通过PubTator进行PubMed文本挖掘
原创
通过PubTator进行PubMed文本挖掘
原创
叶子Tenney
发布于 2023-04-28 14:56:52
发布于 2023-04-28 14:56:52
引言
有许多可以从 PubMed 的文章摘要中提取信息的文本挖掘脚本,包括: NLTK , TextBlob , gensim , spaCy , IBM Whatson NLU , PubTator , LitVar , NegBio , OpenNLP 和 BioCreative 等<sup>1</sup>。这里介绍一下 PubTator Central (PTC) <sup>2</sup>。
PubTator Central(PTC) 是一个基于 Web 的系统,提供 PubMed 摘要和 PMC 全文文章中基因和突变等生物医学概念的自动注释。
效果展示
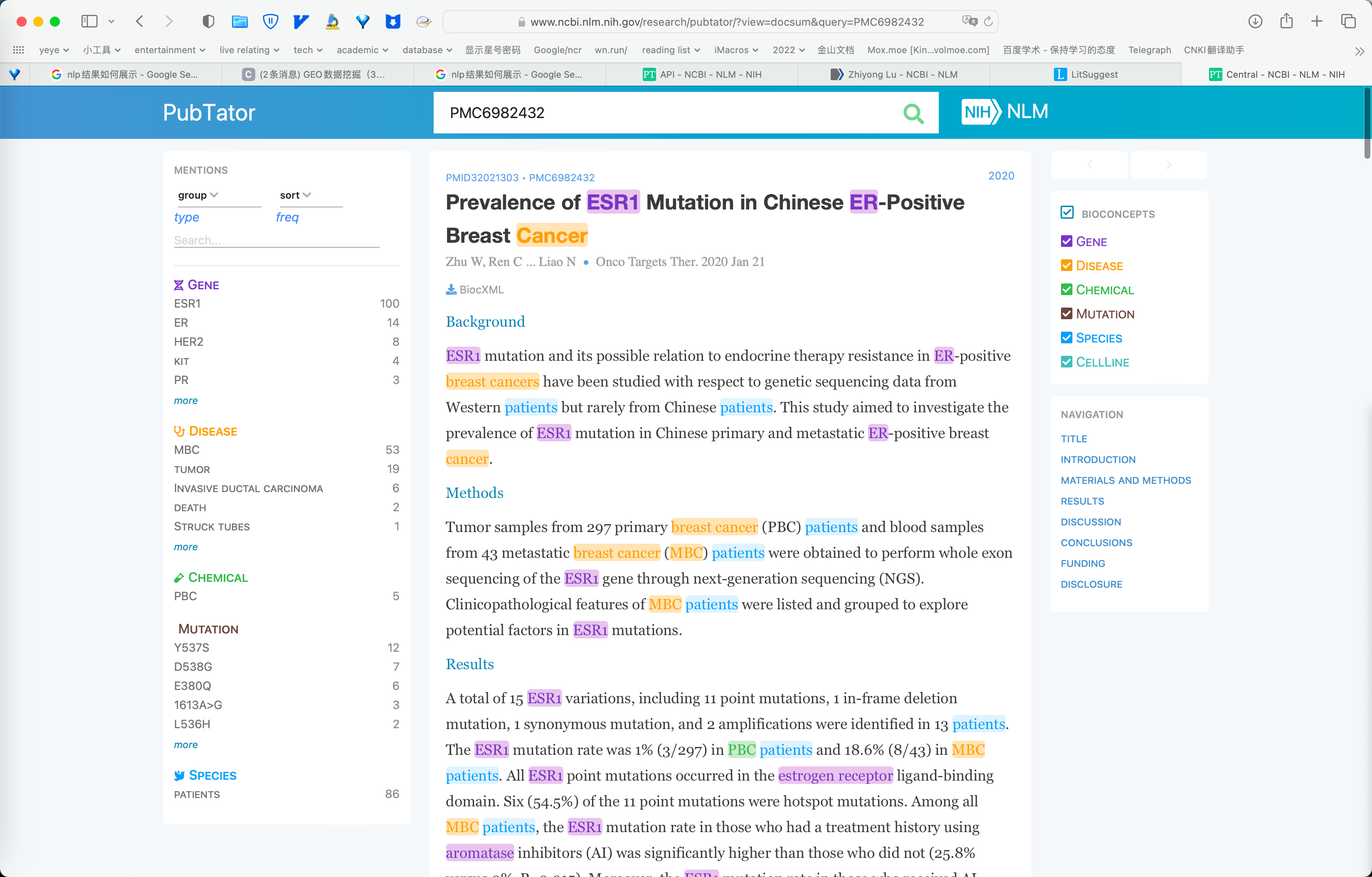
PMC6982432全文的生物医学概念注释 - PubTator
使用方式
PubTator API的使用
PubTator 提供了 API 以导出注释,并提供包括 curl 、 Perl 、 Python 、 Java 在内的四种代码示例。当然,直接通过浏览器访问也是可行的。以 GET 、 POST 、 BioC 、 pubtator 或 JSON 格式批量导出 PubTator 的注释出版物,单次最多以 GET 形式获得 100 份或以 POST 形式获得 1000 份。
