万字长文揭秘37手游的自研任务调度平台
原创
万字长文揭秘37手游的自研任务调度平台
原创
37手游后端技术团队
发布于 2023-03-23 14:27:10
发布于 2023-03-23 14:27:10
一、前言
1. 概念
在 37 手游内部,「统一任务调度平台」用于管理常驻进程和调度定时任务,以确保它们按照预定的计划运行。
它使用 Go 语言开发,轻量又高效。**调度核心完全运行在 Kubernetes 上,仅需依赖 MySQL 和 Redis 实例,易运维、易部署、易维护。
中控后台使用 Vue.js + ElementUI,配合 GitHub 社区的 Vue-Admin-Template 打造,美观大方。
产品定位上,它并不是一个工作流平台,而是一个 supervisor 和 crontab 的统一管理平台。**以解决业务程序(如出队列、数据报表加工清洗程序等)分散在各个 node 节点管理的难题。
本文将完整介绍 37 手游内部的「统一任务调度平台」的实现细节,文笔简陋,如有错误,还请斧正。
2. Kubernetes VS 自研
37 手游早期使用 PHP 自研了调度平台,极大降低了运维的维护成本:
- 无需部署 supervisor 程序
- 无需维护 supervisor 配置
- 无需维护 Linux 系统 crontab 配置
- 解决 crontab 无限启动雪崩宕机的问题
- ……
对于业务来说:
- 稳定性高:运行多年,调度器零故障!
- 简单易用:部署任务仅需几秒钟!后台复制配置修改进程启动参数,提交即调度。
为了更好地应对业务发展的需求,37 手游开始逐步上云。**上云的过程中,我们也逐渐发现旧版 PHP 进程管理也存在一些不足:
一、高可用问题
- 核心调度器故障无法切换
- 单个任务只能与单台机器 IP 绑定,节点故障时任务需要人工切换,凌晨睡觉影响正常休息
二、任务部署问题
- 单个任务只能与单台机器 IP 绑定,无法做到 IDC 上云(双云)、双云切换(需要支持机房一键切换)
- 原任务部署为 IDC 双机房,上云的过程,任务需要独立配置一条云上的机器,漏配会导致任务依然还在云下的情况
三、管理问题
- 队列堆积找不到负责人,缺乏企业微信的人员联动
- 队列堆积找不到生产者、消费者(与监控系统割裂)
于是,我们也在逐步上云的过程中对外探索,对市面上常见的方案进行调研:
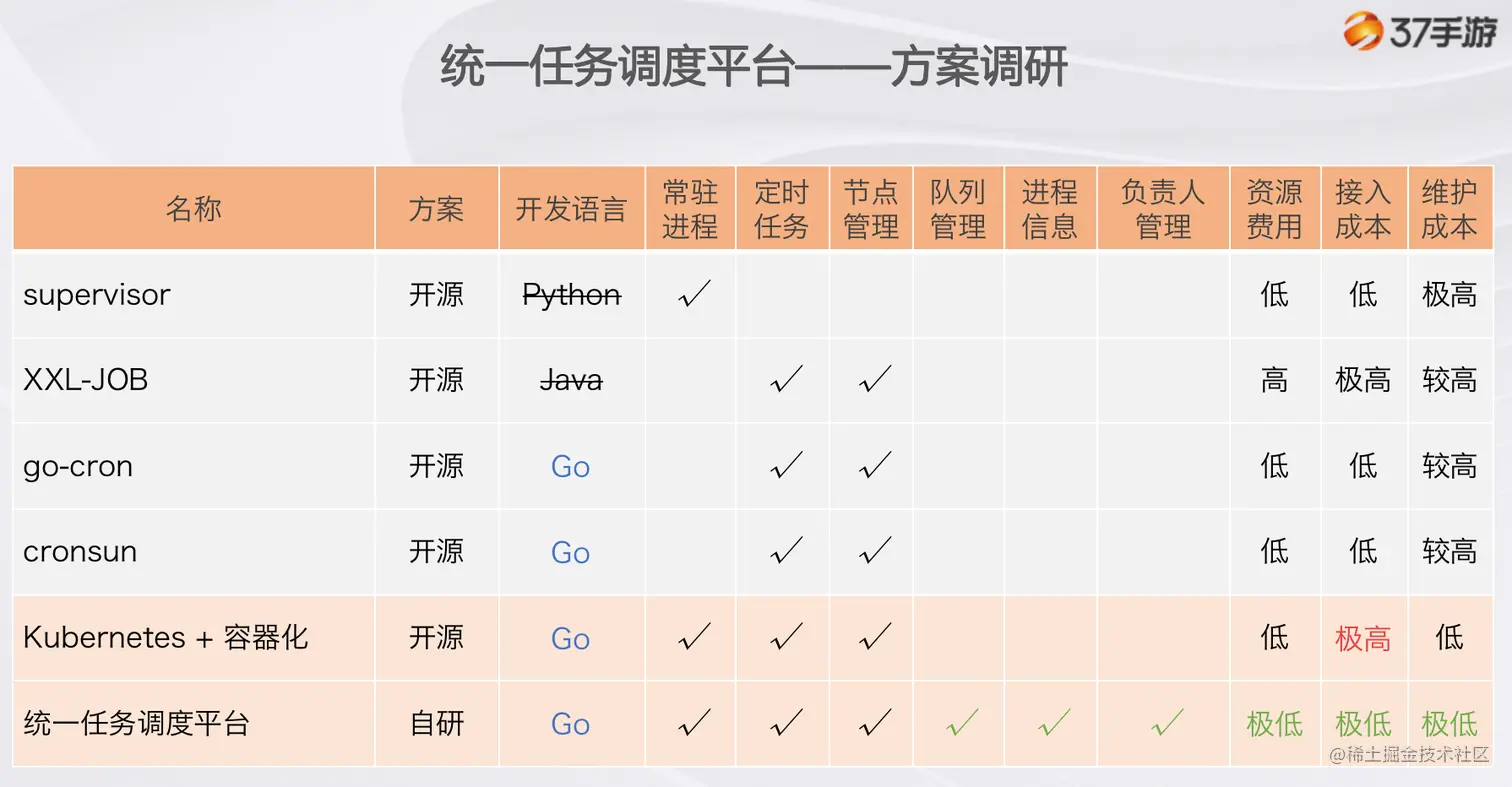
最后有两个大方向可以选择:
- 积极拥抱 Kubernetes 云原生,推动公司所有业务 100% 容器化;
- 使用 Go 语言,自研**「统一任务调度平台」**。
3. 为什么不使用 Kubernetes?
