CPU这么忙,休息一会不调度了


大家好,我是cloud3,本文讲一下操作系统中的调度算法以及多处理中的调度问题。
阅读本文前最好先熟悉一下我关于CPU高速缓存的几篇文章。
狼多肉少轮流吃
首先,为什么要调度,多任务的OS中,每个任务都需要使用CPU,需要为各个任务对CPU的使用提供一种机制,这就是调度。调度器决定了在某一个时刻,应该让哪个任务获得CPU的使用权。
就像下面:

不可兼得
衡量一个策略的优劣通常有系统和用户两个维度:
系统想要处理的快,用户想要响应的快。
面向系统的维度:系统吞吐量高、处理机利用率好、各类资源的平衡利用。
面向用户的维度:周转时间短、响应时间快、均衡性、截止时间的保证、优先权准则。
什么时候调度
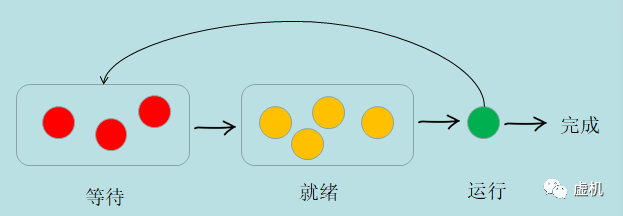
CPU 调度决策出现在以下四个条件之一:
- 当进程从运行状态切换到等待状态时。
- 当进程从运行状态切换到就绪状态时。
- 当进程从等待状态切换到就绪状态时。
- 当进程终止时。
对于条件 1 和 4 没有选择 - 必须选择新的进程。
对于条件 2 和 3,可以选择 - 继续运行当前进程,或选择别的进程。
如果调度只在条件1和4条件下进行,则系统是非抢占,否则这个系统是抢占的。
常见的调度算法
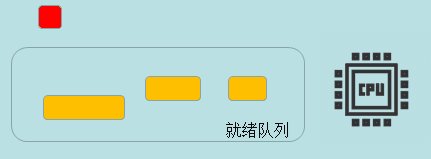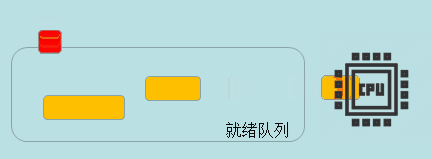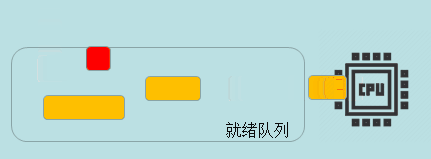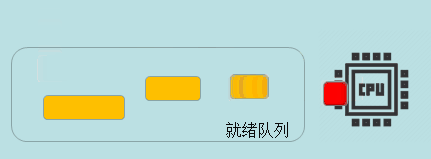
先到先服务(FCFS)
先到先服务算法 (FCFS)是基于FIFO模式的,先进入就绪队列的任务先执行,前一个任务执行完毕或阻塞,后一个任务才执行。

最短任务优先(SJF)
最短任务优先算法会优先选择运行所需时间最短的进程执行,可提高吞吐量。对长作业很不利。

最短剩余时间优先(SRTN)
最短剩余时间优先算法,可以认为是SJF的抢占式版本,当一个新就绪的进程比当前运行进程具有更短完成时间时,系统抢占当前进程,选择新就绪的进程执行。
有最短的平均周转时间,但不公平,源源不断的短任务到来,可能使长的任务长时间得不到运行。
时间片轮转(RR)
时间片轮转算法设定了个时间片,每个进程只有在该时间片内才可以运行,这种方式每个进程都会均匀的获得执行权。
时间片太小会导致系统频繁进行上下文切换,太大可能引起对交互请求的响应变差。