在线教程(https://www.ncbi.nlm.nih.gov/research/pubtator/api.html)<sup>3</sup>提供了完整的详细信息和代码示例。
PTC RESTful Web 服务以简单的制表符分隔格式( PubTator 格式)和两种基于 BioC 的格式: BioC-XML 和 BioC-JSON 提供对 PTC 结果的编程访问。 PMC - TM 全文文章需要 BioC-XML 或 BioC-JSON ,但所有三种格式都支持 PubMed 摘要。
PTC RESTful Web 服务 API 的用法:
摘要示例:
https://www.ncbi.nlm.nih.gov/research/pubtator-api/publications/export/pubtator?pmids=26739349,28483577
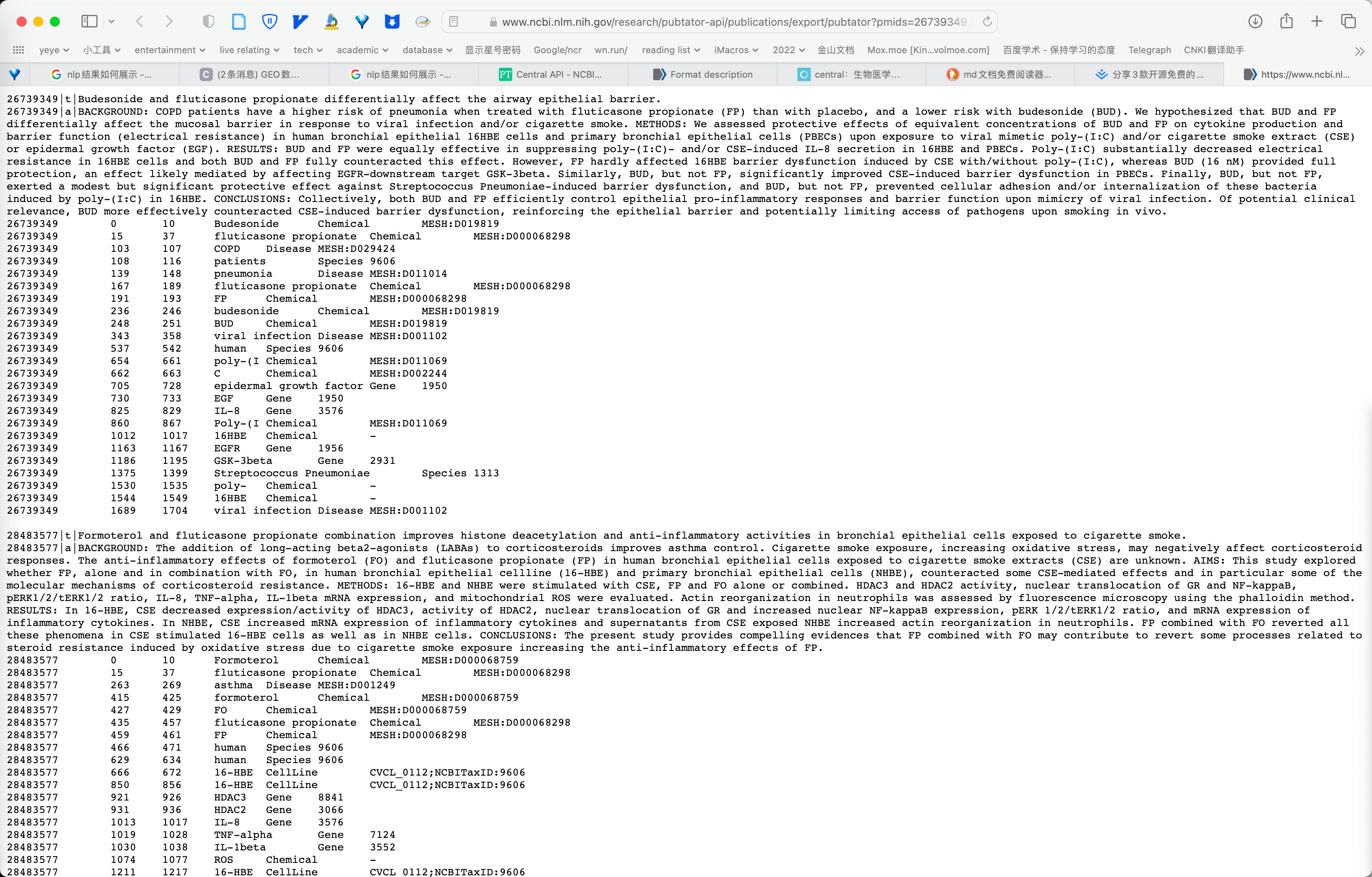
摘要示例
全文示例:
https://www.ncbi.nlm.nih.gov/research/pubtator-api/publications/export/biocxml?pmcids=PMC4743391