毫无疑问,Kubernetes 是一个十分优秀的容器编排系统。
对于常驻进程,使用 Deployment,而定时任务使用 CronJob,简直完美!
然而,现实往往很骨感——本来决定使用 Kubernetes 时,调研发现依然存在很多有状态的业务!
例如任务依赖本地磁盘的配置文件:
- 如果直接挂载宿主机的本地配置,会影响集群的弹性扩容……
- 如果挂载成 NFS 的话,大部分业务都要依赖 NFS,这个时候可能需要解决高可用的问题……
还有更特殊的:
我们发现有部分业务,如果使用 Kubernetes 多云(多集群),没办法做到同一时刻只运行一个 CronJob 的情况。
第二个麻烦点,是多云环境下,发生单云故障时的容灾问题:
**我们是希望故障时发生时保证所有流量,都跟着主 Kubernetes 集群走。**比如 A 云内部存在问题,需要紧急切换到 B 云。
理想的情况下是删除 A 的部署任务,并新增 B 的部署。
- 对于 WEB 程序来说,是不需要删除部署的——因为它没有外部的流量,我们切断源头链路即可。
- 对于 CronJob 来说,可能数据来源于某个从库(主从可能断开了),经过计算后通知到某个下游(比如邮件通知等)或者进入队列后,继续执行错误的逻辑……
它可能没那么重要,但确实也是需要考虑的点。
第三是全面容器化难度大。我们内部存在 PHP / Go / Java / Python / NodeJS 等多语言,很多语言内部还有多个版本(PHP5 / 7、Python2 / 3)……
对于业务来说,本身需要完成业务需求已经是筋疲力尽,很难有充足的时间,配合架构组同学去完成容器化改造。
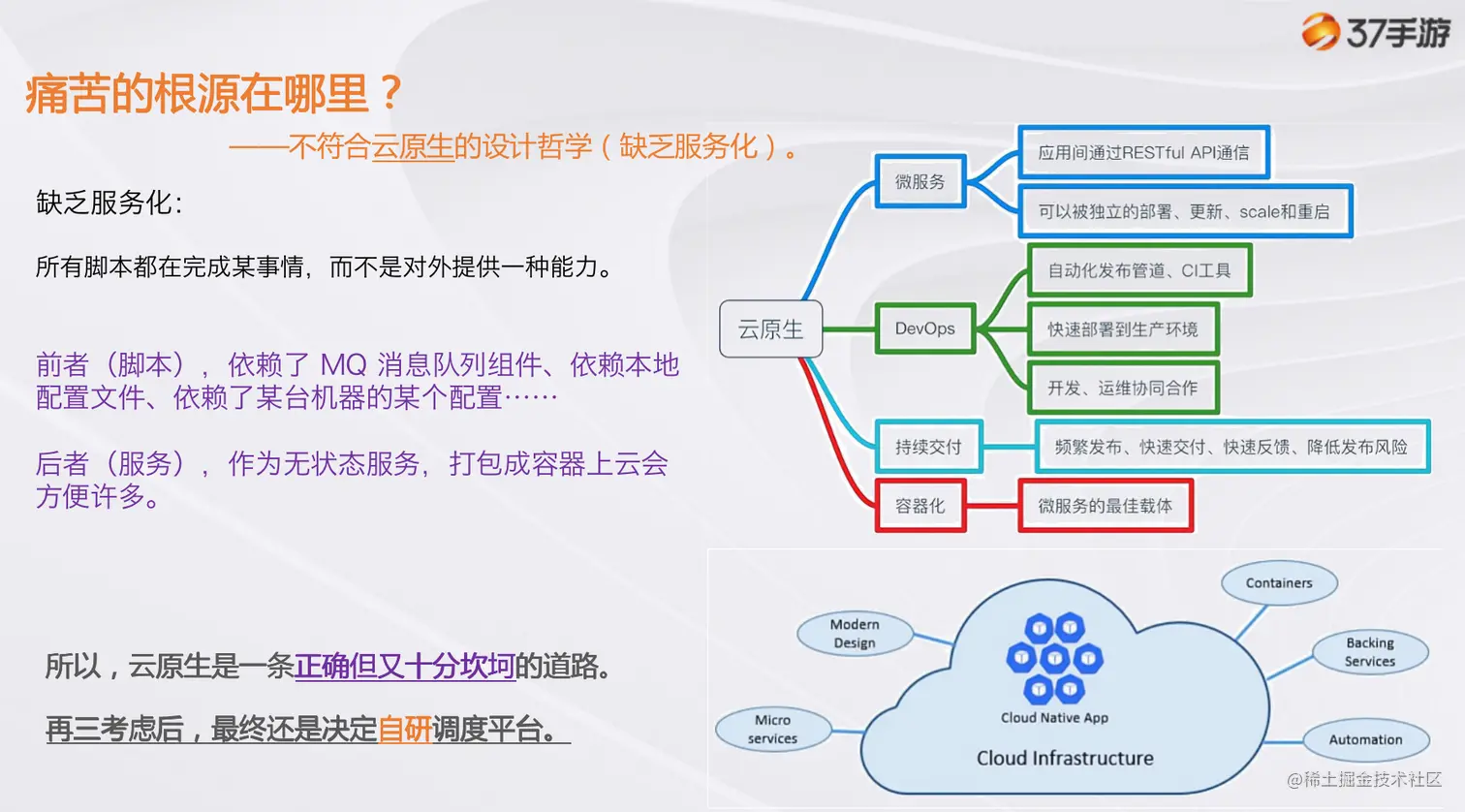
特别是 PHP 脚本,当下推动业务改造并不太现实——并不是说没有收益,在我看来,它更多是一场轰轰烈烈、缝缝补补的容器化运动而已。
最后,我们也决定,先解决稳定性的问题!
