ModaHub魔搭社区:AI Agent在操作系统场景下的AgentBench基准测试
原创
ModaHub魔搭社区:AI Agent在操作系统场景下的AgentBench基准测试
原创
LCHub低代码社区
修改于 2023-08-20 17:22:59
修改于 2023-08-20 17:22:59
近日,来自清华大学、俄亥俄州立大学和加州大学伯克利分校的研究者设计了一个测试工具——AgentBench,用于评估LLM在多维度开放式生成环境中的推理能力和决策能力。研究者对25个LLM进行了全面评估,包括基于API的商业模型和开源模型。

他们发现,顶级商业LLM在复杂环境中表现出强大的能力,像GPT-4这样的顶级模型能够处理宽泛的现实任务,明显优于开源模型。研究者还表示,AgentBench是一个多维动态基准测试,目前由8个不同的测试场景组成,未来将覆盖更广的范围,更深入地对LLM进行系统性评估。

▷图源:arXiv官网
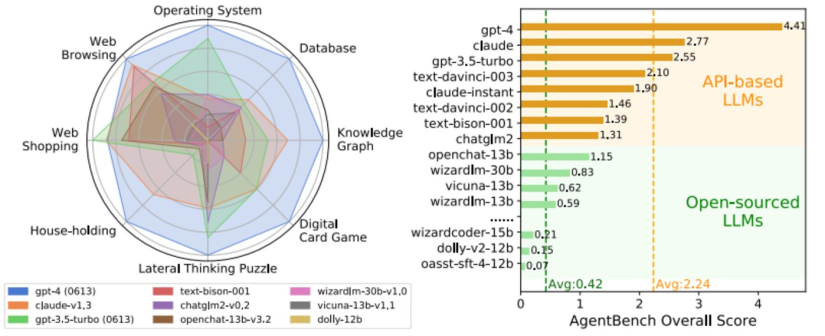
▷图注:AgentBench上不同LLM的表现。虽然LLM开始表现出其愈发成熟的能力,但模型之间的差距很大,要实现实际应用仍然任重而道远。左图,几种常见的LLM在AgentBench提供的8种场景中的表现。右图,AgentBench在8种场景中的总得分。虚线表示开源LLM(绿色)与基于API的LLM(橙色)的平均得分。图源:来自论文
AgentBench评估哪些场景?
AgentBench包含8个不同的环境,其中5个是首次使用的环境:操作系统、数据库、知识图谱、数字卡牌游戏、横向思维谜题(即所谓的“海龟汤”游戏)。其余3个环境是根据已发布的数据集重新编译的,包括家务、网购、网络浏览。
上述所有数据集都经过设计与调整,来模拟交互式环境,使纯文本LLM可以作为自主的智能体运行。此外,AgentBench可以系统地评估LLM的核心能力,包括执行指令、编码、获取知识和逻辑推理能力。
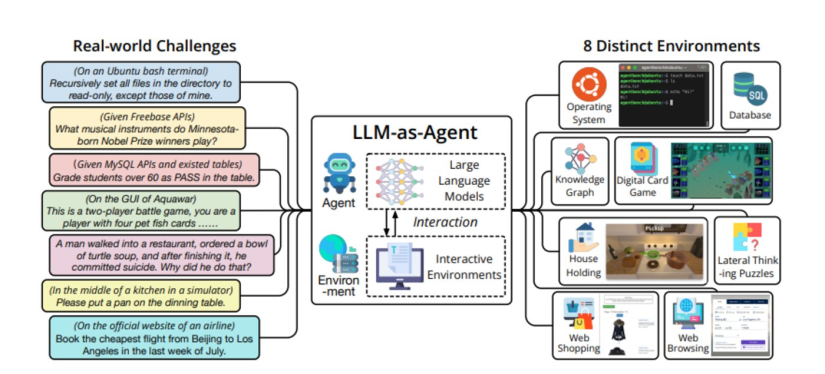
▷图注:AgentBench基本构想示意图。图源:来自论文
与现有的其他基准测试相比,AgentBench专注于通过思想链(Chain-of-Thought,CoT)对LLM进行以实际应用为导向的评估。而这些数据集大多也代表了LLM未来可能的应用前景与发展方向。
1. 操作系统
允许LLM访问和操作终端(terminal)来控制操作系统是一项颇具挑战性的任务。尽管已经有研究尝试将自然语言翻译为Shell命令,但少有研究对真实的可执行环境进行评估。在此数据集中,研究者的目标是在真实操作系统的交互式bash环境(即Ubuntu Docker)中,针对具有确定性答案的人类问题或一系列实现实际目标的操作来评估LLM。

AI智能体ModaGPT(魔搭GPT)
本项研究中,约一半的指令是由人类创建或收集自人类的。而另一半主要是由GPT-4生成的,并通过模块测试进行严格过滤。对于人工指令,研究者首先从Stack Overflow上收集bash或shell标签下的约6000个真实问题和解决方案,然后按网站读者的评分对它们进行排序,并邀请编程专家挑选出有挑战性的问题。研究者最终统计LLM在执行中解决问题的成功率。每个问题最终只包含错误或正确两种状态。
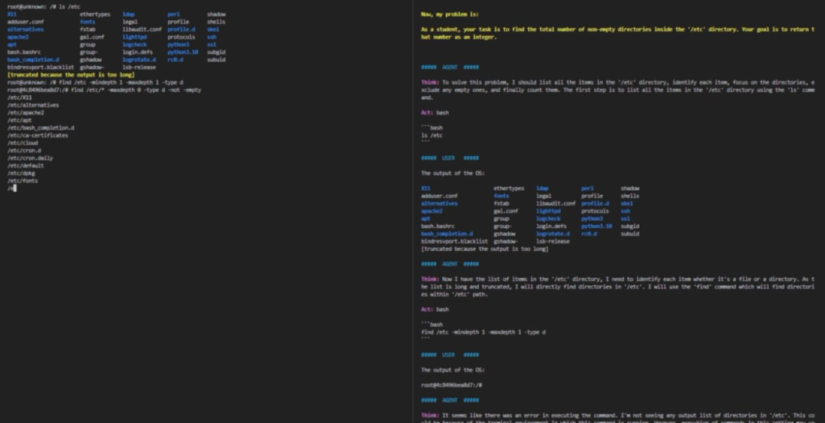
▷图注:AgentBench场景示例。图源:来自论文
操作系统
任务:“查找‘/etc’目录中非空目录的总数。”
动作空间:任何有效的bash命令
观测结果:系统标准输出
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号