基于AidLux&AI中台,轻松落地动态人脸识别AI应用
原创

- 引言
该项目由PauIX老师主讲,项目内容涉及人脸识别原理及Retinaface实战、动态人脸识别整体流程实战、AI视觉软件中台人脸识别实战等。
开始课程之前,需要准备一台安卓系统的手机,手机中安装AidLux软件,一般手机的应用市场就有,本次课程需要使用为面向开发者的内测版本AidLux 1.4beta,下载链接如下:
下载链接
百度网盘
https://pan.baidu.com/s/1jzm_Aaw1tuAcqDflitCTvA?pwd=g60t 提取码:g60t
夸克网盘(压缩文件,需解压)
链接:https://pan.quark.cn/s/293a0b5fec0a
然后分享一份此次训练营的物料包,里面是课程使用的代码。
百度云盘链接↓
链接: https://pan.baidu.com/s/15HZmaV8u5HnOulZuVOWCZA?pwd=4vbu
提取码: 4vbu
2. 人脸识别原理及Retinaface实战
2.1 人脸识别的概念
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机和摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行面部识别的一系列相关技术,通常也加做人像识别,面部识别。

2.2 人脸识别的关键技术和流程
**关键技术:**
- 人脸定位:检测范围内出现的人脸、定位、过滤。
- 人脸关键点检测:提取人脸关键点位置,常用有5/21/68/468点定位。
- 人脸追踪:对检测出的人脸进行追踪。
- 人脸图像预处理:光线补偿、直方图均衡化、几何矫正。
- 人脸特征提取:通过深度学习将人脸像素特征转化为多维的特征向量。
- 特征比对:通过对特征间的距离、寻找最相似的两个特征向量。
**人脸识别整体流程**

**人脸识别落地应用**

2.3人脸识别算法Retinaface的训练和数据集
**RetinaFace原理**
详见sansa大佬的博客,这里不展开细讲
https://zhuanlan.zhihu.com/p/103005911
代码地址:
https://github.com/biubug6/Pytorch_Retinaface
**数据集处理**
该地址包含干净的Wideface数据集:https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
这个是数据集官方网站的地址:
http://shuoyang1213.me/WIDERFACE/
下载后的数据集一共包含这三个:

此时的文件夹是只有图片的,然而作者要求的数据格式是:
├── wider\_face: 存放数据集根目录
├── WIDER\_train: 训练集解压后的文件目录
│ └── images:
│ ├── 0--Parade: 对应该类别的所有图片
│ ├── ........
│ └── 61--Street\_Battle: 对应该类别的所有图片
│
├── WIDER\_val: 验证集解压后的文件目录
│ └── images:
│ ├── 0--Parade: 对应该类别的所有图片
│ ├── ........
│ └── 61--Street\_Battle: 对应该类别的所有图片
|
├── WIDER\_test: 训练集解压后的文件目录
│ └── images:
│ ├── 0--Parade: 对应该类别的所有图片
│ ├── ........