后续逐步抛弃 PHP,使用 Go 和 Java 语言对业务进行梳理、重构、容器化(进行中),逐步拥抱云原生的生态体系。
二、系统架构
**「统一任务调度平台」分为 Agent、常驻进程管理、定时任务管理、后台系统四大模块。**以下是其业务架构图:
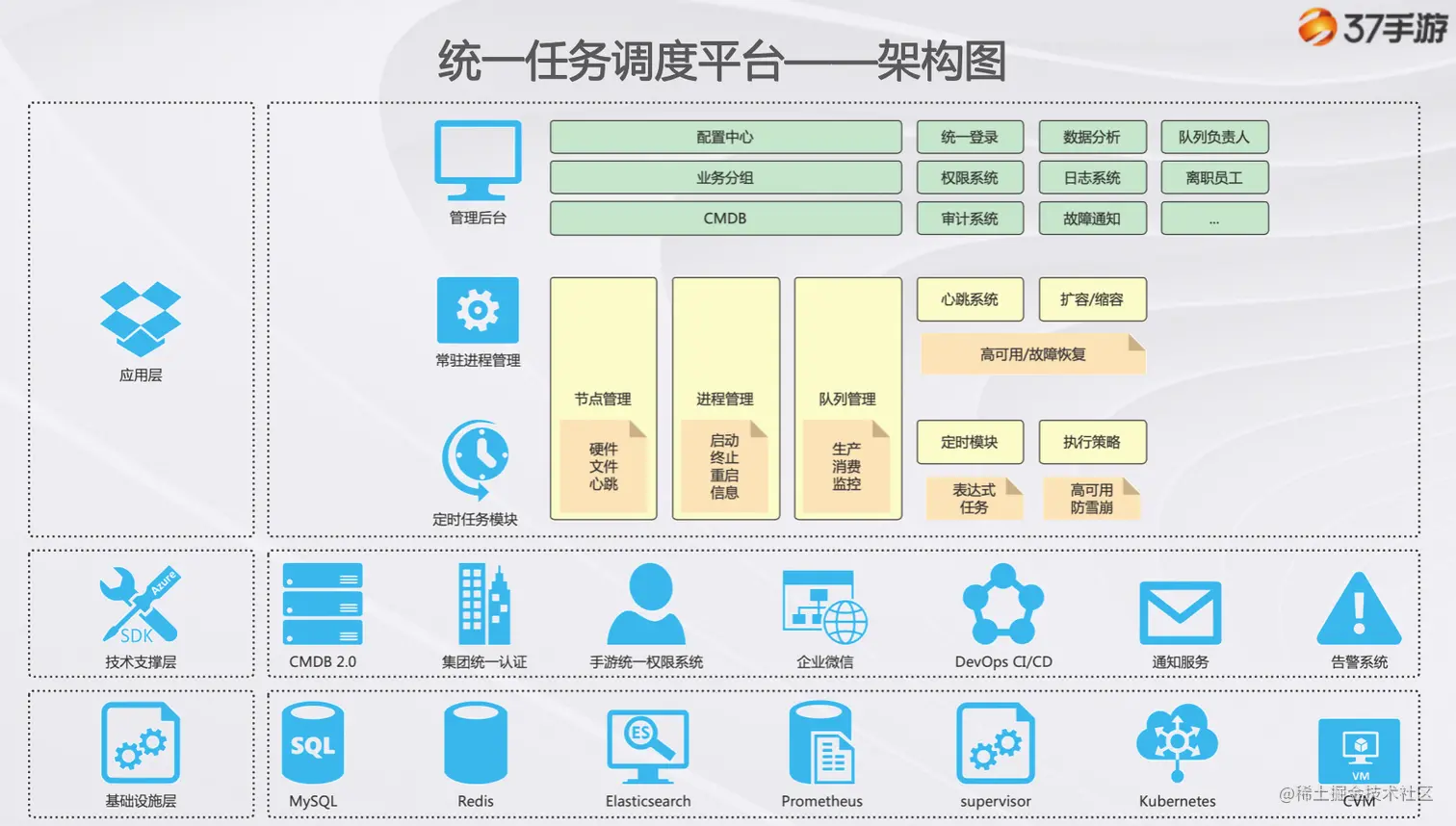
下面我将逐个分析,谈谈每个模块的实现细节。
三、模块实现
1. 统一任务调度平台——Agent
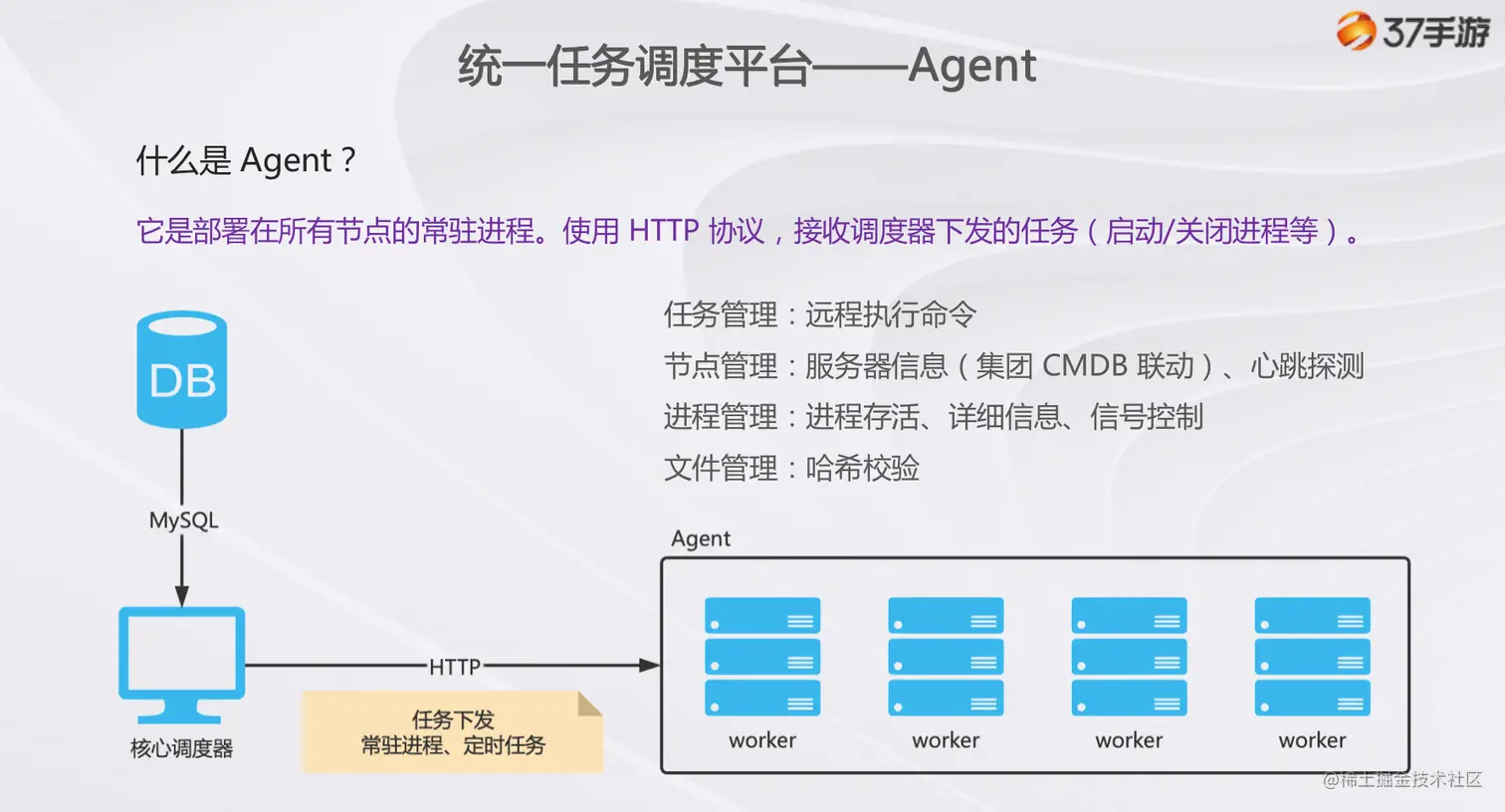
Agent 是部署在所有节点的常驻进程。使用 HTTP 协议,接收调度器下发的任务(启动/关闭进程等)。
**设计上,「统一任务调度平台」的 Agent 极其轻量,只负责执行任务,不负责上层的决策。**任务的调度由上层的中控后台决定。
因为它需要部署到多个节点上,需要保证高可用;较少的逻辑,也意味着往后的需求迭代中,基本不需要频繁发版。
它包含任务管理、节点管理、进程管理、文件管理四大模块。
(1) 任务管理:远程执行命令
- 接口入参:命令行、参数、运行目录……
- 接口出参:进程 ID 号,失败退出码……
type (
JobExecuteRequest struct {
Bash string `json:"bash" form:"bash" query:"bash"`
Command string `json:"command" form:"command" query:"command"`
Dir string `json:"dir" form:"dir" query:"dir"`
OutputMode OutputMode `json:"output_mode" form:"output_mode" query:"output_mode"`
Stdout string `json:"stdout" form:"stdout" query:"stdout"`
Stderr string `json:"stderr" form:"stderr" query:"stderr"`
WaitSec int `json:"wait_sec" form:"wait_sec" query:"wait_sec"`
Timeout int `json:"timeout" form:"timeout" query:"timeout"`
Sign string `json:"sign" form:"sign" query:"sign"`
}
JobExecuteResponse struct {
PID int `json:"pid" query:"pid" form:"pid"`
Code int `json:"code" query:"code" form:"code"`
Stdout string `json:"stdout" query:"stdout" form:"stdout"`
Stderr string `json:"stderr" query:"stderr" form:"stderr"`
}
// JobExecutor 任务执行器
// @service(job)
JobExecutor interface {
// Execute 执行任务
// @http.post("/execute")
Execute(ctx context.Context, req JobExecuteRequest) (resp JobExecuteResponse, err error)
}
)
复制代码进程通过 Go 语言官方包 os/exec 的 CommandContext() 方法并填充上述参数,使用 Run() 方法启动程序。
每个进程都使用了一个 goroutine 等待进程退出,避免子进程挂掉又没有回收资源,产生大量的僵尸进程,耗尽系统进程号。
而进程启动后,会向中控后台回传 PID 号,持久化数据库中。
即便是 Agent 挂掉,进程会交给 init 接管,不会存在 Agent 挂掉所有子进程都挂了的情况,而中控后台可以在 Agent 恢复时继续管理进程。
也就是说,Agent 与子进程本身是弱依赖关系,这点对于平台的高可用至关重要。
(2) 节点管理:节点信息、心跳服务
- 节点信息:获取节点的负载、CPU、内存、磁盘信息等;
- 心跳服务:用于探测节点存活。
type (
ServerInfoRequest struct {
