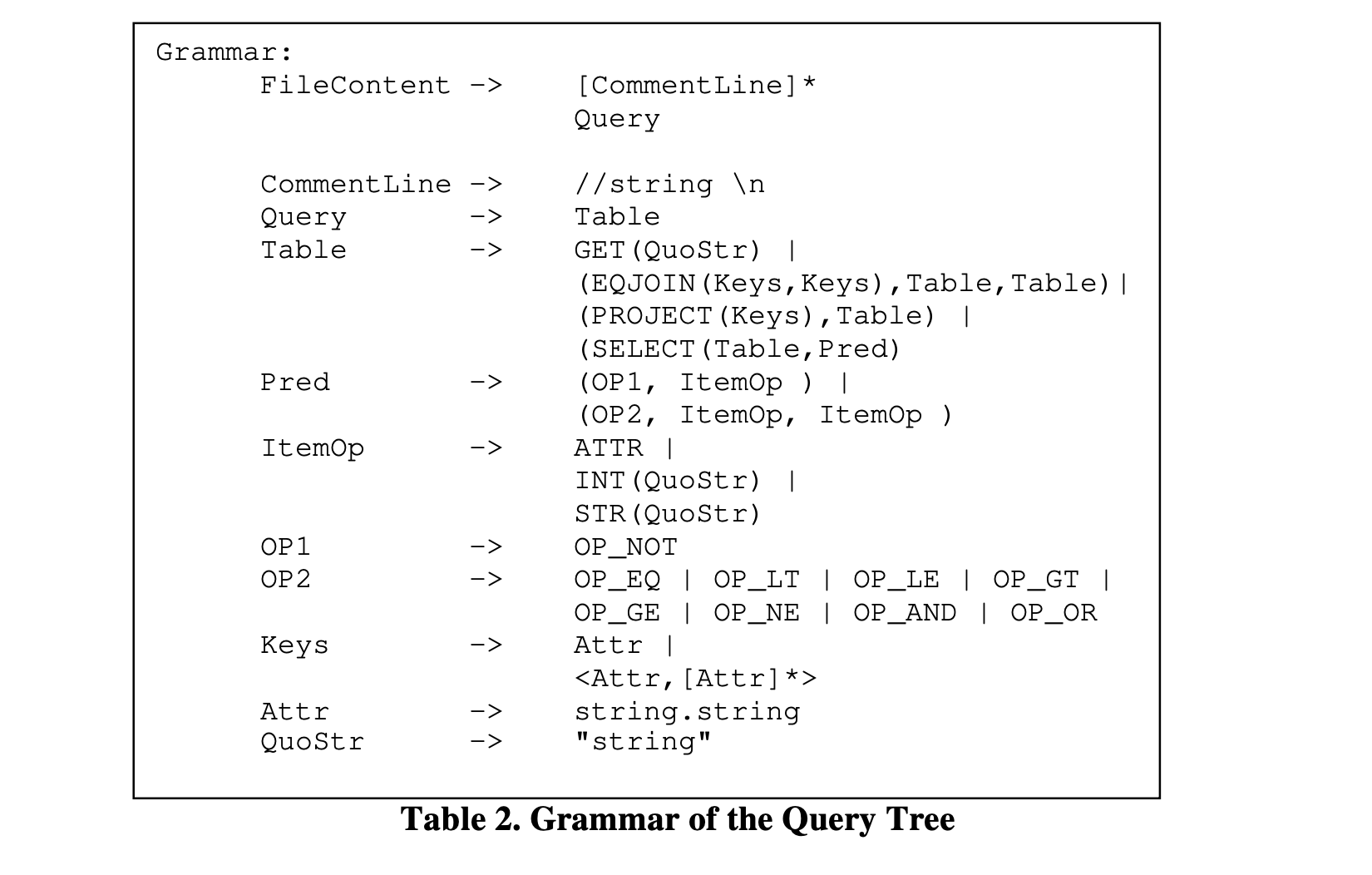
表2
优化器的查询解析器读取查询文本文件并将其存储为表达式树。表达式树被实现为递归数据结构,是一个EXPR类的对象,包含一个运算符和一个或多个EXPR对象作为输入。因此,查询表达式树可以从根表达式进行遍历。表达式树作为中间格式,在搜索空间初始化时由优化器复制到搜索空间中。这种模块分离允许高度的可扩展性。查询解析器与优化器之间的关系较松散(它以查询文本文件作为输入并输出查询表达式),因此可以很容易地向解析器中添加更多操作以支持更多功能,如模式检查、查询重写等。在Cascades中,初始查询直接以C++代码编写并嵌入到优化器的代码中。如果要优化另一个初始查询,则需要编译整个优化器代码以包含对初始查询表达式的更改。在Columbia优化器中,只需要重新编写查询文本文件以表示新的初始查询,无需编译代码。
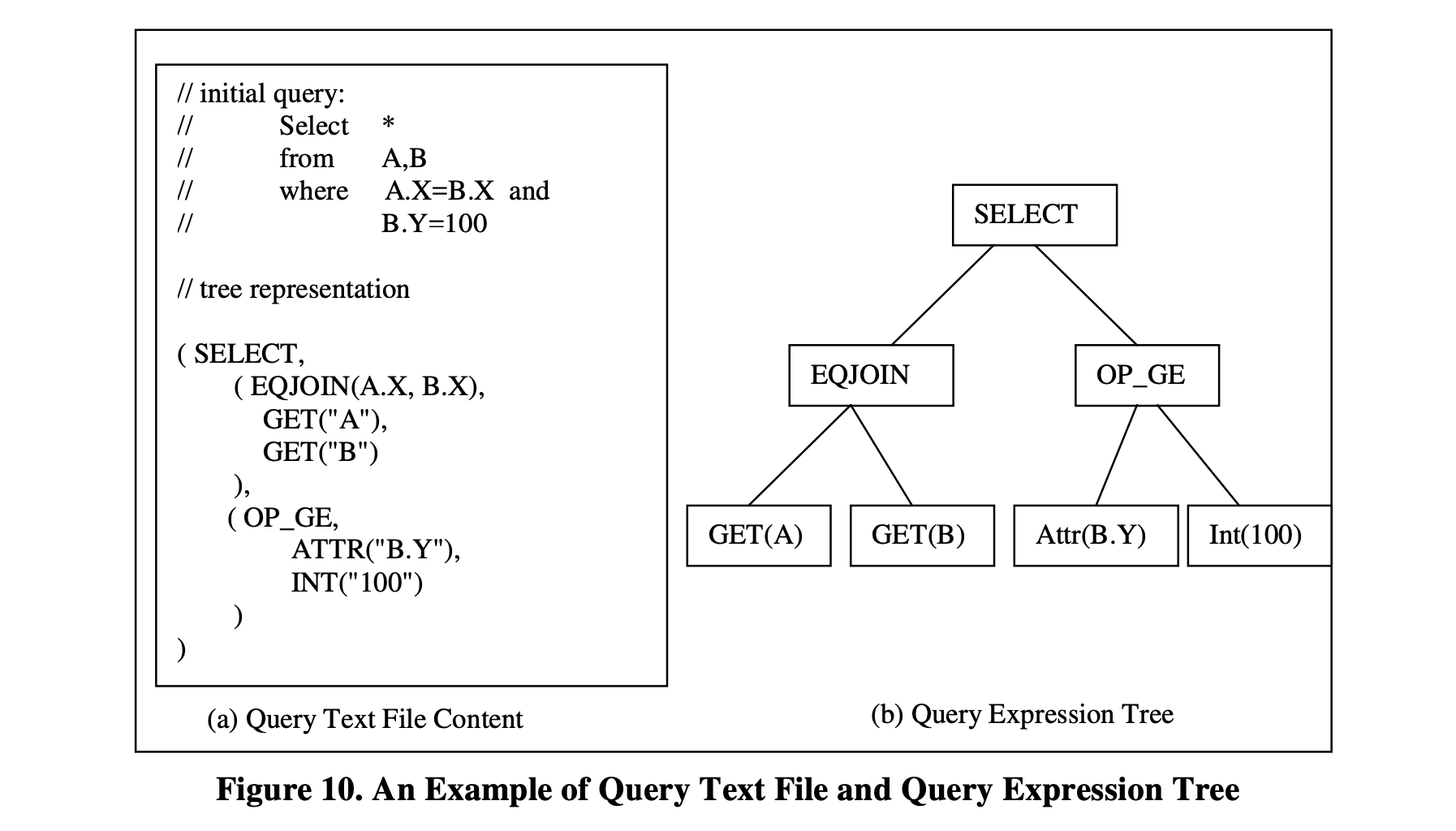
图10
图10 展示了查询文本文件的内容示例以及相应的查询表达式树。
如图10 所示,SELECT的谓词被表示为一个表达式树,作为SELECT运算符的输入之一。在Columbia优化器中,除了逻辑和物理算子,还有从Cascades继承而来的 item算子。item算子与bulk算子(逻辑和物理算子)不同之处在于,它们对固定数量(通常为1)的元组进行操作,而bulk算子对任意数量的元组进行操作[Bil97]。通常,item算子可以被视为对固定数量的元组或固定数量的(原子)值的函数。谓词被表示为item算子的表达式树,返回一个布尔值。谓词的树形表示提供了简单的谓词操作,例如穿过 join 进行谓词项(item算子的子树)下推[Gra95]。
优化器输出
在优化过程中,优化器找到查询的最优计划并将其复制出来。最优计划以缩进树形表示的物理表达式格式打印出来,并附带与表达式相关的成本信息。最终成本是相对于特定 catalog 和成本模型的最优成本。不同的catalog和成本模型为相同的查询产生不同的最优计划。图11展示了优化器输出的两个示例,它们都是相对于不同目录的查询在图10中的最优计划。
SELECT运算符的实现算法是FILTER,它对输入表的每个元组根据谓词进行判断。如图11 所示,不同的 Catalog 产生非常不同的成本和最优计划。使用索引的计划成本更低。

图11
优化器外部依赖
在4.1.2节中,说明了优化器依赖于两种类型的信息:Catalog 和 成本模型。在Columbia优化器中,Catalog和成本模型也以文本文件的形式描述,以提供可扩展性和易用性的特性。Catalog 解析器和成本模型解析器读取Catalog和成本模型信息,然后将它们存储在全局对象“Cat”和“Cm”中(分别是CAT类和CM类的实例)。在优化过程中,优化器将从这些全局对象中获取信息并相应地进行操作。
目前,Columbia 支持简单版本的Catalog和成本模型。这些文本文件模型允许进一步扩展到支持更多Catalog信息和更复杂成本模型的Catalog和成本模型。例如,通过在Catalog 文本文件中添加新条目并相应地修改Catalog,可以很容易地向Catalog添加功能依赖信息。此外,通过仅编辑文本文件,优化器的用户可以轻松更改Catalog和成本模型信息,以体验不同的优化。在Cascades中,Catalog和成本模型都被硬编码为C++代码,就像硬编码的查询表达式一样,因此对它们的任何更改都需要编译和链接所有代码。
为了说明简单且可扩展的格式,附录A和B给出了Catalog和成本模型文本文件的示例。
搜索引擎
图12 说明了Columbia搜索引擎的三个重要组成部分及其关系。搜索空间通过复制初始查询表达式来进行初始化。优化器的目标是扩展搜索空间,并从最终搜索空间中找到最优(即最小成本)的计划。在Columbia中,优化过程由一系列“任务”控制。这些任务优化搜索空间中的组和表达式,应用规则集中的规则,通过生成新的表达式和组来扩展搜索空间。在优化完成后(即所有任务都被调度),最终搜索空间中的最优计划被复制为优化器的输出。
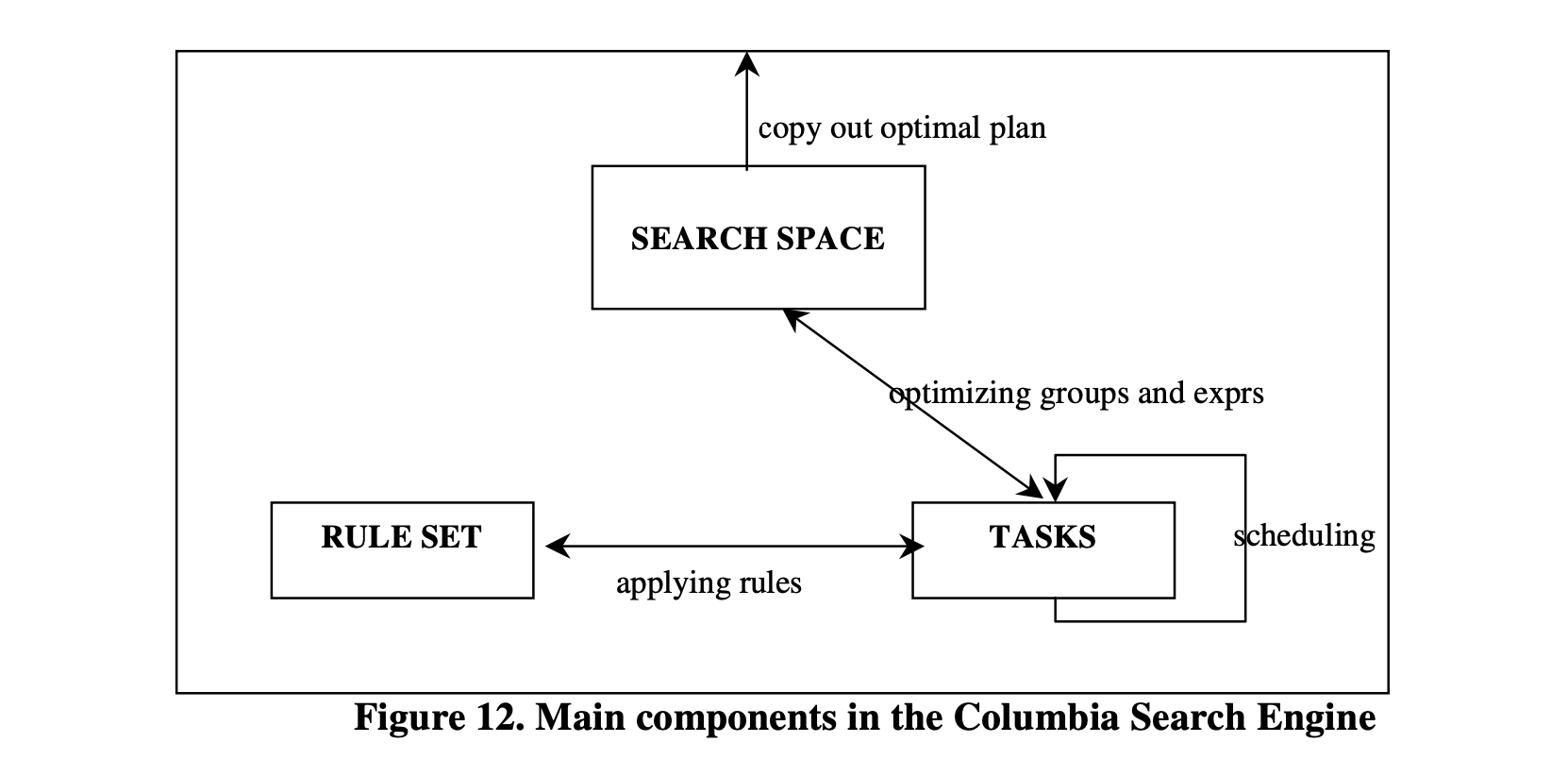
图12
搜索空间
multi-expression(子树)
本节将描述Columbia搜索空间的结构。搜索空间的组成部分是组(groups)。每个组包含一个或多个逻辑上等价的子树。
搜索空间结构 - Class SSP
我们借用了人工智能领域的术语“搜索空间”,它是解决问题的工具。在查询优化中,问题是找到给定查询的成本最低的计划,同时考虑特定的上下文。搜索空间通常由问题及其子问题的一组可能解决方案组成。动态规划和记忆化是使用搜索空间解决问题的两种方法。动态规划和记忆化通过逻辑等价性将可能的解决方案进行分组。我们将每个分组称为一个组(GROUP)。因此,搜索空间由一组组成。
在Columbia中,使用类似于Cascades的MEMO结构来表示搜索空间,即一个SSP类的实例,它由一个组数组组成,其中一个组被标识为搜索空间中的根组。搜索空间中的每个组包含一组逻辑上等价的子树。正如在第2.4节中介绍的那样,子树由一个算子和一个或多个组作为输入组成。因此,搜索空间中的每个组都是根组或其他组的输入组,即从根组开始,可以访问所有其他组作为根组的后代。这就是为什么必须标识根组。通过复制初始查询表达式,搜索空间初始化为几个基本组。每个基本组只包含一个逻辑子树。优化的进一步操作将通过将新的多表达式和新的组添加到搜索空间来扩展搜索空间。方法“CopyIn”将一个表达式复制到一个子树,并将子树包含到搜索空间中。它可以将新的子树包含到逻辑上等价的现有组中,也可以将新的子树包含到新的组中,此时该方法将首先创建新的组并将其附加到搜索空间中。SSP类的方法“CopyOut”将在优化完成后输出最优计划。
