Rust学习笔记Day20集合容器之哈希表


昨天我们一起学习了切片,对比了数组、列表、字符串和它们对应的切片,以及切片引用的关系。 今天我们继续学习另一个集合容器HashMap,也就是哈希表。
哈希表在很多语言里都有这种数据结构。
- PHP里的数组
- Python里的字典dict
- JavaScript里的Map
Rust的哈希表
官方文档出现了两个逼格比较高的词汇:二次探查、SIMD查表。
哈希表最核心的特点就是:巨量的可能输入和有限的哈希表容量。这就会引发哈希冲突,也就是两个或者多个输入的哈希被映射到了同一个位置,所以我们要能够处理哈希冲突。
解决冲突
主要的冲突解决机制有:
- 链地址法(chaining)
- 开放寻址法(open addressing)。
链地址法
这个比较简单,把哈希冲突的数据用链表串起来。 这样在查找的时候,先找到hash bucket,再到冲突链上线性比较。
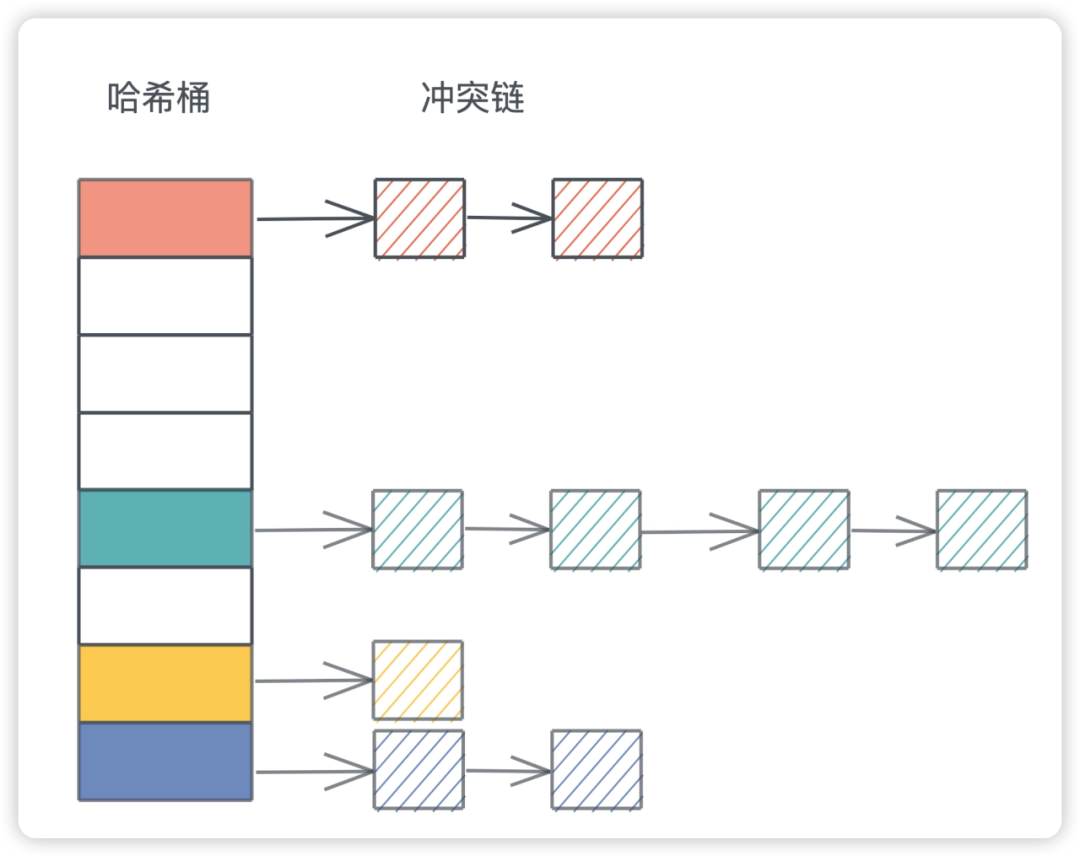
冲突链处理哈希冲突非常直观,很容易理解和撰写代码,但缺点是哈希表和冲突链使用了不同的内存,对缓存不友好。
二次探查
在发生冲突时,不断探寻哈希位置加减n的二次方,找到空闲的位置插入。(这就是开放地址法?)
