从“CRUD”,看Python的常见数据类型

从“CRUD”,看Python的常见数据类型

大刚测试开发实战
发布于 2023-08-29 16:16:32
发布于 2023-08-29 16:16:32
前言
最近一段时间换了新工作,忙于熟悉新环境、新业务,很久没有更新推文了。
之前所写这篇文章是因为最近在帮助团队招聘、面试的过程中,看到很多人的简历上都提及自己擅长功能测试,擅长Python以及各类的自动化测试框架、测试工具,而当我提问用过哪些方法进行测试用例设计时,大多数同学的回答都是等价类划分、边界值,其他的甚至都没听说过;当我问到Python有哪些常见的数据类型以及它们有哪些常用方法、哪些是可变类型等这些基础的问题时,很多人都答不上来。
可见,很多小伙伴的基础都还不是太牢靠。简历上各种技术写得再天花乱坠,如果基础一问三不知,则会给人一种华而不实的感觉。借此篇文章,我将通过类比数据库CRUD的方式,从新增、修改、删除、查询等角度来介绍Python中常见的数据类型以及它们的一些特性,并作出总结,也权当是作一个自我巩固复习的过程。
Python基本的数据类型

当问及Python有哪些常见的数据类型时,很多人都知道有整型(int)、浮点型(float)、布尔型(bool)、字符串型(string)、列表(list)、字典(dictionary)、元组(tuple)、集合(set)。但其实整型、浮点型、布尔型都可以归结为数字型(number),所以Python中基本数据类型如下:
- 数字型(number)
- 字符串型(string)
- 列表(list)
- 字典(dictionary)
- 元组(tuple)
- 集合(set)
列表(list)
一、创建列表
从形式上看,列表会将所有元素都放在一对中括号[ ]里面,相邻元素之间用逗号,分隔,如下所示:
[element1, element2, element3, ..., elementn]
在 Python 中,创建列表的方法可分为两种:
1.使用 [ ] 直接创建列表
使用[ ]创建列表后,一般使用=将它赋值给某个变量,具体格式如下:
listname = [element1 , element2 , element3 , ... , elementn]
其中,listname 表示变量名,element1 ~ elementn 表示列表元素。
# 使用[]创建列表
list_number = [1, 2, 3, 4, 5, 6, 7, 8, 9]
list_str = ["lucy", "kitty", "nick"]2.使用 list() 函数创建列表
除了使用[ ]创建列表外,Python 还提供了一个内置的函数 list(),使用它可以将其它数据类型转换为列表类型。
# 使用list()函数将其他数据类型转换为列表
# 转换字符串
name = "hello"
list_name = list(name)
print(list_name) # ['h', 'e', 'l', 'l', 'o']
# 转换元组
tuple1 = ("age", "name", "height", "weight")
list_tu = list(tuple1)
print(list_tu) # ['age', 'name', 'height', 'weight']
# 转换字典
dict1 = {"name": "大刚", "age": 29, "height": "175cm", "weight": "70kg"}
list_dic = list(dict1)
print(list_dic) # ['name', 'age', 'height', 'weight']二、访问列表元素
列表是 Python 序列的一种,我们可以使用索引(Index)访问列表中的某个元素(得到的是一个元素的值),也可以使用切片访问列表中的一组元素(得到的是一个新的子列表)。
◆ 使用索引访问列表元素的格式为:listname[i]
其中,listname 表示列表名字,i 表示索引值。列表的索引可以是正数,也可以是负数。
◆ 使用切片访问列表元素的格式为:listname[start : end : step]
其中,listname 表示列表名字,start 表示起始索引,end 表示结束索引,step 表示步长。
◆ 获取列表所有元素:listname[:]
# 访问列表元素
list_number = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list_number[0]) # 列表第一个元素,1
print(list_number[-1]) # 列表最后一个元素,9
print(list_number[0:5]) # 列表切片,[1, 2, 3, 4, 5]
print(list_number[0:-1:2]) # 列表切片、并指定步长,[1, 3, 5, 7]
print(list_number[-5:-1:1]) # 使用负数切片、并指定步长,[5, 6, 7, 8]
print(list_number[:]) # 获取列表所有元素,[1, 2, 3, 4, 5, 6, 7, 8, 9]三、列表添加元素
实际开发中,经常需要对 Python 列表进行更新,包括向列表中添加元素、修改表中元素以及删除元素。一共有3种方法:
1.append()方法添加元素
append() 方法用于在列表的末尾追加元素,该方法的语法格式如下:
listname.append(obj)
其中,listname 表示要添加元素的列表;obj 表示到添加到列表末尾的数据,它可以是单个元素,也可以是列表、元组等。
# 列表添加元素
list_app = [1, 2, 3]
# 添加元素-append
list_app.append(4) # 在末尾添加
print(list_app) # [1, 2, 3, 4]2.extend()方法添加元素
extend() 方法的语法格式如下:
listname.extend(obj)
其中,listname 指的是要添加元素的列表;obj 表示到添加到列表末尾的数据,它可以是单个元素,也可以是列表、元组等。
# 列表添加元素
list_app = [1, 2, 3]
# 添加元素-extend
a = ['a', 'b', 'c']