搜索空间上的重复子树检测
将一个子树包含到搜索空间中可能存在一个潜在问题,即可能发生重复,即搜索空间中可能存在与该子树完全相同的。因此,在实际的包含操作之前,必须通过整个搜索空间检查该是否存在重复。如果存在重复,则不应将该子树添加到搜索空间中。
为了检查重复,至少需要以下3个算法:
- 基于树的搜索
- 可扩展哈希
- 静态哈希
虽然已经存在一些针对 算法1或 算法2的代码,但它们很复杂,很难确定它们在这种情况下是否高效。而选择方案3则简单易于编码,尽管当多表达式的数量呈指数增长时可能会出现问题。由于生成了更多的表达式,当优化大型查询时,适用于小型查询的具有固定桶数的哈希表将被填满许多条目。
Cascades和Columbia都使用静态哈希(方案3)来快速检测重复的多表达式。因此,无法避免固定桶大小的潜在问题。搜索空间包含一个静态哈希表。多表达式的三个组成部分,即算子类名、算子参数和输入组编号,都被哈希到哈希表中以检查重复。Columbia和Cascades之间的主要区别在于Columbia使用了高效的哈希函数。
与Cascades使用传统的哈希函数(随机化后取模一个质数)不同,Columbia选择了一种高效的哈希函数“lookup2”,它是对Bob Jenkins编写的原始哈希函数LOOKUP2的修改。Jenkins [Bob97]声称LOOKUP2相对于许多传统的哈希函数来说简单且非常高效。通过简单且快速的操作(如加法、减法和位操作),将哈希键的每个位与其他三个“魔术”值的位混合在一起。键的每个位都会影响返回值的每个位。lookup2的另一个优点是其哈希表的大小是2的幂次,这允许对这样的哈希表大小进行非常快速的模运算。相反,传统的哈希函数需要对一个质数进行模运算,这比对2的幂次进行模运算要慢得多。对于大量的哈希操作,哈希函数的效率非常重要。图13 显示了使用Lookup2函数的伪代码。该伪代码的返回值用作键的哈希值。

图13
由于重复只会在优化过程中发生在逻辑子树上(物理表达式是从逻辑表达式唯一生成的),当要将它们包含到搜索空间中时,优化器会对所有生成的逻辑多表达式进行哈希以检查重复。一个多表达式有三个组成部分:算子类名、算子参数和零个或多个输入组。为了最大化哈希值的分布,Columbia将这三个组成部分都作为多表达式键的参数。这三个组成部分依次应用于哈希函数:首先将算子类名哈希为一个值,该值用于初始化哈希算子参数的初始值。然后,将该哈希值作为初始值依次哈希输入组。最终的哈希值就是子树的哈希值。
SSP类的方法“FindDup()”实现了重复检测。搜索空间中的哈希表包含对搜索空间中逻辑多表达式的指针。FindDup方法以一个多表达式作为参数,并在搜索空间中查找是否存在重复的多表达式。以下是FindDup的算法:计算多表达式的哈希值,然后查找哈希表以查看是否存在冲突。如果存在冲突,则按照简单性的顺序进行两个多表达式的比较,即首先比较运算符的元数,然后比较输入组,最后比较运算符的参数。如果没有找到重复项,则将新的多表达式链接到具有相同哈希值的多表达式上。如果哈希表中没有冲突,则将新的子树添加到哈希表中,并且没有找到重复项。 回想一下,搜索空间中的子树数量非常大,Columbia中的这种哈希机制能够简单高效地消除整个搜索空间中的子树重复。
分组
GROUP类是自顶向下优化中的核心。一个组包含一组逻辑上等价的逻辑和物理子树。由于所有这些子树具有相同的逻辑属性,GROUP类还存储了指向这些子树共享的逻辑属性的指针。对于动态规划和记忆化,还包括记录组的最优计划的获胜者结构。除了这些组的基本元素之外,Columbia对这个类进行了改进,以便实现高效的搜索策略。与Cascades相比,改进包括添加一个下界成员、将物理和逻辑子树分开以及更好的获胜者结构。
组的下界。组的下界是一个值 L,使得组中的每个计划P满足:cost(P) >= L。下界是自顶向下优化中的重要度量,当组的下界大于当前优化的成本上限(即当前优化的成本限制)时,可能会发生组剪枝。组剪枝可以避免对整个输入组进行枚举,同时不会错过最优计划。第4.4.1节将详细讨论Columbia中的组剪枝,这是Columbia优化器效率的主要贡献之一。组的下界在创建组时计算并存储在组中,以便在未来的优化操作中使用。
本节描述了如何在 Columbia 中获取组的下界。显然,较高的下界更好。目标是根据我们从组中收集到的信息找到可能的最高下界。当构建一个组时,从组中收集逻辑属性,包括组的基数和模式,从中推导出我们的下界。由于下界仅基于组的逻辑属性,因此可以在不枚举组中的任何表达式的情况下计算出来。
在说明下界的计算逻辑之前,展示一些定义:
- touchcopy() is a function which returns a numeric value such that for any join the value is less than cost of a join divided by cardinality of the join output. This function represents the cost of touching the two tuples needed to make the output tuple, and the cost of copying the result out.
