最佳实践 | 基于腾讯云MRCP-Server打造简单智能外呼系统
原创
最佳实践 | 基于腾讯云MRCP-Server打造简单智能外呼系统
原创
腾讯云AI
修改于 2023-04-06 15:02:04
修改于 2023-04-06 15:02:04
一、智能外呼架构简介
智能外呼在国内已发展多年,整体的技术早已非常成熟。那么一个简单的智能外呼系统应该包含哪些东西呢?
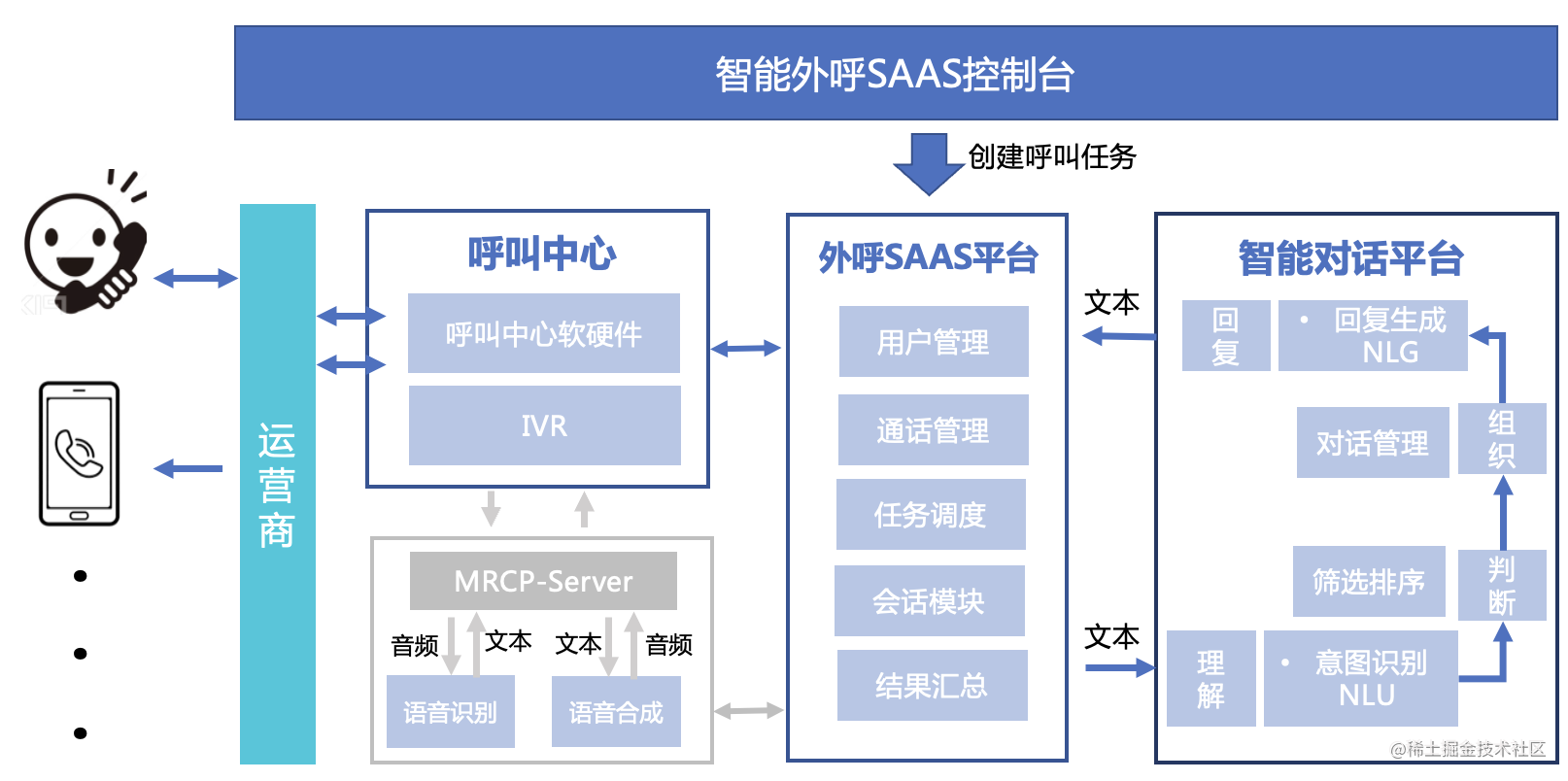
- 运营商:运营商的线路资源是外呼系统的基础,国内就是移动、联通、电信,也有一些集成商。
- 呼叫中心:呼叫中心相关的软硬件用来对接运营商线路,市面上成熟产品很多,各大云厂商也都有相关的云服务。
- 开源方案也有一些,如freeswitch、asterisk,网上有很多的资料可以参考。
- 外呼SAAS平台:用来串起来整个通话流程,这部分的实现相对来说最容易,国内各厂商基本都是自研
- AI能力:语音识别、语音合成、以及智能对话平台能力,关乎到智能外呼系统核心的体验、是否智能、拟人化等
智能外呼简单流程
上面介绍了智能外呼系统的大概组成,那具体是如何运行的呢?下面是一个简单的疫情调研外呼电话例子。
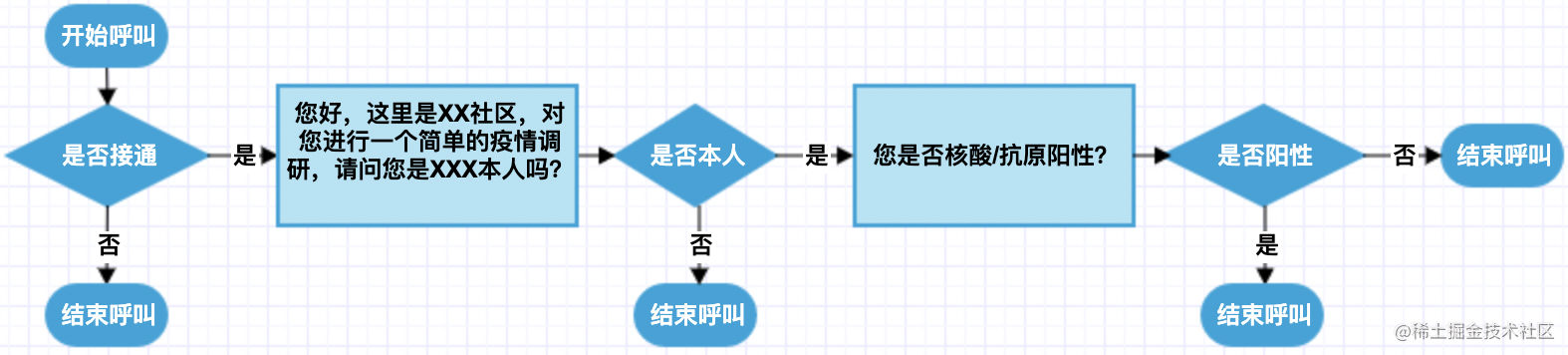
示例中,存在两轮对话,方框内容为机器人语音播报,两次回答“是否本人”、“是否阳性”是客户回答,走语音识别后进行判定。
在智能外呼系统中,对接语音识别和语音合成的部分,通常来说有两种方式:
- 外呼SAAS平台直接调用语音识别、语音合成
- 这种方式一般用完整的客户音频流去做语音识别(以便支持播报中打断、播报中关键词逻辑、播报中打断&回复等功能)
- 通过IVR调用MRCP-Server接口来调用语音识别、语音合成
- 每次语音识别的音频,是机器人播报后,触发识别的一小段音频(类似上面示例中,就是“是否本人”“是否阳性”两段回答的语音片段)
下面我们分别看下两种方式对应的序列图。
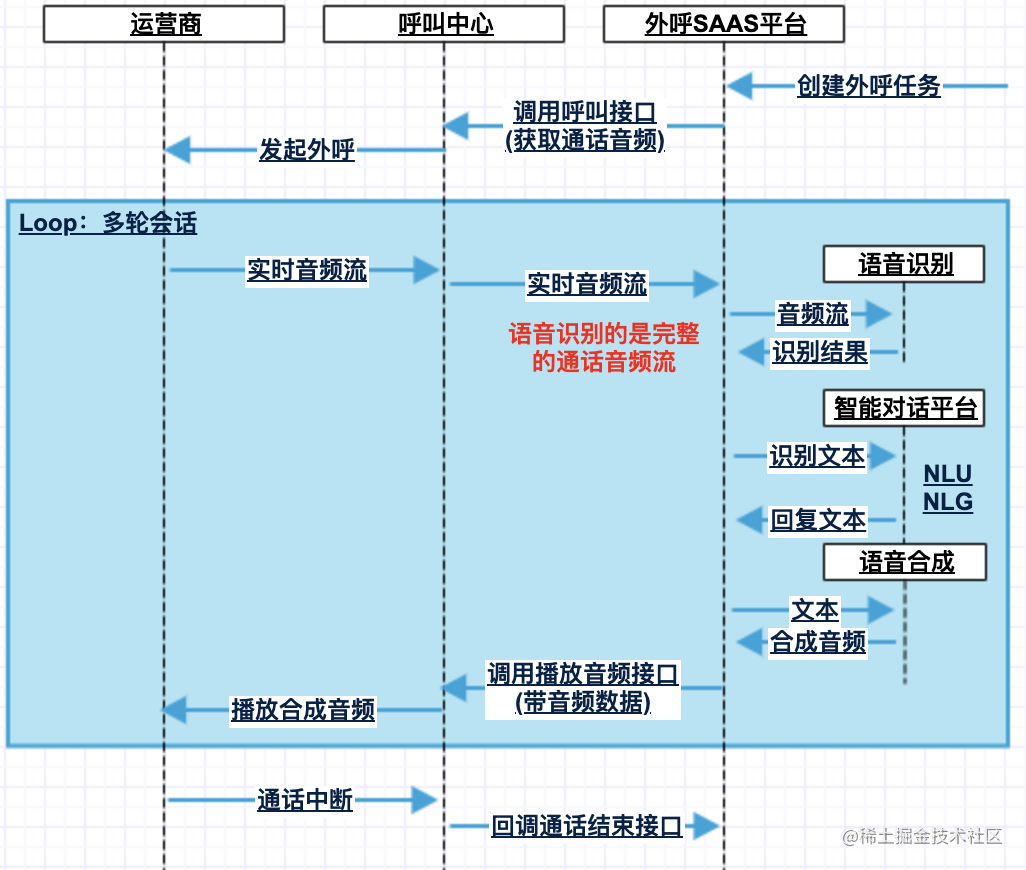
无MRCP-Server流程
- 该方案的开发成本较高,通话流程的控制逻辑很大一部分在“外呼SAAS平台”内,且要对接语音识别、语音合成、智能对话平台等部分
- 外呼通话接通的时候,客户的音频流就持续推到外呼SAAS平台,音频流持续送入语音识别,得到实时识别结果
- 完整通话识别结果可以用来实现机器人播报中打断、播报中客户关键词识别&处理(如转人工、新回复等)等
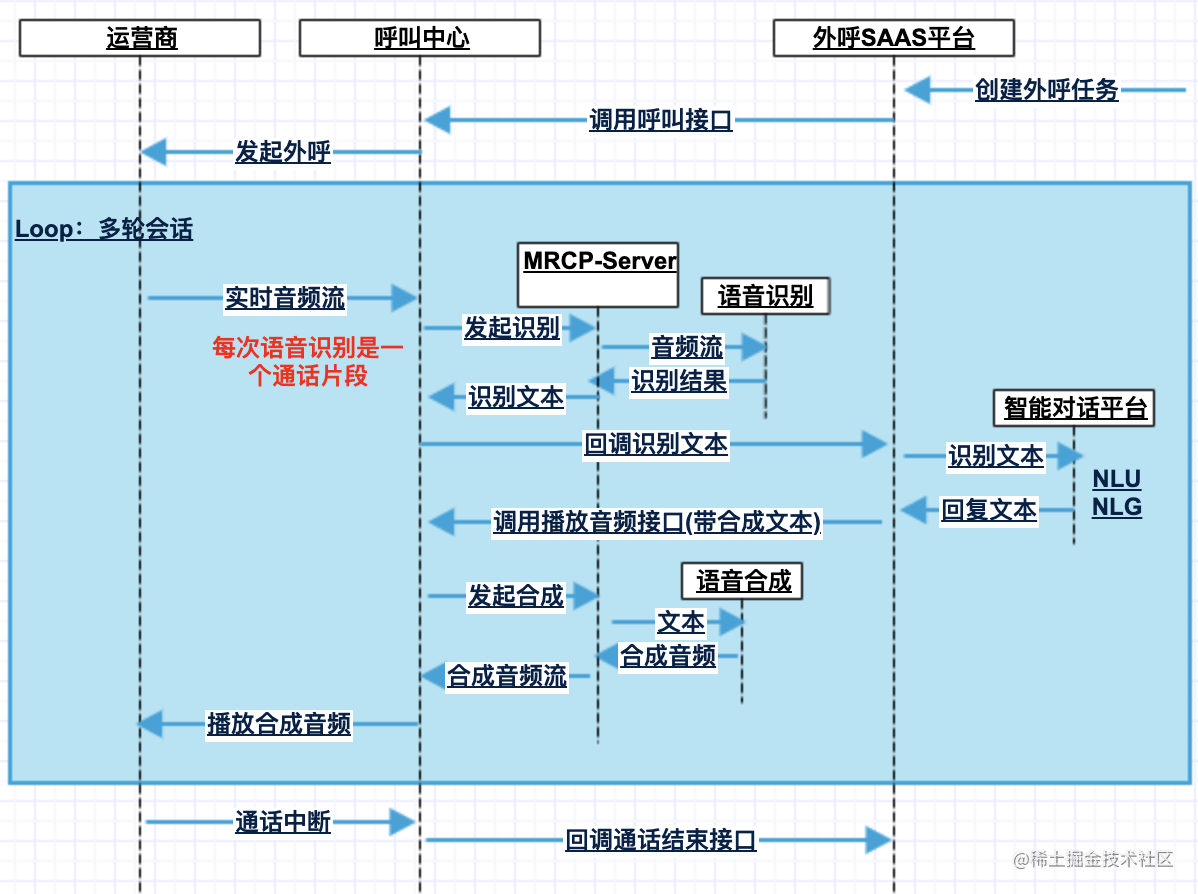
有MRCP-Server流程
- 该方案的开发成本相对2.1要低不少,对接语音识别、语音合成的MRCP-Server一般各大厂商有现成的组件,不用去开发