最高优先级优先(HPF)
最高优先级算法的原理是给每个进程赋予一个优先级,每次需要进程切换时,找一个优先级最高的进程进行调度。
非抢占式:当就绪队列中出现优先级高的进程,运行完当前进程,再选择优先级高的进程。
抢占式:当就绪队列中出现优先级高的进程,当前进程挂起,调度优先级高的进程运行。
多级反馈队列(MLFQ)
多级反馈队列调度算法‘时间片轮转算法’和‘最高优先级算法’的结合。
「多级」表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短。
「反馈」表示如果有新的进程加入优先级高的队列时,立刻停止当前正在运行的进程,转而去运行优先级高的队列。
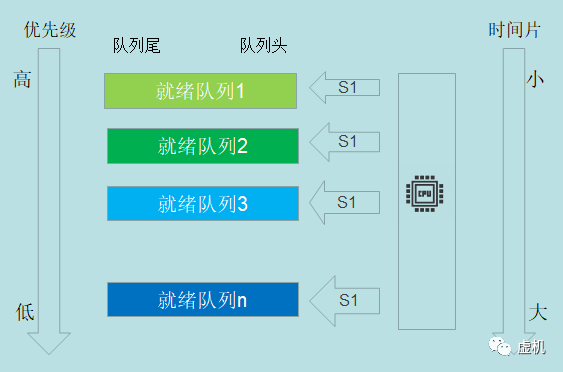
设置多个队列,每个队列优先级不同时间片不同,优先级越高时间片越短。主要规则如下:
如果A的优先级大于B的优先级,运行A,不运行B;
如果A的优先级等于B的优先级,轮转运行A和B;
一旦任务用完了其在某一层中的时间配额(无论中间主动放弃了多少次CPU),就降低其优先级(入低一级队列);
经过一段时间,就将系统中所有工作重新加入最高优先级队列。
多级反馈队列调度算法对于短作业可能可以在第一级队列很快被处理完。对于长作业,如果在第一级队列处理不完,可以移入下次队列等待被执行,虽然等待的时间变长了,但是运行时间也会更长了,所以该算法很好的兼顾了长短作业,同时有较好的响应时间。
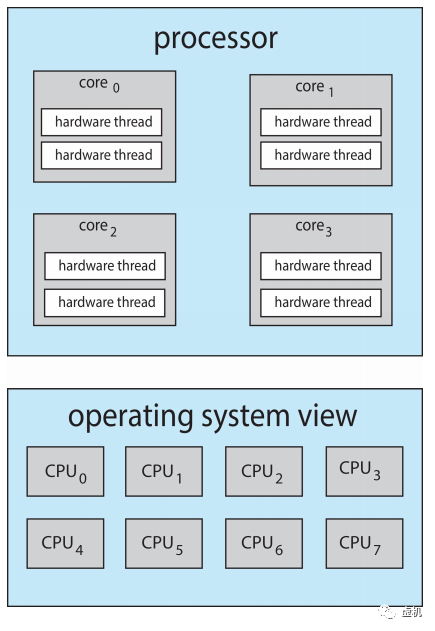
芯片级多线程(CMT)
多核可分为同构(SMP)和异构(AMP)两种,如果使用Hyperthreading技术,则一个CPU core可以有两个逻辑线程,这两个逻辑线程共享ALU, FPU和L2 Cache等。从OS调度的角度,逻辑线程被视作一个独立的processor。
在cpu执行时,内存stall是cpu利用率不足的主要原因,访存操作浪费大部分cpu周期导致cpu大部分处于空闲状态,有些技术例如预取技术等可以隐藏部分访存的延迟,但仍不能有效改善访存延迟。所以很多厂家选择芯片级多线程技术(CMT)。
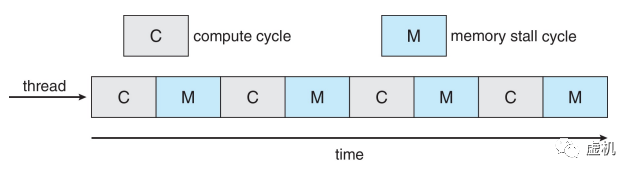
当芯片内某些线程进行访存操作时,另外一些线程仍在运行,这样就隐藏了访存延迟,提高了CPU的利用率。
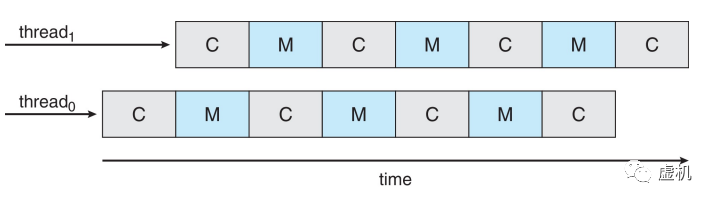
多核系统的调度
无论是单核还是多核,只要是多任务系统,就需要调度,但调度对多核系统显得尤为关键,因为如果调度不当,就无法充分发挥多核的潜力。
基于多核的调度,大致有两种模型,一种是只有一个任务队列(single queue)多核共享,另一种就是采用每个CPU有一个任务队列的模型(multiple queues)。