│ └── 61--Street\_Battle: 对应该类别的所有图片
│
└── wider\_face\_split: 标注文件解压后的文件目录
├── wider\_face\_train.mat: 训练集的标注文件,MATLAB存储格式
├── wider\_face\_train\_bbx\_gt.txt: 训练集的标注文件,txt格式
├── wider\_face\_val.mat: 验证集的标注文件,MATLAB存储格式
├── wider\_face\_val\_bbx\_gt.txt: 验证的标注文件,txt格式
├── wider\_face\_test.mat: 测试集的标注文件,MATLAB存储格式
├── wider\_face\_test\_filelist.txt: 测试的标注文件,txt格式
└── readme.txt: 标注文件说明所以我们还少了数据的索引文件,这时候要使用作者提供的脚本wider_val.py,将图片信息导出成txt文件:
# -\*- coding: UTF-8 -\*-
'''
@author: mengting gu
@contact: 1065504814@qq.com
@time: 2020/11/2 上午11:47
@file: widerValFile.py
@desc:
'''
import os
import argparse
parser = argparse.ArgumentParser(description='Retinaface')
parser.add\_argument('--dataset\_folder', default=r'E:\pytorch\Retinaface\data\widerface\WIDER\_val\images/', type=str, help='dataset path')
args = parser.parse\_args()
if \_\_name\_\_ == '\_\_main\_\_':
# testing dataset
testset\_folder = args.dataset\_folder
testset\_list = args.dataset\_folder[:-7] + "label.txt"
with open(testset\_list, 'r') as fr:
test\_dataset = fr.read().split()
num\_images = len(test\_dataset)
for i, img\_name in enumerate(test\_dataset):
print("line i :{}".format(i))
if img\_name.endswith('.jpg'):
print(" img\_name :{}".format(img\_name))
f = open(args.dataset\_folder[:-7] + 'wider\_val.txt', 'a')
f.write(img\_name + '\n')
f.close()导出后的完整格式如下:
为了进一步方便大家理解txt文件内容的含义,我们打开wider_face_train_bbx_gt.txt文件,比如第一行0--Parade/0_Parade_marchingband_1_849.jpg代表图片的路径,第二行的1代表在该图片中人脸的数量为1个。第三行449 330 122 149 0 0 0 0 0 0为人脸的详细信息。从第四行开始又是另一张图片,以此类推。
