Kylin4 在有赞业务场景下的深度实践

Kylin4 在有赞业务场景下的深度实践

有赞coder
发布于 2023-09-06 11:29:23
发布于 2023-09-06 11:29:23

作者:李闯、家龙、世鑫
部门:数据中台
一、Kylin4 在有赞现有业务场景的应用
早在 2018 年有赞引入 Kylin 到现在,有赞已经使用 Kylin 五年的时间了,作为 Kylin4 最早的一批使用用户,亲自参与见证了 Kylin4 的逐渐成熟,同时 Kylin4 在 2021 年在有赞正式落地,并且将所有的线上业务都迁移到了 Kylin4。
目前 Kylin 在有赞的应用几乎覆盖了有赞的所有的业务板块,Kylin 在有赞的多模块应用场景如下图:

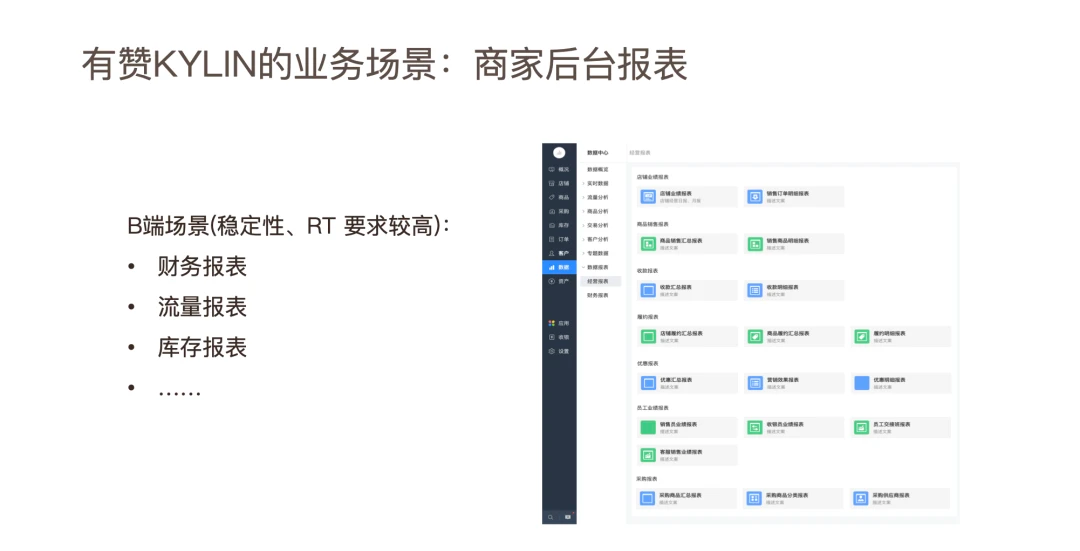
重点的应用场景主要包括商家后台,客户增长分析等场景:下图为有赞商家后台功能,右侧是有赞商家后台,包括财务报表、流量报表、库存报表、履约、供应链、优惠等营销相关的报表,涉及多个对外场景,是 SaaS 服务的一部分,每天有大量商家关注这些报表数据,因此对 RT 和稳定性的要求非常高的。
二、目前业务场景下存在的一些痛点
Kylin4是基于Spark构建的,相比之前版本在查询性能和稳定性方面都有了很大的提升。然而,在有赞的一些场景下,仍然存在一些稳定性问题。此外,由于用户使用的复杂性,他们希望获得更多关于现有功能使用的建议,并希望Kylin能够支持提供更丰富的功能来进行开发提效。
用户使用体验:
在有赞的业务场景下,由于历史数据变更或新增指标等情况,可能需要重新构建 cube 或者刷新已有的 cube。而且无论重新构建还是刷数都会是一个比较大时间范围,这个过程通常需要较长的时间,不建议将一个大范围构建成一个 segment。因此,用户希望Kylin 能够提供批量构建和刷数的功能,可以实现给定大的时间范围自动划分 segment 进行 build 或refresh。同时,用户也希望能够查询指定时间范围内的segment是否有效和是否已经构建完成。
此外,用户还提到了查询缓存的问题。当前 Kylin 的查询缓存是单点缓存的,导致有时候会出现"连续两次查相同的 SQL 第二次应该会很快,为什么第二次查询相同的 SQL 依然很慢?"的疑问。
稳定性:
在稳定性方面,有赞集群查询节点常常出现瞬间 CPU 飙高的问题,这已经影响到了集群的稳定性。同时,Kylin层面没有很好的手段对业务查询进行限制,存在一个 cube 可能会被多个业务方使用,其中任意一个业务方的大量查询都可能导致磁盘 I/O过 高等问题,从而影响到其他关于该Cube的查询。
由于高并发查询导致集群不稳定、查询堆积、RT 过高等问题,每周一都会告警,扩容是一个办法,但并不是最佳解决方法。因此,Kylin需要进一步优化性能和稳定性,并提供更丰富的功能和工具来帮助用户更好地使用该平台。
三、针对上述痛点的一些优化
3.1 功能及稳定性优化
3.1.1 支持Cube segment 批量构建和重刷的功能