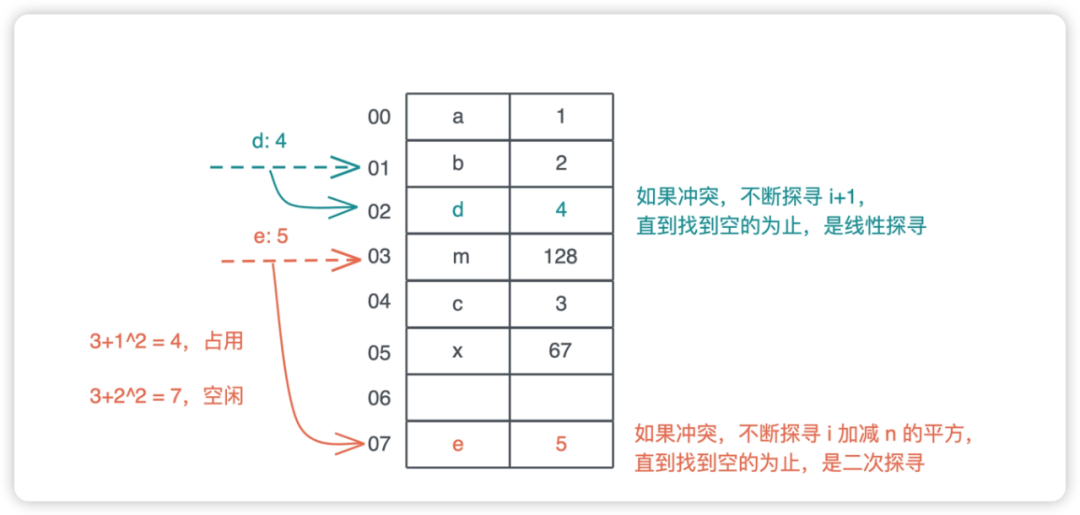
也有其他方案,比如二次哈希什么的。
另一个使用 SIMD 做单指令多数据的查表,也和一会要讲到 Rust 哈希表巧妙的内存布局息息相关。
HashMap
看下Rust的哈希表代码定义:
use hashbrown::hash_map as base;
#[derive(Clone)]
pub struct RandomState {
k0: u64,
k1: u64,
}
pub struct HashMap<K, V, S = RandomState> {
base: base::HashMap<K, V, S>,
}
可以看到,HashMap 有三个泛型参数,
- K 和 V 代表 key / value 的类型
- S 是哈希算法的状态,它默认是 RandomState,占两个 u64。
- RandomState 使用 SipHash 作为缺省的哈希算法,它是一个加密安全的哈希函数
Rust 的 HashMap 复用了 hashbrown 的 HashMap。
pub struct HashMap<K, V, S = DefaultHashBuilder, A: Allocator + Clone = Global> {
pub(crate) hash_builder: S,
pub(crate) table: RawTable<(K, V), A>,
}
HashMap 里有两个域:
- 一个是 hash_builder,类型是刚才我们提到的标准库使用的 RandomState。
- 一个是具体的 RawTable。
pub struct RawTable<T, A: Allocator + Clone = Global> {
table: RawTableInner<A>,
// Tell dropck that we own instances of T.
marker: PhantomData<T>,
}
struct RawTableInner<A> {
// Mask to get an index from a hash value. The value is one less than the
// number of buckets in the table.
bucket_mask: usize,
// [Padding], T1, T2, ..., Tlast, C1, C2, ...
// ^ points here
ctrl: NonNull<u8>,
// Number of elements that can be inserted before we need to grow the table
growth_left: usize,
// Number of elements in the table, only really used by len()
items: usize,
alloc: A,
}
这里RawTableInner,前四个字段很重要:
- bucket_mask 是哈希桶的数量 -1;
- ctrl 指针,它指向哈希表堆内存末端的 ctrl 区;
- growth_left,指哈希表在下次自动增长前还能存储多少数据;
- items,指哈希表当前数据的条数。
- alloc,和 RawTable 的 marker 一样,只是一个用来占位的类型,我们现在只需知道,它用来分配在堆上的内存。(是不是有点像柔性数组?)