- touchcopy() 是一个函数,返回一个数值,对于任何 join 操作,该值都小于连接操作的成本 除以 连接输出的基数。这个函数表示触碰生成输出元组所需的两个元组的成本,以及将结果复制出去的成本。
- Fetch() is the amortized cost of fetching one byte from disk, assuming data is fetched in blocks.
- Fetch() 是从磁盘中获取一个字节的摊销成本,假设数据是以块为单位获取的。
- |G| denotes the cardinality of group G.
- |G| 是组G的基数
- Given a group G,we say that a base table A is in the schema of G if A.X is in the schema of G for some attribute X of A. Then cucard(A.X) denotes the unique cardinality of a column A.X in G, cucard(A) in G denotes the maximum value of cucard(A.X) over all attributes A.X in the schema of G. Without loss of generality we assume the base tables in the schema of G are A1, . . . , An, n >= 1, and cucard(A1) <= ... <= cucard(An).
- 给定一个组G,如果A.X是A的属性X在G的模式中,则我们说数据库表A在G的模式中。然后,cucard(A.X)表示G中列A.X的唯一基数,cucard(A)在G中表示G模式中所有属性A.X的cucard(A.X)的最大值。不失一般性,我们假设G模式中的基本表是A1,...,An,其中n >= 1,并且cucard(A1) <= ... <= cucard(An)。
组的下界计算 如图14。

图14 注意:对于每个没有在 join 顺序上建立索引的Ai,将上述“from leaves”项中的cucard(Ai)替换为|Ai|,可以得到一个更好的下界。
在图14 中,我们定义了组的三种下界。下面的段落中详细讨论了这三种下界。这三种下界是独立的,因此它们的总和提供了组的下界。
(1). 来自G的顶部连接的 touch-copy下界。它基于G的基数,因为G中任何计划输出的元组集合只是该组的顶部连接的结果输出。根据touchcopy()的定义,任何连接的成本(包括复制输出的成本)至少是结果连接的基数乘以t ouchcopy()。
(2). 来自G的非顶部连接的touch-copy下界。它基于G中列的唯一基数,即G模式中属性的cucards。我们可以证明这个touch-copy下界是非顶部连接的一个下界。
- Theorem: A lower bound corresponding to non-top joins of G is given by touchcopy() * sum ( cucard(Ai) where i=2, ..., n )
- 定理:G的非顶级连接对应的下界由touchcopy() * sum ( cucard(Ai) where i=2, ..., n )给出。
- Motivation: Think of the left deep plan with the Ai’s in order. The first join has A2 in its schema so a lower bound for the join of A1 and A2 is touchcopy()*C2 where C2=cucard(A2). Other joins Ai (i>2) have the same properties. So the sum of them yields the result of the theorem. The following lemma says this works for any ordering of the Ai and for any join graph, not only left deep.
- 动机:考虑按顺序排列的左深计划,其中包含Ai。第一个连接的模式中包含A2,因此A1和A2的连接的下界为touchcopy()C2,其中C2=cucard(A2)。其他连接Ai(i>2)具有相同的属性。因此它们的总和得出了定理的结果。以下引理说明这适用于Ai的任何排序和任何连接图,不仅仅是左深计划。
- Lemma: Let L be an operator tree such that schema(L) contains attributes from base tables A1, ..., An. Let J be the set of joins in L and let A* be an arbitrary table in the schema of L. There is a map f: J -> schema(L) such that (1) the range of f is all of schema(L) except A*, (2) foreach j in J,f(j) is in the schema of j.
- 引理:设L是一个操作树,其模式包含基本表A1,...,An的属性。设J是L中的连接集合,A是L模式中的任意表。存在一个映射f: J -> schema(L),满足:(1) f的值域是除A之外的schema(L)的所有属性。(2) 对于J中的每个j,f(j)在j的模式中。
- Proof of Lemma: by induction on k = size of schema(L). The case k = 2 is obvious. Induction step: Let L have k tables in its schema. Map the top join to any table on the side without A*. Induction succeeds on the two sub-trees since each of the sub-trees has less than k tables in its schema.
- 设J是L中的连接集合,A是L模式中的任意表。存在一个映射f: J -> schema(L),满足: (1) f的值域是除A之外的schema(L)的所有属性。 (2) 对于J中的每个j,f(j)在j的模式中。 引理的证明:对模式大小k进行归纳。当k = 2时,显然成立。归纳步骤:设L的模式中有k个表。将顶级连接映射到不包含A的一侧的任意表。归纳成功地应用于两个子树,因为每个子树的模式中的表数小于k。
- Proof of theorem: For any ordering of Ai and any join graph of the group G, there are n-1 joins in G. Let J be a set of joins of G and Ji (where i= 2, ..., n) be a join of G. The schema of G contains attributes from base table A1, ..., An. According to the lemma, there is a map from J to the schema of G, such that Ji (i=2, ..., n) maps to Ai (i=2, ..., n) respectively and Ai is in the schema of Ji. Thus, a lower bound for the join Ji is touchcopy() * Ci where Ci>=cucard(Ai). Hence, the sum of these lower bounds for join Ji (where I=2,..., n) is touchcopy() * sum ( cucard(Ai) where i=2, ..., n ), which prove the theorem.
- 定理的证明:对于Ai的任何排序和G的任何连接图,G中有n-1个连接。设J是G的连接集合,Ji(其中i=2,...,n)是G的一个连接。G的模式包含基本表A1,...,An的属性。根据引理,存在一个从J到G的模式的映射,使得Ji(i=2,...,n)分别映射到Ai(i=2,...,n),并且Ai在Ji的模式中。因此,连接Ji的下界为touchcopy() * Ci,其中Ci>=cucard(Ai)。因此,这些连接Ji(其中I=2,...,n)的下界的总和为touchcopy() * sum ( cucard(Ai) where i=2, ..., n ),证明了定理。
(3). 来自G的叶子节点(基本表)的fetch下界。它也基于G模式中属性的cucards,对应于从基本表中获取元组的成本。这个获取成本作为G的下界的原因是:
- Theorem: Suppose T.A is an attribute of a group G, where T is a range variable ranging over a base table which we also call T, and A is an attribute of the base table. Let c = the cucard of T.A. Then any plan in G must fetch (retrieve from disc) at least c tuples from A. Especially, if c is the max cucard value over all T.As in G, it yields a higher fetch cost.
- 定理:假设T.A是组G的一个属性,其中T是一个在基本表上变化的范围变量,我们也称之为T,A是基本表的一个属性。设c为T.A的cucard值。那么G中的任何计划都必须从A中检索至少c个元组。特别地,如果c是G中所有T.A的最大cucard值,则会导致更高的检索成本。
- Proof: Each relational operator preserves values of attributes (assuming the attributes are still in the output, e.g., are not projected out). Thus if there are two tuples in a plan from G with distinct T.A values, just descend the plan tree to T in order to find two tuples in T with these same T.A values.
- 证明:每个关系算子都保留属性的值(假设属性仍然在输出中,例如没有被投影掉)。因此,如果计划中存在两个具有不同T.A值的元组,只需沿着计划树下降到T,就可以找到具有相同T.A值的两个T中的元组。
- Separation of logical and physical multi-expressions. Cascades stored logical and physical multi-expressions in a single linked list. We store them in separate lists, which saves time in two cases.