为了满足用户重刷或者重构数据的需求,设计了一个批量构建的功能,可以用户在Kylin 的 web ui 界面进行批量构建或者重刷。同时考虑到功能做完善,批量刷数功能特点主要应该包括以下几点:
- 支持 segment 划分粒度配置:可以选择按照自然月划分segment刷数或者按照 Cube 的 Merge interval 划分 segment,用户可以根据实际需求进行选择。
- 支持多种操作类型,BUILD、REFRESH、BUILD_OR_REFRESH,三种操作类型的功能介绍:
BUILD:批量构建,按照划分周期对指定的时间范围划分多个 segment 进行 build。REFRESH:批量重刷,判断 cube 下所有 ready 的 segment 中与指定时间范围存在重叠的 segment 进行 refresh。BUILD_OR_REFRESH: 批量构建或者重刷,当用户想批量构建一个大的时间范围的 segment 时,如果在范围内存在重叠的多个零散的 segment (比如临时进行刷了某一天的数据等),可能会导致无法批量构建(这里的规则是如果有重叠但是不是包含关系的话会报错)。因此提供一个批量构建或者刷数功能,如果选定时间范围内的存在重叠的 segment 进行 refresh 操作,如果是不存在的进行 build
- 支持低优先级的构建并发限制:为了防止批量刷数占用过多的集群资源,我们支持构建任务的优先级的并发控制配置,正常的批量构建或者刷数的行为会默认设置为低优先级,对于低优先级我们会控制并行度,同时控制 spark 的max executor 数量实现资源控制,防止批量构建或者刷数的任务影响到其他的高优先级任务。
- 支持构建完成后的空缺 segment 检测:提供了指定时间范围内 ready 状态的缺失 segment 检测的 api,方便用户在批量构建或者刷数后的判断是否都有的 segment 都构建成功,也可以用于平时进行指定时间范围内的 segment 的有效性检测。
下面是功能完成够的用户在 Kylin web ui 界面的功能使用图:
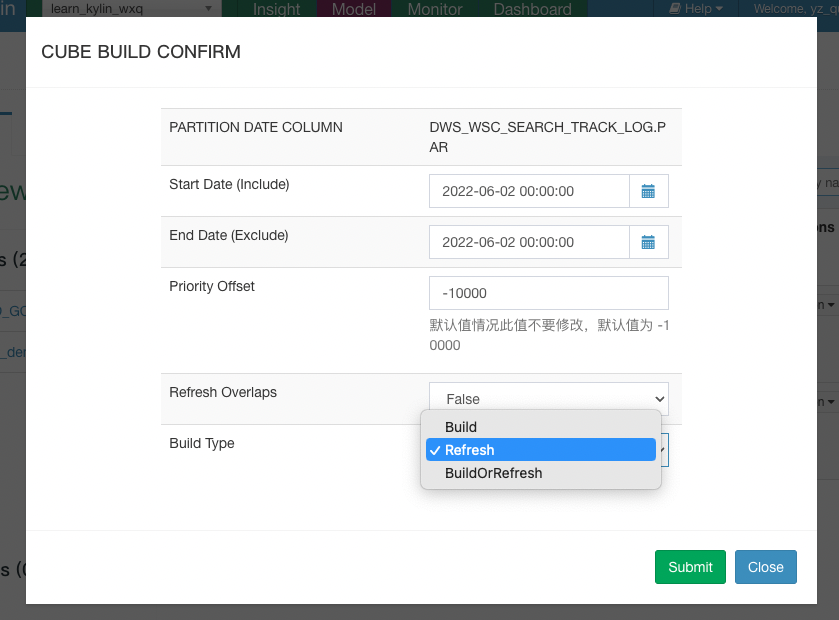
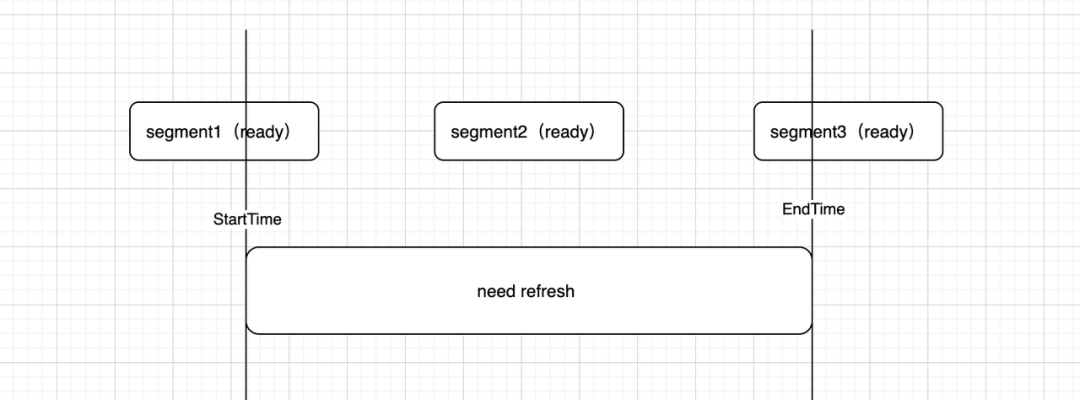
其中 priority offset 表示任务的优先级,这个是为了控制批量刷数任务的使用资源和并发度,默认不会让用户修改;Refresh Overlaps 这个参数表示在进行 Refresh 时是否重刷部分重叠的 segment。如下图所示 Refresh Overlaps 为false 时只会重刷 segment2,Refresh Overlaps为 true 时会重刷 segment1、segment2 和 segment3,通过该参数用户可以更灵活的决定自己重刷的策略。
3.1.2 基于 Cube 级别的查询限流,支持SQL正则匹配限流
Kylin 暂时没有 Cube 级别的限流,没有办法保证 Kylin 查询节点的稳定性。为了保证 Kylin 集群的稳定性,设计出的基于 Cube 级别的 SQL 查询限流功能主要包括以下几方面的功能:
- 基于 Cube 级别的限流,支持 Cube 动态配置限流阈值