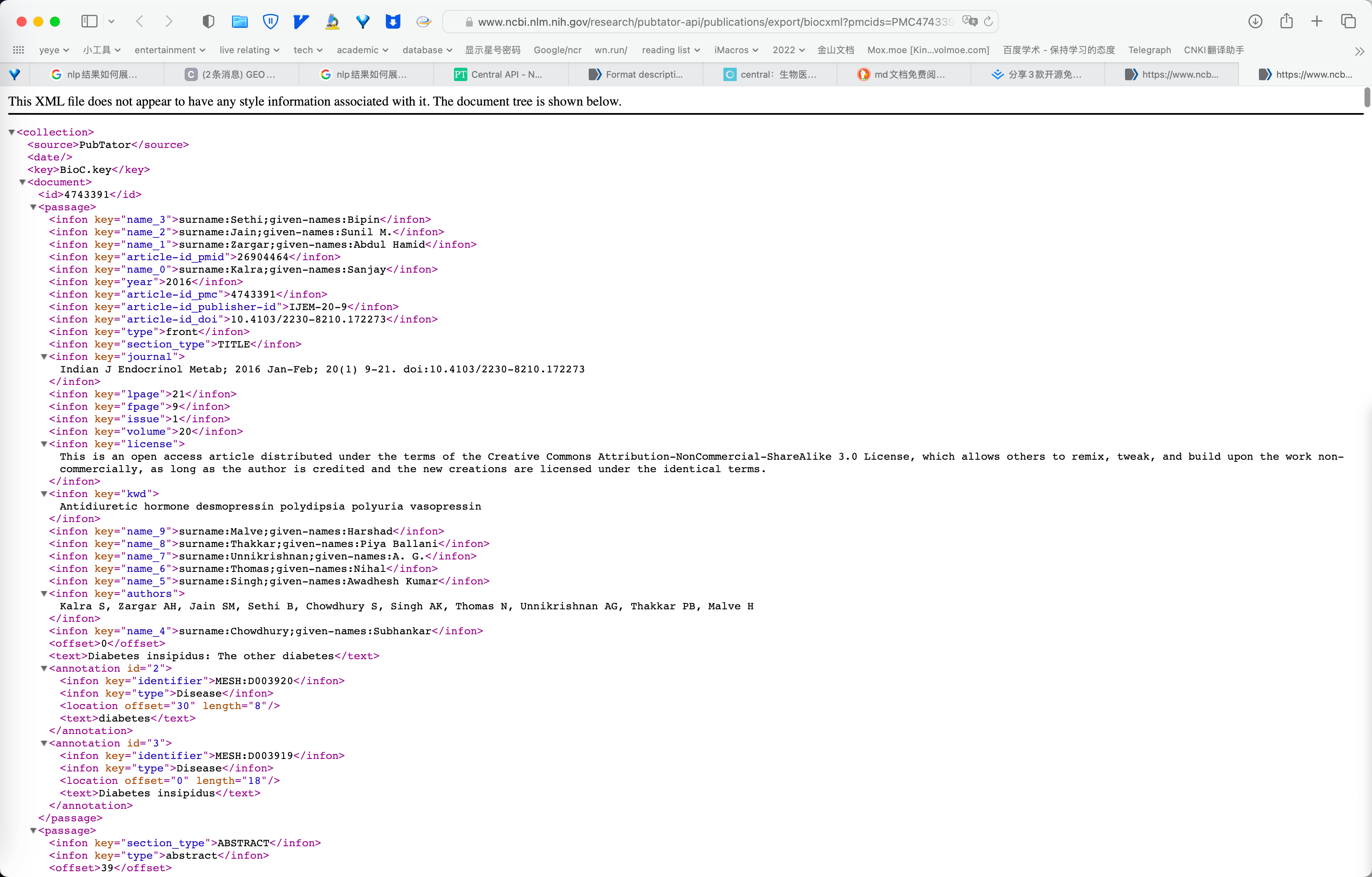
全文示例
因此, 可以使用 curl 命令来获得相应的文档. 如:
curl https://www.ncbi.nlm.nih.gov/research/pubtator-api/publications/export/pubtator?pmids=26739349,28483577
如需获得文件, 在后面添加 -o output.pubtator 即可(对 pubtator 文件).
https://www.ncbi.nlm.nih.gov/research/pubtator-api/publications/export/[Format]?[Type]=[Identifiers]&concepts=[Bioconcepts]PubTator在python中的安装和使用
注: 如仅需要对PubMed文献进行处理, 则无需搭建环境, 存在 `requests` 包即可. 可跳至本文"上传 `PMID` "部分继续观看. conda建立新环境
# conda run
conda create --name py36 python=3.6
conda env list
conda activate py36
conda install virtualenvconda 安装的安装过程详见篇外部分<sup>外1</sup>.
PubTator Python安装
