一文读懂JVM虚拟机
原创

JVM
1、内存模型
image
内容描述
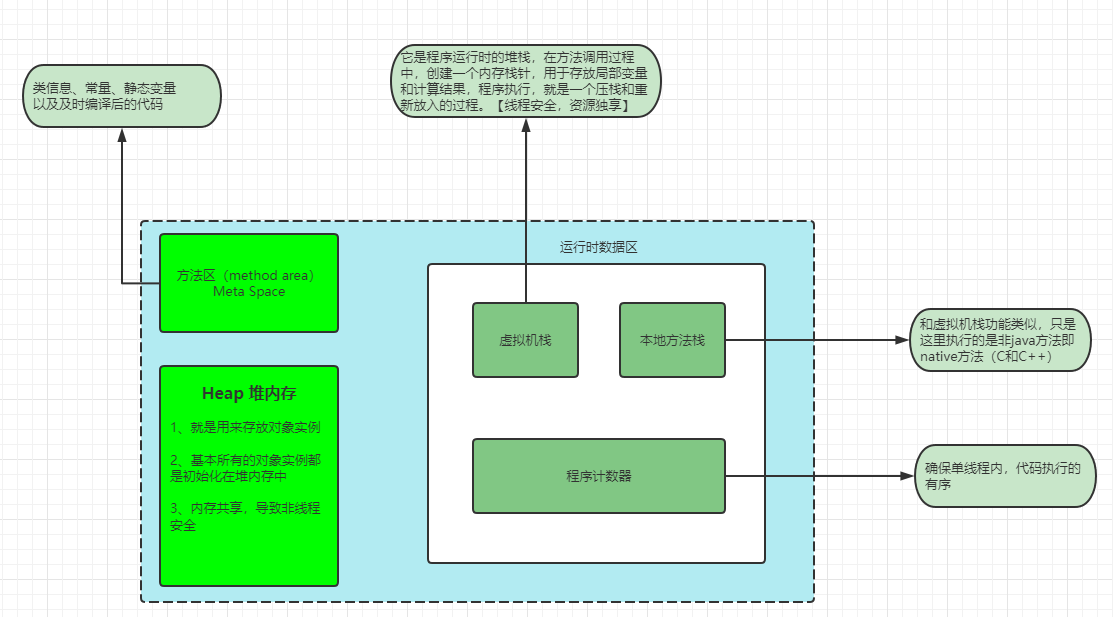
从上图可以看出,JVM的内存区域主要分为两个大块,一是内存共享区,一是内存线程私有区。
结合java代码的执行编译过程,可以理解成:当我们的代码呗java执行引擎加载后,解释器进行处理成.class文件,通过JIT(即时编译器)编译,中间涉及到类加载的过程(先略过),此时编译后的代码和一些常量、静态变量都会保存在方法区中。随着代码的执行,会创建对象,这些对象都会存放在堆内存空间。代码的执行,都是由main线程执行,随着程序的调用,线程中的程序计数器,会记录每个程序执行到了哪一步,同时伴随着方法调用,通过虚拟机栈压栈和弹栈的动作往下执行,当程序执行完毕后就涉及到对象的回收和销毁过程。
2、类加载过程
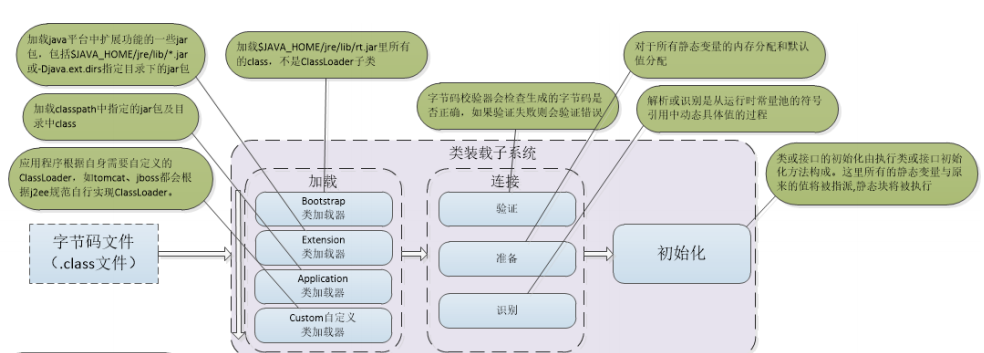
image-1663581984967
聊完内存分配,涉及到的重点就是类加载过程
常规意义上,我们都把类加载器分为四层,逐层继承。最顶层是BootStrap加载器,通过源码,我们可以看到,他的实现和定义都是空的,所以我们可以理解成它并不存在。主要的类加载都是在extention和application中完成,其中extention偏向加载jre目录下的对象,application偏向记载classpath下jar中的对象。
**补充重点:双亲委派模型**
当一个类加载器区加载一个类的时候,会优先委托父类去尝试加载,以此传递到顶层(Extention),如果父类加载不了,才会由子类加载,这样确保了:
1.一个类只会被加载一次
2.每个类都会尽可能被夹在
3.避免恶意加载(直接通过自定义加载器加载成JVM无法处理的)
**补充重点:happend-before原则**
即先后原则,大致如下:
- 程序执行有序,前一个的执行结果必须对后一个操作可见
- 锁有序,只能先加锁,再解锁
- volatile读写有序,即对一个volatile对象的读操作之前,必须先写这个对象
- 传递性原则,A依赖B的结果,B依赖C的结果,那么A一定执行在C后面
- 线程启动原则,先启动再执行线程内部方法
- 线程终止原则,终止只能发生在不线程内部方法执行后
- 线程中断原则
2.1 类初始化的过程:
1.加载:由类加载器,对class文件进行读写到JVM中,流程大致为先获取class文件,以二进制流读入内存,再将二进制流静态存储结构转化为运行时数据结构,最后在内存(堆)中生成对象;
2.链接:链接也分为三个过程,验证、准备、解析。验证的目的是为了确保加载进来的二进制数据流,符合JVM规范,准备阶段是为静态变量和常量在方法区分配内存,设置默认值,解析是虚拟机讲常量池的符号引用替换为直接引用的过程
3.初始化:根据赋值语句为变量赋值和内存分配的过程
4.使用:程序内部的调用
5.卸载:对象的销毁,引用变为null
2.2 class初始化(详述类加载第三步)
1.每个类都有一个初始化锁LOCK,初始化的第一步就是去获取LOCK
2.如果这个类正在被其他线程初始化,此时当前线程获取不到LOCK,处于等待状态