list_app.extend(a) # 列表添加列表,在末尾添加
print(list_app) # [1, 2, 3, 4, 'a', 'b', 'c']
b = (110, 120, 119)
list_app.extend(b) # 列表添加元组,在末尾添加
print(list_app) # [1, 2, 3, 4, 'a', 'b', 'c', 110, 120, 119]3.insert()方法插入元素
insert() 的语法格式如下:listname.insert(index , obj)
其中,index 表示指定位置的索引值。insert() 会将 obj 插入到 listname 列表第 index 个元素的位置。
# 列表添加元素
list_app = [1, 2, 3]
# 添加元素-insert
list_app.insert(0, 555) # 在指定位置添加元素
print(list_app) # [555, 1, 2, 3, 4, 'a', 'b', 'c', 110, 120, 119]四、列表删除元素
在 Python 列表中删除元素主要分为以下 3 种场景:
- 根据目标元素所在位置的索引进行删除,可以使用 del 关键字或者 pop() 方法;
- 根据元素本身的值进行删除,可使用列表(list类型)提供的 remove() 方法;
- 将列表中所有元素全部删除,可使用列表(list类型)提供的 clear() 方法。
1.del:根据索引值删除元素
- del 可以删除列表中的单个元素,格式为:del listname[index]
- del 也可以删除中间一段连续的元素,格式为:del listname[start : end]
# 列表删除元素
list_del = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# del-根据索引值删除元素
del list_del[0] # 在指定位置添加元素
print(list_del) # [2, 3, 4, 5, 6, 7, 8, 9]2.pop():根据索引值删除元素
Python pop() 方法用来删除列表中指定索引处的元素,具体格式如下:listname.pop(index)
# 列表删除元素
list_del = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# pop-根据索引值删除元素
list_del.pop() # 不添加索引,默认删除最后一个元素
print(list_del) # [2, 3, 4, 5, 6, 7, 8]
list_del.pop(0) # 添加索引,删除指定索引的元素
print(list_del) # [3, 4, 5, 6, 7, 8]3.remove():根据元素值进行删除
除了 del 关键字,Python 还提供了 remove() 方法,该方法会根据元素本身的值来进行删除操作。删除不存在的元素时,会报错。
# 列表删除元素
list_del = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# remove-根据元素值进行删除
list_del.remove(6)
print(list_del) # [3, 4, 5, 7, 8]4.clear():删除列表所有元素
Python clear() 用来删除列表的所有元素,即清空列表。
# 列表删除元素
list_del = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# clear-删除列表所有元素(清空列表)
list_del.clear()
print(list_del) # []五、列表查找元素
Python 列表(list)提供了 index() 和 count() 方法,可以用来查找元素。
1.index() 方法
index() 方法用来查找某个元素在列表中出现的位置(也就是索引),如果该元素不存在,则会导致 ValueError 错误,所以在查找之前最好使用 count() 方法判断一下。
index() 的语法格式为:listname.index(obj, start, end)
其中,listname 表示列表名称,obj 表示要查找的元素,start 表示起始位置,end 表示结束位置。
start 和 end 参数用来指定检索范围:
- start 和 end 可以都不写,此时会检索整个列表;
- 如果只写 start 不写 end,那么表示检索从 start 到末尾的元素;
- 如果 start 和 end 都写,那么表示检索 start 和 end 之间的元素。
2.count()方法
count() 方法用来统计某个元素在列表中出现的次数,基本语法格式为:listname.count(obj)
其中,listname 代表列表名,obj 表示要统计的元素。如果 count() 返回 0,就表示列表中不存在该元素,所以 count() 也可以用来判断列表中的某个元素是否存在。
# 列表元素出现次数统计
list_cou = ["c", "c++", "java", "python", "python", ".net", "c#", "go", "js", "java", "object-c", "python"]
print(list_cou.count("python")) # 返回3
if list_cou.count("java"): # 判断元素是否存在列表中,存在会返回1,即True,故可以用来做判断
print("java存在于列表list_cou中")
else:
print("列表list_cou中不存在java元素")六、列表反转、排序
1.reverse
列表元素反转,用法:listname.reverse()
# reverse-列表元素反转,不改变ID
list_rev = [5, 6, 7, 1, 2, 3, 4]
list_rev.reverse()
print(list_rev) # [4, 3, 2, 1, 7, 6, 5]2.sort
列表排序,覆盖原列表,不改变ID,用法:listname.sort()