0--Parade/0\_Parade\_marchingband\_1\_849.jpg
1
449 330 122 149 0 0 0 0 0 0
0--Parade/0\_Parade\_Parade\_0\_904.jpg
1
361 98 263 339 0 0 0 0 0 0
0--Parade/0\_Parade\_marchingband\_1\_799.jpg
21
78 221 7 8 2 0 0 0 0 0
78 238 14 17 2 0 0 0 0 0
113 212 11 15 2 0 0 0 0 0
134 260 15 15 2 0 0 0 0 0
163 250 14 17 2 0 0 0 0 0
201 218 10 12 2 0 0 0 0 0
182 266 15 17 2 0 0 0 0 0
245 279 18 15 2 0 0 0 0 0
304 265 16 17 2 0 0 0 2 1
328 295 16 20 2 0 0 0 0 0
389 281 17 19 2 0 0 0 2 0
406 293 21 21 2 0 1 0 0 0
436 290 22 17 2 0 0 0 0 0
522 328 21 18 2 0 1 0 0 0
643 320 23 22 2 0 0 0 0 0
653 224 17 25 2 0 0 0 0 0
793 337 23 30 2 0 0 0 0 0
535 311 16 17 2 0 0 0 1 0
29 220 11 15 2 0 0 0 0 0
3 232 11 15 2 0 0 0 2 0
20 215 12 16 2 0 0 0 2 0 数据集的格式介绍引用了两位大佬的博客内容,详解大家可以看两位大佬的博客,博客链接如下:
PauIX老师提供了转换后的txt文件,大家可以直接使用。
https://pan.baidu.com/s/1Laby0EctfuJGgGMgRRgykA
**模型训练**
python train.py --network mobile0.25 如有需要,请先下载预训练模型,放在weights文件夹中。如果想从头开始训练,则在data/config.py文件中指定'pretrain': False。
2.4 本节课的小作业
原来的detect.py只能检测图片,新建detect\_video.py实现视频检测,在detect.py的基础上进行修改,修改的代码位于main函数中,具体修改如下:
# testing begin
# for i in range(100):
image\_path = "./curve/Kuangbiao.mp4"
save\_path = "./results/testout.mp4"
img\_raw = cv2.VideoCapture(image\_path)
frames = int(img\_raw.get(cv2.CAP\_PROP\_FRAME\_COUNT))
size = (int(img\_raw.get(cv2.CAP\_PROP\_FRAME\_WIDTH)), int(img\_raw.get(cv2.CAP\_PROP\_FRAME\_HEIGHT)))