- 支持 SQL 通过正则规则匹配,支持规则动态配置,支持配置多个规则
- 业务方可以通过前端配置限流,做到业务侧限流
- 提供管理员接口,一键设置限流,一键取消限流,一键完全限流等功能,为组件侧稳定性保证提供措施
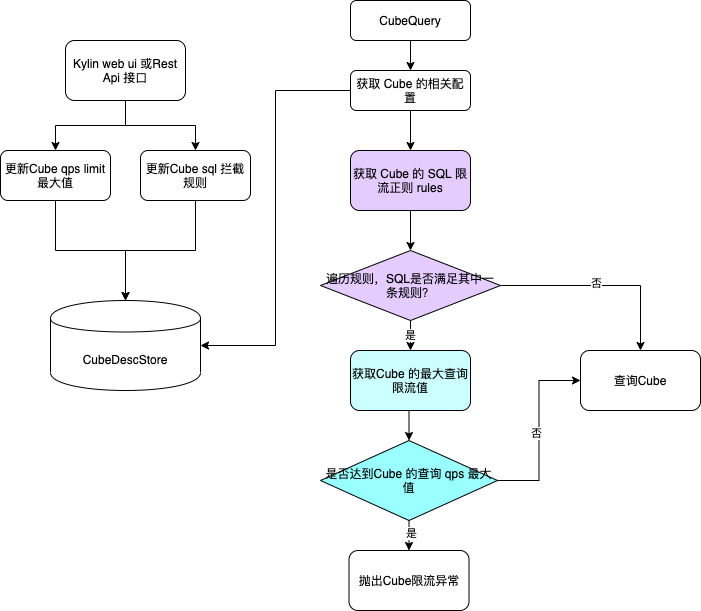
整体基于 Cube 级别限流的功能流程大概如下,我们提供了相关的管理员接口实现一键限流和取消限流,保证组件侧的稳定。同时业务侧用户可以通过配置 properties 实现业务侧的查询限流。
当然当前的限流功能还有一定的不足,还处于手动挡的阶段,需要人工感知那个 Cube 的那些 SQL 需要进行限流。后续也会不断完善功能,做成更自动的检测和自动的限流。
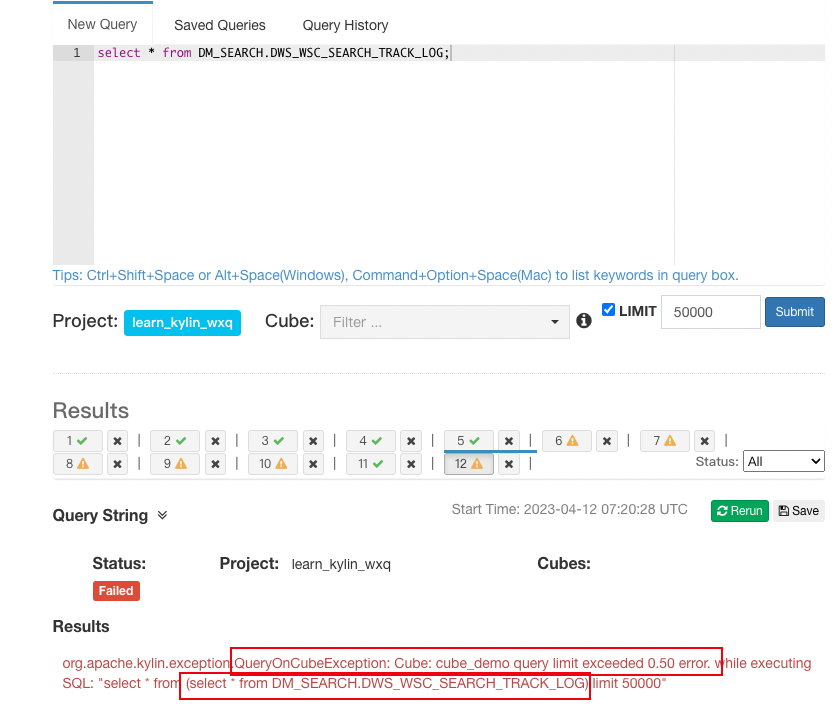
最后达到的效果就是,一旦对某个 Cube 按照指定的 SQL 限流规则限流后,会对相应的查询 SQL 进行限流,并给出限流提示。
3.1.3 其他一些小的性能优化
- 优化 BCryptPasswordEncoder 提升性能
通过 perf 的火焰图分析有很大的CPU的性能损耗是在用户安全验证的 PasswordEncoder.match() 上。Kylin 的安全认证中默认使用的的是 BCryptPasswordEncoder,bcrypt是一种强密码哈希函数,依赖大量的计算资源和时间来生成哈希值来保证安全性。

通过定位分析,一旦 Kylin 的认证缓存过期时,如果有大量的查询过来会同时进行认证,这就会导致同时在进行 Hash 时,产生了很大的 CPU 性能损耗,导致CPU 飙升。
为了解决上面的问题,避免出现 CPU 飙高的问题,我们进行了两方面的优化:
- 优化 BCryptPasswordEncoder 迭代次数
在现有的使用方式中,默认在初始化 BCryptPasswordEncoder 未指定迭代次数,默认是 -1,也就是 10 次将迭代次数设置为较小的值,例如 4 。这样可以减少计算哈希值的时间,但会牺牲一些安全性。
- 增加认证缓存失效时间
Kylin中可以通过配置 Kylin.server.auth-user-cache.expire-seconds (默认300s)增加缓存时间,减少缓存失效引起 CPU 异常的概率。
b. Segment 合并的监控
segment 没有合并的监控,discard了任务之后,如果任务不删除,Kylin 内部不会做合并,导致大量小的segment 不做合并,影响磁盘 IO。 因此我们做了一个 segment 合并的监控,定时检测是否会有 discard 的任务,及时对 discard 的任务进行处理,防止影响 segment 的合并。
3.2 查询性能优化
3.2.1 基于 Redis 的分布式查询缓存
由于有赞的 Cube 数据都是 T+1 构建,在引入基于 Redis 的分布式查询缓存之前,我们首先开启了本地缓存,但是发现实际的缓存命中的效果有,但是不是十分理想。比如在线上我们某一个集群中,15台查询节点,在上午的缓存命中率为 5%-8%,到下午的缓存命中率逐渐提升至 20%。
为什么选择 Redis 做分布式查询缓存?