DiskPath string `json:"disk_path" form:"disk_path" query:"disk_path"`
}
ServerInfoResponse struct {
Load *load.AvgStat `json:"load" query:"load" form:"load"`
CPU []cpu.InfoStat `json:"cpu" query:"cpu" form:"cpu"`
Mem *mem.VirtualMemoryStat `json:"mem" query:"mem" form:"mem"`
Disk *disk.UsageStat `json:"disk" query:"disk" form:"disk"`
}
HeartbeatRequest struct {
}
HeartbeatResponse struct {
UnixNano int64 `json:"unix_nano" query:"unix_nano" form:"unix_nano"`
}
// ServerManager 服务器管理
// @service(server)
ServerManager interface {
// GetServerInfo 获取服务器信息
// @http.get("/info")
GetServerInfo(ctx context.Context, req ServerInfoRequest) (resp ServerInfoResponse, err error)
// Heartbeat 心跳
// @http.get("/heartbeat")
Heartbeat(ctx context.Context, req HeartbeatRequest) (resp HeartbeatResponse, err error)
}
)
复制代码中控后台通过 Agent 提供的接口,实时获取节点信息。
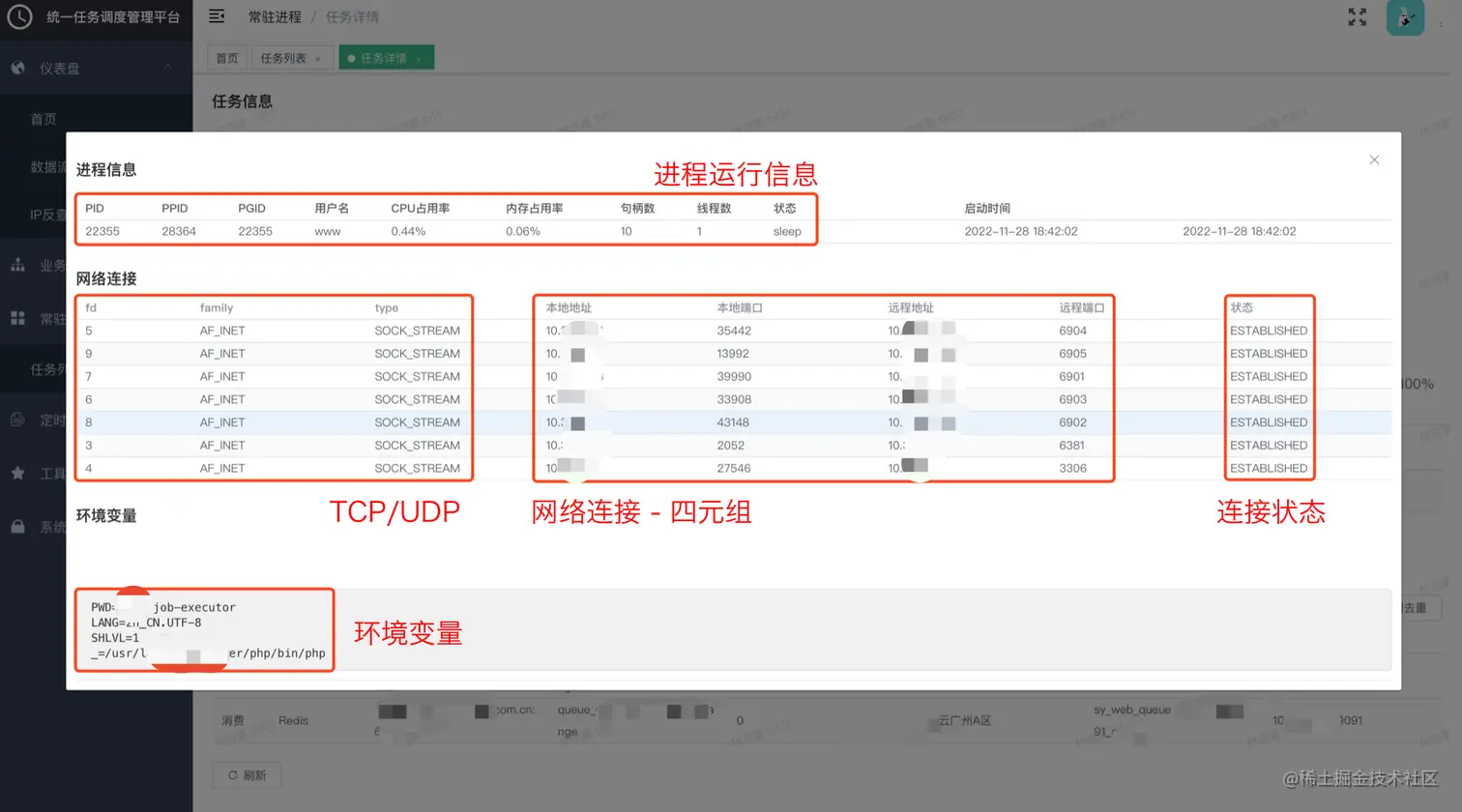
(3) 进程管理:进程存活、信息、信号管理
- 进程存活:探测到进程挂掉时可以及时拉起进程;
- 进程信息:根据 PID 获取进程使用的 CPU / 内存占有率、网络连接等信息;
- 发送信号:等同于 kill USR1 / SIGTERM / KILL...。
type (
ProcessInfoRequest struct {
PID int `json:"pid" form:"pid" query:"pid"`
}
ProcessInfoResponse struct {
PID int `json:"pid" query:"pid" form:"pid"`
PPID int `json:"ppid" query:"ppid" form:"ppid"`
PGID int `json:"pgid" query:"pgid" form:"pgid"`
CreateTime int `json:"create_time" query:"create_time" form:"create_time"`
CPUPercent float64 `json:"cpu_percent" query:"cpu_percent" form:"cpu_percent"`
Cmdline string `json:"cmdline" query:"cmdline" form:"cmdline"`
Connections []net.ConnectionStat `json:"connections" query:"connections" form:"connections"`
Cwd string `json:"cwd" query:"cwd" form:"cwd"`
Environ []string `json:"environ" query:"environ" form:"environ"`
Exe string `json:"exe" query:"exe" form:"exe"`
MemoryPercent float64 `json:"memory_percent" query:"memory_percent" form:"memory_percent"`
NumFDs int `json:"num_fds" query:"num_f_ds" form:"num_f_ds"`