fourcc = cv2.VideoWriter\_fourcc(\*'XVID')
out = cv2.VideoWriter(save\_path, fourcc, 25.0, size)
for j in range(frames):
ref, frame = img\_raw.read()
img = np.float32(frame)
im\_height, im\_width, \_ = img.shape
scale = torch.Tensor([img.shape[1], img.shape[0], img.shape[1], img.shape[0]])
img -= (104, 117, 123)
img = img.transpose(2, 0, 1)
img = torch.from\_numpy(img).unsqueeze(0)
img = img.to(device)
scale = scale.to(device)
tic = time.time()
loc, conf, landms = net(img) # forward pass
print('net forward time: {:.4f}'.format(time.time() - tic))3. AidLux部署Retinaface
AidLux部署Retinaface的流程,大家可以观看本次训练营的课程,这里不再展开讲。笔者此前也参加过训练营并写了博客,博客中详细介绍了AidLux的使用说明以及算法在AidLux平台部署的过程,大家可以参考着部署人脸识别算法Retinaface。
https://blog.csdn.net/weixin_42538848/article/details/129256231
4. AI视觉算法开发平台介绍及使用
AI视觉算法开发平台,是华勤技术基于自研结构化架构+海量自研AI算法+算法应用/训练/开发功能的一站式AI应用解决方案平台,可跨平台部署,支持一体机/服务器/云端多场景使用。任何想要给自己AI赋能的团队或者个人,无需额外人力,都能快速拥有AI算法开发的能力。

**华勤AI中台的使用**
首先打开手机端的AidLux,然后点击应用中心,在应用中心里下载安装aid-IVS软件,安装后才能在进入AI中台。具体流程如下:
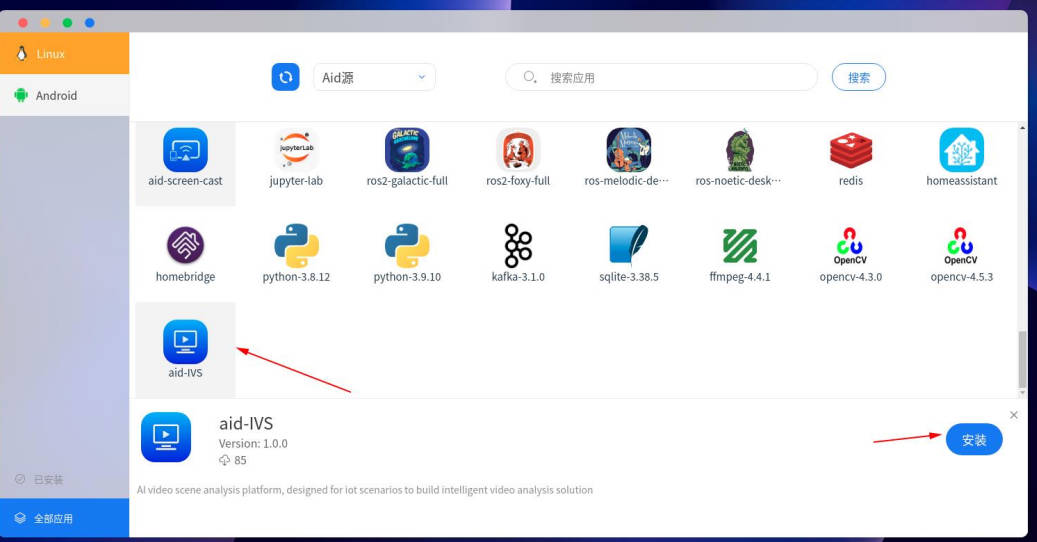
安装完成aid-IVS后,打开终端,cd至zhongtai目录,执行bash start.sh脚本。
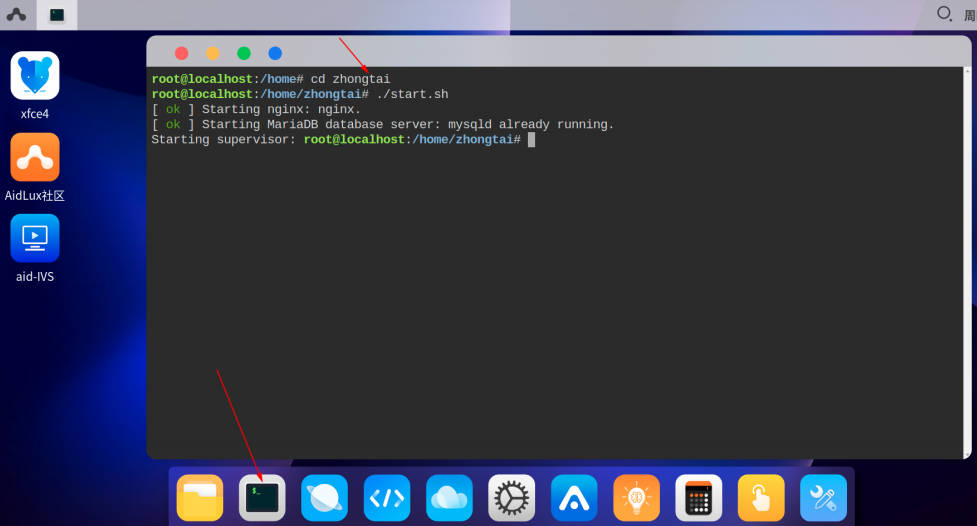
之后再重新打开一个网页,将8000端口改为8088即可打开中台:
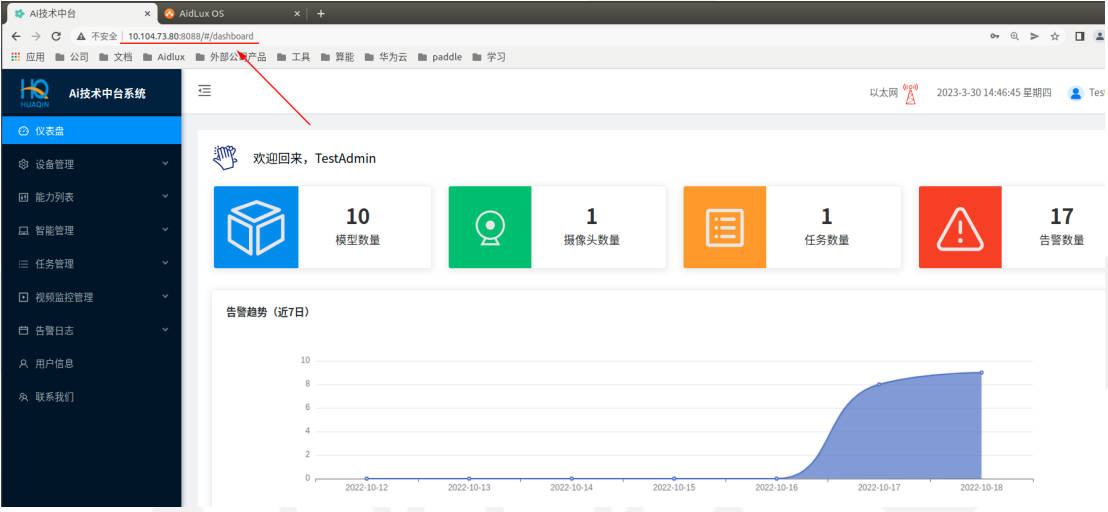
笔者录制了一份AI中台部署人脸识别算法的操作视频,按照训练营课程内容模拟动态人脸识别全流程,尝试在AI技术中台系统中加载自己的视频流,运行人脸识别项目,完成整个流程的串联。
5. 学习心得
笔者最近也在尝试做人脸识别算法,通过AidLux动态人脸识别AI实战训练营的学习,对于人脸识别算法在AidLux平台和AI中台的部署应用有了新的认识,从中受益良多,在此感谢成都阿加犀公司和华勤公司提供的学习平台,感谢PauIX老师的授课。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号