- 该方案只有机器人播报完/被打断后,才会调用mrcp-server启动识别,送入客户音频去做语音识别
MRCP作为标准协议,基本市面上的呼叫中心都是支持的,对接起来也较容易,下面讲一下笔者对接腾讯云MRCP-Server的过程。
二、腾讯云MRCP-Server对接
开始对接之前,我们需要先开通腾讯云的语音识别、语音合成服务。
开通语音识别&语音合成
分别点击 腾讯云语音识别控制台 ,腾讯云语音合成控制台, 点击立即开通服务。
可以点击这里领取一个新人的体验资源包: https://cloud.tencent.com/product/asr
获取调用服务的API密钥
访问腾讯云的服务,都需要一个秘钥,在腾讯云访问管理的API密钥管理页面,可以新建一个秘钥,这个一定要保管好,不能泄露出去,防止被盗用。秘钥后面我们要用到。
MRCP-Server部署
腾讯云的MRCP-Server有现成的部署包,不用自己开发对接ASR&TTS,可以大大节约时间。
只要你有一个干净的linux环境,进行部署。部署环节分位以下几步:
- 解压 unimrcp.tar.gz 到部署路径
- 修改配置文件,运行 change.sh分发配置文件
- 启动&测试验证
下载&解压
- 点击 MRCP-Server部署包 下载部署包,传输到干净的linux环境
- 指定一个安装目录,这里使用 $project_path 来代表安装目录
- 执行解压命令:
tar -xzvf unimrcp.tar.gz -C $project_path修改配置
执行以下命令,打开配置文件:
cd $project_path/unimrcp/admin
vim conf.ini配置文件中各字段含义,可参考文件中注释,可以按照实际需要修改server_ip、server_sip_port、server_mrcp_port等配置。
请将3.2章节中,从官网获得的 appid、secretid、secretkey 填写到配置文件中对应位置。
#公有云用户AppID
appid=1233
#公有云用户SecretID
secretid=123
#公有云用户SecretKey
secretkey=demokey123修改完配置后,执行以下命令分发配置。
cd $project_path/unimrcp/admin
sh change.sh服务启动
运行以下命令启动服务:
cd $project_path/unimrcp/admin
sh start_server.sh成功启动会有如下提示:

运行如下命令也可确认是否成功启动。
netstat -anp | grep mrcp如成功启动,会看到2个tcp端口,1个udp端口

服务测试
进入admin使用unimrcpclient来测试MRCP服务,执行如下命令:
cd $project_path/unimrcp/admin
sh start_client.sh 进入命令行界面,如下:
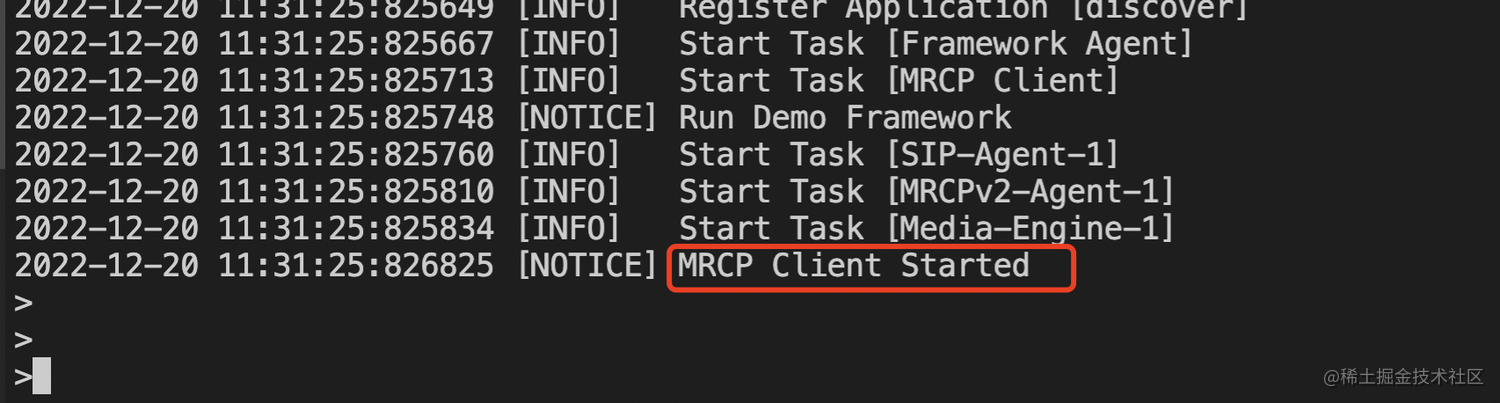
在交互输入栏输入“run recog” 来测试语音识别功能。
run recog如果执行成功会出现类似如下结果:
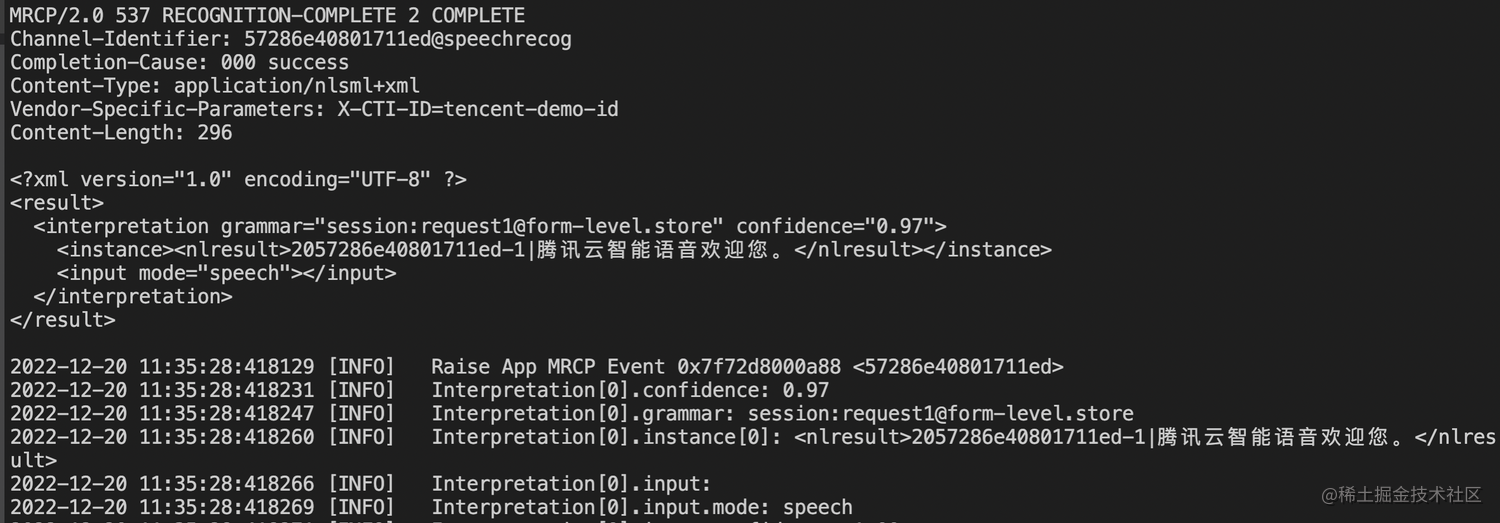
如果还想测试语音合成能力,可以在交互输入栏输入“run synth” 可以测试。客户端显示出识别出结果为:“欢迎使用腾讯云语音合成”,则表示客户端发送文本正常。
对于返回的合成音频,可以检查$project_path/unimrcp/var/synth中的相应的音频,确认音频是否正常。
MRCP-Server对接
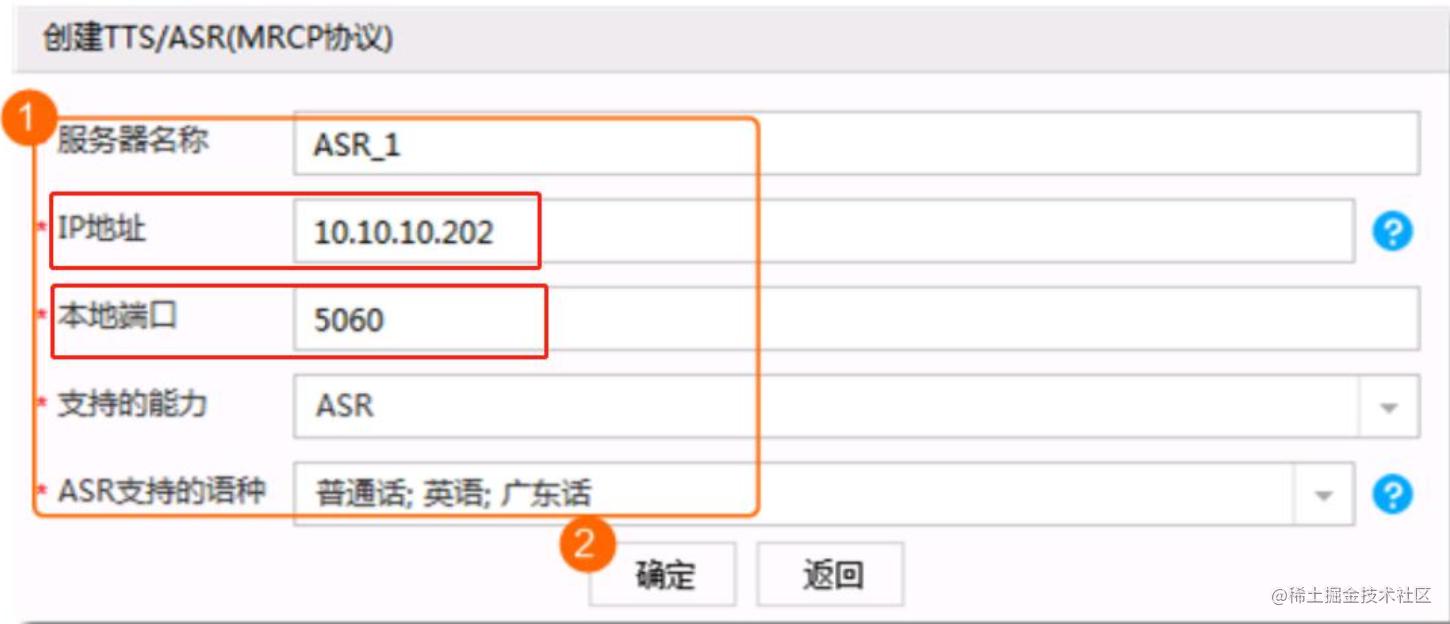
只需对接 MRCP Server 的 IP 和 SIP 端口即可。
需要注意的是腾讯云MRCP Server使用的协议版本为MRCPv2。
参考3.3.3章节,可以获得对应配置,或者去修改对应的端口号。通过ifconfig命令获取机器IP。如下图,5060是sip端口号。

下面给出对接华为IVR的一个实例:
如果使用Freeswitch来对接的话,在profile里面设置即可,如下图:

MRCP协议识别流程简介
关于MRCP协议这里就不多说了,可以参考MRCP协议手册:https://www.rfc-editor.org/rfc/rfc6787
目前大家围绕MRCP的开发,基本都是基于开源软件Unimrcp,它完整实现了MRCP协议(含SIP/RTSP/MRCP/RTCP/RTP)
MRCP使用SIP协议来控制整个音频资源的通信流程,RTP作为实际的音频数据的承载协议,RTCP负责RTP过程中的Qos。
下面是MRCP调用语音识别服务的序列图:
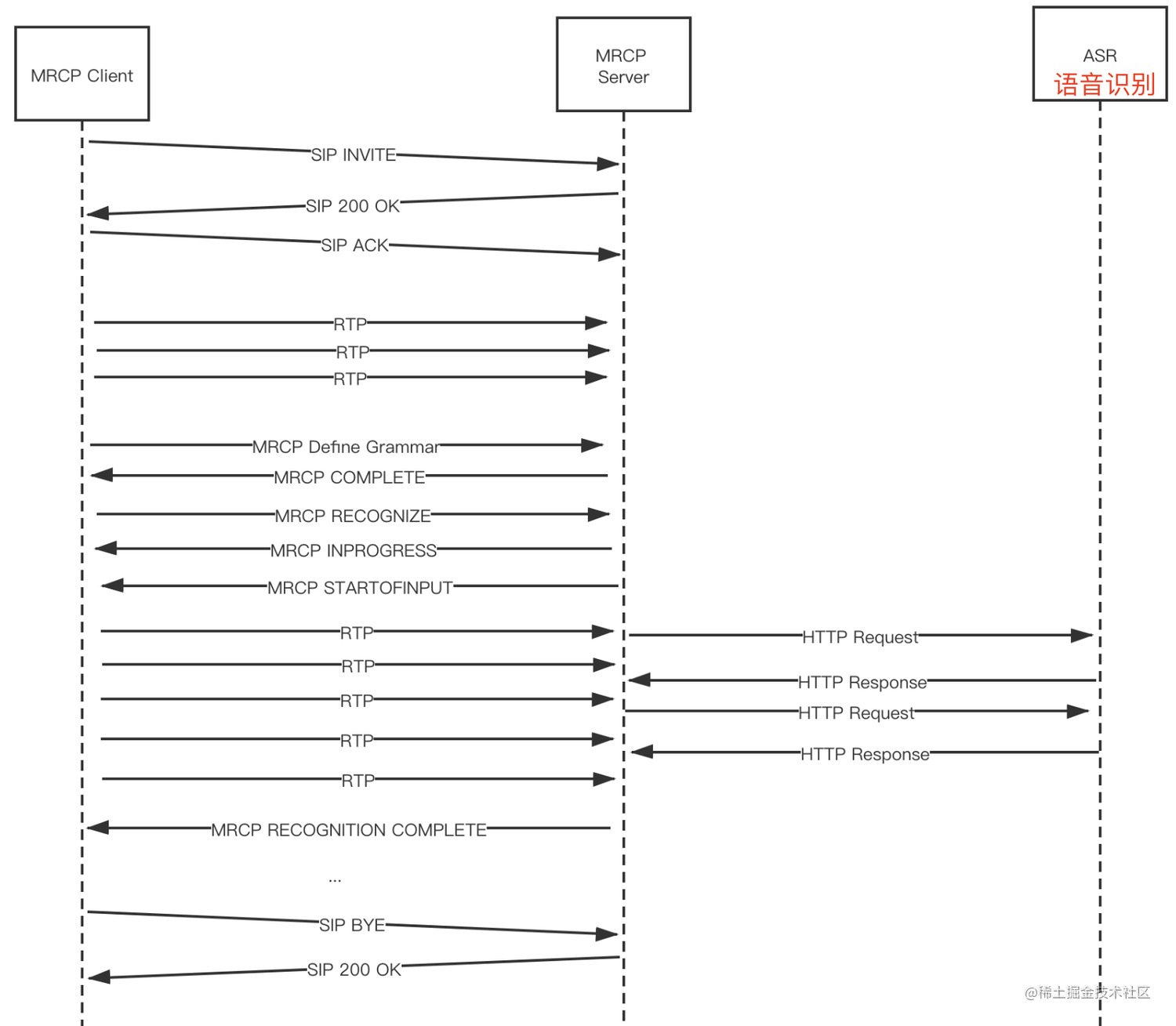
上图描述了整个通信的过程,下面具体描述一下。
MRCP会话建立
通过SIP协议来建立会话。
- MRCP Client的SIP INVITE信息包含Client侧SDP信息。其中“
resource:speechrecog”代表请求语音识别资源。 - MRCP Server回复SIP 200 OK时会发送Server侧的的SDP信息,包含channel标识等。
SIP INVITE消息示例:
c=IN IP4 127.0.0.1
t=0 0
m=application 9 TCP/MRCPv2 1
a=setup:active
a=connection:new
a=resource:speechrecog
a=cmid:1