NumThreads int `json:"num_threads" query:"num_threads" form:"num_threads"`
Status []string `json:"status" query:"status" form:"status"`
Username string `json:"username" query:"username" form:"username"`
}
SendSignalRequest struct {
PID int `json:"pid" form:"pid" query:"pid"`
Signal syscall.Signal `json:"signal" form:"signal" query:"signal"`
Reason string `json:"reason" form:"reason" query:"reason"`
}
// ProcessManager 进程管理
// @service(process)
ProcessManager interface {
// CheckProcess 检查进程存活
// @http.get("/check")
CheckProcess(ctx context.Context, req ProcessInfoRequest) (exist bool, err error)
// GetProcessInfo 获取进程信息(比较耗时,用于后台信息展示)
// @http.get("/info")
GetProcessInfo(ctx context.Context, req ProcessInfoRequest) (resp ProcessInfoResponse, err error)
// SendSignal 发送信号
// @http.post("/send_signal")
SendSignal(ctx context.Context, req SendSignalRequest) (err error)
}
)
复制代码中控后台通过上面 Agent 提供的进程信息接口,直观地展示出进程信息、网络连接等情况。
对于开发来说,很多时候出现问题,他也不需要 ssh 上机器了,只需在后台即可检查自己的服务有没有异常。
进程信息怎么拿?这个也是比较简单的,我们使用了 GitHub 上的开源项目 gopsutil - https://github.com/shirou/gopsutil,它可以获取到机器上的以下信息:
- CPU
- 内存
- 磁盘
- 负载
- 网络连接
- 进程信息
- 进程环境变量
- ……
感兴趣的可以移步链接查看。
(4) 文件管理:计算文件哈希
非核心模块,用于文件校验。
2. 统一任务调度平台——常驻进程管理
type (
// DeploymentManager
// @service(deployment_manager)
DeploymentManager interface {
SyncRunningInfo()
DeployDeployments()
StartCron()
HandleTask(ctx context.Context, db *gorm.DB, task DeploymentQueueTask)
CheckDeployment(ctx context.Context, task DeploymentQueueTask) (change bool, err error)
CloseDeployment(ctx context.Context, task DeploymentQueueTask) (change bool, err error)
SyncState(ctx context.Context, task DeploymentQueueTask, a *table.DeploymentStates) (change bool, err error)
KillState(ctx context.Context, task DeploymentQueueTask, a *table.DeploymentStates) (change bool, err error)
ScaleUp(ctx context.Context, task DeploymentQueueTask, server Server, n int) (change bool, err error)