virtualenv -p python3.6 venv
source venv/bin/activate
pip install -r requirements.txt报错处理
ERROR: Could not find a version that satisfies the requirement en-core-sci-sm==0.2.4 (from versions: none)
ERROR: No matching distribution found for en-core-sci-sm==0.2.4根据 scispacy 官网<sup>6</sup>提示:
pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.5.1/en_core_sci_sm-0.5.1.tar.gz进入 requirements.txt 注释 en-core-sci-sm==0.2.4 :
# en-core-sci-sm==0.2.4
再次运行 pip install -r requirements.txt .
PubTator Python使用
上传 PMID
示例:
python SubmitPMIDList.py input_pmid/ex.pmid pubtator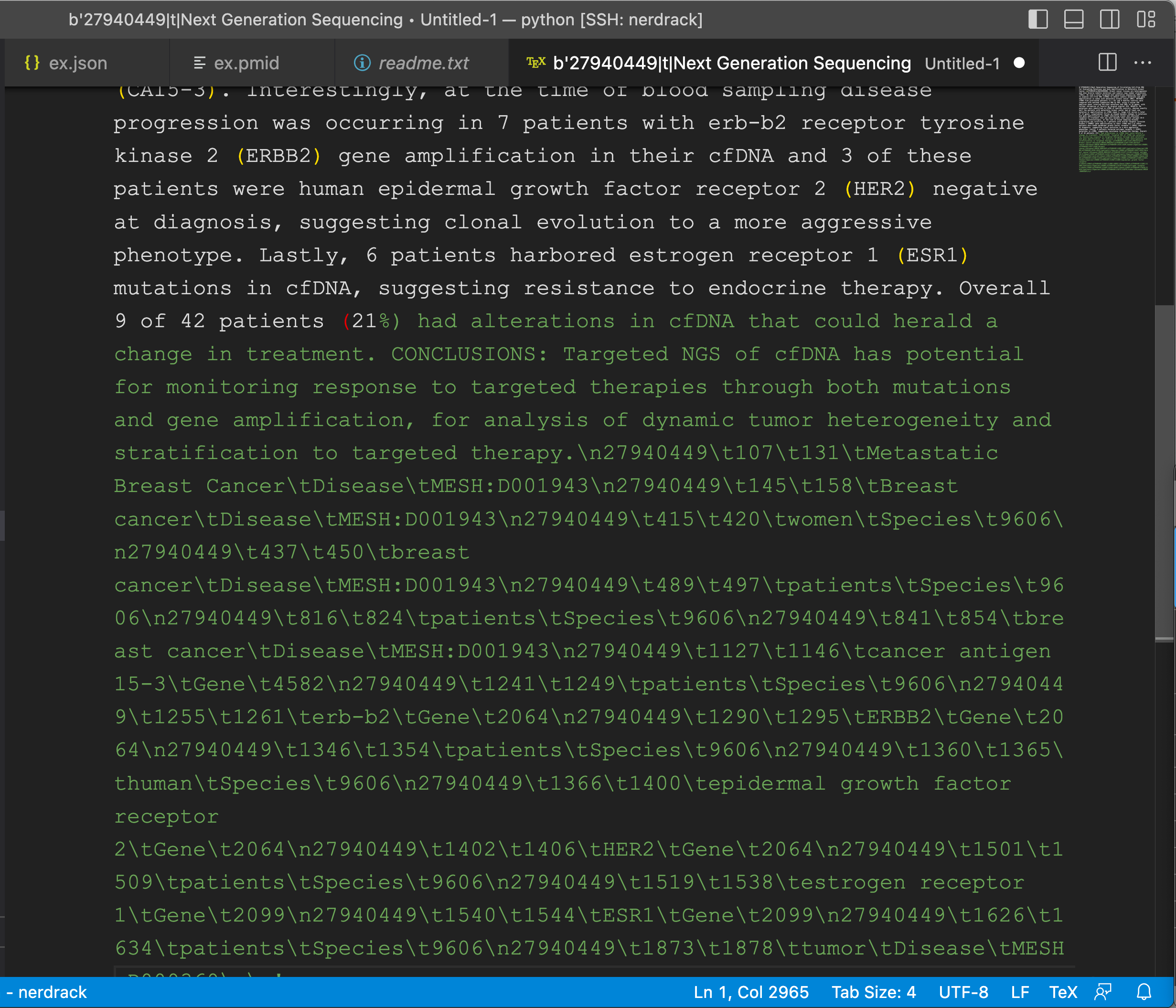
pubtator
$ python SubmitPMIDList.py [InputFile] [Format] [BioConcept]
[Inputfile]: a file with a pmid list
[Format]: 1) pubtator (PubTator)
2) biocxml (BioC-XML)
3) biocjson (JSON-XML)
* Reference for format descriptions: https://www.ncbi.nlm.nih.gov/research/bionlp/APIs/format/
[Bioconcept]: Default (leave it blank) includes all bioconcepts. Otherwise, user can choose gene, disease, chemical, species, proteinmutation, dnamutation, snp, and cellline.
* All arguments are case sensitive.根据文档可知, 可以输出三种格式:
- pubtator (PubTator)
- biocxml (BioC-XML)
- biocjson (JSON-XML)
其中, PubTator 是以制表符分隔的, 可以直接在Excel中打开.