社区仅支持 memcached 的原因在于, memacahed 对于大对象的支持性能更好。社区将大对象拆分成 1M 的多个对象,写入时分批存进 memacahed,查询时批量取出组装。
而在有赞的使用场景下, 98%-99% 的返回结果行数小于50,0.01% 的结果大于 500。绝大部分请求为小请求。
最终在考虑重新搭建一套 memcached,还是选择接入有赞的 Redis 上,考虑当前的使用场景和后期的维护成本,最终选择使用有赞的 Redis 作为分布式查询缓存。
基于Redis 的分布式缓存主要包括了以下几个功能点:
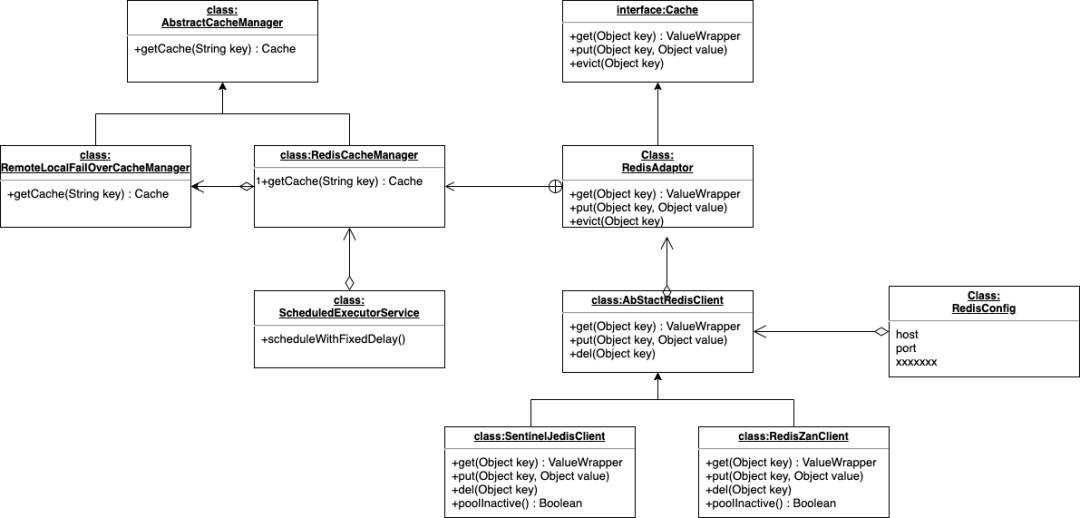
- 接入 Redis 缓存:接入 redis 缓存的 uml 设计如下:
- 缓存降级功能:会定时进行健康检查,一旦 Redis 缓存健康检查失败会触发缓存降级,防止查询重试引起 RT 过高。
- 缓存管理工具:可以管理员在Kylin Web UI 手动失效缓存,配置缓存降级等。
最终使用 Redis 作为分布式的查询缓存,缓存命中率从单机缓存的 20%的命中率提升到了 41% 左右,cpu在单机缓存基础上下降25%左右,RT下降50%左右。最终整个 Kylin 集群优化 50%的节点,成本降低 50%。
3.2.2 Parquet存储倾斜优化
Kylin4数据存储采用 parquet 进行存储,因此我们先看下parquet存储的数据结构。在 parquet 文件中会将一批数据以row group形式进行存储,row group 中对行组数据按列进行存储压缩以及 min-max 索引。抛开文件裁剪等优化,对单个文件的读取Kylin4查询性能强烈依赖 parquet 的min-max索引来实现 row group 的跳跃。
对于点查场景,我们的线上运行环境设置了较小的 row group size,配合min-max索引在点查场景下能达到较高的qps和较低的RT。但是在部分场景下,我们发现 row group size 设置失效,部分点查场景出现很高的延迟以及较大的扫描的数据量,同时出现task任务的切斜。
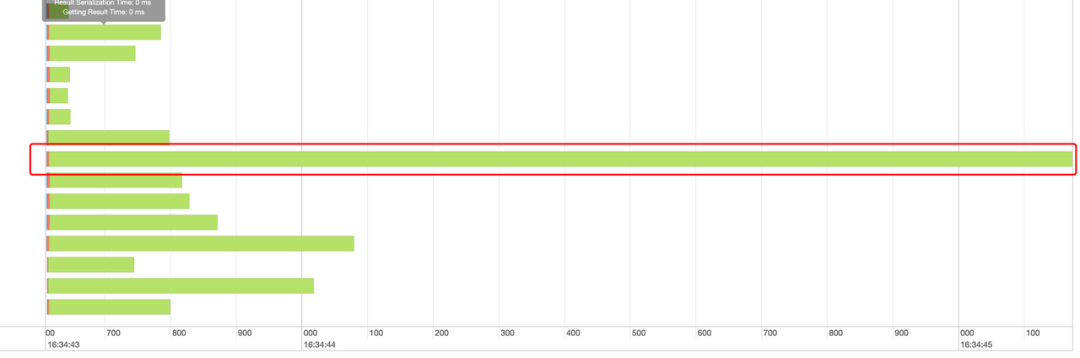
如上图是展示的 Kylin 执行的spark task的运行时间图,图中我们可以清晰的看到有一个task产生了倾斜导致。