- 逻辑和物理多表达式的分离。Cascades将存储的逻辑和物理子树存储在单个链表中。我们将它们存储在不同的列表中,这在两种情况下节省时间。
首先,规则绑定将所有逻辑子树作为输入来检查是否匹配模式,因此我们不需要跳过物理子树。一个组通常包含大量的逻辑和物理子树,可能占用几页虚拟内存,因此对物理子树的单个引用可能导致内存页错误,从而大大降低程序的执行速度。通常,一个组中物理子树的数量是逻辑子树的两倍或三倍。通过分离逻辑和物理表达式,并仅查看逻辑表达式,Columbia中的绑定应该比Cascades中的绑定更快。
其次,如果一个组已经被优化,并且我们正在为不同的属性进行优化,我们可以分别处理组中的物理和逻辑子树。物理列表中的物理子树仅被扫描以检查所需属性是否满足并直接计算成本,逻辑列表中的逻辑子树仅被扫描以查看是否已触发了所有适当的规则。只有当一个规则之前未应用于一个表达式时,才对逻辑表达式进行优化。在 Cascades 中,优化一个组的任务不考虑物理子树。相反,所有逻辑子树都需要再次进行优化。显然,Columbia中优化组的方法优于Cascades中的方法,并且通过在组中分离逻辑和物理链接列表来实现。
更好的获胜者结构。动态规划和记忆化的关键思想是保存搜索的获胜者以供将来使用。对于问题或子问题的最低成本解的每次搜索都是相对于某个上下文进行的。这里的上下文包括所需的物理属性(例如,解必须按A.X排序)和一个上界(例如,解的成本必须小于5)。一个获胜者是在引导搜索的上下文中赢得搜索的子树(物理)。由于不同的搜索上下文可能为一个组产生不同的获胜者,因此将获胜者对象数组存储在组结构中。
在Cascades中,Winner类包含一个由引导搜索的上下文和赢得该搜索的子树组成的对。Cascades中的获胜者类还包含一个指针,用于链接到下一个获胜者,表示该组可能有另一个获胜者适用于不同的搜索上下文。
在Columbia中,使用了一个简化的结构来表示获胜者。在Columbia中,获胜者类不存储上下文和链接到其他获胜者的指针,而是由赢得搜索的子树、表达式的成本(即获胜者)和搜索的所需物理属性组成。组中的获胜者对象表示对该组的一次可能搜索的结果。由于一个组包含一组获胜者,所以不需要存储指向组的下一个获胜者的指针。显然,Columbia中的获胜者结构比Cascades中的获胜者结构更简单、更小。在Columbia中,获胜者还用于存储搜索的临时结果。在计算组的物理多表达式的成本时,将找到的最便宜的表达式存储为获胜者。在优化过程中,获胜者会不断改进,最终找到最佳(最低成本)的计划。有时,当找不到具有所需物理属性的物理算子时,我们将子树指针存储为NULL,表示该物理属性没有获胜者。由于没有获胜者也是该子问题的解,这个信息被记忆化,并将在将来的优化过程中发挥作用。以下是Columbia中WINNER类的数据成员的定义:

代码定义
表达式
有两种类型的表达式对象:EXPR和M_EXPR。
EXPR对象对应于查询优化中的表达式,它表示优化器中的查询或子查询。EXPR对象被建模为具有参数(OP类)的算子,以及指向输入表达式(EXPR类)的指针。为了方便起见,它保留了算子的arity(元数)。EXPR用于表示初始和最终查询,并参与规则的定义和绑定。
M_EXPR实现了多表达式。它是EXPR的一种紧凑形式,利用了共享。M_EXPR被建模为具有参数的算子,以及指向输入GROUP而不是EXPR的指针,因此一个M_EXPR包含了多个EXPR。M_EXPR是组的主要组成部分,所有的搜索都是在M_EXPR上进行的。因此,M_EXPR必须有一些与之相关联的状态。
表3显示了类M_EXPR中数据成员的定义,
表4显示了在Cascades中实现多表达式的相应类EXPR_LIST的定义。
表3和表4 说明了Columbia和Cascades中多表达式的两种类实现。我们可以看到,与Cascades中的相应类EXPR_LIST相比,类M_EXPR具有较少的数据成员。EXPR_LIST中的额外数据成员在M_EXPR中是不需要的:mexpr的arity可以从算子中获取。无需跟踪创建mexpr的任务,并存储物理mexpr的物理属性和成本,因为一旦计算并做出决策后,它们就不再在任何地方使用。由于多表达式占据了搜索空间内存的主要部分,因此将此数据结构尽可能简洁非常关键。例如,一个M_EXPR对象占用24字节的内存,而一个EXPR_LIST对象占用40字节的内存。类EXPR_LIST和M_EXPR之间的内存使用比例约为1.67:1。如果初始查询是10个表的连接,根据第2.5节中表1的数据,至少有57k个逻辑多表达式。在Columbia中,这些逻辑多表达式可能占用高达2457k = 1368k字节的内存。在Cascades中,它们可能占用高达4057k = 2280k字节的内存。因此,Columbia中的这种简洁数据结构在内存上节省了大量空间。
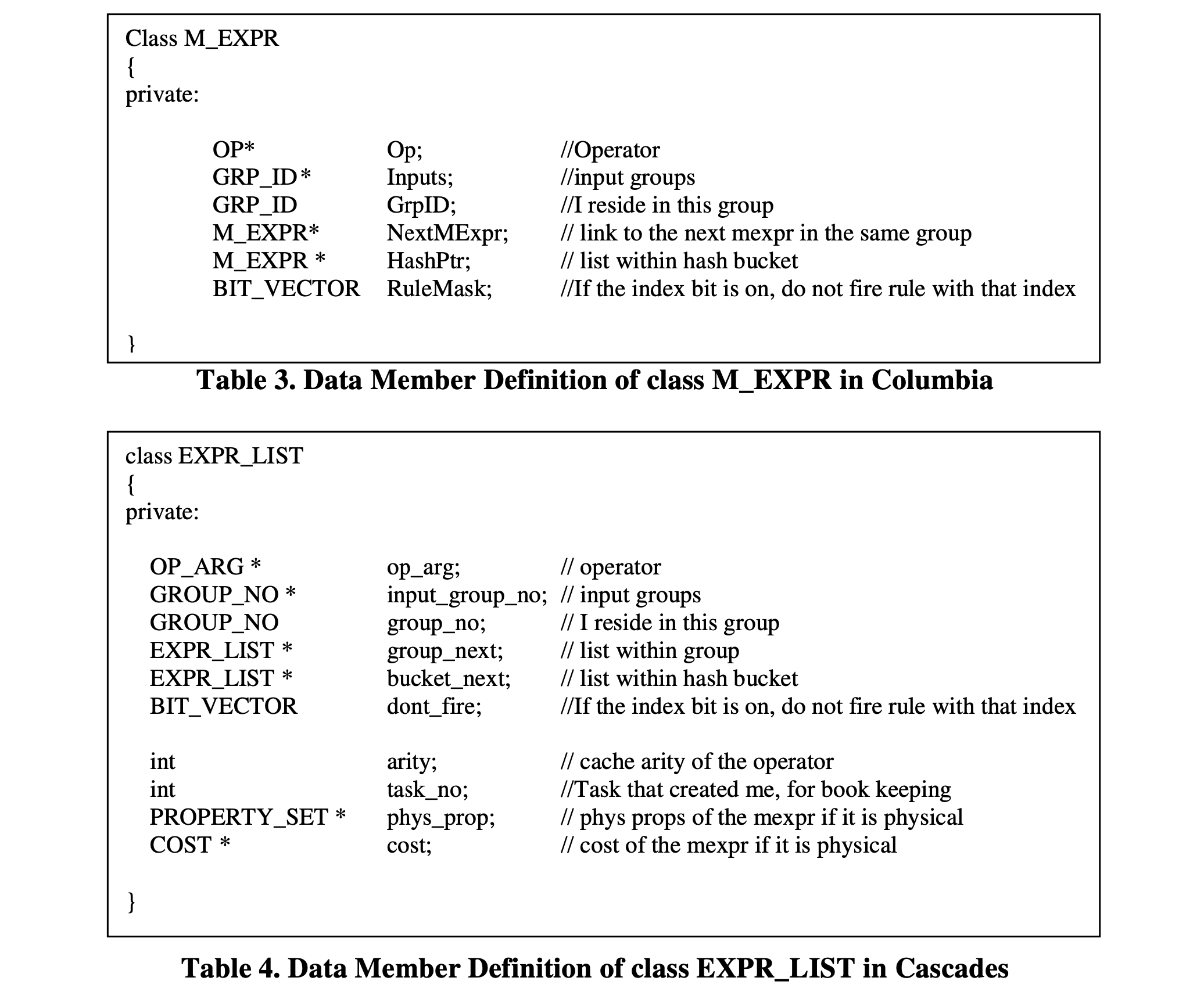
表3 表4
规则
优化搜索所遵循的规则定义在一个规则集中,该规则集与搜索结构和算法无关。规则集可以通过添加或删除一些规则来独立修改。附录C 展示了用于优化简单连接查询的简单规则集。
所有规则都是RULE类的实例,该类提供规则名称、前提条件(“pattern”)和结果(“substitute”)。pattern和substitute被表示为表达式(EXPR对象),其中包含叶子算子。叶子算子是仅在规则中使用的特殊算子。它没有输入,并且是pattern或substitute表达式树中的叶子节点。在匹配规则时,模式的叶子算子节点与任何子树匹配。例如,从左到右(LTOR)连接关联规则具有以下成员数据,其中L(i)表示叶子运算符i:
Pattern: ( L(1) join L(2) ) join L(3) Substitute: L(1) join ( L(2) join L(3) )
pattern和substitute描述了如何在搜索空间中生成新的子树。这些新的多表达式的生成由APPLY_RULE::perform()完成,分为两个部分:首先,BINDERY对象将pattern与搜索空间中的EXPR绑定;然后调用 RULE::next_substitute() 生成新的表达式,并通过 SSP::copy_in() 将其整合到搜索空间中。
类RULE中还有其他方法来方便规则的操作。方法top_match()检查规则的顶级运算符是否与当前要应用规则的表达式的顶级运算符匹配。这种顶级匹配在实际绑定规则之前进行,因此可以消除许多明显不匹配的表达式。
方法promise()用于决定应用规则的顺序,甚至可以选择不应用规则。promise() 方法根据优化上下文(例如,我们正在考虑的所需物理属性)返回规则的承诺值。因此,它是一个运行时值,并告知优化器规则可能有多大的用处。承诺值为 0 或更小表示不在此处安排该规则。较高的承诺值表示尽早安排该规则。默认情况下,实现规则的承诺值为2,其他规则的承诺值为1,表示实现规则始终较早安排。这种规则调度机制允许优化器控制搜索顺序,并通过安排规则尽快获得搜索边界,尽可能低。
Columbia 从 Cascades继承了规则机制的基本设计,但进行了几项改进,包括绑定算法和执行器的处理。接下来的章节将详细讨论这些改进。
Rule Binding
所有基于规则的优化器都必须将 pattern 绑定到搜索空间中的表达式。例如,考虑从左到右的连接关联规则,其中包括以下两个成员数据。这里的L(i)表示索引为i的LEAF_OP:
Pattern: (L(1) join L(2)) join L(3)
Substitute: L(1) join (L(2) join L(3))
每次优化器应用这个规则时,都必须将 pattern 绑定到搜索空间中的一个表达式上。一个示例绑定可以是到表达式:
( G7 join G4 ) join G10
Gi 代表 GROUP_NO i.
