【论文笔记】2019-ACL-Dialog State Tracking: A Neural Reading Comprehension Approach

【论文笔记】2019-ACL-Dialog State Tracking: A Neural Reading Comprehension Approach

yhlin
发布于 2023-02-27 17:03:59
发布于 2023-02-27 17:03:59
概要
问题动机
以往的 DST 方法通常都是输出一个对所有槽值的预测概率分布,使得模型无法预测 unseen 的槽值。这篇文章的作者以不同角度看待 DST 问题,将其建模为一个阅读理解任务,让模型回答“What is the state of the current dialog ?”这个问题。
主要贡献
- 应用阅读理解的方法,提出了一个简单的基于注意力的神经网络模型来提取对话历史中的槽值,并克服了以往方法中的 fixed-vocabulary 问题能够生成的 unseen 状态值
- 将 DST 的任务描述为三个顺序决策:
- 通过简单 slot carryover 模型的二元 carryover 决策
- 通过 slot type 模型的槽类型决策
- 通过阅读理解模型的槽跨度(slot span)决策
- 整合 Bert 模型,得到相当大的改进
- 在 MultiWOZ 2.0 跨域对话数据集上取得与更复杂模型相似的精度表现
相关研究
阅读理解任务通常被表述为一个监督学习问题,对于给定的训练数据集,目标是学习一个预测器,它将一段 p 和相应的问题 q 作为输入,并给出答案 a 作为输出。
- 2018-arXiv-Flexible and scalable state tracking frame work for goal-oriented dialogue systems.
- 2017-ACL-Dialog state tracking, a machine reading approach using memory network.
- 2018-ACL-An end-to-end approach for handling unknown slot values in dialogue state tracking.
方法详解
DST as Reading Comprehension
定义对话 D 的一个子对话 D_t 作为以用户话语结束的完整对话的前缀,其状态由组成插槽 s_j(t) 的值定义,即 S(t)={s_1(t),s_2(t),.s_j(t),...,s_M(t) } 定义。
可以把 D_t 当成一篇文章,对于每一个插槽 i 制定一个问题 q_i : 槽 i 的值是多少?这样子 DST 任务就变成了一个理解 D_t 并回答问题 q_i 的阅读理解任务了!
Encoding
Dialog Encoding
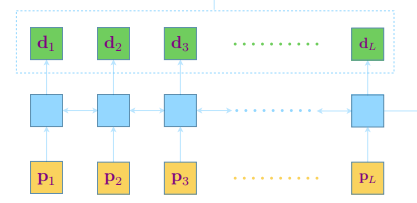
并将他们作为输入馈入一个 RNN 中:
L: 表示拼接序列的长度 d_i:RNN 对于每一个 token 的输出,包含上下文信息 p_i:用 Bert 模型生成的预训练词嵌入 RNN:这里使用的是单层双向 LSTM,故 d_i = (\overleftarrow{d_i};\overrightarrow{d_i})
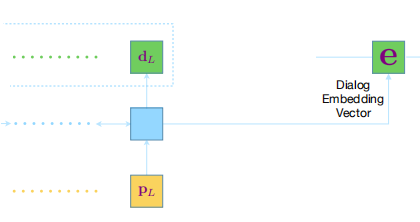
回合对话的嵌入表示:
Question Encoding
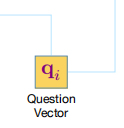
将前面定义的问题 q_i 定义为“插槽 i 的值是什么?”对于每个对话,都有 M 个对应于 M 个槽的类似问题,因此,我们将每个问题 q_i 表示为一个固定维度的向量 \bf{q}_i 来学习。
模型
Overview
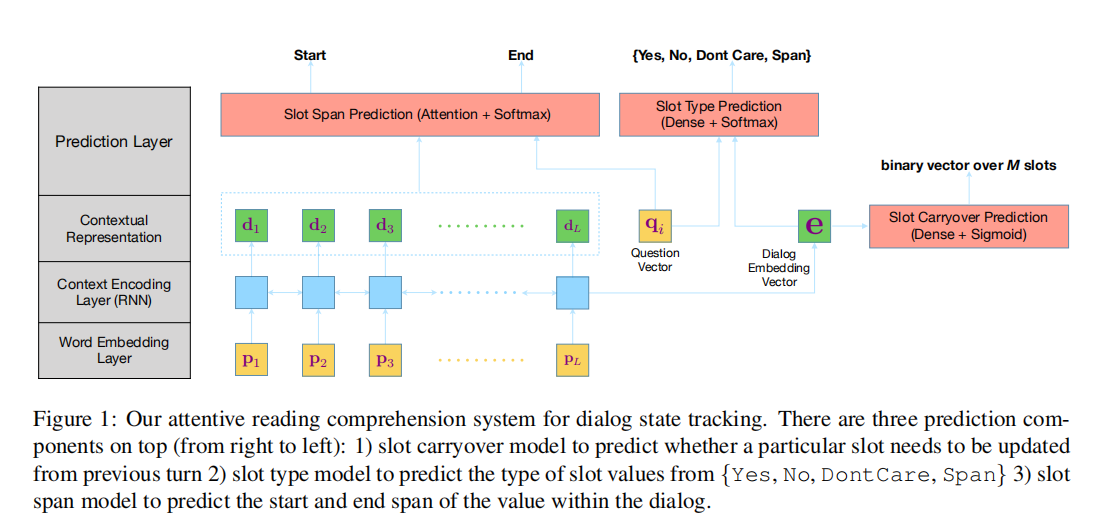
如上图在完整模型设置中,三个不同的模型组件被用来进行一系列的预测:首先,使用一个 slot carryover 模型来决定是否从最后一个回合中 carryover 一个槽值。如果 slot carryover 模型决定不延续,则执行一个 slot type 预测模型,从 {Yes, No, DontCare, Span} 集合预测答案类型。如果 slot type 模型预测结果为 Span,则 Slot Span 预测模型最终将预测插槽值作为对话中 tokens 的 span(start,end)
Slot Carryover Model
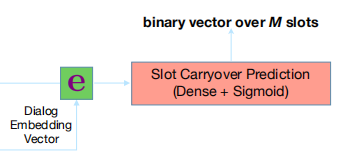
: C_j(t) = \begin{cases} 1, & \text {if s_j(t) = s_j(t-1)} \end{cases}P(C_i(t)) = sigmoid(e(t)\cdot W_i)
W_i : 对于不同槽都有一个权重矩阵,神经网络将联合预测所有 M 个槽的 slot carryover 结果
Slot Type Model
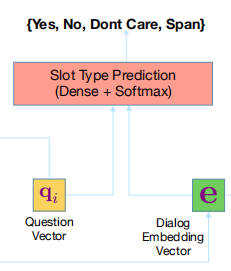
该模型是一个用来预测每一回合槽值类型的分类器。如果预测结果为 Span 表示可以在对话中找到槽值实体。如上图所示,具体计算如下:
Slot Span Model
,其分布计算如下:
实验
数据集
采用 MultiWOZ 多域对话数据集,包含 7 个不同域共 37 个 slot,之中许多槽类型都是在不同域之间共享的。实验中通过考虑槽域、槽类型、槽名的链接来独立处理每个槽。