查看该task读取的数据量,我们设置了row group 的 size 为8M,其他task大概读取0-8M之间,读取一个rw大小符合预期,而通过 spark 任务查看当前 task 读取比其他 task 大的多。
查看task对应读取的parquet文件,根据过滤条件发现当前 query 命中的 rowgroup 大小超过了64M,设置的8M的row-group失效了。
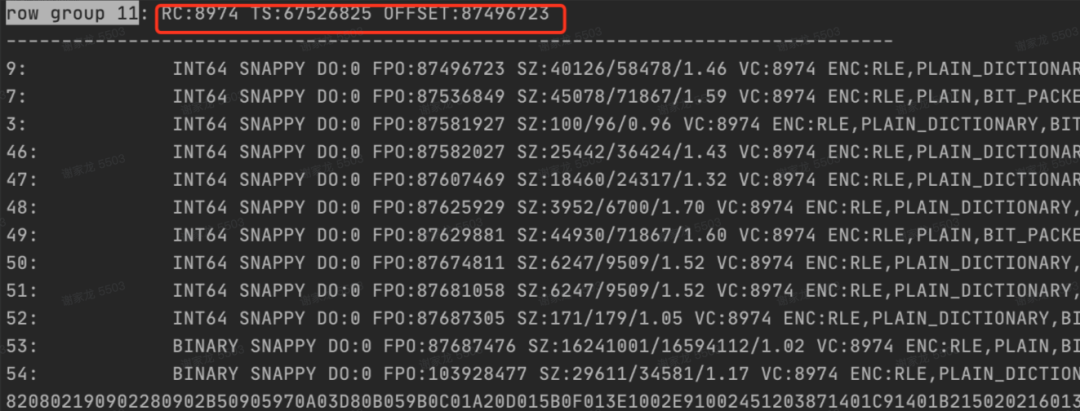
通过 parquet 文件写入的流程和校验规则得到最终的结论:预估逻辑会在数据倾斜时导致下一次写入row group的行数过大,row group size过大,比如存储内容为 team_id(long)、user_id(bitmap),前 100 个店铺都是连锁新店铺,数据量较小,预估行数为 10K,紧接着这100个店铺的店铺都是大店铺,每个店铺 bitmap 大小约1M,直接导致该 row group 成为超大 row group,影响数据查询。
为了解决上述 parquet 数据倾斜对查询的影响:通过实现最小的检验次数配置化,对线上存在倾斜的 row group文件进行统计,对倾斜严重的表设置较小的最小校验次数,数据重刷。
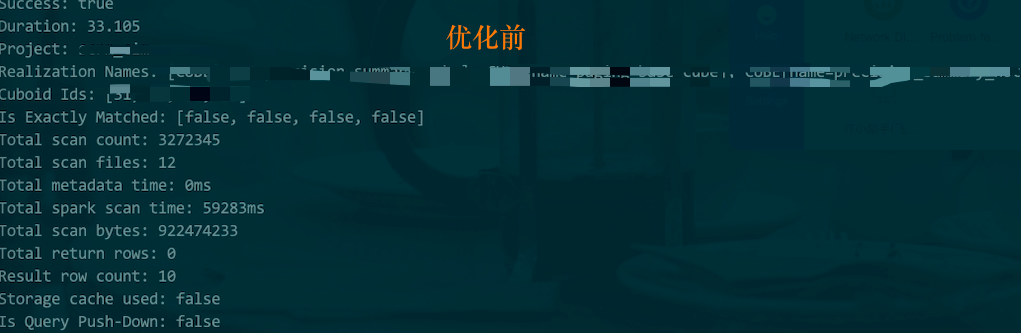
优化后 RT从 33s 降低到 1.2s,IO从 879M 降低到 77 M,性能有了极大的提升。线上整体治理后,查询IO降低了 1/3,查询 RT 降低 25%。如下图展示优化前后的对比图:

3.2.3 范围查询优化
在有赞的业务场景下,长时间范围查询以天粒度的 cuboid 进行查询,存在查询RT较长,资源占用多等问题,开放更大的商家数据查询时间周期存在性能瓶颈。
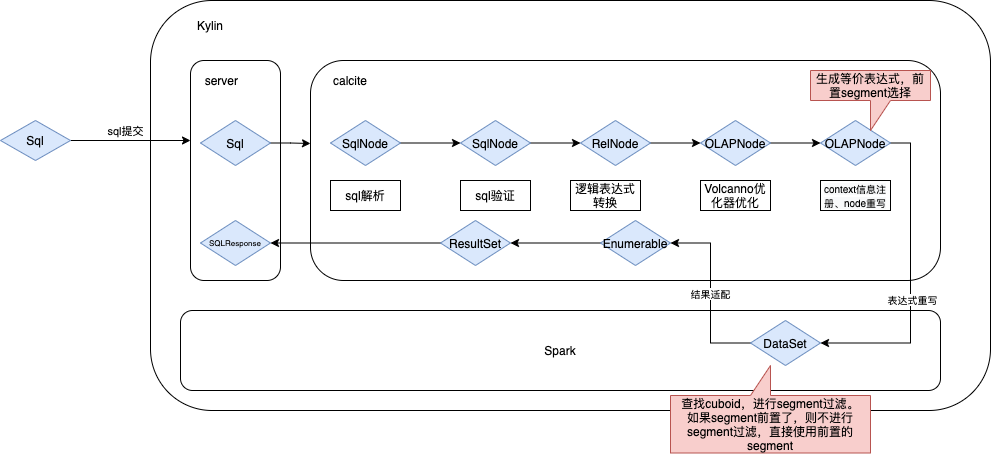
为了解决长时间查询范围的性能瓶颈,我们优化 Kylincube 查询策略,通过 segment 元数据自动匹配where条件中的日期范围。如能匹配则消除分区过滤条件,该 segment 的查询采用更粗粒度的 cuboid 进行查询,实现数据库内部自动改写查询实现多粒度的 cuboid 组合加速查询。