m=audio 4000 RTP/AVP 0 8 96 101
a=rtpmap:0 PCMU/8000
a=rtpmap:8 PCMA/8000
a=rtpmap:96 L16/8000
a=rtpmap:101 telephone-event/8000
a=fmtp:101 0-15
a=sendonly
a=ptime:20
a=mid:1SIP 200 OK消息示例:
v=0
o=UniMRCPServer 0 0 IN IP4 127.0.0.1
s=-
c=IN IP4 127.0.0.1
t=0 0
m=application 1544 TCP/MRCPv2 1
a=setup:passive
a=connection:new
a=channel:743997aec02d11ea@speechrecog
a=cmid:1
m=audio 5000 RTP/AVP 0 101
a=rtpmap:0 PCMU/8000
a=rtpmap:101 telephone-event/8000
a=fmtp:101 0-15
a=recvonly
a=ptime:20
a=mid:1MRCP DEFINE-GRAMMAR
通过MRCP DEFINE-GRAMMAR消息,可以将一些语音识别所需的参数关联进去,来帮助更好的识别(DEFINE-GRAMMAR必须在RECOGNIZE之前发送)
例如下面的 DEFINE-GRAMMAR消息体中,设置hotword_id和customization_id,发送给腾讯云的MRCP-Server,就可以分别设置语音识别的热词和自学习参数,来做识别加强。
2020-07-07 16:40:04:490628 [INFO] Receive MRCPv2 Data 127.0.0.1:1544 <-> 127.0.0.1:43893 [448 bytes]
MRCP/2.0 448 DEFINE-GRAMMAR 1
Channel-Identifier: 743997aec02d11ea@speechrecog
Content-Type: application/srgs+xml
Content-Id: request1@form-level.store
Content-Length: 269
<grammar xmlns="http://www.w3.org/2001/06/grammar" xml:lang="en-US" version="1.0" mode="voice" root="digit">
<rule hotword_id="test_hotword" customization_id="test_customization_id"/>
</grammar>