使用方法
使用方法很简单: 常用的有:
- map.insert(k, v);
- map.get(&k);
- map.get_key_value(&k);
- map.remove(&k);
- map.contains_key(&k);
- map.shrink_to_fit();
看一段代码,感觉一下
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
explain("empty", &map);
map.insert('a', 1);
explain("added 1", &map);
map.insert('b', 2);
map.insert('c', 3);
explain("added 3", &map);
map.insert('d', 4);
explain("added 4", &map);
// get 时需要使用引用,并且也返回引用
assert_eq!(map.get(&'a'), Some(&1));
assert_eq!(map.get_key_value(&'b'), Some((&'b', &2)));
map.remove(&'a');
// 删除后就找不到了
assert_eq!(map.contains_key(&'a'), false);
assert_eq!(map.get(&'a'), None);
explain("removed", &map);
// shrink 后哈希表变小
map.shrink_to_fit();
explain("shrinked", &map);
}
fn explain<K, V>(name: &str, map: &HashMap<K, V>) {
println!("{}: len: {}, cap: {}", name, map.len(), map.capacity());
}
输出如下:
empty: len: 0, cap: 0
added 1: len: 1, cap: 3
added 3: len: 3, cap: 3
added 4: len: 4, cap: 7
removed: len: 3, cap: 7
shrinked: len: 3, cap: 3
有几点发现:
- new的时候没有分配空间,容量是零。
- 哈希表的扩容是以2的幂-1的方式增长,对比Go数据小的时候,2的幂,大了以后1.25倍?
- Rust的哈希表还可以调用shrink_to_fit缩容,Go的map好像不能缩容。
内存布局
要想看HashMap的布局,需要用std::mem::transmute方法打印数据结构,代码如下:
use std::collections::HashMap;
fn main() {
let map = HashMap::new();
let mut map = explain("empty", map);
map.insert('a', 1);
let mut map = explain("added 1", map);
map.insert('b', 2);
map.insert('c', 3);
let mut map = explain("added 3", map);
map.insert('d', 4);
let mut map = explain("added 4", map);
map.remove(&'a');
explain("final", map);
}
// HashMap 结构有两个 u64 的 RandomState,然后是四个 usize,
// 分别是 bucket_mask, ctrl, growth_left 和 items
// 我们 transmute 打印之后,再 transmute 回去
fn explain<K, V>(name: &str, map: HashMap<K, V>) -> HashMap<K, V> {
let arr: [usize; 6] = unsafe { std::mem::transmute(map) };
println!(
"{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}",
name, arr[2], arr[3], arr[4], arr[5]
);
unsafe { std::mem::transmute(arr) }
}
运行结果
empty: bucket_mask 0x0, ctrl 0x1056df820, growth_left: 0, items: 0
added 1: bucket_mask 0x3, ctrl 0x7fa0d1405e30, growth_left: 2, items: 1
added 3: bucket_mask 0x3, ctrl 0x7fa0d1405e30, growth_left: 0, items: 3
added 4: bucket_mask 0x7, ctrl 0x7fa0d1405e90, growth_left: 3, items: 4
final: bucket_mask 0x7, ctrl 0x7fa0d1405e90, growth_left: 4, items: 3
我们发现ctrl的地址发生了变化。
- 没有数据的时候,指向了一个空表的地址。
- 插入数据后指向了一个刚申请的地址。
- 扩容后,指向了重新分配的地址。
ctrl 是一个指向哈希表堆地址末端 ctrl 区的地址,所以我们可以通过这个地址,计算出哈希表堆地址的起始地址。
计算方法: 哈希表有 8 个 bucket(0x7 + 1),每个 bucket 大小是 key(char) + value(i32) 的大小,也就是 8 个字节,所以一共是 64 个字节。对于这个例子,通过 ctrl 地址减去 64,就可以得到哈希表的堆内存起始地址。
要想弄清理这里,需要搞清楚ctrl表。
我们明天接着学习ctrl表。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-02-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号