「深度学习」PyTorch笔记-02-线性回归模型


20230421 越学越迷糊~~~
Introduction
线性模型可以看做是单层神经网络:
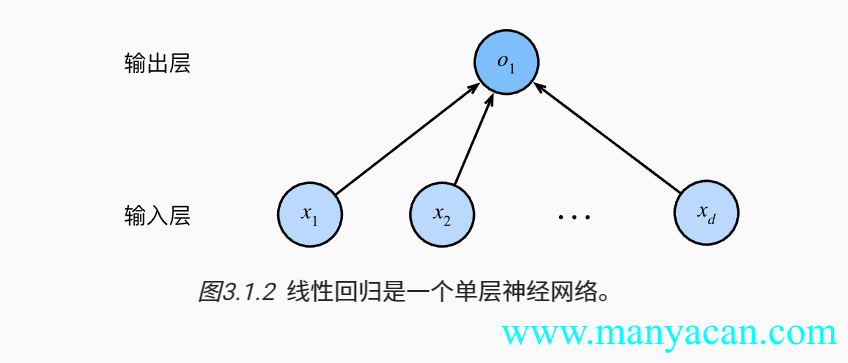
对于单行数据,可以用点积形式来简洁地表达模型:
这里的\mathbf{w}、\mathbf{x}都是一维Tensor,\hat y是一个标量。
而对于特征集合\mathbf{X},预测值\mathbf{\hat y} \in \mathbb{R}^n可以通过矩阵-向量的乘法表示为:
这里的\mathbf{w}是一维Tensor,\mathbf{X}是二维Tensor,\mathbf{\hat y}是一个一维Tensor。
损失函数
对于单行数据,平方误差可以定义为以下公式:
常数1/2的并没有什么实质性作用,仅仅是为了求导后常数项为1而设置。
需计算在训练集n个样本上的损失均值(也等价于求和):
模型的训练过程,就是寻找出一组参数(\mathbf{w}^*, \ b^*),这组参数能最小化在所有训练样本上的总损失:
显示解
将偏差与权重结合起来:
这个时候: $$ \begin{equation*} \begin{split} dim(\mathbf{X}) &= n×(m+1) \\ dim(\mathbf{w}) &= (m+1)×1 \end{split} \end{equation*} $$
合并之后:
Tips / 提示 这个时候:
思路一:
所以损失就可以写成:
Tips / 提示 注意:这里\mathbf{y}-\mathbf{Xw}其实是一个列向量,列向量的内积就等于其L_2范数的平方。
求最优解:
$$ \begin{equation*} \begin{split} \frac{\partial }{\partial \mathbf{w}}\varsigma(\mathbf{X, \ y, \ w}) &= 0 \\ \frac{1}{n}(\mathbf{y-Xw})^T\mathbf{X}&=0 \end{split} \end{equation*} $$
这里运用了复合函数求导,另\mathbf{z=Xw},且\mathbf{v = y-Xw},所以说:
$$ \begin{equation*} \begin{split} \frac{\partial\varsigma }{\partial \mathbf{w}} &=\frac{1}{2n}· \frac{\partial\varsigma }{\partial \mathbf{v}}·\frac{\partial\mathbf{v} }{\partial \mathbf{z}}·\frac{\partial\mathbf{z} }{\partial \mathbf{w}} \\ &=\frac{1}{2n}·\frac{\partial(||\mathbf{v}||^2) }{\partial \mathbf{v}}·\frac{\partial(\mathbf{y-z}) }{\partial \mathbf{z}}·\frac{\partial(\mathbf{Xw}) }{\partial \mathbf{w}}\\ &=2\mathbf{v}^T·I·\mathbf{X} \\ &=\frac{1}{n}(\mathbf{y-Xw})^TX \end{split} \end{equation*} $$
所以说:
$$ \begin{equation*} \begin{split} \frac{\partial\varsigma }{\partial \mathbf{w}}=0\\ \Longleftrightarrow \frac{1}{n}(\mathbf{y-Xw})^TX=0\\ \Longleftrightarrow \mathbf{w}^*=(\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y} \end{split} \end{equation*} $$
Expand / 拓展 这个最后的线性代数移项还是没搞懂,等过几天把知识捡起来再回头看~
思路二:
损失函数为:
$$ \begin{equation*} \begin{split} L_2(\mathbf{w}, \ b) &= \sum_{i=1}^n l^{(i)}(\mathbf{w},\ b) \\ &=(\mathbf{y}-\mathbf{Xw})^2 \end{split} \end{equation*} $$