2020-07-07 16:40:04:490756 [INFO] Assign Control Channel <743997aec02d11ea@speechrecog> to Connection 127.0.0.1:1544 <-> 127.0.0.1:43893 [0] -> [1]MRCP RECOGNIZE
MRCP RECOGNIZE消息用来启动一次语音识别,打开channel准备接收数据。
RECOGNIZE的Header有很多种类型,其中以下4种是在外呼场景最常见的4个。
- Start-Input-Timers:是否启动no-input计时器,大多数情况下设置true即可,配合No-Input-Timeout一起使用。
- No-Input-Timeout:单位为ms,当识别开始并在一段时间内没有检测到语音时,向client发送一个RECOGNITION-COMPLETE事件,Completion-Cause为“no-input-timeout”,终止识别操作。
- 如该参数设置3000,代表外呼中的等待客户回复的时候,超过3秒客户一直没说话,触发no-input-timeout事件。机器人可以尝试再次播报或者是挂机等操作。
- Recognition-Timeout:单位为ms,识别超时时间,用于语音识别vad(人声检测)断不开一直识别的情况,向client发送一个RECOGNITION-COMPLETE事件,Completion-Cause为“recognition-timeout”,终止识别操作。
- 如该参数设置10秒,代表外呼中客户最多一次不停的说10秒的话,10秒触发Recognition-Timeout事件,机器人根据客户说话结果生成回复。
- Speech-Complete-Timeout:单位为ms,静音尾部检测时间。用于设置语音识别vad静音检测阈值,一般会设置在500ms-1000ms的区间。
下面是一个RECOGNIZE消息的实例:
MRCP/2.0 290 RECOGNIZE 2
Channel-Identifier: 743997aec02d11ea@speechrecog
Content-Type: text/uri-list
Cancel-If-Queue: false
No-Input-Timeout: 5000
Recognition-Timeout: 10000Speech-Complete-Timeout: 500
Start-Input-Timers: true
Confidence-Threshold: 0.87
Content-Length: 33MRCP-Server给Client响应,IN-PROGRESS表示识别处理中。
MRCP/2.0 83 2 200 IN-PROGRESS
Channel-Identifier: 743997aec02d11ea@speechrecogMRCP START-OF-INPUT