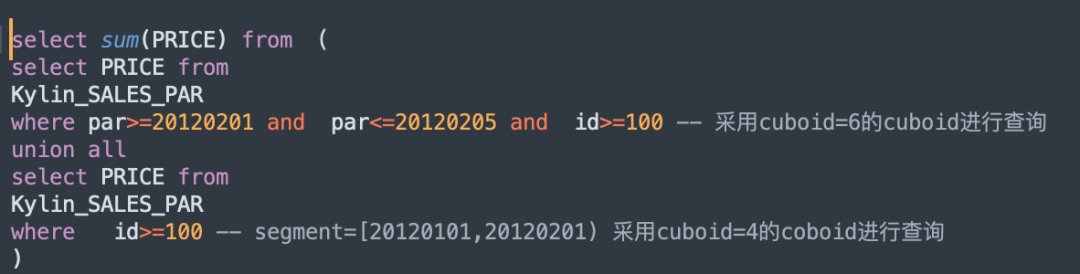
举个具体的例子:有一个 Cube 有两个Segment,分别为[20120101,20120201),[20120201,20120301),有以下两个cuboid: 【cuboid 4】维度组合为ID 和 【cuboid 6】维度组合为ID + PAR。
当查询 SQL 如下时:

原生的逻辑表达式:

优化后的逻辑表达式:

通过上面的等价表达式的改写,实现一个查询采用多个粒度的cuboid的能力,将物化视图的能力最大可能的利用,极大提升了大查询性能。以一年的查询范围进行压测,优化后整体QPS提升40%,RT降低20%,部分场景RT降低50%,查询IO降低70%,QPS提升三倍以上。
3.2.4 Classloader 类加载优化
在有赞的业务场景下,发现在线上高并发场景下经常会出现毛刺以及查询积压的情况,特别是在周一和月初的一些高并发场景出现查询积压问题。为了让系统更加平稳,我们针对上述问题做了以下优化:
- classloader开启并行参数
- 缓存不能加载的类
- 异常Exception常驻
- Class.forName 替换 ClassLoader.loadClass
接下来会分别介绍这几方面具体的实践,以及最终我们是如何彻底根治这个问题。
- classloader开启并行参数
在出现上述积压、毛刺情况下,我们自动拉取了线程栈,对查询时间较长的 Query 进行分析
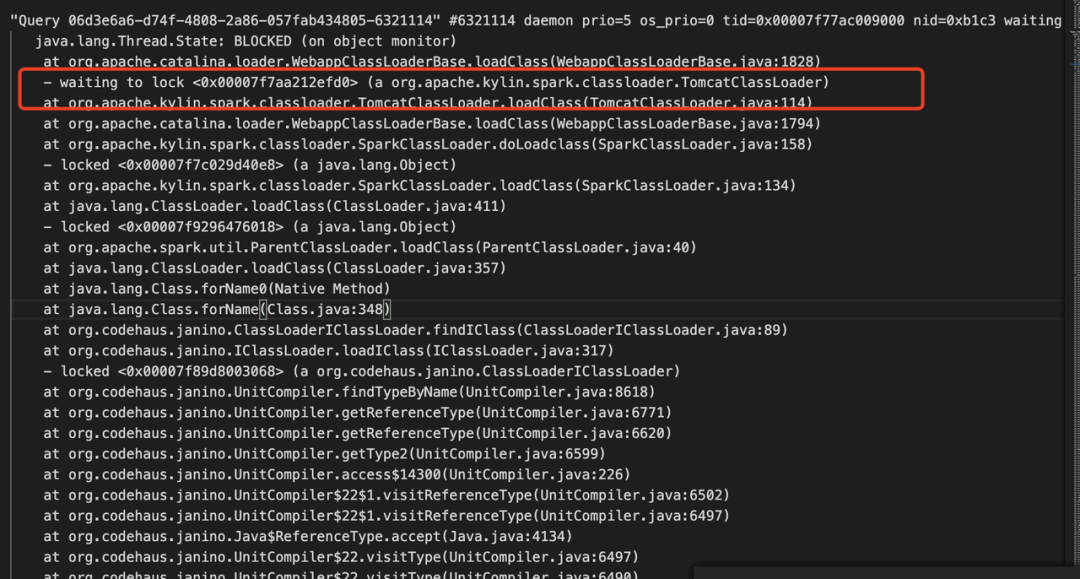
多次观察线程栈发现,Query 线程一直在等待 TomcatClassLoader 锁
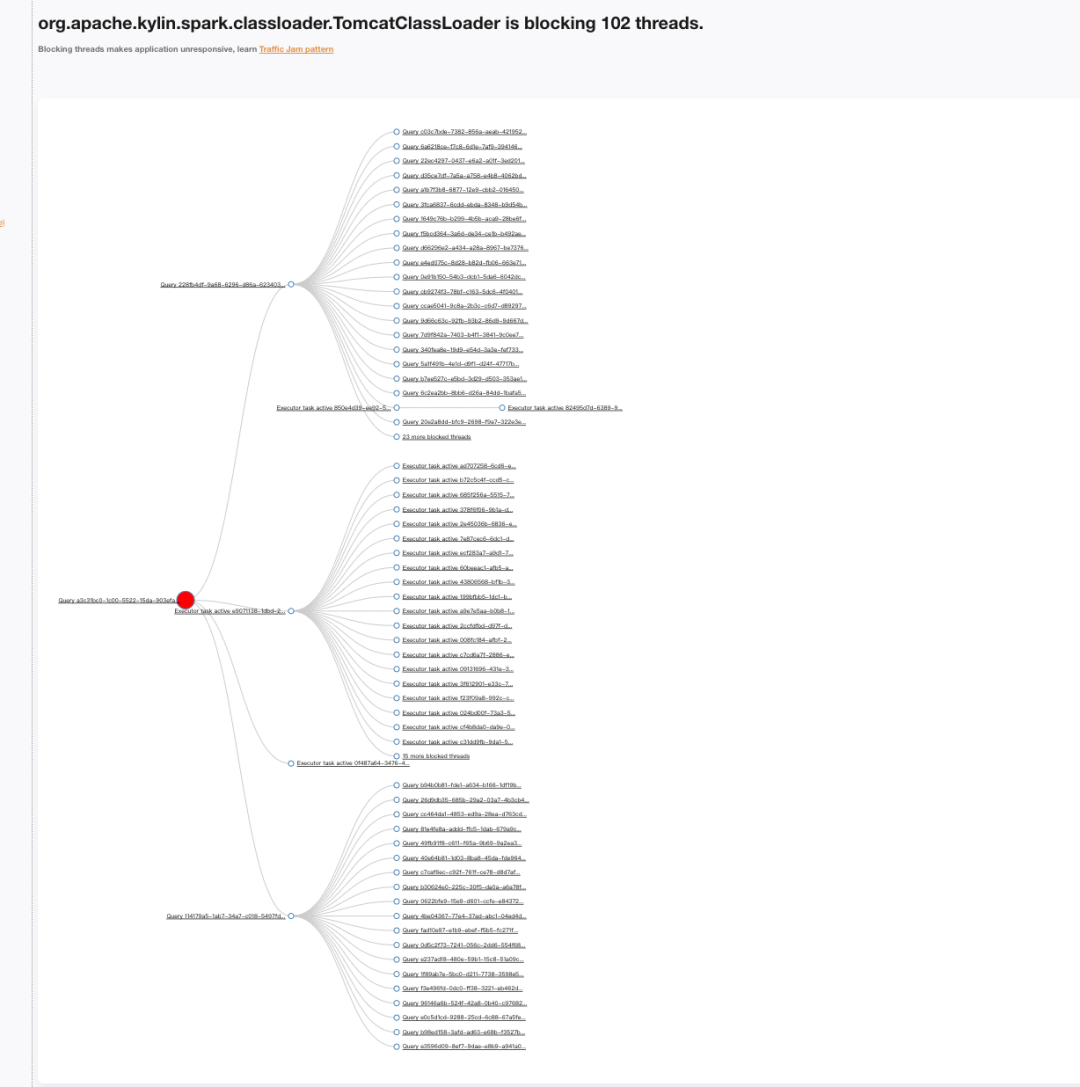
整体分析线程栈可以看出大量线程在等待 TomcatClassLoader.
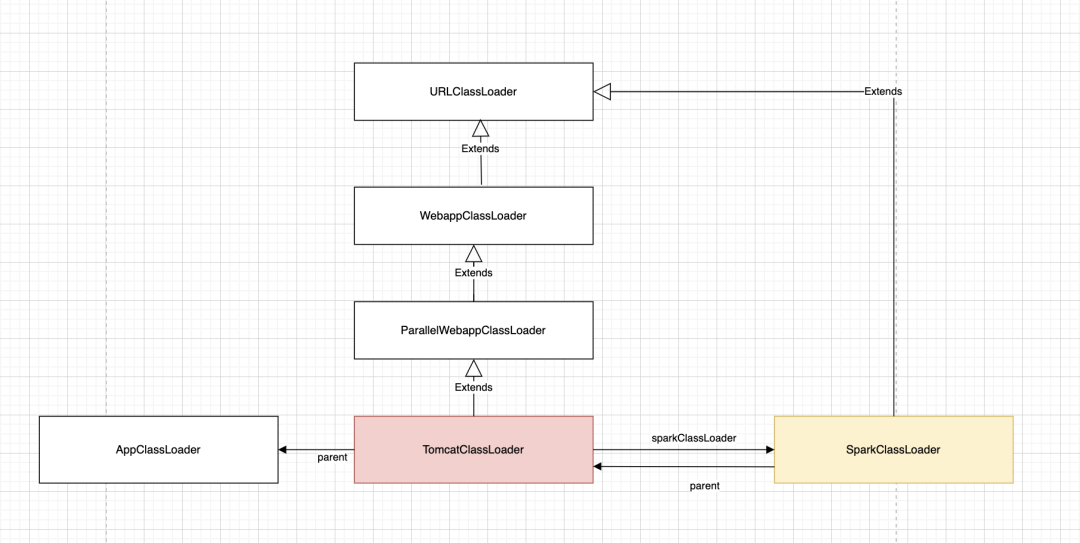
TomcatClassLoader是Kylin内部自定义的类加载器,根据上图的线程栈TomcatClassLoader进行类加载的过程发现会调用父类的loadClass方法,org.apache.catalina.loader.WebappClassLoaderBase进行loadClass操作,最终会调用 java.lang.ClassLoader#getClassLoadingLock 方法获取锁对象、从上述代码中我们可以看出如果开启并行锁,那么会针对不同的 className 生成不同的锁对象,否则使用全局锁。