因为(\mathbf{y}-\mathbf{Xw})是一个一维Tensor——向量,所以:
所以损失函数为:
$$ \begin{equation*} \begin{split} L_2(\mathbf{w}) &= (\mathbf{y}-\mathbf{Xw})^T(\mathbf{y}-\mathbf{Xw}) \\ &= (\mathbf{y}^T-(\mathbf{Xw})^T)(\mathbf{y}-\mathbf{Xw})\\ &= \mathbf{y}^T\mathbf{y}-\mathbf{w}^T\mathbf{X}^T\mathbf{y}-\mathbf{y}^T\mathbf{Xw}+\mathbf{w}^T\mathbf{X}^T\mathbf{Xw} \end{split} \end{equation*} $$
Expand / 拓展
- 标量的交换律是不能用在向量情况中的;
- \mathbf{y}^T\mathbf{y}、\mathbf{w}^T\mathbf{X}^T\mathbf{y}、\mathbf{y}^T\mathbf{Xw}以及\mathbf{w}^T\mathbf{X}^T\mathbf{Xw}都是一个标量;
- (\mathbf{w}^T\mathbf{X}^T\mathbf{y})^T=\mathbf{y}^T(\mathbf{w}^T\mathbf{X}^T)^T=\mathbf{y}^T\mathbf{Xw},又因为两者的结果都是一个标量,所以:
损失函数进一步化简为:
进一步对其进行求导:
因为第一项\mathbf{y}^T\mathbf{y}是一个与\mathbf{w}无关的标量,所以
$$ \frac{\partial (\mathbf{y}^T\mathbf{y})}{\partial \mathbf{w}}= \begin{bmatrix} 0 \\ 0 \\ \cdots \\ 0 \\ \end{bmatrix}_{(m+1)×1} $$
第二项:
Expand / 拓展 这里有一个求导公式:
第三项:
Expand / 拓展 这里有一个求导公式:
对三项进行总结,求导后的结果就是:
另:
$$ \begin{equation*} \begin{split} -2\mathbf{X}^T\mathbf{y} + 2\mathbf{X}^T\mathbf{Xw}^* &= 0 \\ \mathbf{X}^T\mathbf{Xw}^* &= \mathbf{X}^T\mathbf{y} \\ \mathbf{w}^* &= (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y} \\ \end{split} \end{equation*} $$
殊途同归,数学的奥妙~
从零实现线性回归
生成数据集
生成一个包含1000个样本的数据集, 每个样本包含从标准正态分布中采样的2个特征。 我们的合成数据集是一个矩阵 \mathbf{X} \in \mathbb{R}^{1000×2},使用线性模型参数 \mathbf{w}=[2, \ -3.4]^T、b=4.2以及噪声项\epsilon(随机数)生成数据集及其标签:
Tips / 提示 这里需要注意,我们创建了\mathbf{w}、b以及\epsilon,只是为了生成\mathbf{y}。最后,需要通过线性回归梯度下降求出可以使得\mathbf{ \hat y}与\mathbf{y}最接近的\mathbf{w}、b。
编写一个生成随机数据集的函数:
def synthetic_data(w, b, num_examples): #@save
"""
生成y=Xw+b+噪声,
:param w: 数据集矩阵X中每一列特征对应的权重,X有几列特征,其维度就是几
:param b: 偏置
:param num_examples: 需要生成的数量,等于数据集矩阵X的行数
:return: y=Xw+b+噪声
"""
X = torch.normal(0, 1, (num_examples, len(w))) # 生成一个随机的num_examples×len(w)的数据矩阵
y = torch.matmul(X, w) + b # 计算y=Xw+b
y += torch.normal(0, 0.01, y.shape) # y需要加上一个随机噪声
return X, y.reshape((-1, 1)) # 需要保证y为一个n×1的列向量举个?
