批量从pdf中提取基金年报观点


接上篇,我们已经爬下来了所有的基金年报。这篇我们来说明怎么通过python批量获取全部基金经理的观点,用到的数据就是所有的基金年报,还没爬或者还不知道怎么爬的可以看看上一篇。
我这里只把所有的混合型和股票型基金的年报爬下来了,不嫌慢的话,也可以考虑把其他债券、货币、ETF等等类型的都搞下来。
# 保留股票型和混合型
allpdf['ifstock'] = allpdf.announcementTitle.map(lambda x:'股票型' in x or '混合型' in x)
allpdf1 = allpdf.loc[allpdf.ifstock].reset_index(drop = True)
getFundReportpdf(allpdf1,fpath)爬下来大概需要一小时吧,1425份,还是挺快的。


先说下我们要干啥,免得有的童鞋云里雾里。
基金年报里有一大章是管理人报告,我们主要针对里面的两小节:管理人对报告期内基金的投资策略和业绩表现的说明、管理人对宏观经济、证券市场及走势的简要展望。

这两节里,前一节基金经理会对过去这一整年的投资逻辑和业绩情况给一个说明,分析赚钱或者赔钱的原因。后一节里投资者会对未来的市场做一个展望。有的基金经理很懒,每年都是复制粘贴上一年的话不变,有的很勤奋,洋洋洒洒写个一两页。总之关注这两节,有助于我们快速了解基金经理的投资逻辑,对基金风格有一个整体的了解。随便贴一个基金的样例。


这次我们做的事情就是把前面爬的1425份报告所有的这两小节都提出来到excel里,方便查看,毕竟只看一两份可能有偏,看得多了才能慢慢有一些自己的体会。
截止目前所有公募基金的年报都已经公布完了,感兴趣可以自己把全部的都爬下来,我这个是前两天爬的,肯定是不全的。最后整理出来到EXCEL里大概是下面这个样子,总共3列,第一列是基金名称,后面两列见下,需要EXCEL和python代码的可以在后台回复“年报观点”获取。1425份年报观点都已经整理到位。

下面来说怎么获取,简单来说,就是先读到python里,然后根据标题去切割,只保留对应部分的内容。基金年报最好的一点就是每一节标题都是一模一样一字不差的标准格式。也就不需要正则表达式之类的复杂操作。

我们需要的是4.4节管理人对报告期内基金的投资策略和业绩表现的说明下面的内容,以及4.6管理人内部有关本基金的监察稽核工作情况上面的内容。所以些代码的时候就直接判断获取到的文字里是不是包含这两部分就可以了,不包含的都踢掉。
唯一需要处理下的就是,目录里有这两段,后面正文里也有这两段,因此第一次出现的时候不要做任何处理,第二次出现的时候再操作。
用python读pdf,因为基金年报都是文本没有图片,直接用pdfplumber就可以了。这部分代码如下
res = []
for fname in tqdm(allf):
with pdfplumber.open(fpath + fname) as pdf:
page_count = len(pdf.pages)
alltext = ''
n = 0
for page in pdf.pages:
texts = page.extract_text()
if '管理人对报告期内基金的投资策略和业绩表现的说明' in texts:
n += 1
if n==2:
alltext += texts
if '管理人内部有关本基金的监察稽核工作情况' in texts:
res.append([fname,alltext])
break
res = pd.DataFrame(res,columns =['fname','text'])这部分因为要解析pdf,比较慢,用了两小时。

