pandas库的简单介绍(2)

pandas库的简单介绍(2)

python数据可视化之路
发布于 2023-02-23 21:23:23
发布于 2023-02-23 21:23:23
3、 DataFrame数据结构
DataFrame表示的是矩阵数据表,每一列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既包含行索引,也包含列索引,可以视为多个Series集合而成,是一个非常常用的数据结构。
3.1 DataFrame的构建
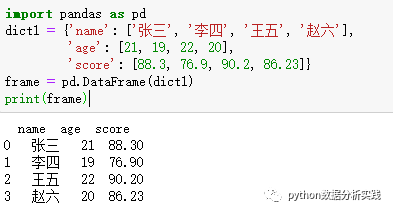
DataFrame有多种构建方式,最常见的是利用等长度的列表或字典构建(例如从excel或txt中读取文件就是DataFrame类型)。
另外一个构建的方式是字典嵌套字典构造DataFrame数据;嵌套字典赋给DataFrame,pandas会把字典的键作为列,内部字典的键作为索引。

3.2 DataFarme的基础操作
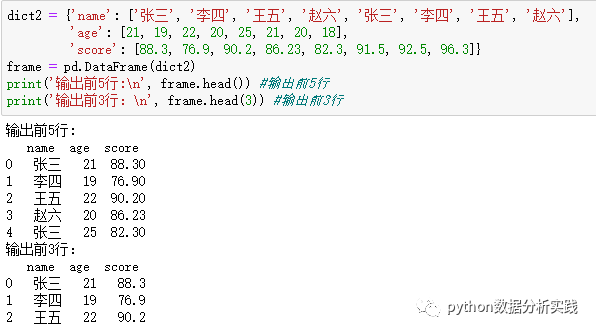
(*1)输出前n行
输出前n行用到了head()函数,如果不加参数,默认输出前5行,加参数,例如3,输出前3行。输出尾部n行同理,用到了tail()函数。
(*2)指定列顺序和索引列、删除、增加列
指定列的顺序可以在声明DataFrame时就指定,通过添加columns参数指定列顺序,通过添加index参数指定以哪个列作为索引;移除列可以用del frame[列名]进行移除;增加列有两个方法:1,直接frame[列名]=值;2,frame[列名]=Series对象,如果被赋值的列不存在,会生成一个新列。


(3)为列、索引命名和values属性
与Series一样,DataFrame也能为列,索引命名,同时也有values属性。

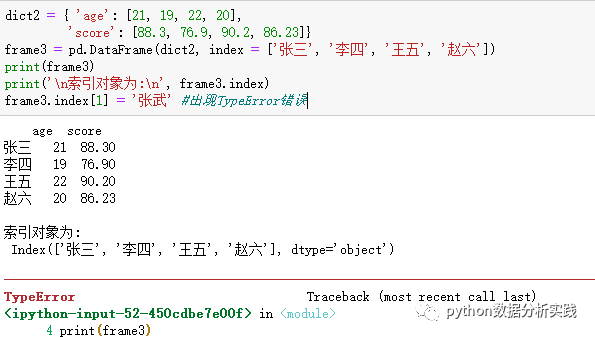
(*4)索引对象的特征和操作
索引对象的重要特征是不可变的,因此我们无法修改索引对象(初学者常常忽略这一点)。
索引对象类似数组;也像一个固定大小的集合,但是集合不允许有重复元素,索引对象则可以。由于类似数组和集合,索引对象的一些方法和属性如下:
一些索引对象的方法和属性
方法 | 描述 |
|---|---|
append | 将额外的索引对象粘贴到原对象后,产生一个新的索引 |
difference | 计算两个索引的差集 |
intersection | 计算两个索引的交集 |
union | 计算两个索引的并集 |
delete | 将位置i的元素删除,并产生新的索引 |
drop | 根据传入的参数删除指定索引值,并产生新索引 |
unique | 计算索引的唯一值序列 |
is_nuique | 如果索引序列唯一则返回True |
is_monotonic | 如果索引序列递增则返回True |
4 pandas基本功能
这里主要关注Series或DataFrame数据交互的机制和最主要的特性。不常用的特性感兴趣的可自行探索。
4.1 重建索引
reindex是pandas对象的重要方法,该方法创建一个符合条件的新对象。如果某个索引值之前并不存在,则会引入缺失值;在这里注意与上一篇文章2.2的区别。

对于顺序数据,例如时间序列,重建索引时可能会需要进行插值或填值。method方法可选参数允许我们使用ffill等方法在重建索引时插值,ffill方法会将值前项填充;bfill是后向填充。
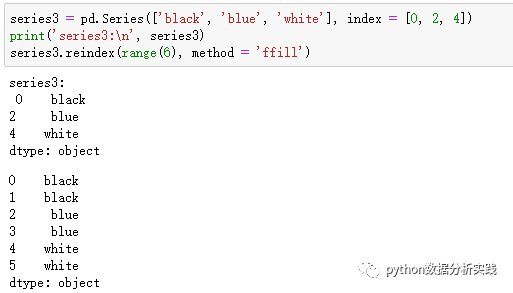
在DataFrame中,reindex可以改变行索引、列索引,当仅传入一个序列,会默认重建行索引。
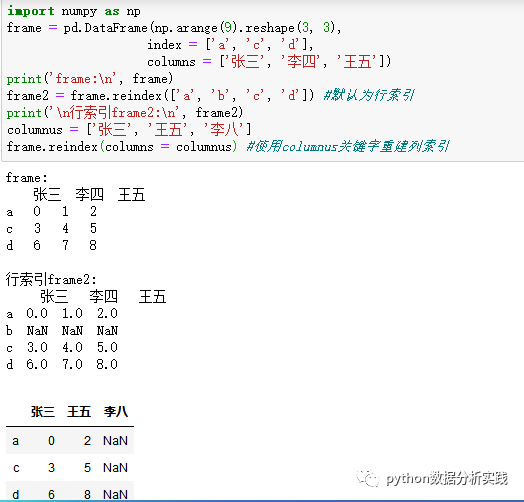
另外一种重建索引的方式是使用loc方法,可以了解一下:

reindex方法的参数表
常见参数 | 描述 |
|---|---|
index | 新的索引序列(行上) |
method | 插值方式,ffill前向填充,bfill后向填充 |
fill_value | 前向或后向填充时缺失数据的代替值 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2021-01-19,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 python数据可视化之美 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号