保存文本
在 SubmitPMIDList.py 中查找
else:
print(r.text.encode("utf-8"))并添加
with open('output_'+Inputfile+'.'+Format, 'wb') as f:
f.write(r.text.encode("utf-8"))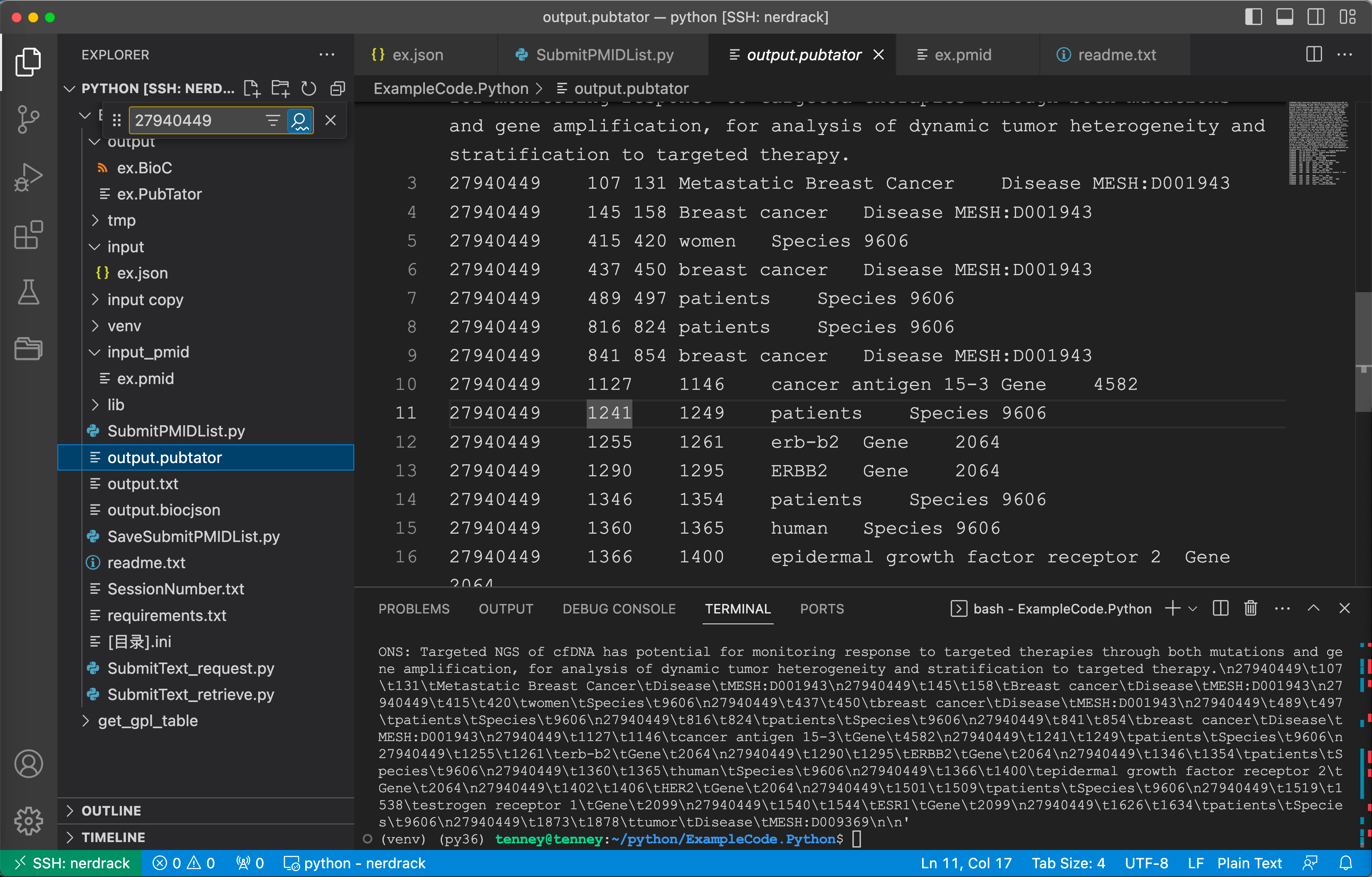
output.pubtator
上传原始文本
同样, 可以上传三种数据格式, 后缀名分别为 BioC 、 PubTator 、 json .
而后根据相应的格式传回处理后的文件.