一个BINDERY对象(绑定器)执行识别给定pattern的所有绑定的中重要任务。在其生命周期内,BINDERY对象将产生所有这样的绑定。为了产生一个绑定,绑定器必须为每个输入子组生成一个绑定器。例如,考虑一个用于LTOR关联规则的绑定器。它将为左输入生成一个绑定器,该绑定器将寻找模式L(1) join L(2)的所有绑定,并为右输入生成一个绑定器,该绑定器将寻找模式L(3)的所有绑定。右侧绑定器只会找到一个绑定,即整个右输入组。左侧绑定器通常会找到许多绑定,每个连接在左输入组中找到一个绑定。
BINDERY对象(绑定器)有两种类型:表达式绑定器和组绑定器。表达式绑定器将模式绑定到组中的一个子树。表达式绑定器由顶部组中的规则使用,用于绑定单个表达式。组绑定器用于在输入组中生成,将绑定到组中的所有多表达式。由于Columbia及其前身仅将规则应用于逻辑子树,因此绑定器仅绑定逻辑算子。
由于搜索空间中存在大量的子树,规则绑定是一个耗时的任务。事实上,在Cascades中,找到一个绑定的BINDERY::advance()函数是优化器系统中最昂贵的函数。对规则绑定算法的任何改进都将确保优化器性能的提升。Columbia改进了BINDERY类和绑定算法,使规则绑定更加高效。
由于绑定器可能会绑定搜索空间中的多个EXPR,它将经历几个阶段,基本上是:开始,然后循环遍历几个有效的绑定,最后完成。在Columbia中,这些阶段由三个绑定状态表示,每个状态都是枚举类型BINDERY_STATE的值。以下是C++类型定义的示例:
typedef enum BINDERY_STATE
{
start, // This is a new MExpression
valid_binding, // A binding was found.
finished, // Finished with this expression
} BINDERY_STATE;在Cascades中,绑定算法使用了更多的状态来跟踪所有的绑定阶段,从而使算法变得复杂并消耗更多的CPU时间。在Cascades中,绑定阶段由六个绑定状态表示。以下是绑定状态定义的Cascades版本:
typedef enum BINDING_STATE
{
start_group, // newly created for an entire group
start_expr, // newly created for a single expression
valid_binding, // last binding was succeeded
almost_exhausted, // last binding succeeded, but no further ones
finished, // iteration through bindings is exhausted
expr_finished // current expr is finished; in advance() only
} BINDING_STATE;在Columbia中,绑定算法是在函数BINDERY::advance()中实现的,该函数由APPLY_RULE::perform()调用。绑定函数遍历嵌入在搜索空间结构中的许多树,以找到可能的绑定。遍历过程使用了一个有限状态机,如图15 所示。
由于有限状态机只有三个状态,相比Cascades中更复杂的六个状态的有限状态机,Columbia中的算法具有简单和高效的特点。此外,正如在4.2.1.3节中提到的,将逻辑和物理多表达式分为两个链接列表在Columbia中使得绑定速度更快,因为不需要跳过组中的所有物理表达式。

图15
Enforcer Rule
enforcer规则是一种特殊类型的规则,它插入物理算子以强制或保证所需的物理属性。由enforcer规则插入的物理算子称为enforcer。通常,enforcer以一个组作为输入,并输出具有不同物理属性的相同组。例如,QSORT物理运算符是一个enforcer,它在搜索空间中由一个组表示的元组集合上实现QSORT算法。SORT_RULE规则是一个enforcer规则,它将QSORT运算符插入到替代方案中。可以表示为:
Pattern: L(1)
Substitute: QSORT L(1)
Where L(i) stands for the LEAF_OP with index i.
只有当搜索上下文需要排序的物理属性时,才会触发enforcer规则。例如,在优化合并连接时,其输入的搜索上下文具有需要输入在合并连接属性上排序的必需物理属性。考虑以下多表达式:
MERGE_JOIN(A.X, B.X), G1, G2.
当我们使用自顶向下的方法优化这个子树时,首先需要对输入进行优化,并带有特定的上下文。对于左输入组G1,在搜索上下文中所需的物理属性是按A.X排序,而右输入组G2将具有按B.X排序的所需物理属性。当搜索需要排序属性时,SORT_RULE被触发,插入QSORT运算符来强制输入组具有所需的属性。
其他enforcer规则(例如HASH_RULE)也是类似的,它们强制哈希的物理属性。是否触发enforcer规则由规则对象中的promise()方法确定。如果搜索上下文具有所需的物理属性(例如排序或哈希),promise()方法将返回一个正的承诺值。如果没有所需的物理属性,则返回零承诺值,表示不会触发enforcer规则。
Cascades 和 Columbia 在处理enforcer规则方面有两个区别。
首先是排除属性。Cascades 在promise()函数中使用排除属性来确定enforcer规则的承诺值。当所需的物理属性集和排除的物理属性集都不为空时,promise()函数返回一个非零的承诺值。使用排除属性的目的是避免对一个组重复应用enforcer规则。但是,这些排除属性很难跟踪,并且使用更多的内存(需要搜索上下文包含指向排除属性的指针),还使搜索算法在处理enforcer规则时变得复杂。相反,Columbia根本不使用排除属性。上下文只包括所需的属性和上限。promise()函数仅通过所需的物理属性确定规则的承诺。为了避免重复应用enforcer规则的潜在问题,enforcer规则采用了唯一规则集技术。也就是说,每个M_EXPR中的RuleMask数据成员都有一个位用于每个enforcer规则。当一个enforcer规则被触发时,与该规则相关联的位被设置为打开状态,这意味着该enforcer规则已经对该多表达式触发过。当再次触发enforcer规则时,将检查规则掩码位,该规则将不会被重复触发。另一方面,这种简单的方法引发了一个潜在问题:如果一个组已经被优化,并且我们正在为不同的属性进行优化,由于上一次优化,多表达式中的enforcer制规则位可能已经被设置为打开状态。在这个新的优化阶段中,enforcer规则将没有机会为不同的属性触发,即使它对这个新的物理属性有很好的承诺。因此,优化器可能会对这个优化阶段给出错误的答案。解决这个问题的方法是Columbia相对于Cascades的另一个改进。下一段将讨论这个解决方案,作为与Cascades的第二个区别。
其次,enforcers 的表示方式。在Cascades中,enforcer被表示为具有一些参数的物理运算符。例如,QSORT运算符有两个参数:一个是需要排序的属性,另一个是排序顺序(升序或降序)。方法QSORT::input_reqd_prop()返回输入的不需要的物理属性和一个已排序的排除属性。它为优化多表达式向下时的输入提供了搜索上下文。实际上,enforcer是由enforcer规则生成的。在enforcer规则成功绑定到表达式后,将调用方法 RULE::next_substitute() 来生成一个插入了enforcer的新表达式。enforcer的参数根据搜索上下文的所需物理属性生成。例如,如果搜索上下文具有在属性<A.X, A.Y>上排序的所需物理属性,生成的enforcer将是一个带有参数<A.X, A.Y>的QSORT,表示为QSORT(<A.X, A.Y>)。这个带有enforcer的新表达式将被包含在搜索空间中与“之前”表达式相同的组中。由于enforcer具有参数,具有相同名称但不同参数的enforcer被视为不同的enforcer。从这个例子可以看出,如果搜索具有许多不同的所需物理属性,例如在不同的属性上排序,那么在搜索空间的一个组中可能会有许多具有相同名称但不同参数的enforcer。这可能是一种潜在的浪费。
在Columbia中,enforcer被表示为没有任何参数的物理运算符。例如,QSORTenforcer被表示为QSORT(),不包含任何参数。在整个优化过程中,只会生成一个QSORT运算符并将其包含在一个组中,因为在第一次SORT_RULE被触发后,表达式中的相应规则位被设置为打开状态,阻止了未来的SORT_RULE应用。这种方法是安全的,因为我们假设对输入流进行排序的成本与排序键无关。以下是Columbia优化器的工作原理:如果一个组已经针对某个属性进行了优化,那么一个enforcer算子将被添加到该组中。现在我们要为不同的属性进行优化,那么相同的enforcer将不会生成,因为相应的规则位已经被设置。因此,enforcer规则将不会被触发。另一方面,将检查组中的所有物理多表达式(包括enforcer算子),以查看是否满足所需的属性,并在新的上下文中直接计算成本,使用新的所需物理属性。由于enforcer没有参数,它满足新的物理属性,因此该enforcer算子的成本将在新的物理属性下计算出来。如果enforcer多表达式成为某个物理属性的优胜者,它和物理属性将被存储在优胜者结构中,就像普通的多表达式优胜者一样。