主要结果
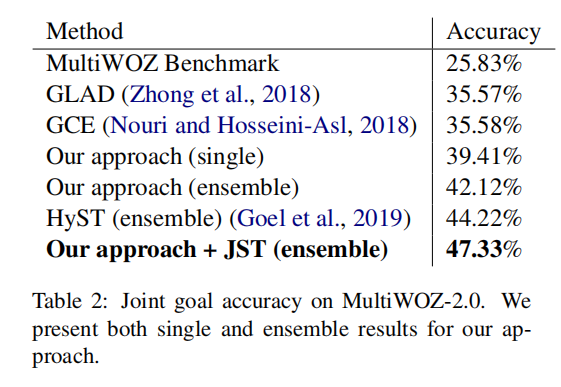
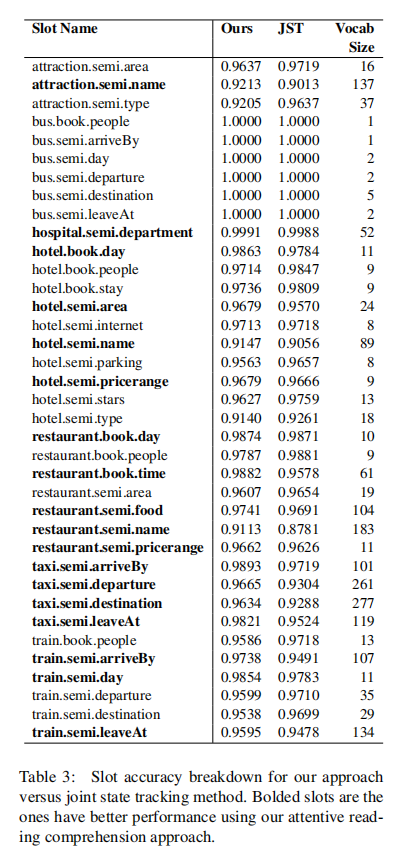
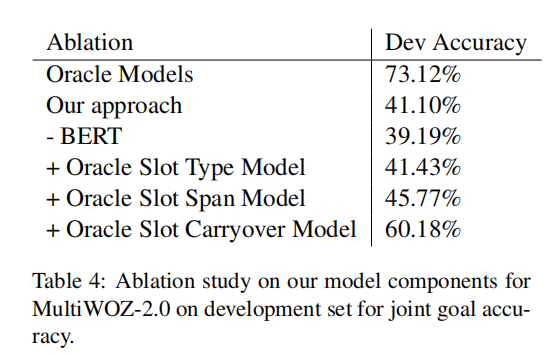
消融实验
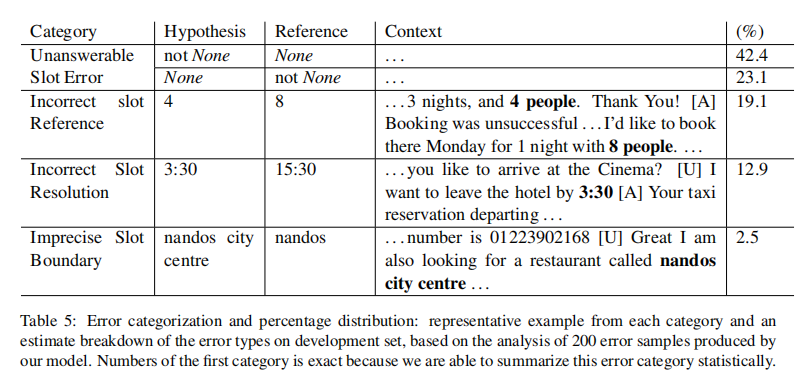
错误分析
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2022-11-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号