MRCP START-OF-INPUT事件表示识别正式开始,数据通过RTP持续传输过来。
MRCP/2.0 94 START-OF-INPUT 2 IN-PROGRESS
Channel-Identifier: 743997aec02d11ea@speechrecogMRCP RECOGNITION-COMPLETE
MRCP RECOGNITION-COMPLETE事件表示识别结束,并返回识别结果
MRCP/2.0 477 RECOGNITION-COMPLETE 2 COMPLETE
Channel-Identifier: 743997aec02d11ea@speechrecog
Completion-Cause: 000 success
Content-Type: application/nlsml+xml
Content-Length: 290
<result>
<interpretation grammar="session:request1@form-level.store" confidence="0.97">
<instance><nlresult>07743997aec02d11ea-1|微粒贷借借贷问题。</nlresult></instance>
<input mode="speech"></input>
</interpretation>
</result>三、常见问题
发现有任何异常的时候,可以先去排查下日志。MRCP Server的日志为:$project_path/unimrcp/log/unimrcpserver_current.log
会话相关
MRCP Client日志出现Failed to Create Listening Socket
原因:MRCP端口被占用
解决方法:使用以下命令检查端口$(port)(默认1544)是否被占用,若被其他服务占用,则参考3.3.2修改&分发配置并重启服务。
netstat -anp |grep $(port)
MRCP Server日志出现Failed to Create NUA
原因:SIP端口被占用
解决方法:使用以下命令检查端口$(port)(默认5060)是否被占用,若被其他服务占用,则参考3.3.2修改&分发配置并重启服务。
netstat -anp |grep $(port)
MRCP Client日志出现Connection refused
Receive SIP Event [nua_i_state] Status 0 INVITE sent [SIP-Agent-1]
nta: INVITE (950928814): Connection refused (111)原因:MRCP Server未启动,或者是没有正确配置MRCP Server的ip和端口。