这个数据集的作用就是用来生成我们使用的随机数据,例如:
In [3]: synthetic_data(torch.tensor([1., 2]), 3, 2)
Out[3]:
(tensor([[-0.6825, 1.3965],
[-1.1661, 1.3457]]),
tensor([[5.0897],
[4.5437]]))上面调用函数的过程其实就是实现了:
$$ \mathbf{y}= \begin{bmatrix} 5.0897 \\ 4.5437 \\ \end{bmatrix}= \mathbf{Xw}+b+\epsilon= \begin{bmatrix} -0.6825 & 1.3965 \\ -1.1661 & 1.3457 \\ \end{bmatrix} \begin{bmatrix} 1.0 \\ 2.0 \\ \end{bmatrix}+ \begin{bmatrix} 3 \\ 3 \\ \end{bmatrix} + \begin{bmatrix} -0.0208 \\ 0.0184 \\ \end{bmatrix} $$
Tips / 提示 需要注意的是,我们在进行定义的时候b=3是一个标量,这里可以利用PyTorch的广播机制,将其转化为一个一维Tensor——[3, \ 3]^T,然后参与了运算。
制造数据
OKay,经过上面的?,相比已经理解了函数的作用,接下来就生成货真价实的用于模拟的数据:
true_w, true_b = torch.tensor([2, -3.4]), 4.2 # 定义w与b
features, labels = synthetic_data(true_w, true_b, 1000)上面的代码根据定义的\mathbf{w}^{2×1}、b^{2×1}创建了数据集 \mathbf{X} \in \mathbb{R}^{1000×2}以及用于拟合对比的\mathbf{y}^{1000×1}。
观察数据
可以通过Pandas来查看数据的分布情况:
data_df = pd.concat([pd.DataFrame(features.numpy()), pd.DataFrame(labels.numpy())], axis=1)
data_df.columns = ['features_x_1', 'features_x_2', 'labels']
data_df也可以采用seaborn可视化绘图查看:
# 可视化生成的随机数据
g = sns.PairGrid(data_df)
g = g.map(plt.scatter)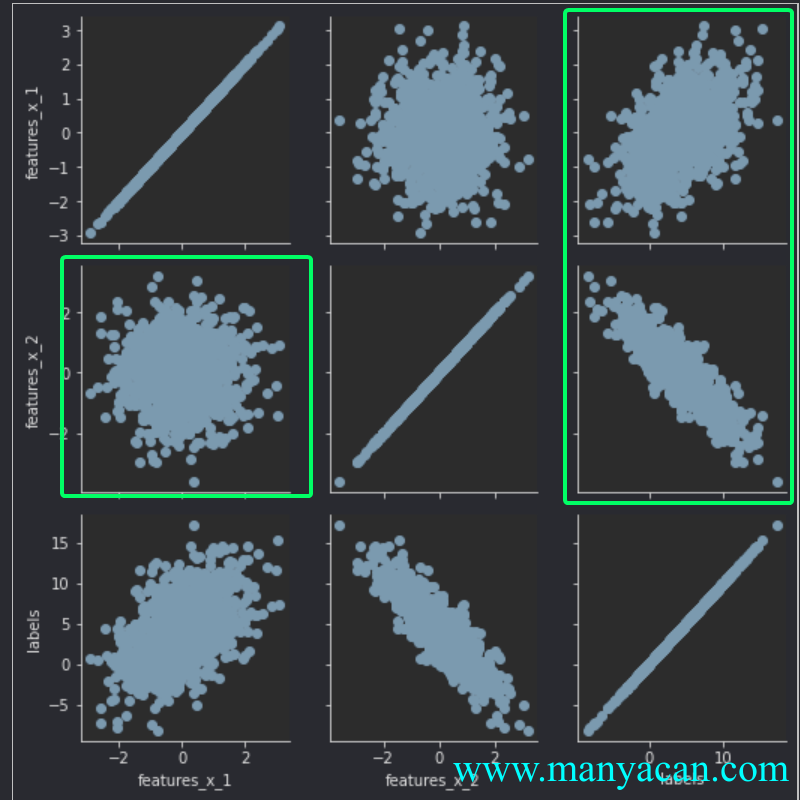
数据分布情况
可以看出\mathbf{X}^{1000×2}数据集的两列特征features_x_1、features_x_2都是服从均值为0的正态分布,同时这两列与labels标签\mathbf{y}都存在明显的线性相关关系。
读取数据集
训练模型时要对数据集进行遍历,每次抽取一小批量样本,并使用它们来更新我们的模型。 由于这个过程是训练机器学习算法的基础,所以有必要定义一个函数, 该函数能打乱数据集中的样本并以小批量方式获取数据。
def data_iter(batch_size, X, y):
"""
从数据集(X, y)中随机抽取batch_size个样本
:param batch_size: 抽取的样本个数
:param X: features数据
:param y: label数据
:return: yield出每一个样本的features以及对应的label
"""
num_examples = len(X) # 获取样本个数
indices = list(range(num_examples)) # 制造一个样本编号,用于随机取样
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices) # 随机打乱编号
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])
yield X[batch_indices], y[batch_indices]