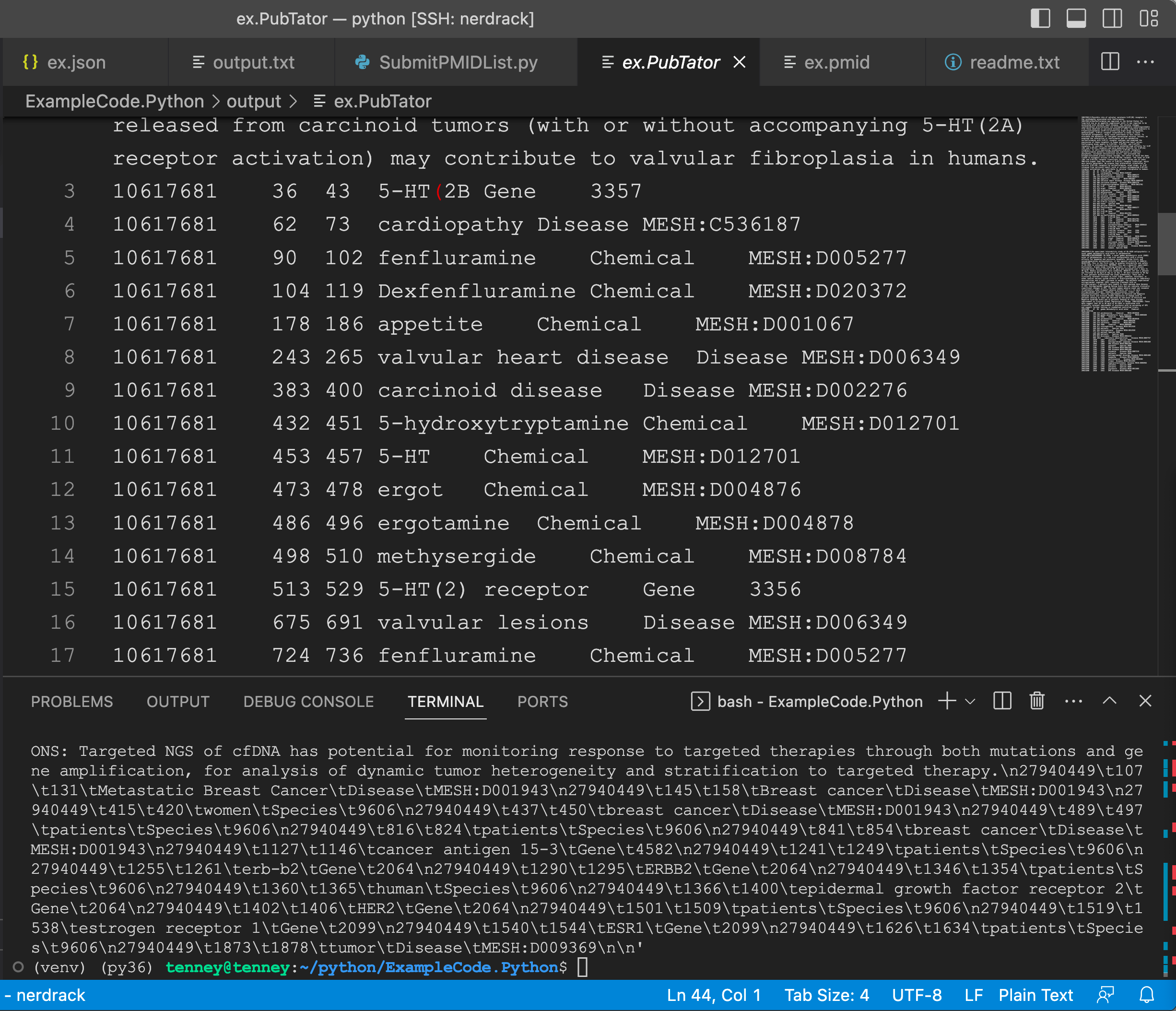
ex. PubTator
# Submitting requests
python SubmitText_request.py input All SessionNumber.txt
# Retrieving results
python SubmitText_retrieve.py input SessionNumber.txt output第一步是提交输入文件并获得服务编号, 第二部是根据服务编号获得文件.
值得注意的是文件处理并不是实时的, 一般都需要10~20分钟. 另外, 官方示例中的 python SubmitText_retrieve.py SessionNumber.txt output 疑似缺少参数, 应添加输入文件夹.
批量上传
代码来自codeium:
Q: 写一个shell脚本将一个纯文本文件每一千行分隔一次, 并输出文件名列表到文件.