当优化器要复制最优计划时,enforcer优胜者需要进行特殊处理,即根据相应的所需物理属性将参数附加到它们上,因为实际的enforcer实现需要参数。例如,假设enforcer多表达式“QSORT(), G1”是物理属性“按A.X排序”的优胜者。当我们复制这个优胜者时,实际的计划是“QSORT(A.X), G1”,它附加了实际的参数到enforcer上。
任务 -- 搜索算法
任务是搜索过程中的活动。最初的任务是优化整个查询。任务之间相互创建和调度;当没有未完成的任务时,优化过程终止。每个任务与特定的上下文相关联,并且具有一个名为“perform()”的方法,用于实际执行任务。类TASK是一个抽象类,从中继承了具体的任务。它包含一个指向上下文的指针,创建该任务的父任务编号,以及一个需要在子类中实现的纯虚函数“perform()”。类PTASKS包含一组未完成的任务,需要进行调度和执行。PTASKS当前实现为堆栈结构,具有“pop()”方法用于移除要执行的任务,以及“push()”方法用于将任务存储到堆栈结构中。在优化开始时,创建一个PTASKS对象“PTasks”,并将优化顶级组的原始任务推入PTasks中。当优化开始时,原始任务被弹出,并调用任务中的perform()方法开始实际优化。优化过程将创建后续任务,并将其推入PTasks中进行进一步调度。图16显示了主要优化过程的伪代码。通过使用抽象类,我们可以看到实现了简单而清晰的编程结构。

图16
整个搜索算法由优化器中的所有特定任务执行。Columbia中的任务包括:组优化(O_GROUP)、组探索(E_GROUP)、表达式优化(O_EXPR)、输入优化(O_INPUTS)和规则应用(APPLY_RULE)。图17 显示了这些任务之间的关系。箭头表示哪种类型的任务调度(调用)了其他类型的任务。本节的其余部分将详细描述每个任务在Columbia中的实现。在每个任务的描述中,将与Cascades进行比较讨论。
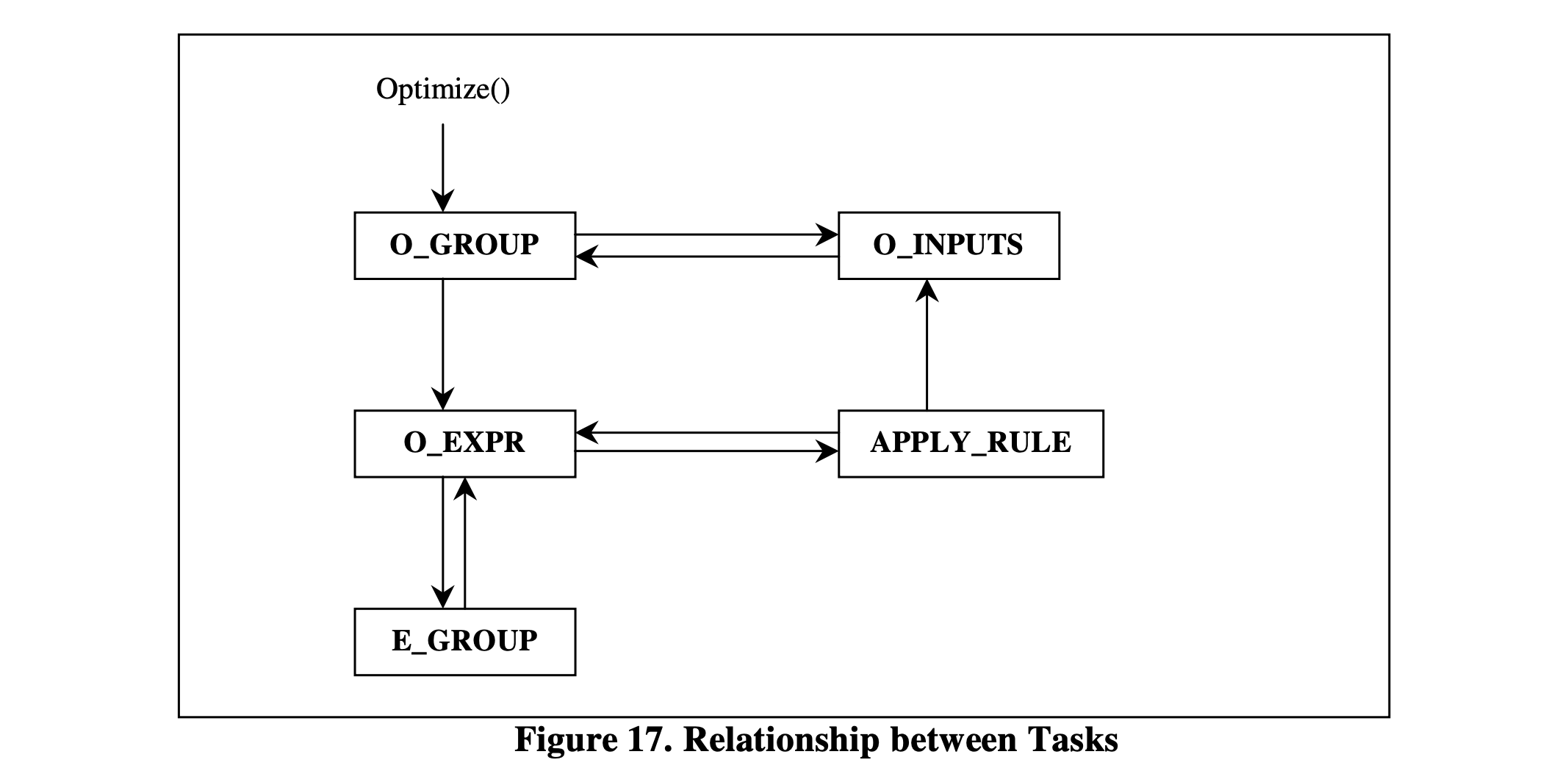
图17
O_GROUP - 优化分组的任务
这个任务在给定一组上下文的情况下,找到该组中最低成本的计划,并将其(以及上下文)存储在组的优胜者结构中。如果没有最便宜的计划(例如,无法满足上限),则将具有空计划的上下文存储在优胜者结构中。该任务生成组中所有相关的逻辑和物理表达式,对所有物理表达式进行成本估算,并选择最低成本的一个。O_GROUP任务还创建了另外两种类型的任务来生成和优化组中的表达式:O_EXPR 和 O_INPUTS。
该任务使用动态规划和记忆化技术。在开始优化组中的所有表达式之前,它会检查是否已经追求过相同的优化目标(即相同的搜索上下文);如果是,则直接返回之前搜索中找到的计划。重用先前推导出的计划是动态规划和记忆化的关键方面。

图18
如图18所示,将组中的逻辑和物理多表达式分离有助于该任务的搜索过程。
执行 O_GROUP 任务有两种情况。 首先,第一次优化一个组(即为一个上下文搜索组):在这种情况下,组中只有一个逻辑子树(初始子树)。根据该算法,只会创建一个任务,即O_EXPR初始子树,并将其推入任务栈中,该任务将通过应用规则生成其他表达式。
第二种情况是在不同上下文下优化一个组,例如不同的所需物理属性:在这种情况下,该组已经进行了优化,可能已经有一些优胜者。因此,组中可能有多个逻辑和物理子树。需要做两件事:
- 1. 我们需要对每个逻辑多表达式使用新的上下文执行 O_EXPR。因为在新的上下文下,一些规则集中不能应用于多表达式的规则变得可应用。由于独特的规则集技术,我们不会重复触发同一规则,从而避免生成重复的多表达式到组中;
- 2. 我们需要对每个物理多表达式使用新的上下文执行 O_INPUTS,以计算物理多表达式的成本,并在可能的情况下为该上下文生成一个优胜者。
在 Cascades 中,优化组的任务不涉及物理子树。对于组中的所有逻辑子树,该任务为每个逻辑子树创建并压入O_EXPR任务。然后生成所有物理子树并计算成本。在第二次优化组的情况下,所有物理子树将再次生成,以在不同上下文下进行成本计算。由于所有逻辑和物理多表达式都存储在一个链表中,这种方法必须跳过组中的所有物理多表达式。从这个比较可以看出,Columbia中优化组的算法比Cascades更高效。
E_GROUP - 扩展分组的任务
有些规则要求它们的输入包含特定的目标算子,通常是逻辑算子。例如,连接关联性规则要求其中一个输入必须是连接操作符。考虑连接的左关联性规则。当多表达式中的连接操作符与规则中的顶级连接操作符匹配时,必须展开多表达式的左输入组,以查看组中是否存在连接,因为规则要求左输入必须是连接。并且组中的所有连接操作符应与规则中的左连接匹配。
E_GROUP任务通过创建可能属于组的所有目标逻辑运算符来扩展组,例如,触发必要的规则以创建可能属于连接组的所有连接。此任务仅在根据规则的模式需要进行探索时按需调用。它由O_EXPR任务在必要时创建和调度。

图19
在这里也使用了动态规划来避免重复工作。在探索组的表达式之前,任务会检查该组是否已经被探索过。如果是,则任务立即终止,而不会生成其他任务。当需要进行探索时,任务为每个逻辑多表达式调用一个带有“exploring”标志的O_EXPR任务,以通知O_EXPR任务仅对表达式进行探索,即仅对表达式触发转换规则。
在Cascades中,E_GROUP任务会生成另一种类型的任务,即E_EXPR任务,用于探索多表达式。由于E_EXPR具有与O_EXPR类似的操作,Columbia没有E_EXPR任务。相反,Columbia只是使用一个标志来指示任务的目的,从而重用O_EXPR任务。
O_EXPR - 子树优化的任务
在Columbia中,O_EXPR任务有两个目的:一个是优化子树。该任务按照承诺的顺序触发规则集中的所有规则,对多表达式进行优化。在这个任务中,转换规则被触发以扩展表达式,生成新的逻辑子树;而实现规则被触发以生成相应的物理子树。O_EXPR的另一个目的是探索子树以准备规则匹配。在这种情况下,只触发转换规则,并且只生成新的逻辑子树。与O_EXPR任务相关联的有一个标志,指示任务的目的。默认情况下,标志设置为“优化”,因为O_EXPR任务主要用于优化表达式。如果任务用于探索,特别是由E_GROUP任务生成的,标志设置为“探索”。
图20 展示了O_EXPR任务的算法,该算法在O_EXPR::perform()方法中实现。在O_EXPR::perform()方法中,优化器决定将哪些规则压入PTASK堆栈。请注意,在扩展并与规则的模式进行匹配之前,会评估规则的承诺,并使用承诺值来决定是否扩展这些输入。

图20
在Columbia和Cascades中,优化多表达式的算法没有太大的区别,除了Columbia重用O_EXPR任务来探索多表达式。在Cascades中,使用了一种新的任务类型“E_EXPR”来进行探索。
APPLY_RULE - 子树应用规则的任务
在Columbia和Cascades中,应用规则的算法没有区别。规则仅适用于逻辑表达式。APPLY_RULE是将规则应用于逻辑多表达式并将新的逻辑或物理多表达式生成到搜索空间中的任务。给定一个规则和一个逻辑多表达式,该任务确定搜索空间中当前可用的表达式与规则的模式绑定,然后应用规则并将新的替代表达式包含到搜索空间中。如果生成的是逻辑多表达式,则进一步优化进行进一步的转换;如果生成的是物理子树,则计算其成本。
图21 展示了APPLY_RULE任务的算法,该算法由APPLY_RULE::perform()方法实现。这个算法在Columbia中与Cascades中的算法是相同的。
在找到绑定之后,会调用RULE::condition()方法来确定规则是否实际适用于表达式。例如,将选择操作符推到连接操作符下面的规则需要关于模式兼容性的条件。这个条件只能在绑定之后检查,因为输入组的模式只有在绑定之后才可用。
在将规则应用于多表达式之后,必须设置多表达式中相应的规则位,以便下次不再将相同的规则应用于该多表达式,从而避免重复工作。

图21
O_INPUTS - 优化输入并输出表达式成本的任务
在优化过程中,当应用了一个实现规则时,即在查询树中的一个节点考虑了一个实现算法,优化会继续通过优化每个输入来进行。任务O_INPUTS的目标是计算物理子树的成本。它首先计算子树的输入的成本,然后将它们加到顶部算子的成本中。类O_INPUTS中的成员数据input_no,初始值为0,指示已计算成本的输入。这个任务与其他任务不同之处在于,在调度其他任务后它不会终止。它首先将自身推入堆栈,然后安排下一个输入的优化。当所有输入都计算完毕后,它计算整个物理多表达式的成本。
这个任务是Columbia修剪技术的主要任务,详细讨论在第4.3节中。基于Cascades中的相同任务,Columbia中的O_INPUTS重新设计了算法,并添加了与修剪相关的逻辑,以实现Columbia中的新修剪技术。
图22 展示了O_INPUTS_perform()方法的伪代码,该方法实现了任务O_INPUTS的算法。
NOT A TION:
G: the group being optimized.