3.如果这个类已经被初始化,则不去尝试获取锁,直接使用该对象
4.如果其他线程初始化失败,抛出异常,该线程会释放锁,当前线程获取到LOCK后会去做初始化的动作(类变量初始化和静态代码块执行,对象内存分配)
5.当前线程初始化完成后,会释放LOCK,并通知其他线程放弃初始化
3、GC垃圾回收
类加载说完之后,就涉及到对象的回收机制,这里我们主要针对的就是堆内存的回收。常见的堆内存分代为新生代和老年代,新生代又分为Eden区和Survivor区,Survivor区又分为From区和To区。常规情况下,我们的对象都是创建在新生代的Eden区,当一个对象被标记为可清除后,会从Eden区转移到From区,进行标记处理,满足回收条件后,会在To区进行回收。当一个对象多次回收失败,会被标记转移到老年代,重新进行回收动作。当然,如果一个对象是大对象,它的创建和销毁都是在老年代发生。
新生代的回收,称之为Young GC,老年代的回收称之为Full GC
**GC中的补充概念**:
**并行:** 多个回收线程同时执行,用户线程等待
**并发:** 回收线程和用户线程同时执行
**吞吐量:** 用户线程运行时长 / (用户线程运行时长 + GC时长)
说完内存分代,就会引出不同分代下的垃圾收集器和相关的垃圾回收算法,常见的垃圾收集器如下。
3.1 新生代
新生代收集器,都是使用复制算法,内存消耗会比较大,占用资源较多。并且他们都只有并行阶段,没有并发阶段,只要发生GC,就会STW
Serial:
单线程回收,简单,单一线程使用率高
ParNew:
多线程回收,为了解决Serial的效率问题,出的多线程版本,默认开启线程数和CPU核数相同(变相佐证了IO密集型操作,线程数选择cpu核数)
Parallel Scavenge:
多线程,高吞吐,GC自适应调节
3.2 老年代
CMS
标记清除算法,多线程回收
**回收过程:**
初始标记:标记GC Root能直接访问的对象,会出现STW
并发标记:在用户线程执行过程中,进行标记
重新标记:为了修正因用户线程执行,导致遗漏的对象,重新打标,会出现STW
并发清除:在用户线程执行的过程中,进行回收
Serial Old
标记整理算法,单线程回收
Parallel Old
标记整理算法,多线程回收,高吞吐
3.3 G1
区别于其他分代收集器,G1收集器的对象是整个堆,他的优点就是能充分利用CPU资源,完美适配多核条件下的回收场景,大幅减少STW时间。
G1针对新生代(标记整理)和老年代(复制算法),有不同的回收策略
G1回收后,会重新整理内存空间,不会产生内存碎片
他的回收过程和CMS类似,只是最后一步是筛选回收,并不是全部标记对象并发清除
G1的特点:
1、设计原则是尽可能多的回收垃圾
2、内存分区的思路(避免像CMS那种,整个堆内存回收,STW时间过长),分为不同的内存块region,它的内存回收就是把回收对象发知道另一个region中,实现局部压缩
3、只有分代概念,实际的内存空间会在运行时不停切换分区,从而使用不同方式回收,内存使用更合理
4、停顿时间模型,回收时间可控,不会长时间STW
GC回收器通常的选择:
CMS+ParNew
G1
旨在减少STW时间
垃圾回收算法