解决方法:参考3.3.3章节,确认MRCP Server是启动状态,如果已启动,确认client端设置了正确的ip和端口。
语音识别相关
MRCP Client没有拿到识别结果
查看MRCP Server日志,如果出现类似“send to asr error, httpcode 0, rsp_code xxx” 这样的日志,说明识别请求发送失败了,可以根据错误码提示排查一下错误。
如果出现类似如下日志,说明语音识别的请求是正常发送了的。
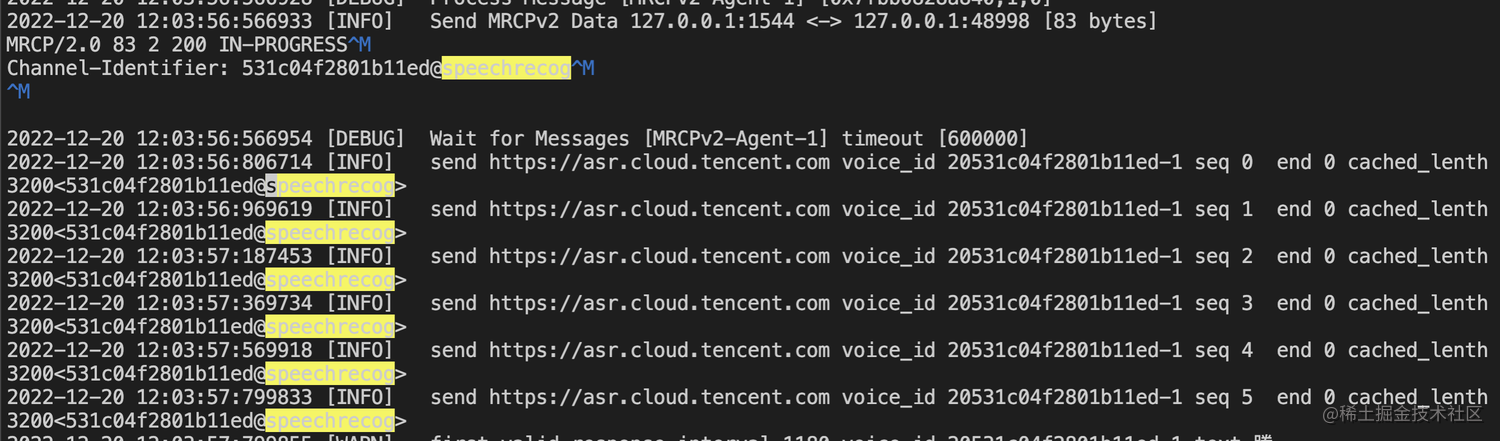
这种情况下没有拿到识别结果,可以往下分析一下日志,一般就是如下两种情况:
- 用户一直没说话,默认5s没有说话会话自动超时,发送识别结果为no-input-timeout。详细可参考4.3章节里面的header说明。

2. client侧发送了STOP请求,STOP请求会中断识别,并关闭链接,导致client端无法收到识别结果。
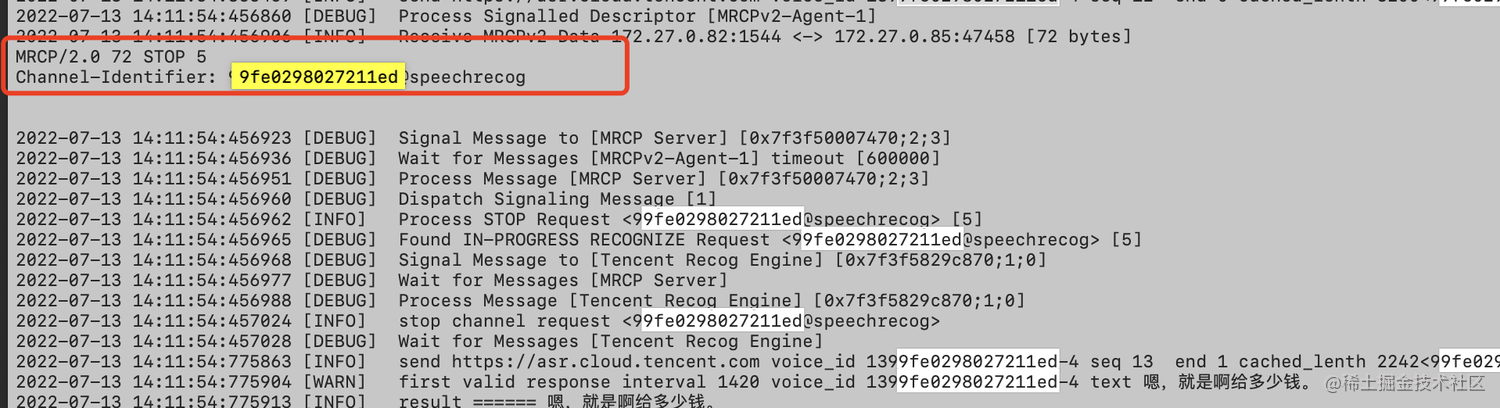
MRCP Server如何设置热词&自学习
关于热词和自学习的设置,使用3.1章节的账号登陆语音识别控制台,参考下面两个文档进行设置。
自学习设置:https://cloud.tencent.com/document/product/1093/38416
热词设置:https://cloud.tencent.com/document/product/1093/40996
控制台里面可以看到对应的热词ID和自学习ID,参考4.2章节, DEFINE-GRAMMAR消息体中,分别设置hotword_id和customization_id。
这样对应的热词和自学习就可以生效了。
MRCP Server如何修改识别结果样式
默认的返回结果为如下样式:
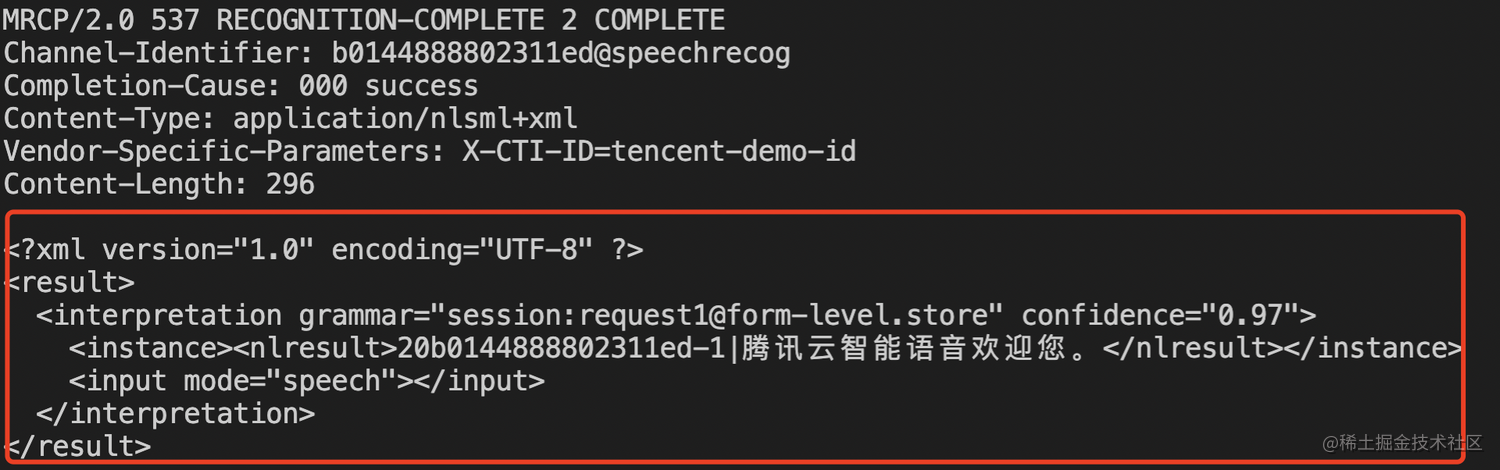
如果想改下对应的返回结构,可以修改
cd $project_path/unimrcp/data
vim result.tpl.xml默认格式如下:
<?xml version="1.0" encoding="UTF-8" ?>
<result>
<interpretation grammar="%s" confidence="0.97">
<instance><nlresult>%s|%s</nlresult></instance>
<input mode="speech"></input>
</interpretation>
</result>如果想把识别结果放到input speech节点里。则可以修改为:
<?xml version="1.0" encoding="UTF-8" ?>