在单队列的情况下,当有一个新任务需要执行时,选择一个空闲的CPU来执行,这样任务一会儿在这个CPU上运行,一会儿又在那个CPU上运行,没到一个CPU,cache往往都是“冷”的,效率极低,所以就有了每个CPU有一个任务队列的模型,避免了各个CPU共享一个队列,cache的命中率也大大提高。
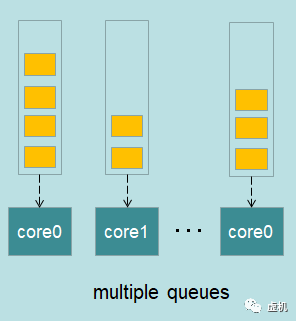
假设有4个所需耗费的时间都差不多的任务,分给2个CPU来执行那好分配。如果这4个任务所需耗费的时间差异很大,或者只有3个任务需要执行呢,该怎么分配?这就涉及到了多核系统的负载均衡。
多核系统的负载均衡
要实现多核系统的负载均衡,主要依靠task在不同CPU之间的迁移(migration),也就是将一个task从负载较重的CPU上转移到负载相对较轻的CPU上去执行。
从CPU的runqueue上取下来的这个动作,称为"pull",放到另一个CPU的runqueue上去,则称之为"push"。

迁移是有代价的,在同一个物理CPU的两个logical core之间迁移,因为共享cache,代价相对较小。如果是在两个物理CPU之间迁移,代价就会增大。更进一步,对于NUMA系统,在不同node之间的迁移将带来更大的损失。
为了解决拓扑结构多样性的问题,在 2.6 版的 Linux 内核引入了调度域的概念。这种方案按层次结构将系统中所有可用的 CPU 分组,这就使得内核有了一种办法描述下层的处理器核心拓扑结构。
调度域和调度组
内核引入了调度域的概念实际上就是实现一个调度上的约束。一个调度域是一组共享调度属性和策略的 CPU,可以用来和其它域进行负载平衡。
每个域包含一个或多个调度组,每个组在域内都被视为一个单元,调度器会尝试使各个组的负载均等而不考虑组内到底发生了什么。

处于同一内层domain的,迁移可以更频繁地进行,越往外层,迁移则应尽可能地避免。
每个调度域都有一个只在本层级中有效的均衡策略集。这个策略的参数包含每隔多长时间要尝试在整个域内进行一次负载均衡,在尝试执行负载均衡之前成员处理器的负载在达到多少之前可以处于不同步状态,一个处理器处于空闲状态多久才会被认为不再具有明显的缓存亲和性。
系统会周期性的进行积极负载均衡将调度域层级上移,按顺序检查所有的组是否失去均衡了。如果失去均衡则会尝试使用对应域的调度策略的规则执行一次负载均衡。
处理器亲和性
CPU affinity 是一种调度属性, 它可以将一个进程"绑定" 到一个或一组CPU上。设置亲和性最直观的好处就是提高了cpu cache的命中率,从而减少内存访问损耗,提高执行的速度。
Linux调度器支持自然CPU亲和性(natural CPU affinity)::调度器会试图保持进程在相同的CPU上运行, 这意味着进程通常不会在处理器之间频繁迁移。
另外还可以设置硬亲和性,将进程或者线程绑定到一个cpu子集运行,例如linux提供了两个和性相关的命令:taskset和numactl
调度的是谁
人们一般很少叫线程调度器,而叫进程调度器或者任务调度器,但我们要明白实际上在linux系统中,进程是资源管理的最小单元,线程才是调度的最小单元。
Linux系统的调度算法
Linux内核中有几种调度程序:O(n)调度程序、O(1)调度程序、完全公平调度程序(CFS)以及BF调度程序(BFS)。
• O(n) scheduler
– Linux 2.4 to 2.6
• O(1) scheduler
– Linux 2.6 to 2.6.22
• CFS scheduler
– Linux 2.6.23 onwards
O(1)和CFS调用算法使用的都是multiple queues模型, 而Brain Fuck Schedule(简称BFS)使用的则是single queue模型。
对于Linux系统中的这几种调度算法我以后单独详细讲解。关于CPU调度本文就介绍这些
这是图解系列之CPU调度
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2021-09-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号