虽然TomcatClassLoader 继承 ParallelWebappClassLoader,但是注册是否是开启并行是类级别的,因此TomcatClassLoader 还需自行开启并发能力,否则将会是全局锁,对性能影响较大。
- 缓存不能加载的类
除了开启 classloader 开启并行参数之外,为了尽快结束类加载,对于当前类加载器不能加载的类进行缓存,快速结束当前 findloadedClass 查询的执行,尽快的交由双亲类加载器进行加载。
- 异常Exception常驻
对上述优化后,再次压测发现大量代码在异常的堆栈填充执行

通过分析代码发现类加载过程中会频繁地进行异常生成与抛出,在代码生成时该部分异常的堆栈比较深,对性能影响较大。对此我们将异常对象单例化,快速抛出异常。
- Class.forName 替换ClassLoader.loadClass
在经过上述的类加载优化后,我们发现对于查询性能有一定的提升,但是达不到理想的效果。为了彻底根治这个问题,我们进一步进行了定位和优化。
在 Spark 动态代码生成依赖 Janino compiler 做动态编译。Kylin 依赖 Calcite 做 sql 解析,Calcite 也会依赖 Janino compiler 动态编译。动态编译过程中需要加载所有依赖相关类。在上述优化做完后高并发场景下Kylin Query 线程和 Spark Executor 线程堆栈基本上都在执行 java.lang.Class.forName 上。
默认jstack对于native的方法调用一般会显示为RUNNABLE。如图:

但是我们的CPU很低,猜测应该是BLOCK在jvm内部,通过native堆栈,如下图所示证实了我们的猜想。
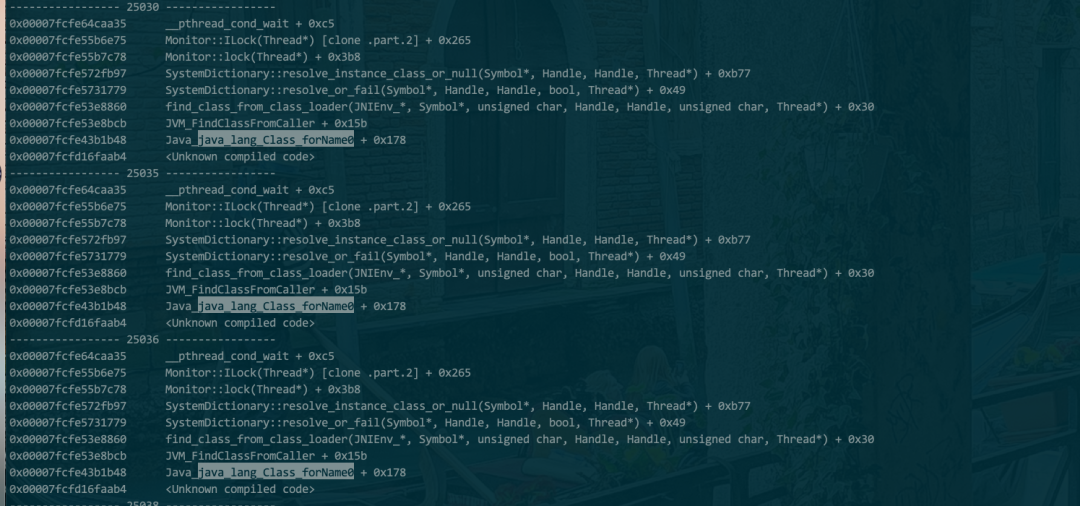