<result>
<interpretation grammar="%s" confidence="0.97">
<instance><nlresult>%s</nlresult></instance>
<input mode="speech">%s</input>
</interpretation>
</result>如果想修改成JSON格式,则可以调整为:
{
"grammar" : "%s",
"voiceid" : "%s",
"result" : "%s"
}修改后对应结果变为:
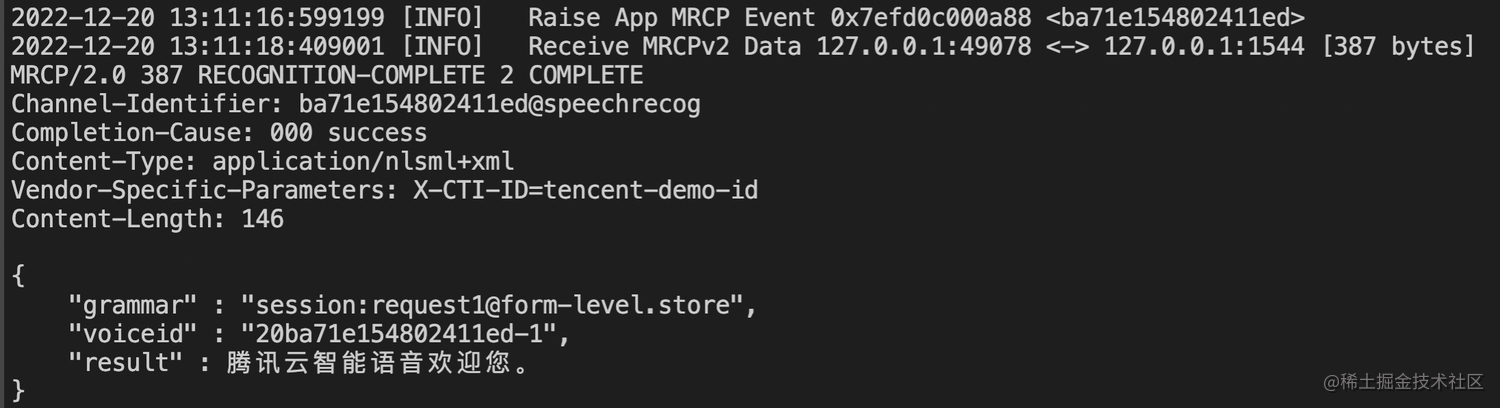
如何修改语音识别参数
运行如下命令打开ASR对应的配置文件:
cd $project_path/unimrcp/
vim conf/TCloudRealtimeASRConfig.ini[tcloud_asr]节点下的内容都是语音识别的参数,参数的详细含义,可以参考官网文档:https://cloud.tencent.com/document/product/1093/48982
配置文件里面的参数都不建议修改,脏词过滤、语气词过滤、标点、数字转换几个可以根据需求来修改。
filter_dirty=0
filter_modal=0
filter_punc=0
convert_num_mode=1修改配置后记得重启MRCP Server以便生效。
语音合成相关
如何设置音色&音量&语速
参考MRCP标准协议中相关描述:https://datatracker.ietf.org/doc/id/draft-ietf-speechsc-mrcpv2-22.html#sec.synthesizeHeaders

以上是一个实际调用示例,实际的调用中,最常用的也就是这三个参数。
- Voice-Name:音色,对应腾讯云实时合成里面的VoiceType参数
- Prosody-Volume:音量,对应腾讯云实时合成里面的Volume参数
- Prosody-Rate:语速,对应腾讯云实时合成里面的Speed参数
这几个参数对应的值,可以参考官网文档:https://cloud.tencent.com/document/product/1073/34093
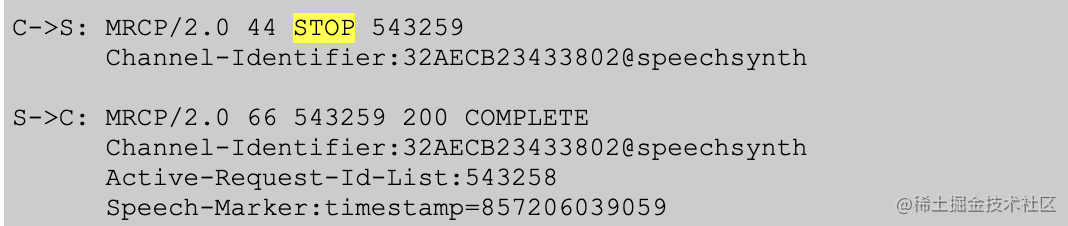
如何实现中断播报
client发送一个STOP消息即可中断语音合成播报。详细参考:https://datatracker.ietf.org/doc/id/draft-ietf-speechsc-mrcpv2-22.html#anchor46
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号