# sort-列表排序,覆盖原列表,不改变ID
list_sor = [5, 6, 7, 1, 2, 3, 4]
print(id(list_sor)) # 48733864
list_sor.sort()
print(list_sor) # [1, 2, 3, 4, 5, 6, 7]
print(id(list_sor)) # 487338643.sorted
列表排序,生成新列表,用法:sorted(listname)
# sorted-列表排序,生成新列表
list_std = [8, 5, 6, 9, 4, 1]
print(id(list_std)) # 原ID:60944456
list_std_new = sorted(list_std)
print(list_std_new) # [1, 4, 5, 6, 8, 9]
print(id(list_std_new)) # 生成的新列表的ID:60944520七、列表总结
操作 | 用法示例 |
|---|---|
C-创建列表 | [] list()函数 |
R-访问列表元素 | 使用索引访问列表元素的格式为:listname[i]使用切片访问列表元素的格式为:listname[start : end : step]获取列表所有元素:listname[:] |
U-列表添加元素 | append:末尾追加元素extend:末尾添加元素,可以是单个元素、列表、元组insert:列表指定位置添加元素 |
D-列表删除元素 | del:根据索引值删除元素,可以是单个元素,也可以是一段元素pop:删除指定索引位置的元素remove:根据元素值进行删除clear:删除列表所有元素(清空列表) |
其他 | count:统计某个元素在列表中出现的次数,也可以判断元素是否存在index:查找某个元素在列表中出现的位置reverse:列表元素反转sort:列表排序,不生成新列表sorted:列表排序,生成新列表 |
- []
- list()函数
R-访问列表元素
- 使用索引访问列表元素的格式为:listname[i]
- 使用切片访问列表元素的格式为:listname[start : end : step]
- 获取列表所有元素:listname[:]
U-列表添加元素
- append:末尾追加元素
- extend:末尾添加元素,可以是单个元素、列表、元组
- insert:列表指定位置添加元素
D-列表删除元素
- del:根据索引值删除元素,可以是单个元素,也可以是一段元素
- pop:删除指定索引位置的元素
- remove:根据元素值进行删除
- clear:删除列表所有元素(清空列表)
其他
- count:统计某个元素在列表中出现的次数,也可以判断元素是否存在
- index:查找某个元素在列表中出现的位置
- reverse:列表元素反转
- sort:列表排序,不生成新列表
- sorted:列表排序,生成新列表
元组(tuple)
元组(tuple)是 Python 中另一个重要的序列结构,和列表类似,元组也是由一系列按特定顺序排序的元素组成,列表和元组都是有序序列。
一、list列表和tuple元组
元组和列表(list)的不同之处在于:
- 列表的元素是可以更改的,包括修改元素值,删除和插入元素,所以列表是可变序列;
- 而元组一旦被创建,它的元素就不可更改了,所以元组是不可变序列。
元组也可以看做是不可变的列表,通常情况下,元组用于保存无需修改的内容。
二、创建元组
Python 提供了两种创建元组的方法:
1.使用( )直接创建
通过( )创建元组后,一般使用=将它赋值给某个变量,具体格式为:
tuplename = (element1, element2, ..., elementn)
例如:
# 通过()创建元组
t1 = ("c", "c++", "java", "python", "ruby")
print(t1) # ('c', 'c++', 'java', 'python', 'ruby')
# 获取指定索引值
print(t1[2]) # java
# 查询指定范围内是否存在指定值,存在返回索引位置,不存在报错
print(t1.index('java', 0, -1)) # 22.使用tuple()函数创建元组
除了使用( )创建元组外,Python 还提供了一个内置的函数 tuple(),用来将其它数据类型转换为元组类型。例如:
# 使用tuple()函数将其他数据类型转换为元组
list_1 = [1, 3, 5, 7, 9]
t2 = tuple(list_1) # 列表强转为元组
print(t2) # (1, 3, 5, 7, 9)
str_1 = "hello world"
t3 = tuple(str_1) # 字符串强转为元组
print(t3) # ('h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd')
dict_1 = {"name": "chen", "age": 28, "height": "75kg"}
t4 = tuple(dict_1) # 字典强转为元组
print(t4) # ('name', 'age', 'height')字典(dictionary)
Python 字典(dict)是 Python 中唯一的映射类型,是一种无序的、可变的序列,它的元素以“键值对(key-value)”的形式存储。字典中,习惯将各元素对应的索引称为键(key),各个键对应的元素称为值(value),键及其关联的值称为“键值对”。总的来说,字典类型所具有的主要特征如下 所示:
一、创建字典
1.使用 { } 创建字典
由于字典中每个元素都包含两部分,分别是键(key)和值(value),因此在创建字典时,键和值之间使用冒号:分隔,相邻元素之间使用逗号,分隔,所有元素放在大括号{ }中。使用{ }创建字典的语法格式如下:dictname = {'key':'value1', 'key2':'value2', ..., 'keyn':valuen}
# 使用{}创建
dict1 = {"name": "大刚", "age": 29, "phone": 15252162666}2.通过 fromkeys() 方法创建字典
Python 中,还可以使用 dict 字典类型提供的 fromkeys() 方法创建带有默认值的字典,具体格式为:
dictname = dict.fromkeys(list,value=None)
其中,list 参数表示字典中所有键的列表(list);value 参数表示默认值,如果不写,则为空值 None。
# 通过 fromkeys() 方法创建字典
c = ['name', 'age', 'weight']
dict5 = dict.fromkeys(c)
dict6 = dict.fromkeys(c, "0")
print(dict5) # {'name': None, 'age': None, 'weight': None}
print(dict6) # {'name': '0', 'age': '0', 'weight': '0'}3.通过 dict() 映射函数创建字典
格式1: dict1 = dict(key1=value1, key2=value2, key3=value3) 格式2: demo = [('two',2), ('one',1), ('three',3)] dict2 = dict(demo) 格式3: keys = ['one', 'two', 'three'] # 还可以是字符串或元组 values = [1, 2, 3] # 还可以是字符串或元组 dict3 = dict( zip(keys, values) )
# 使用dict()方法创建
dict2 = dict(age=29, name="大刚", city="xuzhou") # dict(key1=value1,key2=value2)
print(dict2) # {'age': 29, 'name': '大刚', 'city': 'xuzhou'}
info = (("name", "大刚"), ("age", 29), ("city", "nanjing"), ("number", 227))
dict3 = dict(info) # 使用dict()方法强制转换二维元组为字典
print(dict3) # {'name': '大刚', 'age': 29, 'city': 'nanjing', 'number': 227}
a = [1, 2, 3, 4]
b = ["a", "b", "c", "d"]
dict4 = dict(zip(a, b)) # 使用dict()方法结合zip()方法将等长的列表转换为字典
print(dict4) # {1: 'a', 2: 'b', 3: 'c', 4: 'd'}二、访问字典元素
列表和元组是通过下标来访问元素的,而字典不同,它通过键来访问对应的值。
1.通过 dictname[key] 访问
其中,dictname 表示字典变量的名字,key 表示键名。注意,键必须是存在的,否则会抛出异常。
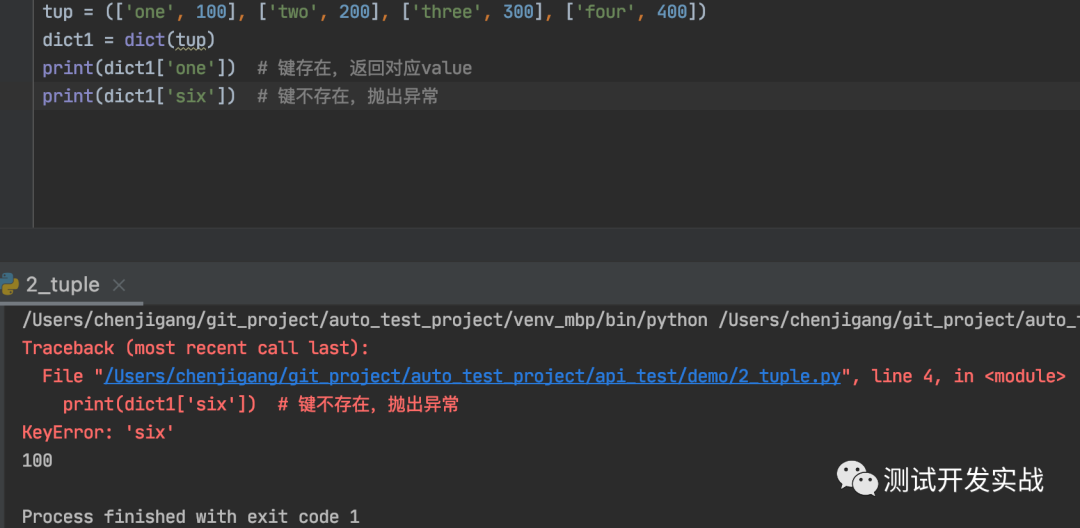
tup = (['one', 100], ['two', 200], ['three', 300], ['four', 400])
dict1 = dict(tup)
print(dict1['one']) # 键存在,返回对应value
print(dict1['six']) # 键不存在,抛出异常运行结果如下:
2.通过 get() 方法获取
格式为:dictname.get(key[,default])
其中,dictname 表示字典变量的名字;key 表示指定的键;default 用于指定要查询的键不存在时,此方法返回的默认值,如果不手动指定,会返回 None。
# 访问字典元素
dict7 = {'age': 28, 'name': 'tom', 'city': 'xuzhou'}
print(dict7["age"]) # 28
print(dict7.get("age")) # 28
print(dict7.get("age", 18)) # 28,设置默认返回值,检索到key时,返回key的实际值
print(dict7.get("age111", 18)) # 18,设置默认返回值,未检索到key时,返回默认值三、字典添加键值对
为字典添加新的键值对很简单,直接给不存在的 key 赋值即可,具体语法格式如下:
dictname[key] = value
各个部分的说明:
- dictname 表示字典名称;
- key 表示新的键;
- value 表示新的值,只要是 Python 支持的数据类型都可以;
# 字典添加键值对
dict8 = {'age': 28, 'name': 'tom', 'city': 'xuzhou'}
dict8["number"] = 227 # 如果存在此键,则更新键值,不存在则添加新键值对
print(dict8) # {'age': 28, 'name': 'tom', 'city': 'xuzhou', 'number': 227}四、字典更新键值对
1.update() 方法
update() 方法可以使用一个字典所包含的键值对来更新已有的字典。
在执行 update() 方法时,如果被更新的字典中己包含对应的键值对,那么原 value 会被覆盖;如果被更新的字典中不包含对应的键值对,则该键值对被添加进去。
# 更新字典
dict14 = {'age': 28, 'name': 'tom', 'city': ['xuzhou', 'suzhou', 'hangzhou']}
dict14.update({"age": 18})
print(dict14) # {'age': 18, 'name': 'tom', 'city': ['xuzhou', 'suzhou', 'hangzhou']}
dict14.update({"num": 227})
print(dict14) # {'age': 18, 'name': 'tom', 'city': ['xuzhou', 'suzhou', 'hangzhou'], 'num': 227}2.setdefault() 方法
setdefault() 方法用来返回某个 key 对应的 value,其语法格式如下:
dictname.setdefault(key, defaultvalue=None)