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
breakTips / 提示
- 为什么要使用
yield关键字?因为使用了yield我们可以只对数据进行一次打乱顺序即可。事实上,打乱多次也是没有意义的。 data_iter()函数的作用就是将数据集进行打乱,然后从第一行开始,每次取出来batch_size行数据给for循环里面。- 例如,定义batch_size = 10,那么for循环中收到data_iter()返回的\mathbf{X}的形状为10×2,返回\mathbf{y}的形状为10×1。
定义模型参数、模型、损失函数以及优化算法
模型参数的定义:
在下面的代码中,我们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重\mathbf{w}^{2×1}, 并将偏置b初始化为0。
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)注意:b在这里定义为了一个标量,但是计算的过程中PyTorch会使用广播机制将其转化为一个2×1的Tensor。
模型的定义:
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b损失函数的定义:
def squared_loss(y_hat, y): #@save
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2这里使用.reshape()的原因是防止\mathbf{y}在计算过程中被转化成为了行向量,保持\mathbf{\hat y}与\mathbf{y}为相同的形状,从而可以进行运算。
优化算法的定义:
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()训练
现在我们已经准备好了模型训练所有需要的要素,可以实现主要的训练过程部分了。
在每次迭代中,我们读取一小批量训练样本,并通过我们的模型来获得一组预测。
计算完损失后,我们开始反向传播,存储每个参数的梯度。
最后,我们调用优化算法sgd来更新模型参数。
概括一下,我们将执行以下循环:
- 初始化参数
- 重复以下训练,直到完成计算梯度\mathbf{g} \leftarrow \partial_{(\mathbf{w},b)} \frac{1}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} l(\mathbf{x}^{(i)}, y^{(i)}, \mathbf{w}, b)更新参数(\mathbf{w}, b) \leftarrow (\mathbf{w}, b) - \eta \mathbf{g}
在每个迭代周期(epoch)中,我们使用data_iter函数遍历整个数据集,并将训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数num_epochs和学习率lr都是超参数,分别设为3和0.03。设置超参数很棘手,需要通过反复试验进行调整。我们现在忽略这些细节,以后会在:numref:chap_optimization中详细介绍。
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad(): # 完成一次迭代后,求出损失率
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')线性回归的简洁实现
其实现的思想与上面一章一样,这里主要就是全部采用PyTorch封装好的方法来进行操作。
参考链接:https://zh-v2.d2l.ai/chapter_linear-networks/linear-regression-concise.html
----- END -----
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-04-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号