IG: various inputs to expressions in G.
GLB: the Group Lower Bound of an input group, stored as a data member of the group.
Full winner: a winner whose plan is non-null.
InputCost[]: contains actual (or lower bound) costs of optimal inputs to G. LocalCost: cost of the top operator being optimized.
CostSoFar: LocalCost + sum of all InputCost[] entries.

图22
算法中有三个修剪标志:Pruning、CuCardPruning和 Glob-eps-Pruning。优化器的用户可以根据需要设置这些标志,以在Columbia中尝试不同的修剪技术。
有四种情况可以对Columbia运行基准测试。O_INPUTS算法使用不同的逻辑处理这四种情况。在Cascades中,只处理了情况1和2。
- Starburst - [!Pruning && !CuCardPruning]:不应用修剪,为输入组生成所有表达式,即彻底展开输入组。
- 简单修剪 - [Pruning && !CuCardPruning]:通过始终积极检查限制条件来尽量避免输入组的展开,即如果在表达式优化过程中的 CostSoFar 大于优化上下文的上界,任务将被终止,不再进行进一步优化。在这种情况下,InputCost[]条目仅存储输入的获胜成本,如果输入对于优化上下文有一个获胜者。
- 下界修剪 - [CuCardPruning]:尽量避免输入组的展开。与简单修剪的区别在于:如果一个输入组没有获胜者,它会将输入组的GLB存储在InputCost[]条目中。这种情况假设Pruning标志为开启状态,即如果CuCardPruning为真,则强制Pruning标志为真。
- 全局 Epsilon 修剪 - [GlobepsPruning]:如果一个计划的成本低于全局epsilon值(GLOBAL_EPS),则被视为G的最终获胜者,因此不需要进一步优化(即任务被终止)。该标志独立于其他标志,可以与其他三种情况结合在优化中使用。
剪枝方法
在本节中,讨论了 Columbia 中的两种修剪技术。它们扩展了Cascades的搜索算法,并通过有效地修剪搜索空间来提高搜索性能。正如我们从第4.2.3.5节中可以看到的那样,这些修剪技术主要是在任务O_INPUTS中实现的。
下界组修剪
动机:自顶向下的优化器在生成某些较低级别的计划之前,会为高级物理计划计算成本。这些早期成本作为后续优化的上界。在许多情况下,这些上界可以用来避免生成整个表达式组。我们称之为组修剪。
由于Columbia是自顶向下搜索并进行记忆化,上界可以用来修剪整个组。例如,假设优化器的输入是(A~B)~C。优化器首先计算组[ABC]中的一个计划的成本,比如(A~LB)~LC;假设其成本为5秒。在计算这个5秒成本时,它扩展了组[AB],但没有考虑组[AC]或[BC]。现在我们正在考虑优化组中的另一个表达式,比如[AC]~L[B]。假设组[AC]表示一个笛卡尔积,它非常庞大,仅将元组从[AC]复制到[ABC]就需要超过5秒的时间。这意味着包含[AC]的计划永远不会成为[ABC]的最优计划。在这种情况下,优化器不会生成(实际上修剪)组[AC]中的所有计划。图23 展示了上述两个表达式优化后的搜索空间内容。请注意,组[AC]没有被展开。另一方面,Starburst和其他自底向上的优化器在开始处理[ABC]之前会优化组[AB]、[AC]和[BC],从而失去了修剪多个计划的机会。
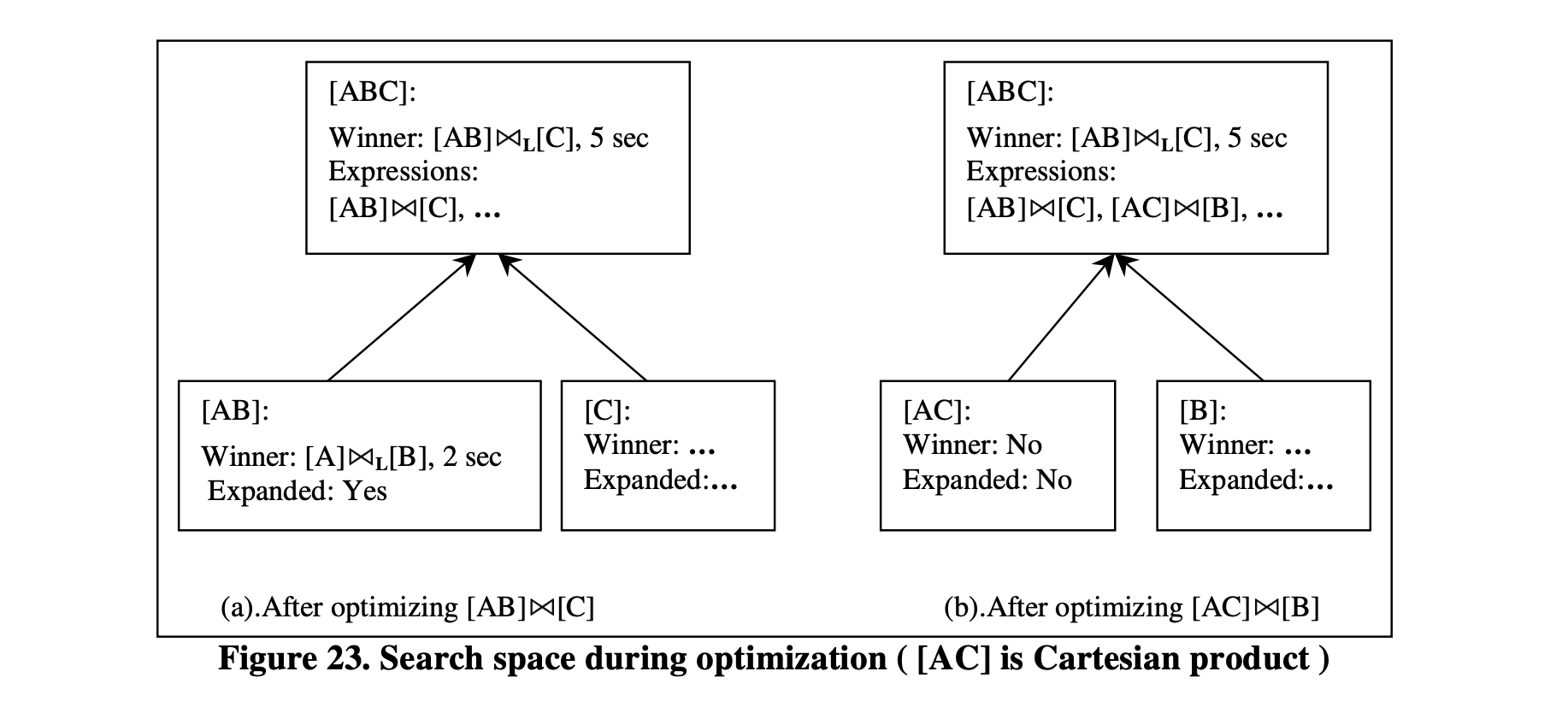
图23
如果一个最优化组G从未被枚举,我们称其为被修剪的。因此,被修剪的组只包含一个表达式,即创建它的表达式。组修剪可以非常有效:表示k个表的连接的组可以包含2k-2个逻辑表达式。而在一个组中,物理表达式通常比逻辑表达式多两倍以上。
算法:在本节中,我们将描述Columbia如何通过改进的优化算法增加实现组修剪的可能性,该算法在图24 中展示。这个算法是任务 O_INPUTS(第4.2.3.5节)的一部分,并且是图22中“Note1”行的详细描述。

图24
在图24 中,第(1)-(4)行计算了Expr的成本下界。如果这个下界大于当前的上界Limit,那么该过程可以返回而不需要枚举任何输入组。这个算法与Cascades的算法的区别在于,Cascades的算法中没有第(4)行。
在Columbia中,与一个组相关联的组下界表示复制组的元组和从组的表中获取元组的最小成本(详见第4.1.2.3节)。这个组下界在优化表达式之前计算并存储在组中,因为它仅基于组的逻辑属性。第(4)行包括没有满足所需属性的最优计划的输入的组下界,从而改进了Expr的成本下界,进而增加了组修剪的可能性。
