Python之CrawlSpider

Python之CrawlSpider

鱼找水需要时间
发布于 2023-02-16 18:36:12
发布于 2023-02-16 18:36:12
CrawlSpider继承自scrapy.Spider
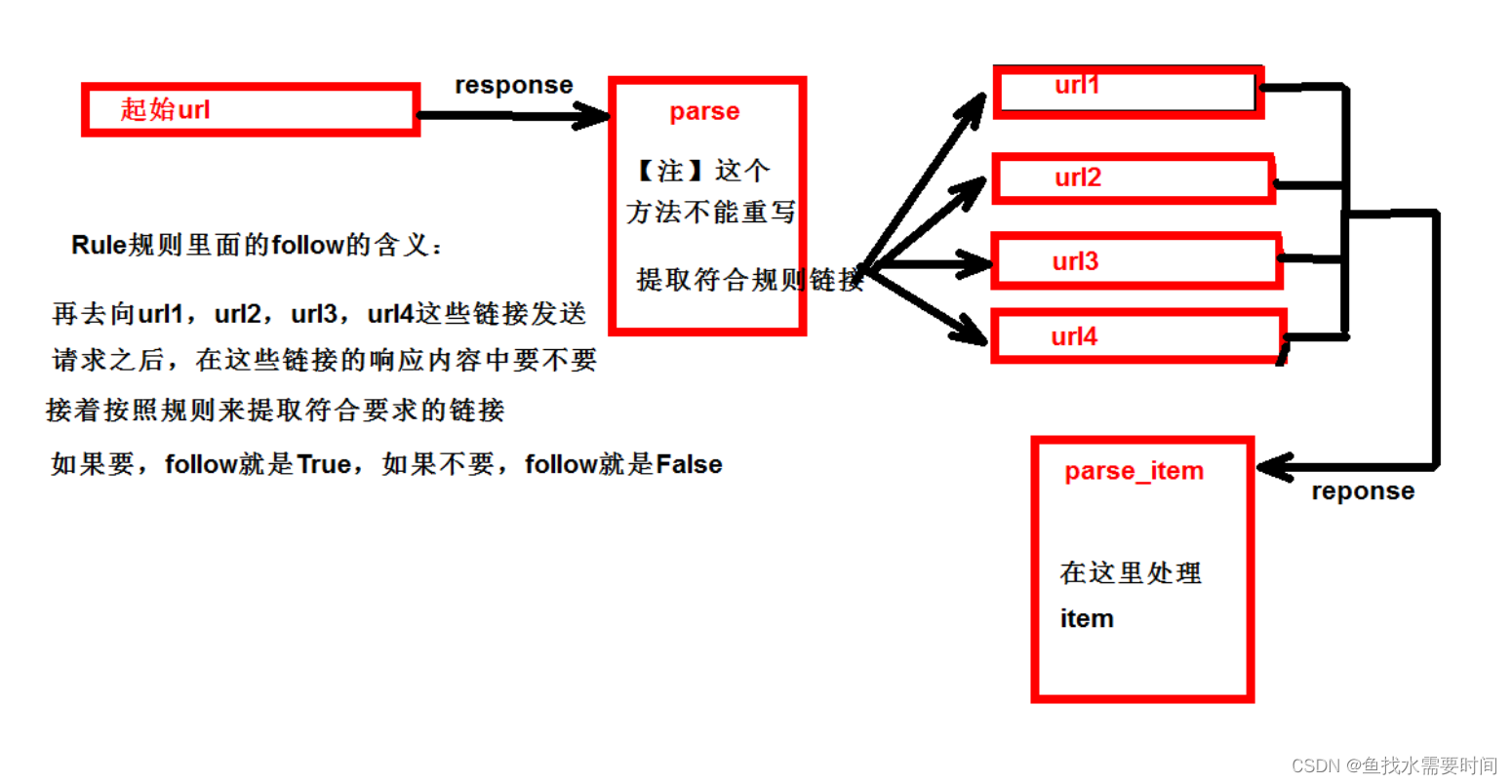
CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的
提取链接
链接提取器,在这里就可以写规则提取指定链接
scrapy.linkextractors.LinkExtractor(
-
allow = (),# 正则表达式 提取符合正则的链接 -
deny = (),# (不用)正则表达式 不提取符合正则的链接 -
allow_domains = (),# (不用)允许的域名 -
deny_domains = (),# (不用)不允许的域名 -
restrict_xpaths = (),# xpath,提取符合xpath规则的链接 -
restrict_css = ()# 提取符合选择器规则的链接)
示例:
正则用法:links1 = LinkExtractor(allow=r'list_23_\d+\.html')
xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]')
css用法:links3 = LinkExtractor(restrict_css='.x')提取连接:
link.extract_links(response)注意事项
【注1】callback只能写函数名字符串, callback='parse_item'
【注2】在基本的spider中,如果重新发送请求,那里的callback写的是 callback=self.parse_item
,follow=true 是否跟进 就是按照提取连接规则进行提取
案例
1.创建项目:scrapy startproject scrapy_crawlspider
2.跳转到spiders路径 cd\scrapy_crawlspider\scrapy_crawlspider\spiders
3.创建爬虫类:scrapy genspider ‐t crawl read www.dushu.com
read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_crawlspider.items import ScrapyCrawlspiderItem
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1188_1.html']
rules = (
Rule(LinkExtractor(allow=r'/book/1188_\d+.html'),
callback='parse_item',
follow=False),
)
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//img')
for img in img_list:
name = img.xpath('./@data-original').extract_first()
src = img.xpath('./@alt').extract_first()
if name == None:
name = img.xpath('./@src').extract_first()
print(name + src)
book = ScrapyCrawlspiderItem(name=name, src=src)
yield bookfollow为True代表一直跟下去,直到没有页数,为False代表之爬取1-13页

items.py
class ScrapyCrawlspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()pipelines.py
class ScrapyCrawlspiderPipeline:
def open_spider(self, spider):
self.fp = open('book.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self, spider):
self.fp.close()settings.py开启管道
ITEM_PIPELINES = {
'scrapy_crawlspider.pipelines.ScrapyCrawlspiderPipeline': 300
}数据入库
首先安装pip isntall pymysql
1、settings配置参数
#
DB_HOST = '127.0.0.1'
# 端口号是一个整数
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWROD = '123456'
DB_NAME = 'py_bd'
# utf-8的杠不允许写
DB_CHARSET = 'utf8'
# 开启管道
ITEM_PIPELINES = {
'scrapy_crawlspider.pipelines.ScrapyCrawlspiderPipeline': 300
'scrapy_crawlspider.pipelines.MysqlPipeline': 301,
}2、管道配置
# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline:
def open_spider(self, spider):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWROD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# 数据库提前建好这张表
sql = 'insert into test_book(name,src) values("{}","{}")'.format(item['name'], item['src'])
# 执行sql语句
self.cursor.execute(sql)
# 提交
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2022-07-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号