ScaleDown(ctx context.Context, task DeploymentQueueTask, states table.DeploymentStatesSlice, n int) (change bool, err error)
}
)
复制代码实现核心有三点:
一是中控后台根据 MySQL 存储的进程部署信息,到对应的 node 拉起相关进程;
二是定时探活进程,保证进程故障的时候可以在第一时间拉起;
三是调度的过程,保证日志有详细的记录,进程失败时候提供企业微信的告警通知,方便开发及时排查问题。
(1) 底层数据存储
调度器定时读取 MySQL 存储的部署信息,请求 Agent 启动进程,并存储进程信息到以下的表中:
// deployment_states:常驻进程状态表
type DeploymentStates struct {
ID int `gorm:"column:id;PRIMARY_KEY;AUTO_INCREMENT;TYPE:int(20) unsigned;NOT NULL"` // 主键ID
DeploymentID int `gorm:"column:deployment_id;TYPE:int(10) unsigned;NOT NULL;INDEX:idx_deployment_id" sql:"DEFAULT:0"` // 所属常驻进程
Server string `gorm:"column:server;TYPE:varchar(100);NOT NULL;INDEX:idx_server"` // 服务器IP
Zone string `gorm:"column:zone;TYPE:varchar(100);NOT NULL"` // 服务器机房
Cmd string `gorm:"column:cmd;TYPE:varchar(190);NOT NULL"` // 命令行
Args string `gorm:"column:args;TYPE:varchar(190);NOT NULL"` // 执行参数
Dir string `gorm:"column:dir;TYPE:varchar(190);NOT NULL"` // 运行目录
Debug *int `gorm:"column:debug;TYPE:tinyint(4) unsigned;NOT NULL" sql:"DEFAULT:2"` // 调试模式: 0-关;1-开;2-无此参数,兼容管理后台配置
DebugArgs string `gorm:"column:debug_args;TYPE:varchar(190);NOT NULL"` // 调试参数: 仅在调试模式下有效。
Log *int `gorm:"column:log;TYPE:tinyint(4) unsigned;NOT NULL" sql:"DEFAULT:0"` // 是否记录日志: 0-丢弃,1-记录
Pid int `gorm:"column:pid;TYPE:int(10) unsigned;NOT NULL;INDEX:idx_pid" sql:"DEFAULT:0"` // 进程ID
CreatedAt time.Time `gorm:"column:created_at;TYPE:timestamp;NOT NULL" sql:"DEFAULT:CURRENT_TIMESTAMP"` // 创建时间
UpdatedAt time.Time `gorm:"column:updated_at;TYPE:timestamp;NOT NULL" sql:"DEFAULT:CURRENT_TIMESTAMP on update CURRENT_TIMESTAMP"` // 更新时间
}
复制代码deployment_id 关联了部署任务,deployment_states 表维护了启动的进程列表,该表最重要的是 server 和 pid 字段,因为常驻进程如果挂掉,调度器需要及时拉起进程,也就是定时探活机制。
(2) 定时探活机制
通过进程号 PID,我们可以得知进程的一切情况。调度器内部使用定时任务的方式,对表中的部署进程定时探测,发现故障进程快速拉起。
(3) 变更日志持久化
开发如果对线上进程进行操作,如重启、禁用等,日志会落盘到 MySQL 中。同样的,调度器对故障进程的拉起、扩缩容等操作也会记录日志。
