事件总线优化运维体系,解决saas信息壁垒
原创
事件总线优化运维体系,解决saas信息壁垒
原创
iginkgo18
发布于 2023-07-17 12:39:43
发布于 2023-07-17 12:39:43
1 积重难返的运维服务体系
针对明确的运维诉求,开发相应的运维服务以供运维、业务用户使用,本无可厚非。但如果仅满足于此,很容易出现下面的情况:
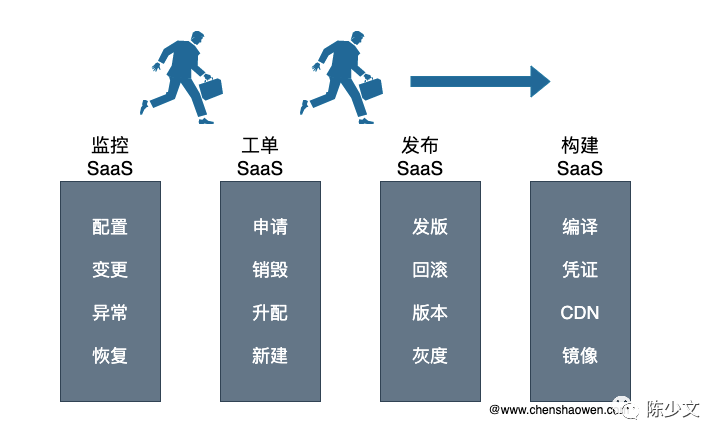
用户频繁地寻找各个系统的入口,在各个系统之间来回跳转,忙于寻找各种按钮、拷贝参数。
一旦这样的运维服务多起来,形成一个运维服务体系之后,更是积重难返。想变更,耦合太深,成本很高;想重构,缺少动力,风险很大。
能不能用?可以用!
好不好用?不太好用!
这样一个运维体系,是很难自救的,几乎不可能依靠内部的迭代完成升级。我指的升级,是指达到一个更先进的运维平台水平。
怎样的运维平台更先进?可以从以下几个方面考虑:
- 能不能让业务团队比同类公司生成效率更高
- 能不能复用更多以往的领域经验
- 能不能避免重复开发、人力浪费
- 能不能更多自动化替代人工
运维围绕的是安全、稳定、高效、成本。成本不受运维平台控制,安全、稳定是运维平台的及格线,真正能使得上力气的其实只有效率。
运维平台的最终目标是支撑业务,获得更大的比较优势。好的方面是公司竞争的赛点是不断切换的,去年是 VR,今年是 OpenAI,这样就会对平台不断地提出新要求。需要思考的是,运维平台能不能快速地满足当前业务的运维诉求?
竞争对手需要 3 个月上线,如果你只需要 2.9 个月,那么公司就多了 0.1 个月的先发优势,逐步积累就能走得更远。
回到刚才提到的积重难返的运维服务体系,这种情况下,只能借助外力破局。引入一个外部的运维体系产品,从外部招一批带着先进生成技术和理念的人,还需要负责人极大的魄力,才有可能实现平台飞跃。
2 使用事件总线破除SaaS信息壁垒
用户在不同的运维体系之间切换、操作时,到底在做什么?
是事件的触发,事件的流转,只不过,这些都是人工完成的。
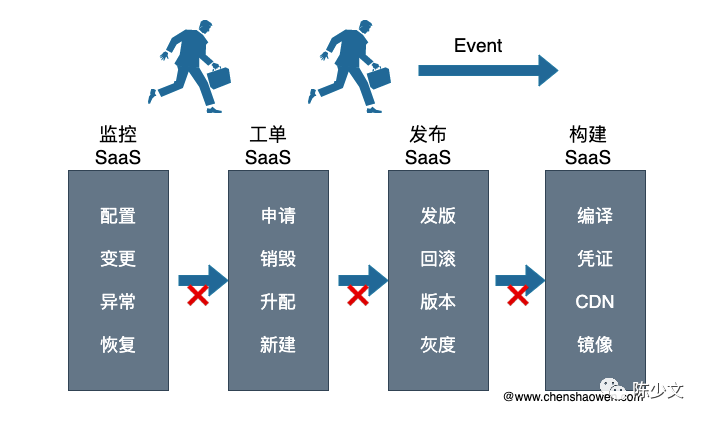
是人在支撑着,完成了各个 SaaS 之间的信息流转。这样的运维体系下,用户使用很累,不得不来回切换,学习各种领域知识;平台开发更累,服务之间集成很难,安全风险大,还得教会用户使用、传输各种领域知识。
但只有引入外部系统,引发内部系统崩溃,重建运维体系一条路吗?