对于 janino的 改动点不多,主要对类加载的操作由 Class.forName 改为 ClassLoader.loadClass。那Class.forName和 ClassLoader.loadClass到底在实现上有什么区别,当两者调用参数resolve都为false时,从功能层面上二者等价。这里的 ClassLoader 对 Kylin query 进程而言分别是 TomcatClassLoader 和 SparkClassLoader。
Class.forName最终实现的时候会调用jvm的SystemDictionary::resolve_instance_class_or_null方法。该方法会加ClassLoader对象锁(开启parallelLock的话可忽略)和SystemDictionary_lock全局锁,最终会调用对应的ClassLoader进行类加载。从上图的 native 堆栈中,我们看到线程基本上都 block 在 SystemDictionary_lock 全局锁上。
而 ClassLoader.loadClass 默认实现会先加 LoadingLock (Kylin自定义 ClassLoader 开启了parallelLock,开销会低很多),然后调用 findLoadedClass,如果找不到会执行双亲委派,最终找不到才会执行。双亲找不到才会调用 findClass 执行类加载。findLoadedClass的jvm实现最终调用SystemDictionary::find_instance_or_array_klass,就是执行系统字典的查询。
由于动态编译过程中大多数类都已经加载,因此 ClassLoader.loadClass 进行 findLoadedClass 查询就能完成,降低大量的锁竞争。同时在动态编译中会尝试加载一些根本不存在的类(大约有10%的比例),我们对Kylin自定义 ClassLoader 在该场景做了进一步优化,进一步降低潜在的锁竞争。
上面的整个定位过程会涉及比较多的代码阅读,感兴趣的小伙伴可以根据思路自行进行代码阅读。
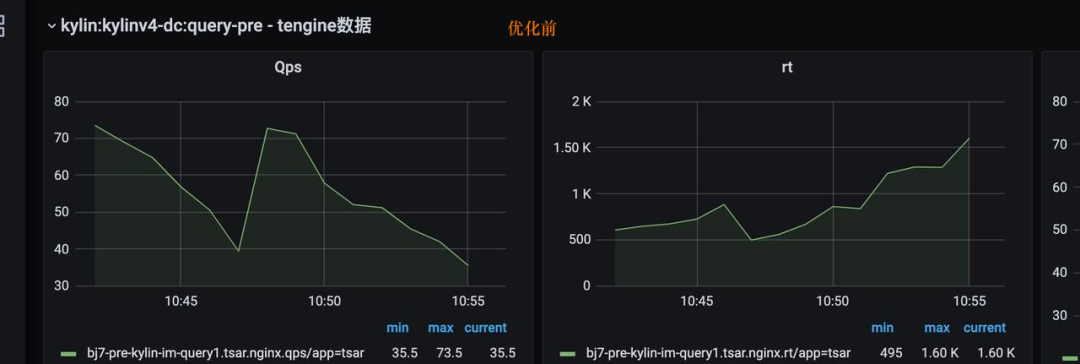
如下图展示了优化前后的对比。优化前QPS达到 70 后,产生各种严重的锁竞争,RT随之升高,QPS也降低了。优化后性能监控,优化后QPS达到150后RT依然保持平稳。彻底根治了高并发场景下类加载引起的查询性能问题

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号