A: 下面是一个可以实现您要求的shell脚本,它将一个纯文本文件分隔成每1000行一个文件,并将文件名列表输出到一个文件中:
#!/bin/bash
# 每个文件的行数
LINES=1000
# 输入文件的名称
INPUT_FILE="ex.pmid"
# 文件名前缀
FILE_PREFIX="ex"
# 计数器
count=1
# 读取文件并将其拆分为多个小文件
split -l $LINES $INPUT_FILE $FILE_PREFIX
# 将小文件重命名为您想要的名称格式
for file in $FILE_PREFIX*
do
mv "$file" "${FILE_PREFIX}_${count}.pmid"
count=$((count+1))
done
# 输出文件列表到文件
ls $FILE_PREFIX* > file_names.txt您可以将上面的脚本保存为 split_and_list_to_file.sh 并通过以下方式运行它:
chmod +x split_and_list_to_file.sh
./split_and_list_to_file.sh请注意,此脚本假定输入文件名为 ex.pmid ,每个输出文件包含1000行,并将输出文件命名为 ex_1.pmid , ex_2.pmid 等。如果您需要使用不同的文件名或行数,请相应地更改变量。
另外, 脚本需要 cd 进入 input_pmid 运行.
之后, 对 filenames.txt 中的 ex_1.pmid , ex_2.pmid 等依次运行 python SubmitPMIDList.py inputpmid/ex.pmid pubtator .
#!/bin/bash
# 读取文件列表
for file in $(sort -t_ -k2 -n file_names.txt)
do
# 运行 SubmitPMIDList.py 脚本
python ../SubmitPMIDList.py $file pubtator
done可以将上述脚本保存为 run_submit_pmid.sh ,并通过以下命令执行:
chmod +x run_submit_pmid.sh
./run_submit_pmid.sh总流程:
cd input_pmid
./split_and_list_to_file.sh
./run_submit_pmid.sh
输出结果
结论
至此,通过PubTator进行PubMed文本挖掘的处理结果已经获得,如何展示且待下回分解。
本文所使用代码文件可在公众号后台回复 PubTator提取PubMed文章摘要信息 获得.
另外, PubTator 隶属于 bionlp 项目<sup>7</sup>,除 PubTator 以外该项目组还 LitSuggest 和 TeamTat 等优秀项目,有兴趣的话大家可以一试。
- LitSuggest:一个文献推荐和策展系统。NAR 2021。
- TeamTat:一个协作的文本/语料库注释工具。NAR 2020。
- PubTator:全文文章的自动概念注释。2013年,2019年。
- LitSense:在句子层面理解生物医学文献。NAR 2019。
- LitVar:一个用于基因组变异的语义文献搜索引擎。NAR 2018。篇外
1. conda安装
安装conda:
wget https://repo.continuum.io/miniconda/Miniconda3-latest-$(uname -s)-$(uname -m).sh
# exemple: wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash ./Miniconda3-latest-$(uname -s)-$(uname -m).sh
# exemple: bash ./Miniconda3-latest-Linux-x86_64.sh
source ~/.bashrc中国镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda
conda config --set show_channel_urls yes
conda config --show # 查看新增channels2. 本机安装python3
不推荐, 比较麻烦
sudo apt-get install python
python -V
python3 -Vroot@tenney:/www/wwwroot/mdreader.yeyeziblog.eu.org# whereis python
python: /usr/bin/python3.8-config /usr/bin/python2.7 /usr/bin/python3.8 /usr/lib/python2.7 /usr/lib/python3.8 /usr/lib/python3.9 /etc/python2.7 /etc/python3.8 /usr/local/lib/python2.7 /usr/local/lib/python3.8 /usr/include/python3.8 /usr/share/python
root@tenney:/www/wwwroot/mdreader.yeyeziblog.eu.org# rm /usr/bin/python
root@tenney:/www/wwwroot/mdreader.yeyeziblog.eu.org# ln -s /usr/bin/python3.8 /usr/bin/pythonRuntimeError: failed to find interpreter for Builtin discover of python_spec='python3.6'
ERROR: Cannot uninstall 'certifi'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.引用
- 基于知识图谱的文本挖掘 - 超越文本挖掘 - 专知
- PubTator Central - NCBI - NLM - NIH
- PubTator Central API - NCBI - NLM - NIH
- 怎么在ubuntu安装python
- [原创] Anaconda安装Python 3.6版本 – 编码无悔 / Intent & Focused
- scispacy | SpaCy models for biomedical text processing
- Zhiyong Lu - NCBI - NLM
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号