图25 展示了发生组下界修剪时的情况。在这种情况下,Cascades的算法不会修剪组[BC],因为正在优化的表达式的下界成本仅为运算符成本和输入的获胜成本(如果有的话)的总和。在这种情况下,它等于1+2+0=3,并且不大于上下文中的上界。组[BC]仍然会被展开。
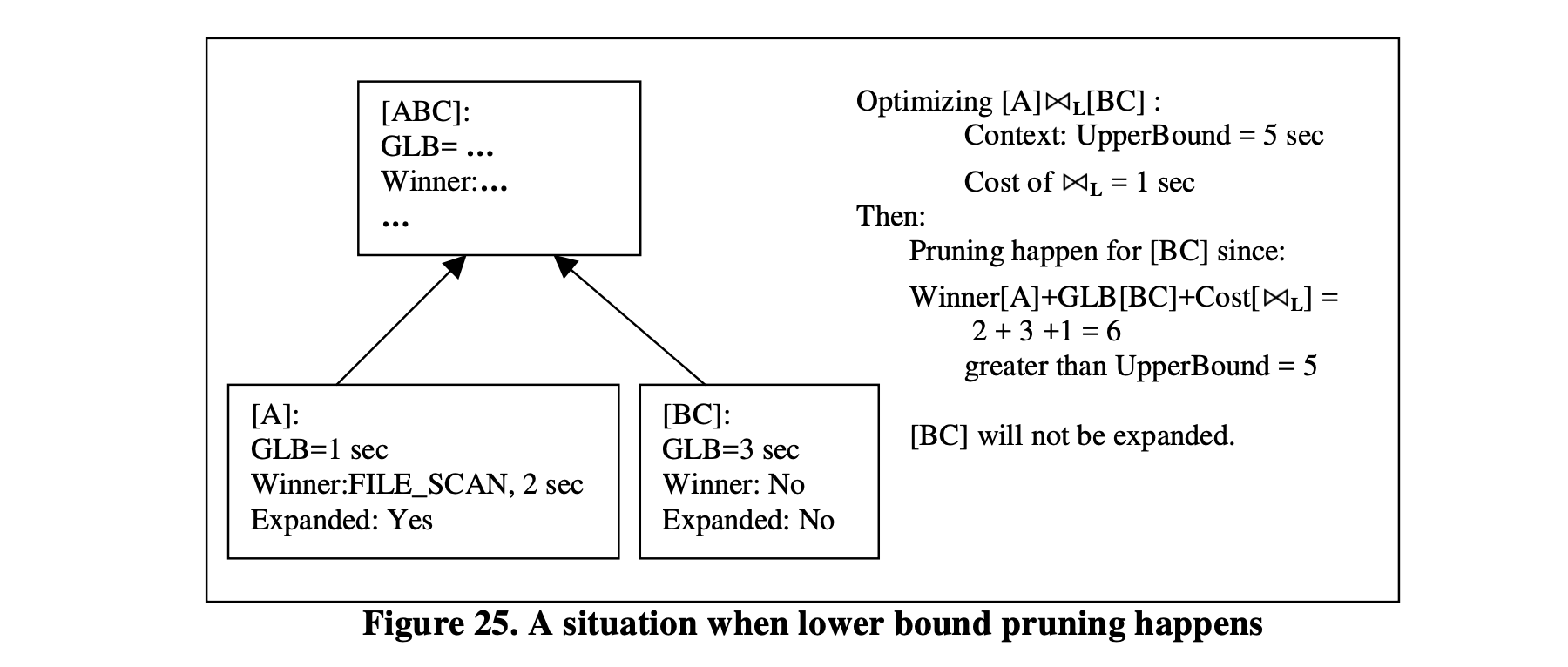
图25
下界组修剪是安全的,也就是说,使用这种修剪技术的优化器会生成最优计划。因为我们只会在一个计划的下界成本大于另一个计划的成本时修剪一组计划,并且我们在第4.1.2.3节中证明了我们使用的下界是一个下界。
全局Epsilon修剪
动机:满足性的概念起源于经济学。理论上,经济系统受到要求每个人在满足一些约束条件的前提下优化满足度的法律的支配。实际上,人们并不总是按照这种方式行事:他们会接受几乎最优的解决方案,几乎满足约束条件。这种行为被称为满足性。一种理解满足性的方式是想象存在某个常数epsilon,所有的优化/满足都在epsilon范围内进行。满足性的概念是以下思想的动机。
全局Epsilon修剪:如果一个计划的成本与最优计划的成本足够接近(在epsilon范围内),则将其视为组的最终获胜者。一旦宣布了这样的获胜者,对于该组就不再需要进一步优化,因此可能修剪搜索空间。例如,假设我们正在优化组[ABC],我们将计算在该组中获得的第一个计划的成本,比如(A~LB)~LC,成本为5秒。如果我们选择的epsilon是6秒,即我们认为小于6秒的计划是最终获胜者。虽然它不是最优的,但我们对它感到满意。因此,成本为5秒的计划(A~LB)~LC被视为组[ABC]的最终获胜者,因此不再对组[ABC]进行进一步搜索。换句话说,对于[ABC]的搜索已经完成,即使我们甚至没有展开组[ABC]。通过这种方法,搜索空间中的许多表达式被修剪掉。
这种修剪技术被称为全局Epsilon修剪,因为epsilon在整个优化过程中被全局使用,而不是局限于特定的组优化。
算法:选择一个全局参数Globeps > 0。按照通常的优化算法进行操作,只是在一个组中,如果找到一个成本小于Globeps的计划,则宣布其为最终获胜者。将获胜者输入到组中,并标记搜索上下文为完成,表示该组不需要进一步搜索。
cost(plan) < Globeps.
这个算法在任务O_INPUTS中实现,如图22中的“Note2”所示。在计算优化表达式的成本之后,如果设置了全局epsilon修剪标志,就会将成本与全局epsilon进行比较。如果成本小于epsilon,则搜索完成。 显然,全局Epsilon修剪不能得到最优计划。但是,从绝对最优性的距离在某种意义上是有界的。
定理:设“absolute-optimum”表示通常优化的结果,“Globeps-optimum”表示使用全局Epsilon修剪进行优化的结果。如果absolute-optimum具有成本小于Globeps的N个节点,则Globeps-optimum的成本与absolute-optimum的成本之间的差异最多为 N * Globeps。
证明:首先对absolute-optimum执行深度优先搜索,但使用全局Epsilon修剪来替换每个最优输入,用第一个成本小于Globeps的计划来替换,如果存在这样的计划。将替换N个最优输入。将此过程的结果称为P。由于P与absolute-optimum在最多N个输入上的差异最多为Globeps,我们有 cost(P) - cost(absolute-optimum) < N * Globeps。 由于P在全局Epsilon修剪算法定义的搜索空间中,我们必须有 Cost (Globeps-optimum) < cost(P)。定理得证。
不同的epsilon会极大地影响修剪效果。非常小的epsilon将不会进行任何修剪,因为组中所有计划的成本都大于epsilon。另一方面,较大的epsilon将修剪掉大量计划,但可能会得到一个远离最优计划的计划。由于这种修剪技术在很大程度上依赖于我们选择的epsilon,上述定理给了我们选择epsilon的一个思路。例如,假设我们想要优化一个由10个表连接而成的查询。我们估计这个连接的最优计划的成本为100秒,最优计划有20个节点。我们还假设与最优计划相差10秒的计划是可以接受的。根据定理,我们可以得到一个Globeps-optimum计划,其成本与最优成本之间的差异最多为20 * Globeps = 10,这是可以接受的。因此,我们可以选择全局epsilon为0.5
附录

附录A
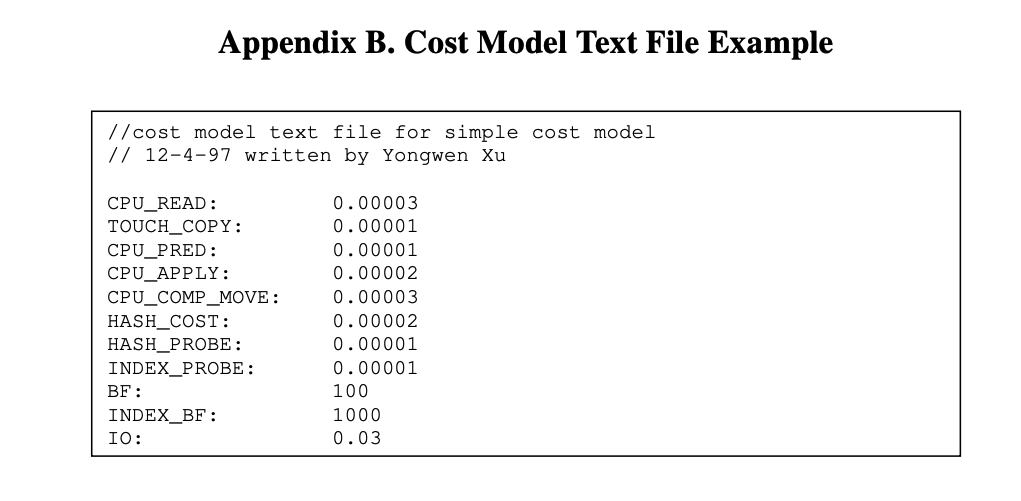
附录B

附录C
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号