说明,dictname 表示字典名称,key 表示键,defaultvalue 表示默认值(可以不写,不写的话是 None)。
# 字典key设置默认值
dict16 = {'age': 18, 'name': 'tom', 'num': 227}
dict16.setdefault('name', 'lucy') # 键存在时,不更新
print(dict16) # {'age': 18, 'name': 'tom', 'num': 227}
dict16.setdefault('city', 'xuzhou') # 键不存在时,更新字典
print(dict16) # {'age': 18, 'name': 'tom', 'num': 227, 'city': 'xuzhou'}五、字典删除键值对
1.pop() 和 popitem() 方法
pop() 和 popitem() 都用来删除字典中的键值对,不同的是,pop() 用来删除指定的键值对,而popitem() 用来随机删除一个键值对,语法格式如下:
dictname.pop(key) dictname.popitem()
# 删除字典元素
dict15 = {'age': 18, 'name': 'tom', 'city': ['xuzhou', 'suzhou', 'hangzhou'], 'num': 227}
dict15.pop('age') # 删除指定键值对
print(dict15) # {'name': 'tom', 'city': ['xuzhou', 'suzhou', 'hangzhou'], 'num': 227}
pi = dict15.popitem() # 删除最后一个键值对,返回值是被删除的键值对
print(pi) # ('num', 227)
print(dict15) # {'name': 'tom', 'city': ['xuzhou', 'suzhou', 'hangzhou']}
del dict15["city"] # 通过del删除指定键值对
print(dict15) # {'name': 'tom'}六、字典的一些其他方法
1.判断字典中是否存在指定键值对
判断字典是否包含指定键值对的键,可以使用 in 或 not in 运算符。
# 判断字典是否包含指定键值对的键
dict9 = {'age': 28, 'name': 'tom', 'city': 'xuzhou'}
assert 'name' in dict9
assert 'address' not in dict92.keys()、values() 和 items() 方法
- keys() 方法用于返回字典中的所有键(key);
- values() 方法用于返回字典中所有键对应的值(value);
- items() 用于返回字典中所有的键值对(key-value);
# 返回字典中的所有键
print(dict9.keys()) # dict_keys(['age', 'name', 'city'])
# 返回字典中的所有键的键值
print(dict9.values()) # dict_values([28, 'tom', 'xuzhou'])
# 返回字典中的所有键值对
print(dict9.items()) # dict_items([('age', 28), ('name', 'tom'), ('city', 'xuzhou')])3.查看dict所有方法
Python 字典的数据类型为 dict,我们可使用 dir(dict) 来查看该类型包含哪些方法
>>> dir(dict)
['clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']七、copy()方法-深拷贝与浅拷贝
copy() 方法返回一个字典的拷贝,也即返回一个具有相同键值对的新字典。
深拷贝与浅拷贝:
- 浅拷贝:若拷贝的对象是一个可变对象,如字典、列表等,拷贝的只是内存地址,只要其中一个被更改,则拷贝前和拷贝后的对象都会被更改
- 深拷贝:deepcopy()方法copy的对象,会新生成一个内存地址,故被拷贝对象的可变元素被更改后不会影响拷贝后的结果
# 拷贝字典
import copy
dict10 = {'age': 28, 'name': 'tom', 'city': ['xuzhou', 'suzhou', 'hangzhou']}
# 浅拷贝:通过dict自带的copy方法
dict11 = dict10.copy()
# 浅拷贝:通过引入copy模块的copy()方法拷贝
dict12 = copy.copy(dict10)
# 深拷贝:通过引入copy模块的deepcopy()方法拷贝
dict13 = copy.deepcopy(dict10)
dict10["city"].remove('xuzhou')
print(dict11) # {'age': 28, 'name': 'tom', 'city': ['suzhou', 'hangzhou']}
print(dict12) # {'age': 28, 'name': 'tom', 'city': ['suzhou', 'hangzhou']}
print(dict13) # {'age': 28, 'name': 'tom', 'city': ['xuzhou', 'suzhou', 'hangzhou']}八、字典总结
- 列表和元组都是有序序列,字典是无需序列;
- 列表和字典都是可变序列,元组是不可变序列;
操作 | 用法示例 |
|---|---|
C-创建字典 | { }fromkeys() 方法dict() 映射函数,也可以强制转换其他类型数据为字典,如:元组 |
R-访问字典键值对 | dictname[key],注意,键必须是存在的,否则会抛出异常。dictname.get(key[,default]),未检索到key时,返回默认值default |
U-字典添加或更新键值对 | dictname[key] = value:如果存在此键,则更新键值,不存在则添加新键值对,value可以是Python任意数据类型update(key: value) :存在则更新键值,不存在则添加此键值对setdefault(key, value):键存在时、不更新键值,键不存在时添加此键值对 |
