eBPF是什么


大家好,今天聊聊eBPF,
一看带e的都很厉害,
PCI Express
NVM Express
eBPF也很厉害:extended BPF。
聊eBPF首先得知道BPF,BPF如果也不熟悉,那大名鼎鼎的 tcpdump 和 wireshark大家很熟悉,他俩是借助BPF实现的。
什么是BPF
BPF出现于BSD,其全称是 Berkeley Packet Filter,顾名思义,它是在伯克利大学诞生的,并且是一个用于过滤(filter)网络报文(packet)的技术。

1992年Steven McCanne 和 Van Jacobson 写了一篇《The BSD Packet Filter: A New Architecture for User-level Packet Capture》论文 ,第一次提出了BPF技术。
在文中,描述了他们如何在 Unix 内核实现网络数据包过滤,这种新的技术比当时最先进的数据包过滤技术快 20 倍。
BPF干什么用?
BPF与之前网络过滤的区别是把过滤功能放到了内核中,其过程是网卡接收到一个数据包后,从数据链路层将数据包额外的拷贝一份交给BPF程序进行处理,BPF根据用户设定的过滤规则对数据包进行过滤。只有符合规则的数据包从内核空间拷贝到用户空间,这样就减少了无用的数据包的拷贝。
BPF 可谓是名气不大,作用不小的典范呀,BPF 可是大名鼎鼎的 tcpdump 和 wireshark 乃至网络监控(Network Monitoring)领域的基石。
eBPF来了
BPF在引入Linux内核后,在发展过程中出现了很多的改进,较革命性的大动作就要等到内核3.17 了。
在这版本内核中BPF代码被添置到了 kernel/bpf 下,这一全新设计最终被命名为了 extended BPF(eBPF),而传统的BPF 仍被保留了下来,并被重命名为 classical BPF(cBPF)。
由一个文件(net/core/filter.c)进化到一个目录(kernel/bpf),相对于 cBPF,eBPF 带来的改变可谓是革命性的:
一方面引入Map机制,以前cBPF通过队列将过滤后的数据发送到用户空间,而eBPF则通过用户空间和内核空间共享的Map空间实现数据的传输。
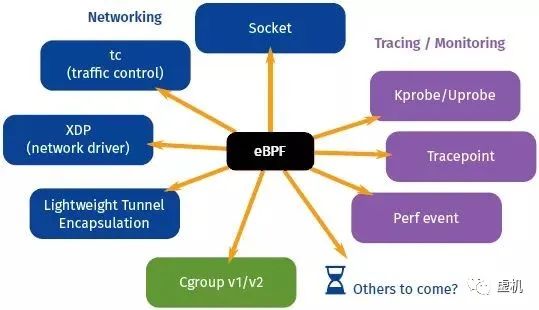
另一方面,除了网络数据包过滤,添加了新的功能,如XDP、Perf Event、kprobe、tracepoint等。
同时eBPF还有了专门的用于编译BPF字节码的编译器clang/llvm。
eBPF基本原理
eBPF也叫内核虚拟机,本质上它是一种内核代码注入的技术,它提供了一种在不修改内核代码的情况下,可以灵活修改内核处理策略的方法。
eBPF程序attach到内核中的指定代码路径上,当内核执行到此路径时,将执行所有附加的eBPF程序。
鉴于其起源,eBPF特别适合于编写网络程序,例如 XDP就是在进入内核协议栈之前插入eBPF的扩展的网络包的过滤和转发功能。
但是目前,除了支持原来cBPF的Socket外,内核中已经支持了 几十 种 eBPF 程序类型。
开发语言
早期的cBPF程序直接使用BPF指令集来编写。
后来eBPF通过c语言进行编写,通过clang/llvm将c语言编译为BPF字节码并 手动注入到内核中。
再后来出现了BCC(BPF Compiler Collection),BCC可帮用户编译、解析 ELF、注入内核以及创建 map 等。
用户只需要用C语言来设计 BPF 程序,剩下的交给BBC处理。
同时也出现了对go和Rust的支持库,感兴趣的朋友可以看看libbpfgo和libbpf-rs这两个开源库。
举个例子
在iovisor的官方github上有一个例子:
bcc/examples/tracing/disksnoop.py
这里有一个磁盘监控的BPF程序,下图是它的代码片断:

其中trace_start 的函数将被编译进 BPF 字节码,然后注入到内核函数 blk_start_request 上,每当内核执行blk_start_request时,都会执行我们注入的trace_start函数。
目前eBPF已经成为内核中炙手可热的项目,其生态也日益壮大,从基础运行时,到各种语言的接口库,再到五花八门的应用程序,下面展示了部分生态成员:
生态系统
基础平台:
linux runtime

windows runtime

FPGA runtime
LLVM编译器

eBPF Libraries:
C/C++库:libbpf

Rust语言库:libbpf-rs

Go语言库:libbpfgo

应用程序:
工具集BCC

bpftrace
cilium

falco

katran

hubble
KubeArmor

kubectl trace

L3AF

ply

Tracee

BumbleBee

我是cloud3,一起聊聊。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-04-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号