这部分搞完之后就已经是比较清晰的文本了。
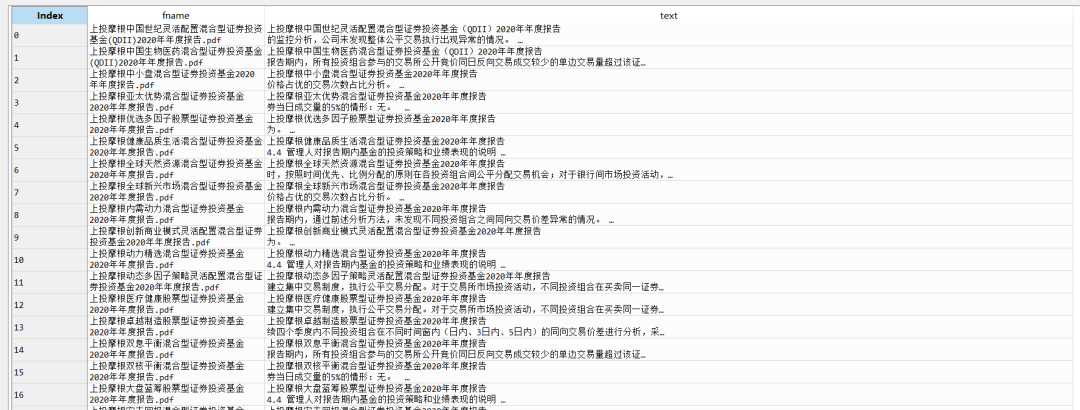
text里是两部分文本合在一起,用函数分开就可以了。另外text里有一些特殊字符,空格之类的,一起删掉。
def getstrategy(x):
res = re.split('管理人对报告期内基金的投资策略和业绩表现的说明|管理人对宏观经济、证券市场及行业走势的简要展望|管理人内部有关本基金的监察稽核工作情况',x)
return res[1]
def getmacrodes(x):
res = re.split('管理人对报告期内基金的投资策略和业绩表现的说明|管理人对宏观经济、证券市场及行业走势的简要展望|管理人内部有关本基金的监察稽核工作情况',x)
return res[-2]
res['text'] = res.text.map(lambda x:re.sub('[\n ]','',x))
res['管理人对报告期内基金的投资策略和业绩表现的说明'] = res.text.map(getstrategy)
res['管理人对宏观经济、证券市场及行业走势的简要展望'] = res.text.map(getmacrodes)
res = res.drop(['text'],axis = 1)这部分处理完就是我们上面看到的样子了。
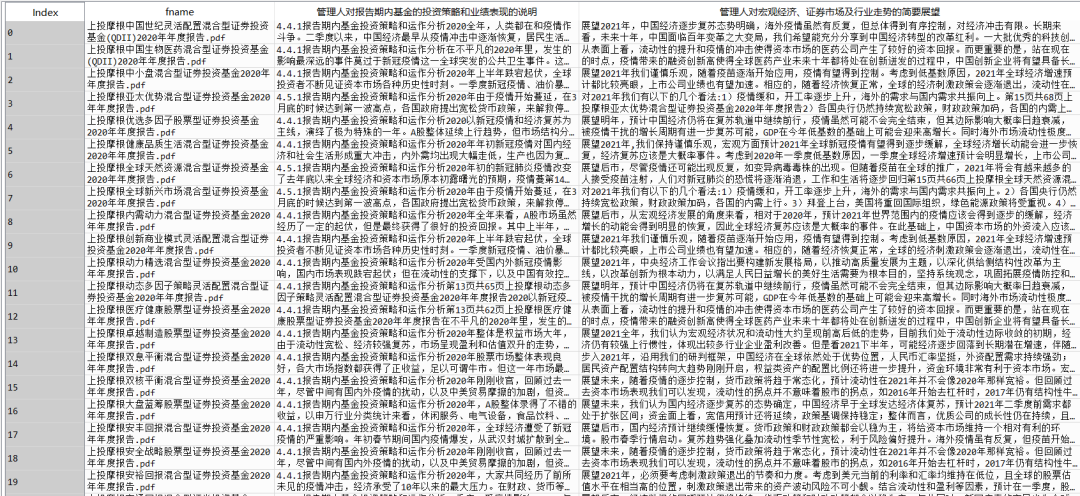
直接存excel就完事。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2021-04-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号