D-字典删除键值对 | pop() 用来删除指定的键值对popitem() 用来随机删除一个键值对del dictname[key]:根据键名称删除键值对 |
其他 | assert key (not) in dictname:判断字典中是否(不)存在指定键值对keys():返回字典中的所有键(key)values():返回字典中所有键对应的值(value)items():返回字典中所有的键值对(key-value) |
- { }
- fromkeys() 方法
- dict() 映射函数,也可以强制转换其他类型数据为字典,如:元组
R-访问字典键值对
- dictname[key],注意,键必须是存在的,否则会抛出异常。
- dictname.get(key[,default]),未检索到key时,返回默认值default
U-字典添加或更新键值对
- dictname[key] = value:如果存在此键,则更新键值,不存在则添加新键值对,value可以是Python任意数据类型
- update(key: value) :存在则更新键值,不存在则添加此键值对
- setdefault(key, value):键存在时、不更新键值,键不存在时添加此键值对
D-字典删除键值对
- pop() 用来删除指定的键值对
- popitem() 用来随机删除一个键值对
- del dictname[key]:根据键名称删除键值对
其他
- assert key (not) in dictname:判断字典中是否(不)存在指定键值对
- keys():返回字典中的所有键(key)
- values():返回字典中所有键对应的值(value)
- items():返回字典中所有的键值对(key-value)
字符串(string)
一、字符串切片
从本质上讲,字符串是由多个字符构成的,字符之间是有顺序的,这个顺序号称为索引(index)。
1.获取单个字符
在方括号[ ]中使用索引即可访问对应的字符,具体的语法格式为:
strname[index]
Python 允许从字符串的两端使用索引:
- 当以字符串的左端(字符串的开头)为起点时,索引是从 0 开始计数的;字符串的第一个字符的索引为 0,第二个字符的索引为 1,第三个字符串的索引为 2 ……以此类推
- 当以字符串的右端(字符串的末尾)为起点时,索引是从 -1 开始计数的;字符串的倒数第一个字符的索引为 -1,倒数第二个字符的索引为 -2,倒数第三个字符的索引为 -3 ……以此类推
str1 = "life is short,i need PYTHON"
# 字符串查找
print(str1.find('s', 0, -1)) # 查找指定范围内是否存在某字符,是返回下标,不存在返回-1
# 获取单个字符
a = str1[0] # 第一个字符
b = str1[-1] # 最后一个字符
print(a) # 1
print(b) # N2.获取多个字符(字符串截取/切片)
使用[ ]除了可以获取单个字符外,还可以指定一个范围来获取多个字符,也就是一个子串或者片段,具体格式为:
strname[start : end : step]
# 获取多个字符(字符串切片)
c = str1[0:3] # 获取str1的第1个到第3个之间的字符,步长默认为1
d = str1[0:5:2] # 获取str1的第1个到第5个之间的字符,指定默认为2二、len():获取对象长度和字节长度
Python 中,要想知道一个对象长度,或者一个字符串占用多少个字节,可以使用 len 函数。len 函数的基本语法格式为:len(obj)
其中 obj用于指定要进行长度统计的对象,可以是字符串、列表、元组、字典等。通过使用 encode() 方法,将字符串进行编码后再获取它的字节数。例如,采用 UTF-8 编码方式,计算“人生苦短,我用Python”的字节数,可以执行如下代码:
# 获取对象长度
str2 = "人生苦短,我用PYTHON"
print(len(str2)) # 13
print(len(str2.encode())) # 27,使用encode()方法转码为字节,一个中文字符占用3个字节三、join()方法:合并字符串
Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。语法格式:
newstr = str.join(iterable)
此方法中各参数的含义如下:
- newstr:表示合并后生成的新字符串;
- str:用于指定合并时的分隔符;
- iterable:做合并操作的源字符串数据,允许以列表、元组等形式提供。
# 合并字符串
list_a = ['a', 'b', 'c', 'd', 'e']
print("".join(list_a)) # abcde 默认连接符
print("#".join(list_a)) # a#b#c#d#e 指定连接符
# 字符串拼接
str_a = "人生苦短"
str_b = "我用PYTHON"
print(str_a + str_b) # 人生苦短我用PYTHON
# 字符串追加字符
print(str_b.join(str_a)) # 人我用PYTHON生我用PYTHON苦我用PYTHON短 输出的为无序的字符串四、split()方法:字符串分隔
# 字符串分隔
str2 = "life is short,i need python"
print(str2.split(' ')) # ['life', 'is', 'short,i', 'need', 'PYTHON']五、替换与删除指定字符
- str.replace(old, new,count),替换指定字符(不加count默认全替换)
- str.replace(old, '',count),将指定字符用空字符代替、从而达到删除的目的(不加count默认全替换)
# 字符串替换指定字符(用大写的LIFE字符代替小写的life)
print(str2.replace('life', 'LIFE')) # LIFE is short,i need python
# 字符串删除指定字符(用空字符代替字符i,从而达到删除目的)
print(str2.replace('i', '')) # lfe s short, need python六、字符串格式化输出
