Yelp 的 Apache Cassandra 集群重建解决方案

Yelp 的 Apache Cassandra 集群重建解决方案

深度学习与Python
发布于 2023-09-08 13:54:48
发布于 2023-09-08 13:54:48
译者 | 明知山
策划 | 丁晓昀
Yelp 构建了一个解决方案,利用其数据流架构来清理来自已损坏的 Apache Cassandra 集群的数据。提供解决方案的团队探索了许多可能的选项来解决数据损坏问题,但最终不得不将数据转移到一个新的集群中,以便在转移过程中移除损坏的记录。
Yelp 将 Apache Cassandra 作为其平台许多组件的数据存储系统,他们根据数据、流量和业务需求为特定的场景提供了许多较小的 Cassandra 集群。最初,Cassandra 集群直接托管在 EC2 上,但最近,他们通过一个专门的 Operator 将大多数集群转移到 Kubernetes 上。
团队发现,一个在 EC2 上运行的 Cassandra 集群受到了损坏的数据的影响,常规数据维护工具无法解决这个问题。随着时间的推移,情况变得越来越糟,甚至进一步影响集群的运行。
Yelp 软件工程师 Muhammad Junaid Muzammil 解释了选择重建损坏的 Cassandra 集群的原因:
由于数据损坏的情况很普遍,删除 SSTable 并进行修复并不是一种好的选择,因为它会导致数据丢失。此外,根据对损坏数据多少的估计和最近的数据值,我们选择不将集群恢复到上次无损坏的备份状态。
团队选择的设计方案的灵感来自于制造业中使用的分拣系统,这种系统会逐步消除到达生产线末端的缺陷产品。他们使用他们的 PaaStorm 流式处理器和 Cassandra Source 连接器(该连接器基于变更数据捕获(CDC)功能,该功能在 Cassandra 3.8 版本中可用)创建了一个数据管道。
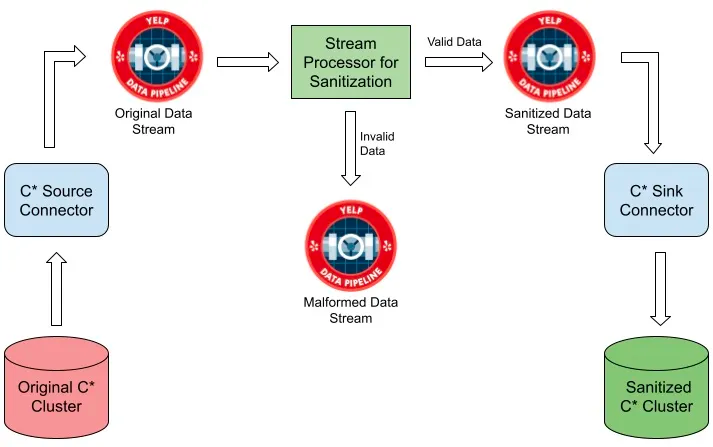
受损数据迁移管道架构视图(来源:https://engineeringblog.yelp.com/2023/01/rebuilding-a-cassandra-cluster-using-yelps-data-pipeline.html)
得益于硬件和软件升级方面的好处,数据基础设施团队在 Kubernetes 上创建了一个新的 Cassandra 集群。数据管道使用 Stream SQL 处理器来定义数据卫生标准,将数据分割为有效的数据流和受损的数据流。管道使用 Cassandra Sink Connector 将经过处理的数据流送入新的 Cassandra 集群。受损的数据流被进一步分析,以便获取数据损坏的严重程度。
团队使用统计抽样技术来验证整个数据迁移过程,通过比较导入到新集群的数据和旧集群中的数据来检查一小部分数据。
在将流量切换到新集群之前,团队通过一个设置将读取请求同时发送到两个集群,并比较返回的数据。他们对记录的结果进行分析,估计旧集群中有 0.009% 的数据损坏。最后,流量被无缝地切换到新集群,损坏的集群被拆除。
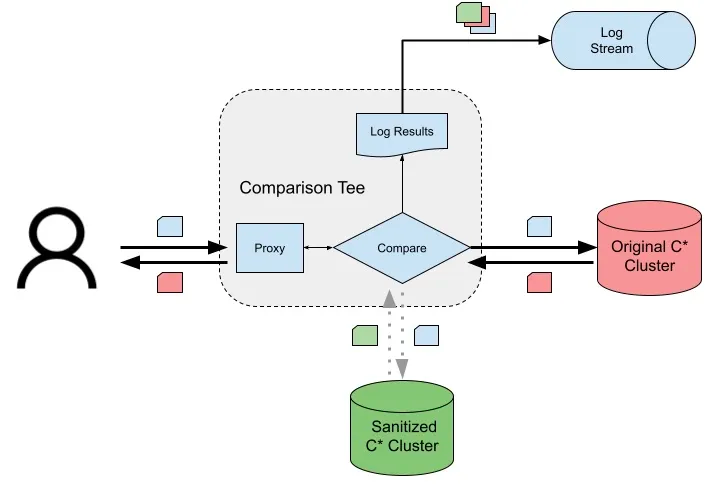
读取请求的数据验证(来源:https://engineeringblog.yelp.com/2023/01/rebuilding-a-cassandra-cluster-using-yelps-data-pipeline.html)
原文链接:
https://www.infoq.com/news/2023/07/yelp-corrupted-cassandra-rebuild/
声明:本文由 InfoQ 翻译,未经许可禁止转载。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号