【干货】介绍Python中的模块,轻松将PDF转换成docx

【干货】介绍Python中的模块,轻松将PDF转换成docx

用户6888863
发布于 2023-09-06 13:15:12
发布于 2023-09-06 13:15:12
可将 PDF 转换成 docx 文件的 Python 库。该项目通过 PyMuPDF 库提取 PDF 文件中的数据,然后采用 python-docx 库解析内容的布局、段落、图片、表格等,最后自动生成 docx 文件。
pdf2docx功能
pdf2docx 同时解析出了表格内容和样式,因此也可以作为一个表格内容提取工具。
限制
- 目前暂不支持扫描PDF文字识别
- 仅支持从左向右书写的语言(因此不支持阿拉伯语)
- 不支持旋转的文字
- 基于规则的解析无法保证100%还原PDF样式
安装
pip install pdf2docx
案例
from pdf2docx import parse
pdf_file = '/path/to/sample.pdf'
docx_file = 'path/to/sample.docx'
# convert pdf to docx
parse(pdf_file, docx_file)
output
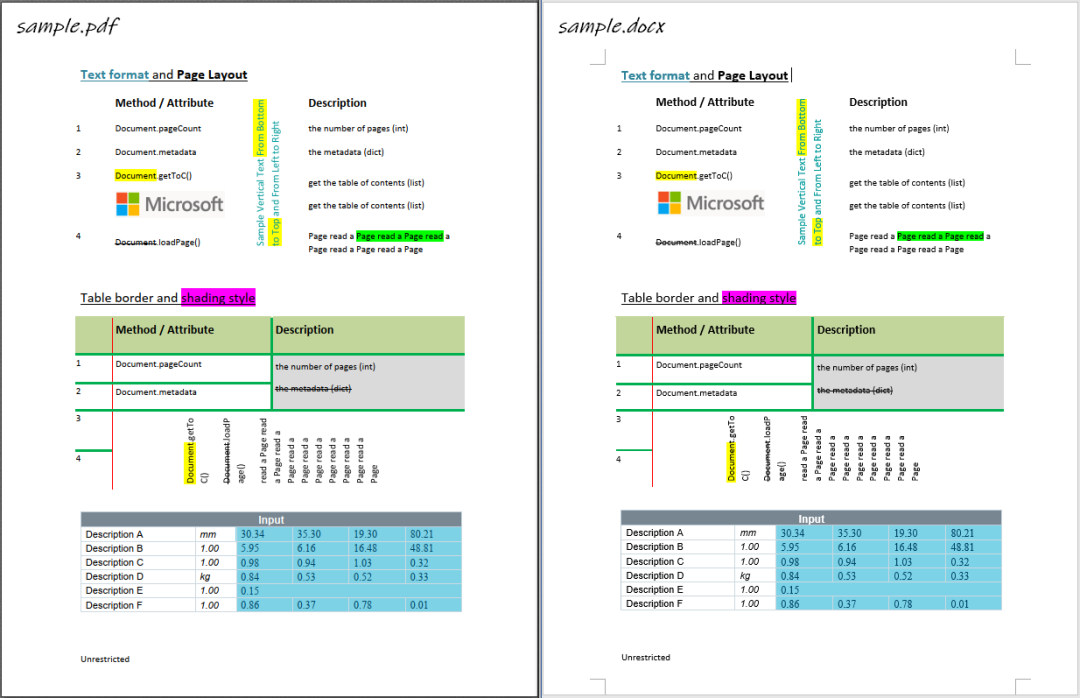
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-07-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号