1.来自C语言的%方式
%号格式化字符串的方式继承自古老的C语言,这在很多编程语言都有类似的实现。%s是一个占位符,它仅代表一段字符串,并不是拼接的实际内容。实际的拼接内容在一个单独的%号后面,放在一个元组里。类似的占位符还有:
- %d(代表一个整数)
- %f(代表一个浮点数)
- %x(代表一个16进制数)
%占位符既是这种拼接方 式的特点,同时也是其限制因为每种占位符都有特定意义,实际使用起来较为麻烦。
# 使用占位符
name = "dang"
age = 5
print("我叫%s,我今年%s岁了" % (name, age)) # 我叫dang,我今年5岁了
print("%d" % (20)) # 八进制 20
print("%o" % (20)) # 十进制 24
print("%x" % (20)) # 十六进制 142.format()拼接方式
# format()拼接方式
name1 = "当当"
name2 = "刚刚"
age = 5
print("我叫{},我今年{}岁了".format(name1, age)) # 我叫当当,我今年5岁了
print("我叫{1},我叫{0}".format(name1, name2)) # 使用编号指定顺序 "我叫刚刚,我叫当当"
print("我叫{name},我今年{age}岁了".format(name=name1, age=age)) # 使用变量名指定顺序 "我叫当当,我今年5岁了"3.f-string方式
f-string方式出自PEP 498(Literal String Interpolation,字面字符串插值),从Python3.6版本引入。其特点是在字符串前加 f 标识,字符串中间则用花括号{}包裹其他字符串变量。
# f-string方式
name3 = "jigang.chen"
age = 28
print(f"我叫{name3},我今年{age}岁了") # 我叫jigang.chen,我今年28岁了
print(f"a total number is {20 * 2 + 8}") # 处理表达式 a total number is 48
name = "PYTHON"
print(f"my name is {name.lower()}") # 处理方法调用 my name is python七、字符串其他方法
str1 = "life is short,i need PYTHON"
# 计算某个字符出现的次数
print(str1.count('i')) # 3
# 在指定区间内查找某个字符,并返回该字符的索引
print(str1.find('f', 0, -1)) # 2
# 将字符串全部转换为小写
print(str1.lower()) # life is short,i need python八、字符串总结
用法示例集合(set)
Python 中的集合,是一种无序的、可变的序列,和数学中的集合概念一样,用来保存不重复的元素,即集合中的元素都是唯一的,互不相同。形式上看,和字典类似,Python 集合会将所有元素放在一对大括号 {} 中,相邻元素之间用“,”分隔,如下所示:
{element1,element2,...,elementn}
一、创建集合
1.使用 {} 创建
在 Python 中,创建 set 集合可以像列表、元素和字典一样,直接将集合赋值给变量,其语法格式如下:
setname = {element1,element2,...,elementn}
set1 = {1, 2, 3, 4, 5, 6}2.set()函数创建集合
set() 函数为 Python 的内置函数,其功能是将字符串、列表、元组、range 对象等可迭代对象转换成集合。该函数的语法格式如下:
setname = set(iteration)
# 使用set()方法创建
list1 = [5, 6, 7, 8, 9]
tup1 = ('a', 'b', 'c')
set2 = set(list1) # 将列表转换为集合
set3 = set(tup1) # 将元组转换为集合,转换结果是无序的
print(set2) # {5, 6, 7, 8, 9}
print(set3) # {'a', 'c', 'b'}二、向集合中添加元素
set 集合中添加元素,可以使用 set 类型提供的 add() 方法实现,该方法的语法格式为:
setname.add(element)
# 向集合中添加元素
set1.add('e') # add()方法添加元素
print(set1) # {1, 2, 3, 4, 5, 6, 'e'}
set1.update(tup1) # update()方法添加元素
print(set1) # {1, 2, 3, 4, 5, 6, 'c', 'e', 'b', 'a'}三、从集合中删除元素
删除现有 set 集合中的指定元素,可以使用 remove() 方法,该方法的语法格式如下:
setname.remove(element)
# 集合删除元素
set1.remove('a') # 删除指定元素
print(set1) # {1, 2, 3, 4, 5, 6, 'e', 'b', 'c'}
set1.pop() # 从最开始位置删除元素
print(set1) # {2, 3, 4, 5, 6, 'c', 'b', 'e'}
set1.discard('e') # 删除指定元素,不存在则不做任何操作
print(set1) # {2, 3, 4, 5, 6, 'c', 'b'}
set1.clear() # 清空集合
print(set1) # set()四、清空集合
清空现有 set 集合中的所有元素,可以使用 clear() 方法,该方法的语法格式如下:
setname.clear()
list1 = [1, 3, 4, 5, 6, 6]
set2 = set(list1)
print(set2) # {1, 3, 4, 5, 6}
set2.clear()
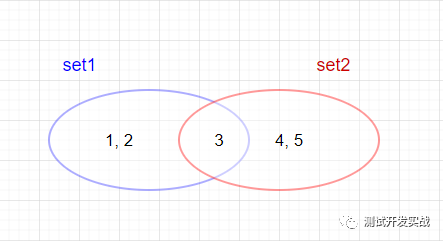
print(set2) # set()五、集合求交集、并集、差集
1.通过python运算符
运算操作 | Python运算符 | 含义 | 例子 |