3. 统一任务调度平台——定时任务管理
type (
// CronJobManager 定时任务管理器
// @service(cron_job_manager)
CronJobManager interface {
prometheus.Collector
RunOnceCronJob(ctx context.Context, ID int, operator string) (err error)
DeployCronJobs()
}
)
复制代码定时任务的实现稍微复杂了一些。
和常驻进程一样,也是读取了 MySQL 的进程部署信息,结合 GitHub 开源项目 cron - https://github.com/robfig/cron 包,做了定时触发执行任务的功能。
而业务也存在手工出发一次定时任务的情况,所以此处加了 RunOnceCronJob() 方法。
(1) 双向同步机制
重点在于 DeployCronJobs() 方法,它定时从数据库更新 sync(),把进程信息和 cron 包做了双向同步:
func (s *Service) sync() {
db := s.DB.GetDB(context.Background())
var groups table.GroupsSlice
if err := db.Table(table.TableGroups).Find(&groups).Error; err != nil {
return
}
s.groupsMapping = groups.ToIntMap(func(t *table.Groups) int { return t.ID })
existModelIDs := map[int]struct{}{}
s.CronJobsStore.List().ForEach(func(i int, t *table.CronJobs) {
existModelIDs[t.ID] = struct{}{}
// 从数据库同步到调度器
job, ok := s.getCronJobByModelID(t.ID)
// 未修改 -> 不操作
if ok && !job.Changed(t) {
return
}
// 修改/新增 -> 删除后新增
s.delCronJob(job)
_, _ = s.newCronJob(t)
})
entries := s.CronScheduler.Entries()
for _, entry := range entries {
job, ok := s.getCronJobByEntryID(entry.ID)
if !ok {
// 跳过非数据库的任务
continue
}
// 针对已删除的记录从调度器反向同步
if _, exist := existModelIDs[job.modelID]; !exist {
s.delCronJob(job)
}
}
}
复制代码可能有些人看到双向同步不太理解,它的核心逻辑是这样的:
- 数据库的定时任务,都保存到调度器中;
- 调度器的定时任务,如果数据库已经被删除了,需要停止调度。
正常是把数据从 MySQL -> 同步 -> cron 实例,从而实现定时触发任务。
但是任务如果被删除,我们需要反过来遍历:
也就是 cron 实例里面没有在 MySQL 数据维护的,需要停止调度。
如果不做双向同步,在后台删除的时候,推送消息队列移除任务,也是可行的。只是需要多维护一套 MQ,要考虑消息的可靠性送达。
在我看来,采用双向同步的实现,更为简洁明了,可用性更加有保障。
(2) 底层数据结构
为了实现方便,我封装了 cronJob 结构:
type cronJob struct {
operator string
srv *Service
model table.CronJobs // 数据库 gorm 模型
modelID int
entryID cron.EntryID // cron 包定时任务句柄
after func(j *cronJob, serverIP string, now int64, err error)
}
复制代码cronJob 维护了数据库模型,与 cron 调度器的调度句柄等信息,并实现了 Job() 接口,可以作为任务添加到 cron 调度器内部。
// Job is an interface for submitted cron jobs.