**标记清除:** 标记为可回收的对象内存回收,会产生内存碎片,空间使用率低,但是高效
**标记整理:** 标记可回收的对象内存回收后,会进行内存移动,空间使用率高,相对回收效率降低
**复制算法:** 重新开辟一个内存空间,进行对象移动,在新的空间中删除边际回收的对象,同事整理合并
4、相关知识
4.1 内存屏障汇编指令
- LoadLoad屏障:
对于这样的语句Load1; LoadLoad; Load2, 在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- StoreStore屏障:
对于这样的语句Store1; StoreStore; Store2, 在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
- LoadStore屏障:
对于这样的语句Load1; LoadStore; Store2, 在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- StoreLoad屏障:
对于这样的语句Store1; StoreLoad; Load2, 在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
4.2 内存溢出的定位和排查
- **【常见】** java.lang.OutOfMemoryError: ......**java heap space**..... 堆栈溢出,代码问题的可能性极大
- java.lang.OutOfMemoryError: **GC over head limit exceeded** 系统处于高频的GC状态,而且
回收的效果依然不佳的情况,就会开始报这个错误,这种情况一般是产生了很多不可以被释放
的对象,有可能是引用使用不当导致,或申请大对象导致,但是java heap space的内存溢出
有可能提前不会报这个错误,也就是可能内存就直接不够导致,而不是高频GC.
- java.lang.OutOfMemoryError: PermGen space jdk1.7之前才会出现的问题 ,原因是系统的
代码非常多或引用的第三方包非常多、或代码中使用了大量的常量、或通过intern注入常量、
或者通过动态代码加载等方法,导致常量池的膨胀
- java.lang.OutOfMemoryError: Direct buffer memory 直接内存不足,因为jvm垃圾回收不
会回收掉直接内存这部分的内存,所以可能原因是直接或间接使用了ByteBuffer中的
allocateDirect方法的时候,而没有做clear
- java.lang.StackOverflowError - Xss设置的太小了
- java.lang.OutOfMemoryError: unable to create new native thread 堆外内存不足,无法为
线程分配内存区域
- java.lang.OutOfMemoryError: request {} byte for {}out of swap 地址空间不够
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号