|---|---|---|---|
交集 | & | 取两集合公共的元素 | set1 & set2 >> [3] |
并集 | | | 取两集合全部的元素 | set1 | set2 >> [1,2,3,4,5] |
差集 | - | 取一个集合中另一个集合没有的元素 | set1 - set2 >> [1,2]set2 - set1 >> [4,5] |
对称差集 | ^ | 取集合A和B中不属于A&B的元素 | set1 ^ set2 >> [1,2,4,5] |
2.通过函数
方法名 | 语法格式 | 含义 |
|---|---|---|
difference() | set3 = set1.difference(set2) | 将set1中有而set2中没有的元素赋给set3 |
intersection() | set3 = set1.intersection(set2) | 取set1和set2的交集,赋给set3 |
union() | set3 = set1.union(set2) | 取set1和set2的并集,赋给set3 |
示例:
# 集合交集、并集、差集
set_a = {'a', 'b', 'c', 'd'}
set_b = {'c', 'd', 'e', 'f'}
# 求交集
ict = set_a.intersection(set_b) # intersection()方法
print(ict) # {'c', 'd'}
set_ict = set_a & set_b # 使用 & 运算符
print(set_ict) # {'c', 'd'}
# 求并集
union = set_a.union(set_b) # union()方法
print(union) # {'f', 'd', 'e', 'b', 'c', 'a'}
set_union = set_a | set_b # 使用 | 运算符
print(set_union) # {'f', 'c', 'b', 'd', 'a', 'e'}
# 求差集
diff = set_a.difference(set_b) # 使用difference()方法
print(diff) # {'b', 'a'}
set_diff = set_a - set_b # 使用 - 运算符
print(set_diff) # {'a', 'b'}六、集合其他用法
1.查看集合所有方法
通过 dir(set) 命令可以查看它有哪些方法:
>>> dir(set)
['add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint',
'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']2.复制集合
# 复制集合
set4 = {1, 3, 5, 7, 9}
set5 = set4.copy()
print(set5) # {1, 3, 5, 7, 9}3.列表去重
# 列表去重
list2 = [1, 1, 1, 3, 4, 5, 6, 6]
set6 = set(list2)
print(set6) # {1, 3, 4, 5, 6}
list3 = list(set6)
print(list3) # [1, 3, 4, 5, 6]七、集合总结
操作 | 用法示例 |
|---|---|
C-创建集合 | 通过{ }创建:setname = {element1,element2,...,elementn}使用set()函数创建:setname = set(iteration) |
R-访问集合元素 | 无序序列,不支持索引查找 |
U-修改集合 | 集合添加元素:setname.add(element) |
D-集合删除元素 | 集合删除元素:setname.remove(element)清空集合:setname.clear() |
其他 | 集合求交集、并集、差集:差集:set3 = set1.difference(set2)交集:set3 = set1.intersection(set2)并集:set3 = set1.union(set2)复制集合:newset = setname.copy() |
- 通过{ }创建:setname = {element1,element2,...,elementn}
- 使用set()函数创建:setname = set(iteration)
R-访问集合元素
- 无序序列,不支持索引查找
U-修改集合
- 集合添加元素:setname.add(element)
D-集合删除元素
- 集合删除元素:setname.remove(element)
- 清空集合:setname.clear()
其他
- 集合求交集、并集、差集:
- 差集:set3 = set1.difference(set2)
- 交集:set3 = set1.intersection(set2)
- 并集:set3 = set1.union(set2)
- 复制集合:newset = setname.copy()
结尾彩蛋🎇
列表、元组、字符串都是有序序列,都可以通过索引(index)获取元素,而字典、集合都是无序序列,无法通过索引获取元素;
列表、字典、集合都是可变序列,而元组、字符串是不可变序列,一旦创建,元素就不能发生变化;
可能有人会疑惑,为什么明明上述提到了字符串可以通过replace()方法替换元素,却要说字符串是不可变元素呢?
那是因为当对字符串进行拼接、替换字符等操作时,会在内存中开辟一个新的内存地址,也就是生成了新的字符串对象,而原始的字符串对象则保持不变。我们通过一段代码简单看一下:
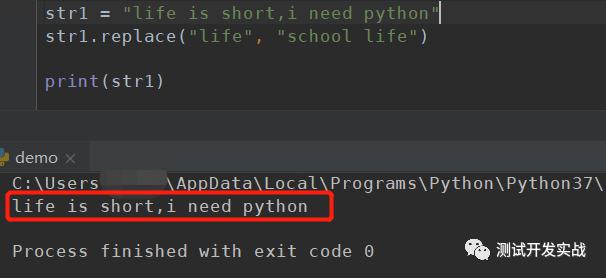
str1 = "life is short,i need python"
str1.replace("life", "school life")
print(str1)打印出来的结果仍然是"life is short,i need python"
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-07-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号