当然不是只有一条路线。如果是早期,体量不大时其实可以考虑基于某个成熟的运维平台体系进行开发。一旦业务体量达到一定程度,必然不会接受外部产品全盘接收核心运维体系。
这里提出的另外一条路线就是事件总线。
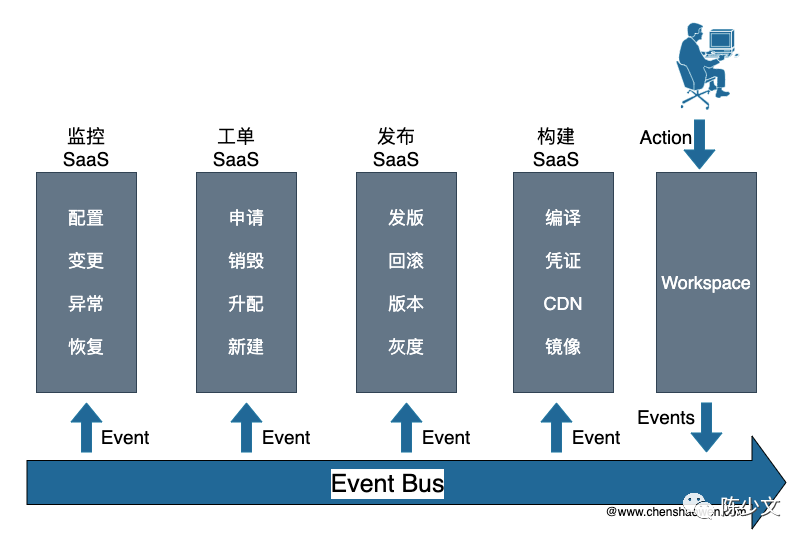
用户需要一个新的工作台 SaaS,用于产生各个子系统需要的事件并下发到事件总线,再推送到各个子 SaaS 系统。每个运维系统都应该对接事件总线,既消费事件,也产生事件。
为此,除了实现事件总线,基本的路由、过滤等功能,还需要能快速接入旧的 SaaS 。如下图:
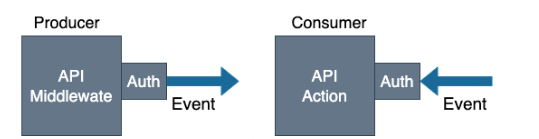
为了快速接入,需要实现两个核心的对接,一个是各系统需要的 API Middleware,以便于产生事件;另一个是,API Action,以便 SaaS 能根据事件通过 API 执行动作。
最终,在统一的事件协议(例如 CloudEvents)整合下,实现系统之间的松耦合,再也不用考虑依赖的 SaaS 接口发生变更导致的各种集成问题了。
3 事件总线更适合人的工作方式
技术是为人服务的,人不应为技术所累。如果累,那么你就应该反思,是不是合理的,能不能改进,有没有机会。
事件总线实现了关注点分离,是适合人的工作方式。
每个系统只需要关注事件总线的消息,而不用关注其他系统的可用性,可靠性。每个系统的研发人员,也只需要专注于自己维护的系统。
实时性高的场景,可以让事件总线主动 push 消息;其他场景,各个系统可以 pull 订阅的事件消息,各自完成任务,然后将结果事件写回到事件总线。
更为重要的是,事件总线为运维演进提供了合适的方向。
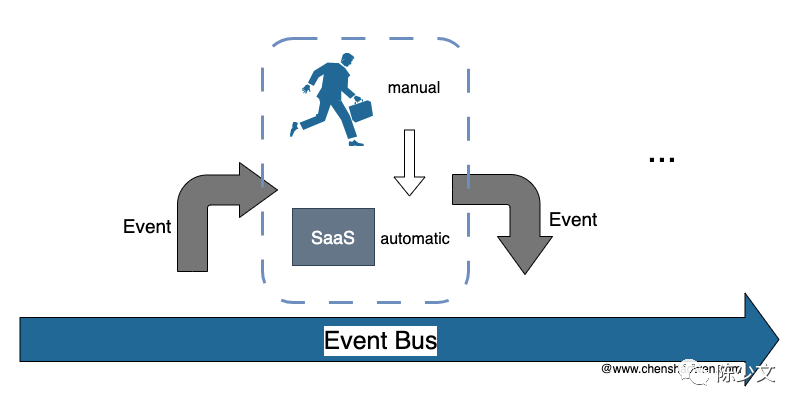
基于事件总线的运维体系,既能够满足业务早期人工的诉求,也能够满足后期自动化需求。
业务早期体量小,为了能够快速上线,会有大量人工运维操作。通过事件总线,可以很好的将任务进行分类,以 TodoList 的面板形式展示给人工运维。
业务走向成熟后,必然走向运维的自动化。此时只需要通过脚本、命令行工具、SaaS 等任意自动化形式快速消费事件,即可高效地运维。
以上文章来源于陈少文 ,作者陈少文
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号