type Job interface {
Run()
}
复制代码Run() 方法有几个比较重要的点:
- 选点上,如果用户交给调度器,调度器会优先选择节点池负载最低的机器执行任务;
- 记录进程的选点信息,上次执行的时间、PID 等信息;
- 如果上次任务没跑完,这次就不会触发了(防雪崩),否则永远跑不完,机器迟早得宕机——相信很多 SRE 都有经历过,自己要维护 shell 脚本避免雪崩,真的是令人抓狂。
(3) 高可用保证
另外,还有一个值得一提的事情——任务执行的高可用保证。
以往 PHP 调度系统在上云时不好停止,因为是 PHP 单实例部署,包含了多个进程,切换过程和步骤较为繁琐。
**现在调度器使用实例部署,意味着实例可以随便挂,反正保证有一个实例能抢到锁就可以了。**具体步骤是这样的:
- 调度器多实例部署,执行任务通过分布式锁协商(是否会产生脑裂现象,取决于底层的 Redis 实例);
- 抢锁成功,负责选点(自动)并执行任务;
- 机器选点会剔除失联的机器。
「统一任务调度平台」对于「分布式锁」做了一层抽象,目前是 Redis 的实现,基于 SetNX 命令:
type (
LockerHandle struct {
Key string `json:"key"`
UUID string `json:"uuid"`
}
Locker interface {
Lock(ctx context.Context, key string, expiration time.Duration) (h LockerHandle, err error)
Unlock(ctx context.Context, h LockerHandle) (err error)
}
)
复制代码而**「分布式锁」**是 CP 模型,而 Redis 主从模式本质上是 AP,这样的实现,会导致一个后果:
在某些情况下,任务可能会被重复启动!
它发生在 Redis 主故障后,从提升为主库,而调度器由于是多实例部署,可能有的拿到了旧主库的锁,有的实例拿到了新主库的锁!
根据 CAP 定理,P(分区)是一定要满足的,C(一致性)、A(可用性)只能选择其一。当前我们采用 AP,容忍任务的重复启动。
我认为也可以选择 etcd,或者自行实现分布式一致性算法(Raft、Paxos 等),出故障时部署了半数以上调度实例的机房,可以正常提供服务。
4. 统一任务调度平台——其他功能
除了以上核心功能,我们还联动了 Prometheus,聚合了进程的运行信息:
- 进程名称、部署任务关联
- 进程生产、消费的队列信息(Redis / RabbitMQ / Kafka)
- 数据流(全平台链路拓扑图)
它的好处非常多,这点也是 Kubernetes 暂时无法做到的,至少 Service Mesh 目前还没有一个这么好用的后台展示功能。
譬如,我们可以通过中控后台,清楚地知道某个任务生产、消费的队列信息——
而任务本身有业务负责人,队列堆积的时候,我们会发送企业微信通知负责人及时处理。
实现上,我们将以下信息上报到 Prometheus:
- Go 语言的自研框架自带程序运行信息;
- PHP 脚本通过扩展的形式,内部 hook 了数据库、RPC 调用。
而中控后台,通过官方提供的接口 v1.API,加载当前的所有 Go 程序信息,再通过程序名称,获取 Go 程序的 Runtime 信息展示出来:
func (s *Service) GoInfo(ctx context.Context) {
t2 := time.Now()
t1 := t2.Add(-time.Hour * 2)
labelSets, _, err := s.PrometheusV1API.Series(ctx, []string{`go_info`}, t1, t2)
if err != nil {
return
}
logger.FromContext(ctx).Infof("[GoInfo] 共加载 %d 个监控数据", len(labelSets))
for _, labelSet := range labelSets {
exportedJob := string(labelSet["exported_job"])
...
}
}
复制代码举个例子,我可以通过部署任务的名称,模糊匹配,进而查询其队列信息:
func (s *Service) FindQueueListByCmd(ctx context.Context, qs service.QuerySeries) (items []service.QueueItem, err error) {
metrics := "mq_consume_total"
if qs.Produce {
metrics = "mq_produce_total"
}
query := fmt.Sprintf(`%s{exported_job=~".*%s.*"}`, metrics, qs.Arg)
labelSets, _, err := s.PrometheusV1API.Series(ctx, []string{query}, qs.T1, qs.T2)
if err != nil {
return
}
re := regexp.MustCompile(`(.+):(.+)@`)
for _, labelSet := range labelSets {
_type := string(labelSet["type"])
_addr := string(labelSet["addr"])
// ...
switch _type {
case "redis_list":
item.Type = service.QueueTypeRedis
case "amqp":
fallthrough
case "rmq":
item.Type = service.QueueTypeRabbitMQ
case "kafka":
item.Type = service.QueueTypeKafka
}
// ...
items = append(items, item)
}
// 聚合队列长度
err = s.withQueueLength(ctx, items)
return
}
复制代码更进一步说:
因为每个服务的下游,如 MySQL、Redis、RabbitMQ、Kafka、RPC 等都是已知的,
所以我们可以从监控系统,队列信息,完整地聚合出全平台的链路图。
四、总结与展望
「统一任务调度平台」在手游内部已经稳定运行近一年时间,业务反馈非常好用,自研的调度平台更贴合我们公司内部的需求。
在我看来,自研是艰辛的且富有挑战性的,往往需要权衡很多问题:
- 一是要满足功能需求,比如调度、日志、告警等;
- 二是技术选型,我们采用了 MySQL + Redis + Go 语言,不得不说 Go 语言开发起来真的是十分顺手;
- 三是系统安全性,这部分我没有展开细说,我个人觉得,执行任务最好规避 ssh 协议,因为对 SRE 来说维护成本较高;
- 四是系统架构层面,着重考虑平台的高可用性,还有后续的扩展性等;
其他的,比如用户体验上,要贴合使用者的直觉,自然而不刻意,一切都恰到好处。
当下,我们正在逐步推进服务化和容器化——
对于传统的消费者模型的服务,剥离它的消费与数据处理的逻辑,消费逻辑统一由队列托管平台接管,
而数据加工处理的过程,对外暴露成无状态服务,从而部署到 Kubernetes 上。
未来——
37 手游「统一任务调度平台」将会支持 Kubernetes 多集群的管理,不再局限于传统虚拟机部署的模式。
嗯,让我们一起拥抱云原生吧!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号